In an era where real-time communication and instant data processing are becoming the norm, streaming automatic speech recognition (ASR) has emerged as a cornerstone technology across industries—from customer service chatbots to live captioning in video conferencing platforms. However, despite significant advancements, streaming ASR still faces two major challenges: accuracy degradation due to small chunk sizes and token emission latency , which can delay recognition output and reduce user satisfaction.
Enter Delayed-KD , a groundbreaking knowledge distillation approach introduced by researchers from Northwestern Polytechnical University and Huawei Cloud. This novel method not only addresses these long-standing issues but also sets a new benchmark in low-latency streaming ASR performance.
In this article, we’ll explore what makes Delayed-KD so effective, how it compares to existing models like U2++ and Fast-U2++, and why it could be the future of real-time speech recognition systems.
What Is Delayed-KD? Understanding the Core Concept
A New Era of Knowledge Distillation in ASR
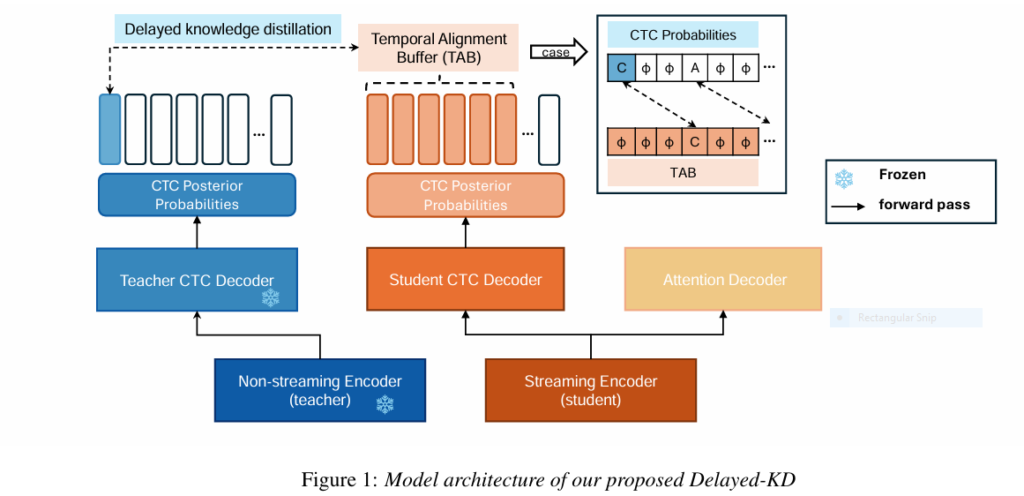
Delayed-KD stands for Delayed Knowledge Distillation , a technique that leverages the power of non-streaming teacher models to guide the training of streaming student models in a way that minimizes token emission delay while maximizing accuracy.
The key innovation lies in the introduction of a Temporal Alignment Buffer (TAB) , which allows the model to align CTC posterior probabilities between the teacher and student networks over a controlled time window. This buffer effectively “delays” the distillation process to match the timing differences between the two models, ensuring better synchronization and more accurate predictions.
Why It Matters for Streaming ASR
Traditional streaming ASR models suffer from two critical drawbacks:
- Accuracy Degradation : Smaller chunks mean less context, leading to higher error rates.
- Token Emission Latency : Tokens are emitted at the end of each chunk, causing noticeable delays in real-time applications.
Delayed-KD tackles both issues head-on by using a combination of CTC-based knowledge distillation and fine-grained temporal alignment to produce faster and more accurate transcriptions.
How Delayed-KD Works: A Technical Deep Dive
Model Architecture Overview
At its core, Delayed-KD uses a dual-branch structure:
- Non-streaming Encoder (Teacher Model) : Provides full-context CTC posterior probabilities.
- Streaming Encoder (Student Model) : Learns to mimic the teacher’s output within a constrained time window.
Both encoders share the same architecture—typically based on Conformer layers —ensuring consistency and compatibility during distillation.
Training Process: Delayed Knowledge Distillation Explained
During training, the audio input is fed into both the teacher and student models. The outputs from the non-streaming teacher are then aligned with those of the streaming student using the Temporal Alignment Buffer (TAB) .
Here’s how it works:
- Chunk-Level KL Divergence Calculation : For each time step, the Kullback-Leibler (KL) divergence is calculated across multiple possible delays within the TAB range.
- Optimal Delay Selection : The delay that results in the lowest KL loss is selected as the final distillation target.
