In the ever-evolving world of artificial intelligence, Large Language Models (LLMs) have become the backbone of innovation. From chatbots to content generation tools, these models power some of the most sophisticated applications in use today. However, with great power comes great vulnerability — especially when it comes to model imitation via knowledge distillation (KD) .
Competitors can easily reverse-engineer proprietary LLM capabilities just by observing publicly accessible outputs. This has led to a growing concern among developers and companies who invest heavily in building these models. Enter DOGe (Defensive Output Generation) — a groundbreaking strategy designed to protect LLMs without compromising user experience or performance.
In this article, we’ll explore 7 revolutionary ways DOGe is transforming LLM security , how it works, its impact on model performance, and what you might be missing if you’re not leveraging this cutting-edge defense mechanism.
What Is DOGe and Why Should You Care?
Understanding the Problem: Knowledge Distillation Threats
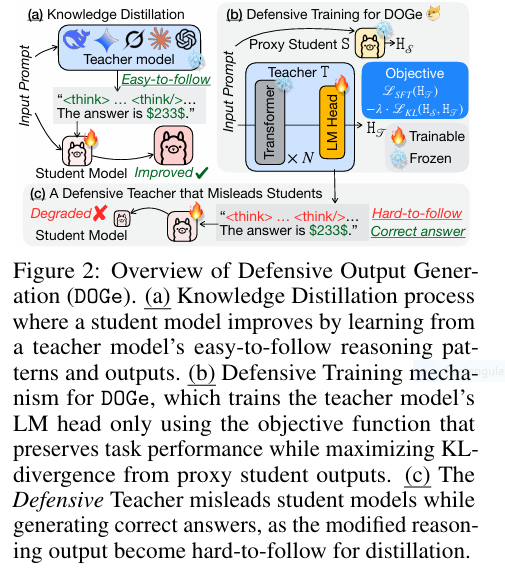
Before diving into DOGe, it’s essential to understand the threat landscape. Knowledge distillation (KD) allows smaller “student” models to mimic the behavior of larger “teacher” models by learning from their outputs. While this technique is widely used for model compression and efficiency, it also opens the door for malicious actors to replicate high-performing models without investing in their development.
Traditional defenses like watermarking or fingerprinting only detect imitation after the fact — they don’t prevent it. Moreover, many existing methods assume that the student model mimics internal logits, which isn’t always the case in real-world API-based KD scenarios.
Introducing Defensive Output Generation: The Game-Changer in LLM Protection
DOGe (Defensive Output Generation) offers a proactive solution by subtly modifying the output behavior of an LLM. These modifications remain imperceptible to legitimate users but are strategically misleading for distillation attempts. By fine-tuning only the final linear layer of the teacher LLM using an adversarial loss, DOGe disrupts the learning process of student models while preserving — or even improving — the original model’s utility.
This approach not only protects intellectual property but also ensures that end-users continue to receive accurate and useful responses.
7 Revolutionary Ways Defensive Output Generation Is Transforming LLM Security
1. Preserving Model Utility While Undermining Imitation
One of the standout features of DOGe is its ability to maintain or even enhance the original performance of the teacher model while significantly degrading the accuracy of distilled student models.
Key Insight:
- DOGe introduces subtle reasoning errors or complex thought patterns that confuse student models.
- Legitimate users still receive correct answers, ensuring no compromise in usability.
- Student models trained on these outputs suffer catastrophic performance drops across multiple benchmarks.
This dual benefit makes DOGe a powerful tool for developers looking to protect their investments without sacrificing user satisfaction.
2. Efficient Defense Without Full Model Retraining
Unlike other methods that require extensive retraining of the entire model, Defence model focuses solely on the final linear layer (LM head) of the LLM. This targeted approach drastically reduces computational costs and training time.
Benefits:
- Cost-effective : Only a small portion of the model needs to be updated.
- Scalable : Easily applied to large-scale models without infrastructure changes.
- Quick deployment : Updates can be rolled out rapidly, making it ideal for fast-moving environments.
By focusing on the LM head, DOGe ensures minimal disruption to the underlying architecture while delivering robust protection.
3. Robustness Against Diverse Student Architectures
Defence model doesn’t just defend against one type of student model — it’s effective across a wide range of architectures and training strategies.
Real-World Impact:
- Tested against models like Llama-3.2-1B and Gemma-3-1b-it , DOGe consistently degraded performance by up to 5x .
- Even when student models had different tokenizers than the teacher, DOGe remained effective due to its focus on output distribution rather than internal mechanics.
This versatility ensures that DOGe remains a formidable defense regardless of the adversary’s resources or sophistication.
4. Cross-Domain Generalization: Protecting Beyond Math
While initial experiments focused on math datasets like GSM8K , DOGe demonstrated strong performance across commonsense reasoning tasks (ARC, CSQA) as well.
