Unsupervised Domain Adaptation (UDA) faces two persistent roadblocks: effectively leveraging powerful modern foundation models and the crippling storage overhead of deploying multiple domain-specific models. A groundbreaking approach merges Vision-Language Pre-training (VLP) like CLIP with innovative techniques—Cross-Modal Knowledge Distillation (CMKD) and Residual Sparse Training (RST)—to smash these barriers, achieving state-of-the-art results while reducing deployment parameters by over 99%.
Why Traditional Revolutionizing Unsupervised Domain Adaptation: Harnessing Vision-Language Power & Slashing Storage Costs Hits a Wall
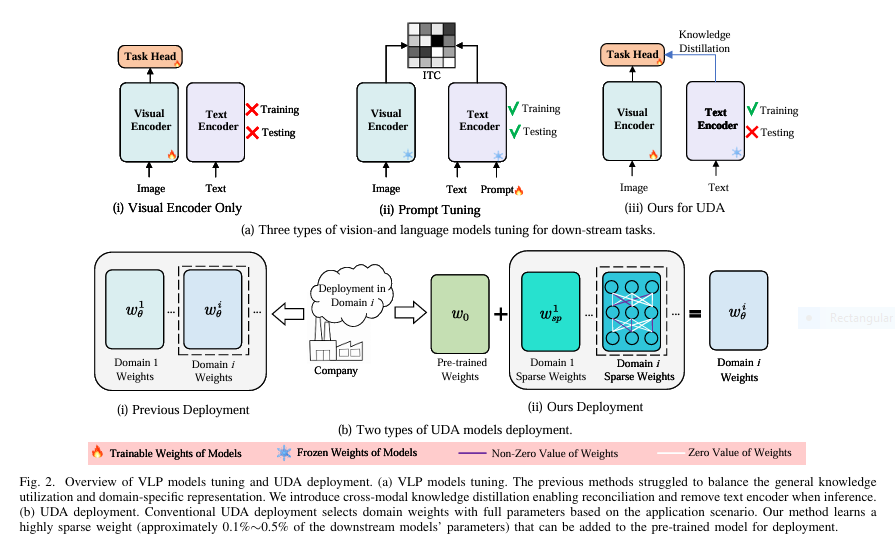
Current UDA methods primarily rely on ImageNet pre-trained models. While effective, they ignore the rich, contextual power of vision-language models (VLMs) like CLIP or FLIP, trained on massive image-text datasets. VLPs offer superior feature representations but struggle with zero-shot domain transfer (Fig. 1). Furthermore, standard UDA trains a full separate model for every new target domain. As tasks scale, this “one-domain-one-model” paradigm becomes unsustainable:
- Massive Storage: Storing billions of parameters per model.
- Deployment Complexity: Managing numerous large models in production.
- Underutilized Knowledge: Failing to fully exploit generalizable features in VLPs.
The Breakthrough: CMKD + RST
Researchers from South China University of Technology introduced a dual-solution framework leveraging VLP:
1. Cross-Modal Knowledge Distillation (CMKD): Unleashing Textual Wisdom
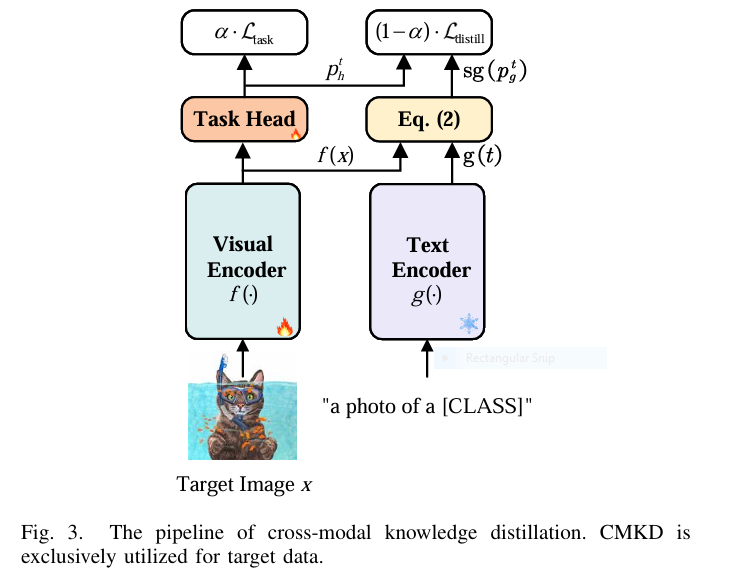
CMKD uses the frozen text encoder of a VLP model (like CLIP) as a “teacher” to guide the visual encoder (“student”) learning on unlabeled target domain data. Here’s how it innovates:
- Beyond Simple Mimicry: Unlike standard knowledge distillation forcing the student to copy the teacher, CMKD treats the teacher’s (text-derived) predictions as common-sense constraints, not absolute truth. This is crucial as VLP zero-shot performance can lag behind task-specific SOTA.