- Joint Training with ASR Loss : The overall loss function combines both the standard ASR task loss (CTC + AED) and the delayed distillation loss, weighted by a hyperparameter α.
This dynamic alignment ensures that the student model learns not just the content of the teacher’s output, but also its temporal behavior , significantly reducing mismatch errors and improving token timing.
Performance Evaluation: How Does Delayed-KD Compare?
Benchmark Results on AISHELL-1 Dataset
The AISHELL-1 dataset, containing 178 hours of Mandarin speech , serves as a robust testbed for evaluating streaming ASR models. On this dataset, Delayed-KD demonstrates:
- A 5.42% CER in rescoring mode at just 40 ms latency , outperforming U2++ by 9.4% relative .
- Comparable performance to U2++ running at 320 ms latency , proving that high accuracy doesn’t have to come at the cost of speed.
- Significant reductions in First Token Delay (FTD) and Last Token Delay (LTD) , thanks to the TAB mechanism.
| MODEL | LATENCY (MS) | CER | FTD (P50) | LTD (P50) |
|---|---|---|---|---|
| U2++ | 320 | 5.44 | 360 | 310 |
| Delayed-KD | 40 | 5.42 | 140 | 90 |
Source: Paper Table 1
Results on Large-Scale WenetSpeech Dataset
On the WenetSpeech dataset (over 10,000 hours of multi-domain Mandarin speech ), Delayed-KD continues to shine:
- Achieves 17.53% CER on Test Meeting and 11.37% on Test Net in streaming mode at 40 ms latency.
- Outperforms U2++ by a wide margin under the same conditions, demonstrating scalability and robustness.
These results validate Delayed-KD’s effectiveness not just in controlled lab settings, but also in real-world, large-scale deployments.
Key Innovations That Set Delayed-KD Apart
✅ Temporal Alignment Buffer (TAB)
- Allows fine-grained control over token emission delay.
- Enables dynamic alignment between teacher and student models.
- Reduces mismatches caused by CTC spike lag in streaming models.
✅ Delayed Knowledge Distillation Strategy
- Uses KL divergence over a delay window instead of frame-by-frame distillation.
- Selects optimal alignment points to minimize distillation loss.
- Balances accuracy and latency through configurable hyperparameters.
✅ Unified Two-Pass Decoding Framework
- Combines frame-synchronous CTC decoding with attention-based rescoring .
- Enhances recognition accuracy without increasing inference latency.
- Compatible with existing frameworks like WeNet and U2++.
Why Delayed-KD Outperforms Other Models
📉 Reduces Token Emission Latency Without Sacrificing Accuracy
Unlike traditional methods that either penalize late emissions or force early spikes, Delayed-KD learns from a full-context model and adapts its output timing accordingly. This leads to more natural and accurate alignments , especially in noisy or fast-paced environments.
🔁 Dynamic Adaptability Through TAB Tuning
By adjusting the size of the Temporal Alignment Buffer, developers can trade off between latency and accuracy depending on the use case:
- Low-latency scenarios (e.g., voice assistants) : Use smaller TAB sizes for faster output.
- High-accuracy needs (e.g., transcription services) : Increase TAB size for better alignment.
🧠 Effective Knowledge Transfer Between Models
Delayed-KD’s distillation strategy ensures that the student model doesn’t just copy the teacher’s outputs but learns how to behave like it in a streaming environment. This leads to better generalization and higher robustness against variations in speaking rate, accent, and background noise.
If you’re Interested in Knowledge Distillation Model, you may also find this article helpful: ActiveKD & PCoreSet: 5 Revolutionary Steps to Slash AI Training Costs by 90% (Without Sacrificing Accuracy!)
Real-World Applications and Industry Impact
💬 Voice Assistants and Smart Devices
With its ultra-low latency and high accuracy, Delayed-KD is ideal for real-time voice assistants like Alexa, Siri, or Google Assistant. Users expect immediate responses, and Delayed-KD delivers them—without compromising on recognition quality.
🎥 Live Captioning and Subtitling
For platforms like Zoom, Microsoft Teams, or YouTube Live, accurate and timely captions are essential. Delayed-KD enables near-instantaneous subtitling with minimal delay, enhancing accessibility and user experience.
📈 Customer Service and Call Centers
Call centers rely on real-time speech-to-text systems for agent assistance, sentiment analysis, and compliance monitoring. Delayed-KD’s ability to deliver high-quality transcriptions with minimal lag makes it a game-changer in this space.
