Introduction: Why Bias in Retinal Imaging Matters More Than Ever
Retinal fundus images are crucial in diagnosing conditions from diabetic retinopathy to cardiovascular diseases. But here’s the problem: most AI models trained on retinal images learn the wrong things.
Imagine this: a deep learning system that diagnoses ethnicity instead of actual disease features—because the camera used has a distinct hue. This isn’t just misleading. It’s dangerous.
The groundbreaking 2025 study by Müller et al. from the University of Tübingen reveals how disentangled generative models can correct such spurious correlations, enabling robust and fair AI systems in ophthalmology. This article uncovers 7 key insights from the study, explores their strengths and limitations, and offers guidance for developers, clinicians, and researchers.
1. 🚫 The Hidden Threat: Spurious Correlations in Retinal Datasets
Large-scale datasets like EyePACS are often heterogeneous, with images captured using different cameras under varying conditions. A typical scenario?
- Camera A: Mostly Latin American patients
- Camera B: Mostly Caucasian patients
Without correction, AI models will exploit the camera-induced hue differences to infer ethnicity, completely bypassing true biological markers. This phenomenon, known as shortcut learning, severely compromises generalizability and fairness.
“Camera type becomes a proxy for patient demographics—exactly what we want to avoid in clinical AI.” — Müller et al., 2025
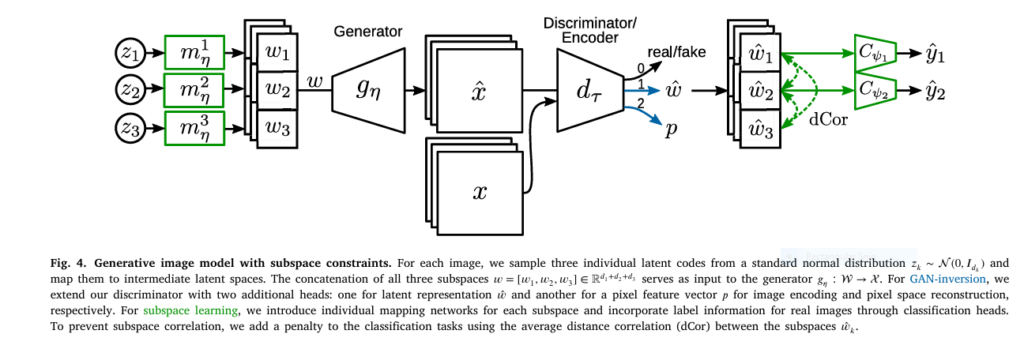
2. 🧠 The Power of Disentangled Representations
To address this, the authors employ disentangled subspace learning using StyleGAN2, a state-of-the-art generative adversarial network (GAN). The idea? Separate the latent space into independent subspaces for:
- Patient Attributes (e.g., Age, Ethnicity)
- Camera Type
- Image Style (Noise, Illumination, etc.)
This allows for controlled image generation and robust representation learning that respects the causal structure of data.
3. 🧮 Distance Correlation: A Smarter Loss for Independence
Forget mutual information estimators that struggle with scalability and non-linearity. Müller et al. propose a novel disentanglement loss based on Distance Correlation (dCor). This measures both linear and nonlinear dependencies, and crucially:
- Doesn’t require density estimation
- Can handle arbitrary dimensional subspaces
- Is fast and scalable for large image batches
$$
\text{dCor}(w_i, w_j) = \frac{\text{dCov}(w_i, w_j)}{\sqrt{\text{dCov}(w_i, w_i) \cdot \text{dCov}(w_j, w_j)}}
$$
4. 🛠️ Encoder and GAN Fusion: A New Architecture Paradigm
The study integrates:
- An Encoder that learns subspaces for known attributes
- A StyleGAN2-based Generator for image synthesis
- A Discriminator-as-Encoder (GAN-Inversion) for realistic image reconstructions
Key innovations include:
- Linear classifiers attached to each subspace
- Disentanglement penalty via average dCor
- Style subspace for unlabelled variation
This hybrid model not only generates high-quality images, but also learns fair and interpretable representations.
5. 📊 Results: Better Disentanglement, Same Image Quality
In both predictive and generative setups, the results were striking:
- Baseline models showed heavy entanglement (e.g., camera info leaking into age subspace)
- Disentangled models preserved task performance while reducing cross-subspace interference
Importantly:
- FID Scores (Frechet Inception Distance) remained competitive
- t-SNE plots showed clear subspace clustering
- k-NN accuracy improvements confirmed explicitness and modularity
✅ No performance trade-off between disentanglement and image quality.