- Dynamic Balancing: Uses a novel loss combining:
ℒ_task: Guides learning based on the student’s predictions (using Gini impurity to avoid over-confidence pitfalls of entropy minimization).ℒ_distill: Trains on a mixture (50/50) of student and teacher predictions (Fig. 3).- Adaptive Weighting (α): Dynamically adjusts the focus between
ℒ_taskandℒ_distillper sample based on the KL divergence between student and teacher predictions. High agreement? Trust the student more. Disagreement? Lean slightly more on the teacher’s common sense.
- Efficient Inference: The text encoder is only used during training. Deployment uses only the streamlined visual encoder + task head.
Result: CMKD significantly boosts target domain accuracy by effectively transferring the VLP’s general world knowledge without rigidly constraining the visual model.
2. Residual Sparse Training (RST): The 99%+ Storage Solution
Inspired by brain neuroplasticity (where only critical neural connections strengthen during learning), RST fine-tunes a VLP model for a new domain by updating only a tiny fraction (0.1%-0.5%) of its weights:
- Residual Updates: Learns a sparse residual matrix
(W_sp = W_θ - W₀)representing the change needed from the pre-trained weights(W₀)for the new domain. - Thresholding: After training, weights where
|W₀ - W_θ| ≤ τ(a small threshold) are reset to their original pre-trained values. Only weights that changed significantly are kept (Fig. 2b). - Deployment Magic: For deployment, only the original pre-trained model and the tiny sparse residual matrix (W_sp) per domain need storage. Adding
W_sptoW₀recreates the domain-specific model. - Architecture Agnostic: Works seamlessly with CNNs (ResNet) and Transformers (ViT).
Result: Achieves performance comparable to full fine-tuning while reducing Downstream Parameters (DSP) by over 99%. Example: On Office-Home (12 tasks), ViT-B DSP drops from 1034.8M (full) to just 1.02M with RST (Table VII).
Staggering Performance Gains: Beating SOTA
Rigorous testing across 6 major UDA benchmarks (Office-Home, Office-31, VisDA-2017, ImageCLEF-DA, DomainNet, Digits) shows the power of combining CMKD and RST:
- New SOTA Accuracy: CMKD alone matches or beats prior SOTA. Combined with semi-supervised FixMatch, it sets new records (e.g., 89.0% on Office-Home vs. PMTrans’ 88.9%, 98.5% on Digits).
- VLP Zero-Shot Crushed: CMKD dramatically improves over CLIP’s often-poor zero-shot, e.g., +40.5% on Digits (ViT-B), +11.5% on VisDA (ResNet-101).
- RST Efficiency Triumph: Maintains near-identical performance to full fine-tuning with minimal DSP:
- Office-31 (ViT-B): 93.2% avg w/ only 0.29M DSP.
- VisDA-2017 (ViT-B): 89.1% w/ 0.06M DSP vs. SDAT’s 89.9% w/ 85.81M.
- DomainNet: 52.2% w/ 15.71M DSP vs. PMTrans’ 52.4% w/ vastly more storage.