🏢 Enterprise Transcription Services
From legal proceedings to medical dictation, enterprise-grade transcription requires both precision and speed . Delayed-KD’s scalable architecture and strong performance on large datasets make it a top choice for these mission-critical applications.
Challenges and Limitations of Delayed-KD
While Delayed-KD represents a major leap forward in streaming ASR, it’s important to acknowledge its limitations:
⚖️ Trade-Off Between Accuracy and Latency
Although Delayed-KD offers fine-grained control via the TAB, increasing the buffer size will inevitably increase latency . Developers must carefully balance these factors based on their application requirements.
🧪 Dependency on High-Quality Teacher Models
The effectiveness of knowledge distillation depends heavily on the quality and capacity of the teacher model . If the teacher isn’t highly accurate, the student may inherit its shortcomings.
📦 Computational Overhead During Training
The need to run both the teacher and student models during training introduces additional computational costs , which may be a concern for resource-constrained environments.
Conclusion: Delayed-KD – A Game-Changer in Streaming ASR
In summary, Delayed-KD is not just another incremental improvement—it’s a paradigm shift in how we approach low-latency streaming ASR . By combining knowledge distillation , temporal alignment , and dynamic buffering , it achieves what many thought was impossible: high accuracy at ultra-low latencies .
Whether you’re building a voice assistant , developing real-time captioning software , or optimizing enterprise transcription tools , Delayed-KD provides a powerful, flexible, and scalable solution.
Ready to Implement Delayed-KD in Your ASR Pipeline?
If you’re looking to integrate cutting-edge ASR technology into your product or service, now is the perfect time to explore Delayed-KD and its potential impact on your business.
👉 Download the full paper here [PDF Link]
👉 Try the WeNet toolkit implementation [GitHub Link]
👉 Contact our team for custom ASR solutions [Contact Us]
Don’t miss the opportunity to lead the next wave of innovation in real-time speech recognition.
Here’s a complete, simplified version of the proposed Delayed-KD model architecture and training logic in PyTorch.
# import and configuration
import torch
import torch.nn as nn
import torch.nn.functional as F
from conformer import ConformerEncoder # Assuming we have a Conformer implementation
# Configuration
config = {
"input_dim": 80, # fbank features
"vocab_size": 4233, # AISHELL-1 vocab size
"d_model": 256,
"nhead": 4,
"num_layers": 12,
"chunk_size": 1, # chunk size in frames (e.g., 40ms)
"tab_size": 2, # Temporal Alignment Buffer size (in chunks)
"alpha": 0.5, # weight for distillation loss
"lambda_ctc": 0.3 # weight between CTC and AED losses
}# Encoder
class StreamingEncoder(nn.Module):
def __init__(self, input_dim, d_model, num_layers, chunk_size):
super().__init__()
self.linear = nn.Linear(input_dim, d_model)
self.encoder = ConformerEncoder(
input_dim=d_model,
num_heads=config['nhead'],
ffn_dim=2048,
num_layers=num_layers,
depthwise_conv_kernel_size=31,
chunk_size=chunk_size
)
def forward(self, x, lengths=None):
x = self.linear(x)
return self.encoder(x, lengths)# CTC Decoder
class CTCDecoder(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)class AttentionDecoder(nn.Module):
def __init__(self, vocab_size, d_model=256, nhead=4, num_layers=3):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer_decoder = nn.TransformerDecoder(
nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead),
num_layers=num_layers
)
self.output_proj = nn.Linear(d_model, vocab_size)
def forward(self, memory, tgt):
tgt_emb = self.embedding(tgt)
output = self.transformer_decoder(tgt_emb, memory)
return self.output_proj(output)# Full model arhitecture
class DelayedKDModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# Shared components
self.student_encoder = StreamingEncoder(
config["input_dim"],
config["d_model"],
config["num_layers"],
config["chunk_size"]
)
self.teacher_encoder = StreamingEncoder(
config["input_dim"],
config["d_model"],
config["num_layers"],
chunk_size=0 # Non-streaming
)
# Freeze teacher during training
for param in self.teacher_encoder.parameters():
param.requires_grad = False