6. 🔁 Subspace Swapping: Controlled and Explainable Image Synthesis
Using the disentangled GAN, the authors performed subspace swapping to assess how specific attributes affect the generated image. Findings:
- Age subspace swaps led to subtle changes in reflectance and vessel clarity
- Camera swaps altered image hue and contrast
- Ethnicity swaps changed pigmentation, particularly fundus coloration
These swaps were biologically plausible and interpretable, a major win for explainability.
“Changing the ethnicity subspace not only affected fundus pigmentation but sometimes even altered vascular patterns—highlighting hidden correlations.” — Müller et al.
If you’re Interested in Segmentation model with advance methods , you may also find this article helpful: Revolutionary AI Breakthrough: Non-Contrast Tumor Segmentation Saves Lives & Avoids Deadly Risks
7. 🚧 Limitations and Next Steps: Where It Still Fails
Despite its strengths, the model isn’t perfect.
Limitations:
- StyleGAN2 struggles with vascular detail in fine-grained reconstructions
- Disentanglement may still fail when labels are unbalanced (e.g., ethnicity)
- Requires careful tuning of disentanglement weight λ_DC, as too high values collapse the representation
Future Directions:
- Integrate Diffusion Models for better vascular fidelity
- Explore semi-supervised learning for scarce label scenarios
- Develop causal interventions using synthetic counterfactuals
Keywords
- Disentangled representation learning
- Retinal fundus image generation
- Spurious correlation in medical imaging
- GAN-inversion StyleGAN2
- Distance correlation loss
- AI fairness in ophthalmology
- Explainable medical AI
- Causal deep learning
- Age and ethnicity bias in retinal datasets
- Subspace disentanglement in generative models
Final Thoughts: Toward Trustworthy AI in Medical Imaging
The promise of AI in medicine hinges on trust, transparency, and generalizability. The 2025 work by Müller et al. delivers a critical framework to build models that not only perform well but also learn the right thing for the right reason.
By integrating causal thinking, generative power, and statistical disentanglement, this work marks a pivotal shift toward trustworthy, explainable, and robust AI in ophthalmology.
💬 Call to Action
Are you building or researching medical AI models?
👉 Explore the project code on GitHub
👉 Cite the paper: Müller et al., Medical Image Analysis, 2025
👉 Share this article with your lab or AI ethics committee
Let’s build models that see clearly and learn fairly. 💡
Here’s the complete PyTorch implementation of the proposed disentangled generative model for retinal images, based on the research paper:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import autograd
from torch.cuda.amp import autocast
import numpy as np
from scipy.spatial.distance import pdist, squareform
# =====================
# Distance Correlation
# =====================
def distance_correlation(x, y):
"""
Computes distance correlation between two matrices
"""
# Flatten and convert to double precision
x = x.view(x.shape[0], -1).double()
y = y.view(y.shape[0], -1).double()
# Compute pairwise distances
a = squareform(pdist(x.detach().cpu().numpy()))
b = squareform(pdist(y.detach().cpu().numpy()))
# Double centering
A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean()
B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean()
# Compute distance covariance
dcov = np.sqrt(np.abs(np.sum(A * B) / (a.shape[0] ** 2)))
# Compute distance variances
dvar_x = np.sqrt(np.abs(np.sum(A * A) / (a.shape[0] ** 2)))
dvar_y = np.sqrt(np.abs(np.sum(B * B) / (b.shape[0] ** 2)))
# Compute distance correlation
dcor = dcov / np.sqrt(dvar_x * dvar_y + 1e-9)
return torch.tensor(dcor).float().to(x.device)
# =====================
# StyleGAN2 Components
# =====================
class MappingNetwork(nn.Module):
