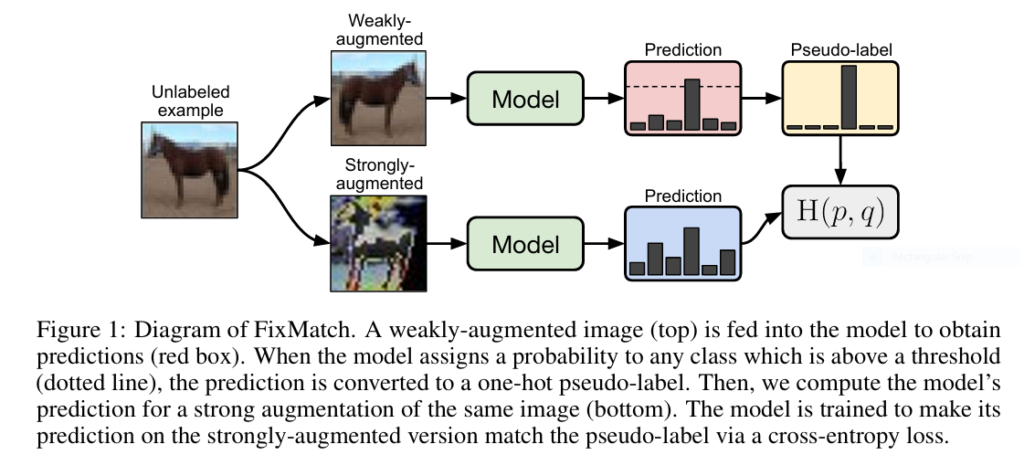
Semi-supervised learning (SSL) tackles one of AI’s biggest bottlenecks: the need for massive labeled datasets. Traditional methods grew complex and hyperparameter-heavy—until FixMatch revolutionized the field. This elegantly simple algorithm combines pseudo-labeling and consistency regularization to achieve state-of-the-art accuracy with minimal labels, democratizing AI for domains with scarce annotated data.
The SSL Challenge: Complexity vs. Scalability
Deep learning thrives on labeled data, but annotation is costly and time-intensive—especially in fields like medical imaging. SSL leverages abundant unlabeled data to boost model performance, but recent methods (MixMatch, UDA, ReMixMatch) became increasingly intricate. FixMatch strips away complexity while improving results by unifying two proven techniques:
- Pseudo-labeling: Generate “artificial labels” from model predictions.
- Consistency regularization: Ensure predictions remain stable under input perturbations.
How FixMatch Works: Simplicity as a Superpower
FixMatch’s innovation lies in its asymmetric use of data augmentation and a confidence-based filtering mechanism. Here’s the 3-step process:
- Weak Augmentation → Pseudo-Label
Apply mild augmentation (flip/shift) to an unlabeled image. If the model predicts a class with >95% confidence, convert the prediction to a hard “pseudo-label.” - Strong Augmentation → Prediction
Apply aggressive augmentation (RandAugment/CTAugment + Cutout) to the same image. Train the model to match the pseudo-label from Step 1. - Unified Loss Function
Combine supervised loss (labeled data) and unsupervised loss (pseudo-labeled data):
Total Loss = ℓₛ + λᵤℓᵤ
ℓₛ = CE Loss (Labeled Data)
ℓᵤ = CE Loss (High-Confidence Pseudo-Labels) | Component | FixMatch | Prior Methods |
|---|---|---|
| Augmentation Strategy | Weak → Strong | Identical for both |
| Artificial Label | Hard pseudo-label | Sharpened distribution |
| Hyperparameters | 3–4 key params | 10+ complex params |
Benchmark Dominance: Less Labels, Higher Accuracy
FixMatch outperformed all predecessors across major datasets with dramatically fewer labels:
CIFAR-10 Results
| Labels per Class | FixMatch Accuracy | Previous SOTA |
|---|---|---|
| 4 | 88.61% | – |
| 250 | 94.93% | 93.73% (ReMixMatch) |
ImageNet (10% Labeled Data)
- Top-1 Error: 28.54% (+2.68% improvement over UDA).