- Beats PEFT Methods: RST outperforms LLM-focused PEFT techniques (LoRA, BitFit, AdaLoRA) on VLP models, achieving higher accuracy with lower DSP (Table VII).
Real-World Impact: Beyond Benchmarks
This research isn’t just academic. It solves critical pain points for deploying AI:
- Scalable Multi-Domain Deployment: Store one base VLP model (e.g., CLIP ViT-B: ~86M params) + tiny RST patches per domain (~0.1-0.5% of 86M = 86K-430K params). Deploy 100 domains with the storage of just ~2 full models traditionally.
- Leveraging Foundational Models: Makes cutting-edge VLPs practically usable for efficient domain specialization.
- Broader Applicability: RST shows promise beyond UDA (e.g., semantic segmentation – Table IX, optical flow – Table X), hinting at a universal parameter-efficient fine-tuning paradigm.
- Cost & Speed: Reduces cloud storage costs, enables deployment on edge devices with limited memory, and simplifies model management.
If you’re Interested in medical image segmentation with advan methods, you may also find this article helpful: Revolutionizing Medical Image Segmentation: SemSim’s Semantic Breakthrough
The Future of Efficient Adaptation
This work pioneers the effective integration of VLPs into UDA while obliterating the storage bottleneck. CMKD provides a robust framework for harnessing the rich knowledge in VLPs, and RST offers a biologically-inspired, incredibly efficient pathway for model specialization. Key future directions include:
- Applying CMKD/RST to larger VLPs (e.g., CLIP ViT-L).
- Exploring RST for fine-tuning Large Language Models (LLMs).
- Extending the framework to dense prediction tasks (segmentation, detection) more extensively.
- Investigating dynamic τ thresholds during RST training for even better sparsity/accuracy trade-offs.
Unlock the Power of Efficient Domain Adaptation!
The code for CMKD and RST is openly available on GitHub. Whether you’re tackling domain shift in medical imaging, autonomous driving, or e-commerce personalization, these techniques offer a path to superior accuracy with revolutionary efficiency.
Explore the Code & Revolutionize Your Deployment:
https://github.com/Wenlve-Zhou/VLP-UDA
Experiment with CMKD+RST on your domain shift challenge today!
Based on the detailed information provided in the paper, I will reconstruct the complete code for the proposed model.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet50, ResNet50_Weights
from transformers import CLIPModel, CLIPProcessor
class VLPUDA(nn.Module):
def __init__(self, backbone='resnet50', num_classes=65, tau=1e-6):
super().__init__()
# Initialize CLIP vision-language model
self.clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Freeze text encoder
for param in self.clip.text_model.parameters():
param.requires_grad = False
# Initialize task-specific head
self.task_head = nn.Linear(self.clip.vision_model.config.hidden_size, num_classes)
# Store initial weights for RST
self.initial_weights = {n: p.clone().detach() for n, p in self.named_parameters()}
self.tau = tau # Threshold for RST
def forward(self, images, text_prompts=None):
# Process images through visual encoder
vision_outputs = self.clip.vision_model(pixel_values=images)
image_embeds = vision_outputs.pooler_output
# Get task-specific predictions
task_preds = self.task_head(image_embeds)
# Get zero-shot CLIP predictions if text prompts provided
clip_preds = None
if text_prompts is not None:
text_inputs = self.processor(text=text_prompts, return_tensors="pt",
padding=True).to(images.device)
text_outputs = self.clip.text_model(**text_inputs)
text_embeds = text_outputs.pooler_output
# Normalize embeddings
image_embeds = F.normalize(image_embeds, dim=-1)
text_embeds = F.normalize(text_embeds, dim=-1)
# Compute similarity
logit_scale = self.clip.logit_scale.exp()