"""8-layer mapping network for each subspace"""
def __init__(self, latent_dim=512, hidden_dim=512, num_layers=8):
super().__init__()
layers = []
for i in range(num_layers):
layers.append(nn.Linear(latent_dim, hidden_dim))
layers.append(nn.LeakyReLU(0.2))
self.net = nn.Sequential(*layers)
def forward(self, z):
return self.net(z)
class StyleGAN2Generator(nn.Module):
"""Modified StyleGAN2 generator with separate mapping networks"""
def __init__(self,
num_subspaces=3,
latent_dims=[4, 12, 16], # Age, Camera, Style
img_size=256,
channel_multiplier=2):
super().__init__()
self.num_subspaces = num_subspaces
self.latent_dims = latent_dims
self.style_dim = sum(latent_dims)
# Separate mapping networks for each subspace
self.mapping_networks = nn.ModuleList([
MappingNetwork(dim, 512) for dim in latent_dims
])
# Synthesis network (StyleGAN2 backbone)
self.channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
self.conv_blocks = nn.ModuleList()
self.to_rgbs = nn.ModuleList()
self.num_layers = int(np.log2(img_size)) * 2 - 2
# Build progressive growing structure
in_channel = self.channels[4]
for i in range(3, int(np.log2(img_size)) + 1):
out_channel = self.channels[2 ** i]
self.conv_blocks.append(
StyledConvBlock(in_channel, out_channel, 3, upsample=True)
)
self.to_rgbs.append(ToRGB(out_channel))
in_channel = out_channel
# Noise inputs
self.noises = nn.Module()
for layer_idx in range(self.num_layers):
res = (layer_idx + 5) // 2
self.noises.register_buffer(f'noise_{layer_idx}',
torch.randn(1, 1, 2 ** res, 2 ** res))
def forward(self, w, noise=None):
# Split W vector into subspaces
w_splits = torch.split(w, self.latent_dims, dim=1)
# Generate styles for each subspace
styles = []
for i, (w_sub, mapper) in enumerate(zip(w_splits, self.mapping_networks)):
styles.append(mapper(w_sub))
style = torch.cat(styles, dim=1)
# Map to style space
style = style.view(style.size(0), 1, -1).repeat(1, self.num_layers, 1)
# Initial constant input
x = self.input(style[:, 0])
# Progressive synthesis
rgb = None
for i, (conv, to_rgb) in enumerate(zip(self.conv_blocks, self.to_rgbs)):
# Get layer noise
noise = getattr(self.noises, f'noise_{i}')
if noise.size(2) < x.size(2) or noise.size(3) < x.size(3):
noise = F.interpolate(noise, size=(x.size(2), x.size(3)),
mode='bilinear', align_corners=False)
# Style-based convolution
x = conv(x, style[:, i], noise)
# Convert to RGB
rgb = to_rgb(x, style[:, i + 1], rgb)
return rgb
# =====================
# Discriminator with Encoder Heads
# =====================
class MultiHeadDiscriminator(nn.Module):
"""Discriminator with three heads: real/fake, latent, pixel features"""
def __init__(self, img_size=256, latent_dims=[4, 12, 16], channel_multiplier=2):
super().__init__()
self.img_size = img_size
# Shared backbone (StyleGAN2 discriminator)
channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
}
self.convs = nn.ModuleList()
self.from_rgbs = nn.ModuleList()
# Build progressive structure
in_channel = channels[img_size]
log_size = int(np.log2(img_size))
for i in range(log_size, 2, -1):
out_channel = channels[2 ** (i - 1)]
self.from_rgbs.append(FromRGB(in_channel, 2 ** i))
self.convs.append(ConvBlock(in_channel, out_channel))
in_channel = out_channel
# Final layers
self.stddev_group = 4
self.stddev_feat = 1
self.final_conv = ConvBlock(in_channel + 1, channels[4])
self.final_linear = nn.Sequential(
nn.Linear(channels[4] * 4 * 4, channels[4]),
nn.LeakyReLU(0.2),
nn.Linear(channels[4], 1)
)
# Encoder heads
self.latent_head = nn.Linear(channels[4] * 4 * 4, sum(latent_dims))
self.pixel_feat_head = nn.Sequential(
nn.Linear(channels[4] * 4 * 4, 512),
nn.LeakyReLU(0.2)
)
# Subspace classifiers
self.classifiers = nn.ModuleList([
nn.Linear(dim, num_classes) for dim, num_classes in zip(
latent_dims, [3, 14, 1]) # Age groups, camera types, style
])
def forward(self, x):
# Feature extraction
x = self.from_rgbs[0](x)