- Matches S4L’s performance without retraining/fine-tuning.
Extreme Low-Data Regime (1 Label/Class)
- Achieved 78% accuracy on CIFAR-10 using only 10 prototypical images.
- Outliers caused training failure, highlighting data quality sensitivity.
Key Insights from Ablation Studies
Through rigorous testing, researchers identified non-negotiable factors for success:
🎯 Confidence Thresholding (τ)
- τ=0.95 optimized the quality/quantity trade-off for pseudo-labels.
- Higher τ reduced “impurity” (incorrect pseudo-labels) but excluded useful data.
- Lower τ flooded training with noise, confirming label quality > quantity.
🌪️ Strong Augmentation is Non-Negotiable
- Removing Cutout or CTAugment increased error by 27%.
- Weak augmentation for predictions caused 45% → 12% accuracy collapse.
⚙️ Hyperparameter Simplicity
- Adam underperformed SGD: Nesterov momentum (η=0.03, β=0.9) was optimal.
- Cosine LR decay outperformed linear/constant schedules.
- Weight decay mis-tuning caused >10% performance drops.
Practical Applications: Where FixMatch Excels
FixMatch’s simplicity makes it adaptable to real-world constraints:
Medical Imaging
- Labeling MRI scans requires radiologists. FixMatch cuts annotation needs by 90%+.
Autonomous Vehicles
- Leverages unlabeled road data to improve object detection with minimal human oversight.
NLP & Multimodal Use Cases
- Replace strong augmentation with back-translation (text) or SpecAugment (audio).
- VAT + FixMatch reduced error by 4% vs. standalone VAT in text classification.
If you’re Interested in skin cancer detection using using advance methods, you may also find this article helpful: GGLA-NeXtE2NET: Advanced Brain Tumor Recognition
Ethical Considerations and Limitations
While FixMatch lowers barriers to AI development, its implications warrant caution:
- Democratization Benefit: Enables startups/researchers with limited labeling budgets.
- Surveillance Risks: High-accuracy few-shot learning could enable invasive person identification.
- Data Bias Amplification: Pseudo-labels may reinforce dataset biases if unmonitored.
Try FixMatch: Implementation Guide
GitHub: github.com/google-research/fixmatch
Basic Workflow:
- Install dependencies: TensorFlow/PyTorch, RandAugment/CTAugment.
- Configure hyperparameters:
params = {
'τ': 0.95, # Confidence threshold
'λᵤ': 1, # Unsupervised loss weight
'batch_size': 64,
'strong_aug': 'randaugment' # or 'ctaugment'
} 3. Add custom data loaders for labeled/unlabeled datasets.
The Future of Accessible AI
FixMatch proves that simplicity drives scalability in machine learning. By merging two foundational SSL techniques with intelligent augmentation, it achieves unprecedented accuracy with almost no labels. As the AI community embraces this framework, we move closer to a world where costly data annotation ceases to be a barrier to innovation.
Explore FixMatch today—transform sparse data into robust models.
“In a low-label regime, quality beats quantity. FixMatch turns this insight into an algorithm.”