Why It Matters:
- Developers can apply Defence model to protect models trained on diverse domains — from legal document analysis to medical diagnostics.
- Cross-domain effectiveness means fewer specialized defenses are needed, simplifying the security landscape.
This generalization capability makes Defence model a versatile choice for any organization deploying LLMs in varied applications.
5. Customizable Trade-Off Between Performance and Security
Defence model allows developers to fine-tune the adversarial loss coefficient (λ) to balance between maintaining teacher model performance and maximizing defense strength.
Practical Application:
- Use lower λ values for minimal impact on user-facing accuracy.
- Increase λ for stronger protection, even at the cost of slight performance degradation in the teacher model.
This flexibility empowers teams to tailor DOGe to their specific risk profiles and operational requirements.
6. Transparent Defense That Doesn’t Compromise User Experience
Perhaps one of the most impressive aspects of Defence model is that users remain unaware of the defense mechanisms at play. Outputs appear natural and coherent, even though they contain subtle distortions that mislead distillation efforts.
Evidence from Testing:
- When evaluated using Gemini-1.5-Pro as a judge, most DOGe-generated outputs were rated as “natural.”
- Minor increases in unnatural samples (e.g., 22% for GSM8K) didn’t detract from overall usability.
This seamless integration ensures that end-users continue to trust and rely on the model’s outputs.
7. Proactive IP Protection in the Age of Open APIs
With more models being deployed via public APIs, traditional post-hoc detection methods fall short. Defence model shifts the paradigm by embedding protection directly into the output generation process , offering a proactive defense against unauthorized replication.
Strategic Advantage:
- Prevents competitors from extracting value through KD without alerting them.
- Maintains competitive edge by keeping proprietary capabilities hidden in plain sight.
For businesses operating in highly competitive industries, DOGe provides peace of mind knowing their innovations are safeguarded.
How DOGe Works: A Technical Deep Dive
Adversarial Training of the Final Layer
At the core of DOGe is an adversarial training objective applied to the final linear layer of the LLM. This layer is responsible for mapping internal representations to vocabulary logits before sampling.
Training Process:
- Supervised Fine-Tuning (SFT) : Ensures the model continues to generate accurate outputs.
- Adversarial Loss (Ladv) : Maximizes divergence between the teacher’s output distribution and proxy student predictions using KL divergence.
- Reasoning-Aware Masking : Applies adversarial updates selectively to intermediate tokens, leaving final answer tokens untouched.
This layered approach ensures that defensive modifications are subtle yet effective.
Empirical Results: DOGe in Action
Across multiple benchmarks, DOGe consistently delivered impressive results:
| DATASET | TEACHER MODEL | STUDENT DEGRADATION |
|---|---|---|
| GSM8K | Qwen3-8B | -8.4% |
| MATH | Qwen3-8B | -17.8% |
| ARC | DeepSeek-R1-Distill-Qwen-7B | -31.7% |
| CSQA | DeepSeek-R1-Distill-Qwen-7B | -39.0% |
These numbers highlight DOGe’s effectiveness in undermining distillation efforts while preserving teacher model integrity.
If you’re Interested in LLM Knowledge Distillation Model , you may also find this article helpful: 7 Revolutionary Ways EasyDistill is Changing LLM Knowledge Distillation (And Why You Should Care!)
Limitations and Considerations
While DOGe represents a major leap forward in LLM security, it’s not without limitations:
- Computational Overhead : Requires additional training beyond standard fine-tuning.
- Hyperparameter Sensitivity : Finding the optimal λ value may require extensive experimentation.
- Proxy Model Dependency : Effectiveness depends on the representativeness of proxy student models.
Despite these challenges, the benefits of DOGe far outweigh the drawbacks for organizations serious about protecting their AI assets.
Conclusion: Embrace DOGe Before It Becomes Standard Practice
As LLMs continue to shape the future of technology, protecting them from unauthorized replication is no longer optional — it’s essential. DOGe offers a proactive, efficient, and user-friendly defense that preserves model utility while disrupting imitation attempts.
Whether you’re a developer, enterprise, or researcher, integrating DOGe into your model deployment pipeline could be the difference between leading the market and playing catch-up.
Call to Action: Secure Your LLMs Today!
Ready to take your LLM security to the next level? Explore DOGe today and ensure your models stay ahead of the curve. Visit GitHub to access the code and start implementing this powerful defense strategy.
📄 Paper: arXiv:2505.19504
Don’t wait until your model is compromised — act now and lead the way in secure AI innovation!