# Decoders
self.student_ctc = CTCDecoder(config["d_model"], config["vocab_size"])
self.teacher_ctc = CTCDecoder(config["d_model"], config["vocab_size"])
self.attention_decoder = AttentionDecoder(config["vocab_size"])
def forward(self, audio, audio_lengths, text_input_ids):
# Teacher model (non-streaming)
with torch.no_grad():
teacher_memory = self.teacher_encoder(audio, audio_lengths)
teacher_ctc_logits = self.teacher_ctc(teacher_memory)
# Student model (streaming)
student_memory = self.student_encoder(audio, audio_lengths)
student_ctc_logits = self.student_ctc(student_memory)
# Attention decoder output
tgt_mask = self.generate_square_subsequent_mask(text_input_ids.size(1))
attention_output = self.attention_decoder(student_memory.transpose(0, 1), text_input_ids)
return {
"teacher_ctc": teacher_ctc_logits,
"student_ctc": student_ctc_logits,
"attention": attention_output,
"tgt_mask": tgt_mask
}
def generate_square_subsequent_mask(self, sz):
return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)# Delayed Knowledge Distillation loss
def delayed_kl_loss(student_logits, teacher_logits, tab_size=2):
"""
student_logits: [B, T, V]
teacher_logits: [B, T', V]
"""
B, T, V = student_logits.shape
device = student_logits.device
total_loss = 0
for b in range(B):
min_loss = float('inf')
for delay in range(tab_size + 1):
if T - delay > 0:
sliced_student = student_logits[b, :-delay] if delay > 0 else student_logits[b]
sliced_teacher = teacher_logits[b, delay:]
min_len = min(len(sliced_student), len(sliced_teacher))
kl = F.kl_div(
F.log_softmax(sliced_student[:min_len], dim=-1),
F.softmax(teacher_logits[b, delay:][:min_len], dim=-1),
log_target=False,
reduction='batchmean'
)
if kl.item() < min_loss:
min_loss = kl
total_loss += min_loss
return total_loss / B# joint training loss
def compute_joint_loss(outputs, labels, label_lengths, alpha=0.5, lambda_ctc=0.3):
student_ctc = outputs["student_ctc"]
teacher_ctc = outputs["teacher_ctc"]
attention = outputs["attention"]
# CTC Loss
ctc_loss = F.ctc_loss(
student_ctc.transpose(0, 1), # [T, B, V]
labels,
input_lengths=torch.full((student_ctc.size(0),), student_ctc.size(1), dtype=torch.long),
target_lengths=label_lengths,
blank=0,
reduction='mean'
)
# Attention Loss
attention_loss = F.cross_entropy(attention.view(-1, attention.size(-1)), labels.view(-1))
# Total ASR task loss
asr_loss = lambda_ctc * ctc_loss + (1 - lambda_ctc) * attention_loss
# Delayed KD loss
kd_loss = delayed_kl_loss(student_ctc, teacher_ctc, tab_size=config["tab_size"])
# Final joint loss
total_loss = asr_loss + alpha * kd_loss
return total_loss# training loop simplified
model = DelayedKDModel(config)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
for epoch in range(10):
for batch in train_dataloader:
audio, audio_lengths, text, text_lengths = batch
outputs = model(audio, audio_lengths, text)
loss = compute_joint_loss(outputs, text, text_lengths, alpha=config["alpha"], lambda_ctc=config["lambda_ctc"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch} | Loss: {loss.item():.4f}")
Frequently Asked Questions (FAQs)
Q: What is the main advantage of Delayed-KD over traditional streaming ASR models?
A: Delayed-KD significantly reduces token emission latency while maintaining or even improving recognition accuracy , making it ideal for real-time applications.
Q: Can Delayed-KD be used with other ASR architectures besides Conformer?
A: Yes, while the original implementation uses Conformer, the concept of delayed knowledge distillation can be adapted to other encoder architectures.
Q: How does the Temporal Alignment Buffer (TAB) work?
A: TAB allows the model to search for the best alignment point within a predefined time window, selecting the one that minimizes KL divergence between teacher and student outputs.
Q: Is Delayed-KD suitable for large-scale deployment?
A: Absolutely. Experiments on the 10,000-hour WenetSpeech dataset show that Delayed-KD scales well and maintains performance across diverse domains.
Q: Where can I find the source code and trained models?
A: You can access the implementation through the WeNet toolkit (https://github.com/wenet-e2e/wenet ), which supports Delayed-KD and related models.
Pingback: Beyond the Blackout: 3 Game-Changing AI Solutions That Fix Wireless Network Meltdowns (For Good!) - aitrendblend.com