– FixMatch Research Team, Google
Full implementation code of Fix-Match using CIFAR10 Dataset with Pytorch Library:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import numpy as np
from torch.optim.lr_scheduler import LambdaLR
from torch.cuda.amp import GradScaler, autocast
import random
import math
# =====================
# Data Augmentation
# =====================
class WeakStrongAugment:
"""Weak and strong augmentations for FixMatch"""
def __init__(self, mean, std):
self.weak = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomCrop(32, padding=4, padding_mode='reflect'),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
self.strong = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomCrop(32, padding=4, padding_mode='reflect'),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize(mean, std),
Cutout(n_holes=1, length=16)
])
def __call__(self, x):
weak = self.weak(x)
strong = self.strong(x)
return weak, strong
class Cutout:
"""Random mask out one or more patches from an image"""
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for _ in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1:y2, x1:x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
# =====================
# Model Architecture
# =====================
class BasicBlock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class WideResNet(nn.Module):
def __init__(self, depth=28, widen_factor=2, num_classes=10):
super(WideResNet, self).__init__()
self.in_planes = 16
assert (depth - 4) % 6 == 0, 'WideResNet depth should be 6n+4'
n = (depth - 4) // 6
k = widen_factor
nStages = [16, 16*k, 32*k, 64*k]
self.conv1 = nn.Conv2d(3, nStages[0], kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(nStages[0])
self.layer1 = self._wide_layer(BasicBlock, nStages[1], n, stride=1)
self.layer2 = self._wide_layer(BasicBlock, nStages[2], n, stride=2)
self.layer3 = self._wide_layer(BasicBlock, nStages[3], n, stride=2)
self.linear = nn.Linear(nStages[3], num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _wide_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, 8)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# =====================
# FixMatch Loss
# =====================
class FixMatchLoss(nn.Module):
"""FixMatch loss function"""
def __init__(self, lambda_u=1.0, threshold=0.95, temperature=1.0):
super().__init__()
self.lambda_u = lambda_u
self.threshold = threshold
self.temperature = temperature
self.ce_loss = nn.CrossEntropyLoss(reduction='none')
def forward(self, logits_x, targets_x, logits_u_w, logits_u_s):
# Supervised loss
loss_x = self.ce_loss(logits_x, targets_x).mean()
# Pseudo-labels from weak augmentation
probs_u_w = F.softmax(logits_u_w.detach() / self.temperature, dim=-1)
max_probs, targets_u = torch.max(probs_u_w, dim=-1)
# Mask for confident predictions
mask = max_probs.ge(self.threshold)
# Unsupervised loss
loss_u = self.ce_loss(logits_u_s, targets_u)
loss_u = loss_u * mask
loss_u = loss_u.mean() if mask.sum() > 0 else 0.0
return loss_x + self.lambda_u * loss_u, loss_x, loss_u, mask.float().mean()
# =====================
# Dataset & DataLoader
# =====================
class SemiSupervisedDataset(Dataset):
"""Combines labeled and unlabeled data"""
def __init__(self, base_dataset, num_labels=4000):
self.base_dataset = base_dataset
self.labeled_idxs = list(range(num_labels))
self.unlabeled_idxs = list(range(len(base_dataset)))
def __len__(self):
return len(self.base_dataset)
def __getitem__(self, idx):
img, label = self.base_dataset[idx]
if idx in self.labeled_idxs:
return img, label, idx # Labeled example
return img, -1, idx # Unlabeled example
def create_dataloaders(num_labels=4000, batch_size=64, mu=7):
# CIFAR-10 statistics
mean = (0.4914, 0.4822, 0.4465)
std = (0.2471, 0.2435, 0.2616)
# Transformations
transform_train = WeakStrongAugment(mean, std)
transform_val = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# Datasets
train_base = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True)
train_dataset = SemiSupervisedDataset(
train_base, num_labels=num_labels)
train_dataset.transform = transform_train
test_dataset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_val)
# DataLoaders
labeled_loader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, num_workers=4,
sampler=torch.utils.data.SubsetRandomSampler(train_dataset.labeled_idxs))