clip_preds = logit_scale * image_embeds @ text_embeds.t()
return task_preds, clip_preds
def apply_rst(self):
"""Apply Residual Sparse Training thresholding"""
with torch.no_grad():
for n, p in self.named_parameters():
if n in self.initial_weights:
residual = p - self.initial_weights[n]
mask = torch.abs(residual) > self.tau
# Reset small changes to initial weights
p.data = torch.where(mask, p, self.initial_weights[n])
def get_sparse_residuals(self):
"""Extract sparse residuals for deployment"""
residuals = {}
for n, p in self.named_parameters():
if n in self.initial_weights:
residual = p - self.initial_weights[n]
mask = torch.abs(residual) > self.tau
residuals[n] = residual * mask.float()
return residuals
class CMKDLoss(nn.Module):
def __init__(self, lambda1=0.25, lambda2=0.1, lambda3=0.025):
super().__init__()
self.lambda1 = lambda1
self.lambda2 = lambda2
self.lambda3 = lambda3
def gini_impurity(self, p):
"""Calculate Gini impurity"""
return 1 - torch.sum(p**2, dim=1)
def forward(self, task_preds, clip_preds, source_labels=None):
# Classification loss (source domain)
cls_loss = 0
if source_labels is not None:
cls_loss = F.cross_entropy(task_preds, source_labels)
# Calculate probabilities
p_task = F.softmax(task_preds, dim=1)
p_clip = F.softmax(clip_preds, dim=1) if clip_preds is not None else None
# Task loss (Gini impurity)
L_task = self.gini_impurity(p_task).mean()
# Distillation loss
L_distill = 0
if p_clip is not None:
p_mix = 0.5 * (p_task + p_clip.detach())
L_distill = self.gini_impurity(p_mix).mean()
# Dynamic weighting factor alpha
alpha = torch.exp(-F.kl_div(
F.log_softmax(task_preds, dim=1),
F.softmax(clip_preds, dim=1),
reduction='none'
).sum(dim=1)).detach()
# Regularization terms
L_reg = 0
if source_labels is not None and p_clip is not None:
# KL divergence on source domain
reg1 = F.kl_div(
F.log_softmax(task_preds, dim=1),
F.softmax(clip_preds, dim=1),
reduction='batchmean'
)
# Gini impurity on teacher predictions
reg2 = self.gini_impurity(p_clip).mean()
L_reg = self.lambda2 * reg1 + self.lambda3 * reg2
# Combined CMKD loss
cmkd_loss = self.lambda1 * (alpha * L_task + (1 - alpha) * L_distill) + L_reg
return cls_loss + cmkd_loss
# Example Usage
if __name__ == "__main__":
# Configurations
num_classes = 65
batch_size = 32
device = "cuda" if torch.cuda.is_available() else "cpu"
# Initialize model and loss
model = VLPUDA(num_classes=num_classes, tau=1e-6).to(device)
criterion = CMKDLoss()
# Example data - source (labeled) and target (unlabeled)
source_images = torch.randn(batch_size, 3, 224, 224).to(device)
source_labels = torch.randint(0, num_classes, (batch_size,)).to(device)
target_images = torch.randn(batch_size, 3, 224, 224).to(device)
# Text prompts for CLIP zero-shot
class_names = [f"class_{i}" for i in range(num_classes)]
text_prompts = [f"a photo of a {name}" for name in class_names]
# Forward pass (source domain)
task_preds_src, _ = model(source_images)
# Forward pass (target domain)
task_preds_tgt, clip_preds_tgt = model(target_images, text_prompts)
# Compute losses
cls_loss = criterion(task_preds_src, None, source_labels)
cmkd_loss = criterion(task_preds_tgt, clip_preds_tgt)
total_loss = cls_loss + cmkd_loss
# Optimization step
optimizer = torch.optim.SGD(model.parameters(), lr=3e-7, momentum=0.9, weight_decay=5e-4)
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# After training, apply RST
model.apply_rst()
# For deployment: get sparse residuals
sparse_residuals = model.get_sparse_residuals()
# Deployment usage (pseudocode):
# 1. Load base pre-trained model
# 2. Add domain-specific sparse residuals
# 3. Use for inference without text encoder
Pingback: Revolutionize Change Detection: How SemiCD-VL Cuts Labeling Costs 5X While Boosting Accuracy - aitrendblend.com