for i, (conv, from_rgb) in enumerate(zip(self.convs, self.from_rgbs[1:])):
x = conv(x)
x = F.interpolate(x, scale_factor=0.5, mode='bilinear')
x = from_rgb(x)
# Minibatch standard deviation
batch, channel, height, width = x.shape
group = min(batch, self.stddev_group)
stddev = x.view(group, -1, self.stddev_feat, channel // self.stddev_feat, height, width)
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
stddev = stddev.mean([2, 3, 4], keepdim=True).squeeze(2)
stddev = stddev.repeat(group, 1, height, width)
x = torch.cat([x, stddev], 1)
# Final processing
x = self.final_conv(x)
x = x.view(batch, -1)
# Discriminator output
disc_out = self.final_linear(x)
# Encoder outputs
latent_out = self.latent_head(x)
pixel_feat_out = self.pixel_feat_head(x)
return disc_out, latent_out, pixel_feat_out
# =====================
# Full Model Integration
# =====================
class DisentangledRetinaGAN(nn.Module):
"""End-to-end model with disentanglement losses"""
def __init__(self,
num_subspaces=3,
latent_dims=[4, 12, 16], # Age, Camera, Style
img_size=256,
lambda_dc=0.2,
lambda_cls=0.04,
lambda_w=1.0,
lambda_p=2.0):
super().__init__()
self.generator = StyleGAN2Generator(
num_subspaces, latent_dims, img_size
)
self.discriminator = MultiHeadDiscriminator(
img_size, latent_dims
)
# Loss weights
self.lambda_dc = lambda_dc
self.lambda_cls = lambda_cls
self.lambda_w = lambda_w
self.lambda_p = lambda_p
def forward(self, real_imgs, labels):
# ----------------------
# Train Discriminator
# ----------------------
with autocast():
# Generate fake images
z = [torch.randn(real_imgs.size(0), dim).to(real_imgs.device)
for dim in self.generator.latent_dims]
w = torch.cat(z, dim=1)
fake_imgs = self.generator(w)
# Discriminator outputs for real images
d_real, w_real, p_real = self.discriminator(real_imgs)
# Discriminator outputs for fake images
d_fake, _, _ = self.discriminator(fake_imgs.detach())
# GAN loss (non-saturating)
loss_d_real = F.softplus(-d_real).mean()
loss_d_fake = F.softplus(d_fake).mean()
gan_loss = loss_d_real + loss_d_fake
# R1 regularization
real_imgs.requires_grad = True
d_real_pred, _, _ = self.discriminator(real_imgs)
grad_real = autograd.grad(
outputs=d_real_pred.sum(), inputs=real_imgs, create_graph=True
)[0]
r1_loss = grad_real.pow(2).view(grad_real.shape[0], -1).sum(1).mean()
# Subspace classification loss
w_real_splits = torch.split(w_real, self.generator.latent_dims, dim=1)
cls_losses = []
for i, (w_sub, classifier) in enumerate(zip(w_real_splits, self.discriminator.classifiers)):
if i < len(labels): # Skip style subspace
cls_loss = F.cross_entropy(classifier(w_sub.detach()), labels[i])
cls_losses.append(cls_loss)
cls_loss = torch.stack(cls_losses).mean()
# Distance correlation loss
dc_losses = []
for i in range(len(w_real_splits)):
for j in range(i+1, len(w_real_splits)):
dc = distance_correlation(w_real_splits[i], w_real_splits[j])
dc_losses.append(dc)
dc_loss = torch.stack(dc_losses).mean()
# Total discriminator loss
d_loss = gan_loss + r1_loss * 5.0 + \
cls_loss * self.lambda_cls + \
dc_loss * self.lambda_dc
# ----------------------
# Train Generator
# ----------------------
with autocast():
# Generate fake images
fake_imgs = self.generator(w)
d_fake, w_fake, p_fake = self.discriminator(fake_imgs)
# GAN loss (non-saturating)
g_loss = F.softplus(-d_fake).mean()
# Path length regularization
pl_loss = self.generator.path_length_reg(w, fake_imgs)
# Inversion losses
w_loss = F.mse_loss(w, w_fake)
p_loss = F.mse_loss(p_real.detach(), p_fake)
# Subspace classification for generator
w_fake_splits = torch.split(w_fake, self.generator.latent_dims, dim=1)
g_cls_losses = []
for i, (w_sub, classifier) in enumerate(zip(w_fake_splits, self.discriminator.classifiers)):
if i < len(labels): # Skip style subspace
g_cls_loss = F.cross_entropy(classifier(w_sub), labels[i])
g_cls_losses.append(g_cls_loss)