Below is a complete code implementation of DOGe based on the methodology described in the paper, using PyTorch and Hugging Face Transformers.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, AutoModelForCausalLM, AdamW, get_scheduler
from datasets import load_dataset
import random
# Set seed for reproducibility
torch.manual_seed(233)
random.seed(233)
# Configuration
TEACHER_MODEL = "Qwen/Qwen3-8B"
PROXY_STUDENT_MODELS = ["Qwen/Qwen3-1.7B", "Qwen/Qwen3-4B"]
DATASET_NAME = "gsm8k"
SUBSET = "main"
TOKENIZER_NAME = TEACHER_MODEL
MAX_LENGTH = 512
BATCH_SIZE = 4
EPOCHS = 2
LEARNING_RATE = 5e-5
ADVERSARIAL_COEF = 3e-5
TEMPERATURE = 2.0
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_NAME)
tokenizer.pad_token = tokenizer.eos_token
# Load dataset
dataset = load_dataset(DATASET_NAME, SUBSET)
def tokenize_function(examples):
return tokenizer(examples["question"], padding="max_length", truncation=True, max_length=MAX_LENGTH, return_special_tokens_mask=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=["question", "answer"])
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=BATCH_SIZE)
# Load teacher model
teacher_model = AutoModelForCausalLM.from_pretrained(TEACHER_MODEL).to(DEVICE)
teacher_model.eval() # Teacher base is frozen
# Replace the LM head with a trainable one
lm_head = teacher_model.get_output_embeddings()
lm_head.requires_grad_(True)
teacher_model.set_output_embeddings(nn.Linear(lm_head.in_features, lm_head.out_features, bias=False).to(DEVICE))
teacher_model.get_output_embeddings().weight = lm_head.weight # Copy weights
# Load proxy student models
proxy_models = [AutoModelForCausalLM.from_pretrained(model).to(DEVICE).eval() for model in PROXY_STUDENT_MODELS]
# Optimizer and scheduler
optimizer = AdamW(teacher_model.get_output_embeddings().parameters(), lr=LEARNING_RATE)
lr_scheduler = get_scheduler(
name="cosine",
optimizer=optimizer,
num_warmup_steps=int(0.1 * len(train_dataloader) * EPOCHS),
num_training_steps=len(train_dataloader) * EPOCHS,
)
# Reasoning-aware mask function (simplified version)
def create_reasoning_mask(input_ids):
"""Mask intermediate tokens (thinking steps), leave answer tokens unmasked"""
masks = []
for ids in input_ids:
decoded = tokenizer.decode(ids)
# Simplified logic: mask all except boxed answers like \boxed{...}
mask = [0 if "\\boxed{" in tokenizer.decode([id]) else 1 for id in ids]
masks.append(mask)
return torch.tensor(masks, device=DEVICE, dtype=torch.float32)
# Training loop
teacher_model.train()
for epoch in range(EPOCHS):
for batch in train_dataloader:
input_ids = batch["input_ids"].to(DEVICE)
attention_mask = batch["attention_mask"].to(DEVICE)
with torch.no_grad():
teacher_logits = teacher_model(input_ids=input_ids, attention_mask=attention_mask).logits
# Supervised fine-tuning loss (standard cross-entropy)
shift_labels = input_ids[..., 1:].contiguous()
shift_logits = teacher_logits[..., :-1, :].contiguous()
sft_loss = nn.CrossEntropyLoss()(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
# Adversarial loss: maximize KL divergence between teacher and proxy outputs
adv_losses = []
for proxy in proxy_models:
with torch.no_grad():
proxy_logits = proxy(input_ids=input_ids, attention_mask=attention_mask).logits
proxy_probs = torch.softmax(proxy_logits / TEMPERATURE, dim=-1)
teacher_probs = torch.log_softmax(teacher_logits / TEMPERATURE, dim=-1)
kl_div = torch.sum(proxy_probs * (torch.log(proxy_probs + 1e-12) - teacher_probs), dim=-1)
adv_loss = kl_div.mean()
adv_losses.append(adv_loss)
adv_loss = sum(adv_losses) / len(adv_losses)
# Apply reasoning-aware mask
mask = create_reasoning_mask(input_ids)
masked_adv_loss = (adv_loss * mask[:, :-1]).mean()
total_loss = sft_loss + ADVERSARIAL_COEF * masked_adv_loss
# Backpropagation
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
lr_scheduler.step()
print(f"Epoch {epoch+1}/{EPOCHS}, Loss: {total_loss.item():.4f}")
# Save defensive model
teacher_model.save_pretrained("./doge_defensive_teacher")
tokenizer.save_pretrained("./doge_defensive_teacher")
print("✅ Defensive model saved to ./doge_defensive_teacher")
Pingback: 7 Revolutionary Insights About ToDi (Token-wise Distillation): The Future of Language Model Efficiency - aitrendblend.com