unlabeled_loader = DataLoader(
train_dataset, batch_size=batch_size * mu, shuffle=True,
num_workers=4, drop_last=True,
sampler=torch.utils.data.SubsetRandomSampler(train_dataset.unlabeled_idxs))
test_loader = DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
return labeled_loader, unlabeled_loader, test_loader
# =====================
# Training Utilities
# =====================
def create_optimizer(model, lr=0.03, momentum=0.9, weight_decay=0.0005):
return optim.SGD(model.parameters(), lr=lr, momentum=momentum,
weight_decay=weight_decay, nesterov=True)
def create_scheduler(optimizer, total_steps, warmup_steps=0):
def lr_lambda(step):
if step < warmup_steps:
return step / warmup_steps
return 0.5 * (1.0 + math.cos(math.pi * (step - warmup_steps) / (total_steps - warmup_steps)))
return LambdaLR(optimizer, lr_lambda)
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
# =====================
# Training Loop
# =====================
def train_fixmatch():
# Hyperparameters (from paper)
config = {
'num_labels': 4000, # Number of labeled examples
'batch_size': 64, # Labeled batch size
'mu': 7, # Ratio of unlabeled to labeled batch size
'total_steps': 2**20, # Total training steps
'lr': 0.03, # Learning rate
'momentum': 0.9, # SGD momentum
'weight_decay': 0.0005, # Weight decay
'threshold': 0.95, # Confidence threshold
'lambda_u': 1.0, # Unsupervised loss weight
'widen_factor': 2, # WideResNet widen factor
'depth': 28, # WideResNet depth
}
# Device setup
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# Create model
model = WideResNet(
depth=config['depth'],
widen_factor=config['widen_factor'],
num_classes=10
).to(device)
# Create data loaders
labeled_loader, unlabeled_loader, test_loader = create_dataloaders(
num_labels=config['num_labels'],
batch_size=config['batch_size'],
mu=config['mu']
)
# Optimizer and scheduler
optimizer = create_optimizer(
model,
lr=config['lr'],
momentum=config['momentum'],
weight_decay=config['weight_decay']
)
scheduler = create_scheduler(
optimizer,
total_steps=config['total_steps'],
warmup_steps=0
)
# Loss function
criterion = FixMatchLoss(
lambda_u=config['lambda_u'],
threshold=config['threshold']
)
# Mixed precision
scaler = GradScaler()
# Training loop
step = 0
best_acc = 0.0
labeled_iter = iter(labeled_loader)
unlabeled_iter = iter(unlabeled_loader)
while step < config['total_steps']:
# Get batches
try:
(inputs_x, labels_x, _) = next(labeled_iter)
except StopIteration:
labeled_iter = iter(labeled_loader)
(inputs_x, labels_x, _) = next(labeled_iter)
try:
(inputs_u, _, _) = next(unlabeled_iter)
except StopIteration:
unlabeled_iter = iter(unlabeled_loader)
(inputs_u, _, _) = next(unlabeled_iter)
# Move to device
inputs_x = inputs_x.to(device)
labels_x = labels_x.to(device)
inputs_u = inputs_u.to(device)
# Apply weak/strong augmentations
with torch.no_grad():
weak_u, strong_u = inputs_u.chunk(2, dim=0)
# Forward pass
with autocast():
# Labeled data
logits_x = model(inputs_x)
# Unlabeled data (weak augmentation)
logits_u_w = model(weak_u)
# Unlabeled data (strong augmentation)
logits_u_s = model(strong_u)
# Compute loss
loss, loss_x, loss_u, mask_ratio = criterion(
logits_x, labels_x,
logits_u_w, logits_u_s
)
# Backward pass
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
# Logging
if step % 100 == 0:
print(f"Step [{step}/{config['total_steps']}] | "
f"Loss: {loss.item():.4f} | "
f"Loss_x: {loss_x.item():.4f} | "
f"Loss_u: {loss_u.item():.4f} | "
f"Mask: {mask_ratio.item():.4f} | "
f"LR: {scheduler.get_last_lr()[0]:.6f}")
# Evaluation
if step % 2000 == 0 or step == config['total_steps'] - 1:
test_acc = evaluate(model, test_loader, device)
print(f"Step [{step}] | Test Acc: {test_acc:.4f}")
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), 'fixmatch_best.pth')
step += 1
print(f"Training complete! Best accuracy: {best_acc:.4f}")
def evaluate(model, test_loader, device):
model.eval()
total_acc = 0.0
total_samples = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
acc = accuracy(outputs, labels)
total_acc += acc * inputs.size(0)
total_samples += inputs.size(0)
model.train()
return total_acc / total_samples
if __name__ == "__main__":
# Set random seeds for reproducibility
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
torch.backends.cudnn.deterministic = True
train_fixmatch()