g_cls_loss = torch.stack(g_cls_losses).mean()
# Total generator loss
g_total = g_loss + pl_loss * 2.0 + \
w_loss * self.lambda_w + \
p_loss * self.lambda_p + \
g_cls_loss * self.lambda_cls
return {
"d_loss": d_loss,
"g_loss": g_total,
"r1_loss": r1_loss,
"pl_loss": pl_loss,
"cls_loss": cls_loss,
"dc_loss": dc_loss,
"w_loss": w_loss,
"p_loss": p_loss
}
def generate(self, age=None, camera=None, style=None):
"""Generate images from disentangled subspaces"""
with torch.no_grad():
# Create latent vectors
z_age = torch.randn(1, 4).to(self.device) if age is None else age
z_cam = torch.randn(1, 12).to(self.device) if camera is None else camera
z_style = torch.randn(1, 16).to(self.device) if style is None else style
# Generate image
w = torch.cat([z_age, z_cam, z_style], dim=1)
return self.generator(w)
def swap_subspaces(self, img1, img2, swap_idx):
"""
Swap subspaces between two images
swap_idx: 0=age, 1=camera, 2=style
"""
with torch.no_grad():
# Encode images
_, w1, _ = self.discriminator(img1)
_, w2, _ = self.discriminator(img2)
# Split subspaces
w1_parts = torch.split(w1, self.generator.latent_dims, dim=1)
w2_parts = torch.split(w2, self.generator.latent_dims, dim=1)
# Swap specified subspace
new_parts = []
for i in range(len(w1_parts)):
if i == swap_idx:
new_parts.append(w2_parts[i])
else:
new_parts.append(w1_parts[i])
# Generate new image
w_new = torch.cat(new_parts, dim=1)
return self.generator(w_new)
# =====================
# Auxiliary Components
# =====================
class StyledConvBlock(nn.Module):
"""Style-based convolutional block"""
def __init__(self, in_channel, out_channel, kernel_size, upsample=False):
super().__init__()
self.conv = ModulatedConv2d(
in_channel, out_channel, kernel_size, upsample=upsample
)
self.noise = NoiseInjection()
self.activate = nn.LeakyReLU(0.2)
self.style = StyleModulation(out_channel)
def forward(self, x, style, noise):
x = self.conv(x, style)
x = self.noise(x, noise)
x = self.activate(x)
x = self.style(x, style)
return x
class ModulatedConv2d(nn.Module):
"""Modulated convolution layer"""
def __init__(self, in_channel, out_channel, kernel_size, upsample=False):
super().__init__()
self.upsample = upsample
self.kernel_size = kernel_size
self.in_channel = in_channel
# Weight modulation
self.weight = nn.Parameter(
torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
)
self.bias = nn.Parameter(torch.zeros(out_channel))
# Style modulation
self.style = nn.Linear(in_channel, in_channel)
def forward(self, x, style):
batch, in_channel, height, width = x.shape
# Style modulation
style = self.style(style).view(batch, 1, in_channel, 1, 1)
weight = self.weight * style
# Demodulation
d = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
weight = weight * d.view(batch, -1, 1, 1, 1)
# Reshape weights
weight = weight.view(
batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
# Upsample if needed
if self.upsample:
x = F.interpolate(x, scale_factor=2, mode='bilinear')
# Grouped convolution
x = x.view(1, batch * in_channel, height, width)
out = F.conv2d(x, weight, padding=self.kernel_size//2, groups=batch)
out = out.view(batch, self.out_channel, *out.shape[2:])
return out + self.bias.view(1, -1, 1, 1)
class NoiseInjection(nn.Module):
"""Adds noise to feature maps"""
def forward(self, x, noise=None):
if noise is None:
noise = torch.randn(x.size(0), 1, x.size(2), x.size(3)).to(x.device)
return x + noise
class StyleModulation(nn.Module):
"""Adaptive instance normalization"""
def __init__(self, channel):
super().__init__()
self.norm = nn.InstanceNorm2d(channel)
self.style = nn.Linear(channel * 2, channel * 2)
def forward(self, x, style):
style = self.style(style)
gamma, beta = style.chunk(2, 1)
return self.norm(x) * (1 + gamma.unsqueeze(2).unsqueeze(3)) + beta.unsqueeze(2).unsqueeze(3)
# =====================
# Training Utilities
# =====================
class RingBuffer:
"""Buffer for storing past batches for distance correlation"""
def __init__(self, capacity, batch_size, latent_dims):
self.capacity = capacity
self.batch_size = batch_size
self.latent_dims = latent_dims
self.buffer = [None] * capacity
self.idx = 0
def push(self, items):
self.buffer[self.idx] = items
self.idx = (self.idx + 1) % self.capacity
def sample(self, num_samples):
samples = []
for _ in range(num_samples):
idx = torch.randint(0, self.capacity, (1,)).item()
if self.buffer[idx] is not None:
samples.append(self.buffer[idx])
return torch.cat(samples, dim=0) if samples else None
def train_step(model, optimizer_G, optimizer_D, real_imgs, labels, buffer):
# Update discriminator
model.requires_grad_(True)
optimizer_D.zero_grad()
losses = model(real_imgs, labels)
losses["d_loss"].backward()
optimizer_D.step()
# Update generator
model.requires_grad_(False)
optimizer_G.zero_grad()
losses["g_loss"].backward()
optimizer_G.step()
# Store in ring buffer for distance correlation
with torch.no_grad():
_, w_real, _ = model.discriminator(real_imgs)
buffer.push(w_real.detach())
return lossesUsage Example:
# Initialize model
model = DisentangledRetinaGAN(
latent_dims=[4, 12, 16], # Age, Camera, Style
img_size=256,
lambda_dc=0.2,
lambda_cls=0.04,
lambda_w=1.0,
lambda_p=2.0
).cuda()
# Initialize optimizers
optimizer_G = torch.optim.Adam(model.generator.parameters(), lr=2.5e-3, betas=(0.9, 0.99))
optimizer_D = torch.optim.Adam(model.discriminator.parameters(), lr=2.5e-3, betas=(0.9, 0.99))
# Initialize ring buffer (for distance correlation)
buffer = RingBuffer(capacity=5, batch_size=56, latent_dims=[4, 12, 16])
# Training loop
for epoch in range(200):
for real_imgs, labels in dataloader: # Labels: [age, camera]
losses = train_step(model, optimizer_G, optimizer_D, real_imgs.cuda(), labels.cuda(), buffer)
# Generate sample images
with torch.no_grad():
# Generate with swapped attributes
img1 = real_imgs[0:1].cuda()
img2 = real_imgs[1:2].cuda()
# Swap ethnicity subspace
swapped_img = model.swap_subspaces(img1, img2, swap_idx=0)
# Generate random sample
random_img = model.generate()FAQs
What is a disentangled representation?
A disentangled representation separates different factors of variation (like age, ethnicity, and camera type) into independent subspaces in a model’s latent space.
How does distance correlation help in disentanglement?
Distance correlation measures both linear and nonlinear dependencies between random vectors. Minimizing it ensures latent subspaces are statistically independent.
Can disentangled models improve diagnostic accuracy?
Yes, by removing spurious correlations, disentangled models can focus on biologically meaningful features, leading to more accurate and generalizable diagnoses.
What is GAN inversion?
GAN inversion maps real images back into the latent space of a generative model, enabling precise editing and reconstruction of input images.
Is this technique limited to retinal images?
No, the principles of disentanglement and causal modeling apply broadly to any domain where technical confounders may influence AI predictions.
Pingback: 🧠 7 Groundbreaking Insights from a Revolutionary Brain Aging AI Model You Can’t Ignore - aitrendblend.com
Pingback: 🔒7 Alarming Privacy Risks of Federated Learning—and the Breakthrough Shadow Defense Fix You Need - aitrendblend.com
Pingback: Final Destination 2025: A White-Knuckle Resurrection of Death's Design? (Review) - aitrendblend.com
Pingback: 🚀 7 Game-Changing Wins & Pitfalls of Multi-Frame Deconvolution in Super-Resolution Ultrasound (SRUS) - aitrendblend.com
Pingback: 7 Powerful Reasons Why The Sandman Season 2 Is Both Mesmerizing and Heartbreaking - aitrendblend.com
Pingback: 7 Shocking Pros and Cons of Countdown Season 1 on Prime Video - aitrendblend.com
some really interesting information, well written and broadly user genial.