Introduction
In the fast-evolving world of artificial intelligence, knowledge distillation has emerged as a critical technique for transferring learning from large, complex models to smaller, more efficient ones. This process is essential for deploying AI in real-world applications where computational resources are limited—think mobile devices or edge computing environments.
However, traditional methods often struggle with balancing the dual objectives of learning from both the teacher model and the task-specific goals. Gradient conflicts and dominance can lead to suboptimal performance, making it difficult to achieve the best results efficiently.
Enter MoKD (Multi-Task Optimization for Knowledge Distillation) , a groundbreaking approach introduced by Hayder et al. in their paper MoKD: Multi-Task Optimization for Knowledge Distillation . This innovative framework addresses key challenges in knowledge distillation by reformulating the training process as a multi-objective optimization problem. The result? Improved accuracy, faster convergence, and greater efficiency in model deployment.
In this article, we’ll explore 7 powerful ways MoKD revolutionizes knowledge distillation , why it’s gaining traction among researchers and developers, and what you might be missing out on if you’re still relying on conventional distillation techniques.
What Is Knowledge Distillation?
Before diving into MoKD, let’s briefly revisit the concept of knowledge distillation .
Knowledge distillation is a machine learning technique where a compact “student” model learns from a larger, pre-trained “teacher” model. The goal is to transfer the teacher’s knowledge—often superior predictive capabilities—to the student without requiring the same computational overhead.
This method is widely used in domains such as:
- Image classification
- Object detection
- Natural language processing
While effective, standard distillation approaches face several limitations:
- Gradient Conflicts : When the gradients from the distillation loss and the task-specific loss pull in opposite directions.
- Gradient Dominance : One objective may overpower the other, leading to unbalanced learning.
- Manual Hyperparameter Tuning : Requires careful adjustment of weights between losses, which is time-consuming and inefficient.
These issues have long been roadblocks in achieving optimal distillation performance—until now.
Why MoKD Stands Out: A Game-Changer in Model Compression
The MoKD framework introduces two major innovations that address the shortcomings of traditional knowledge distillation:
1. Multi-Objective Optimization for Balanced Learning
MoKD treats knowledge distillation as a multi-task learning problem , dynamically adjusting the contribution of each loss function during training. Unlike conventional methods that rely on fixed hyperparameters (e.g., α₁Ldistill + α₂Ltask), MoKD automatically balances the importance of distillation and task-specific objectives.
This eliminates the need for manual tuning and ensures that neither gradient dominates the other, leading to more stable and effective learning.
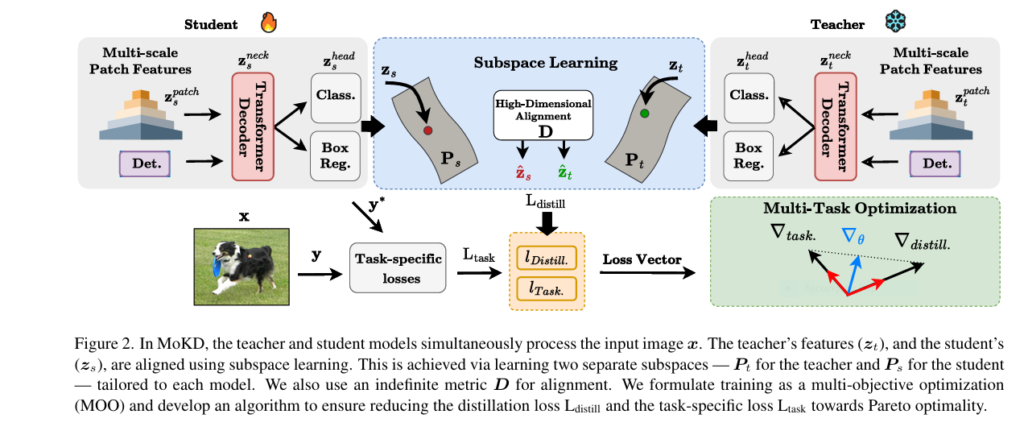
2. Subspace Learning for Enhanced Feature Alignment
MoKD introduces a projection-based adaptation module that aligns the feature representations of the teacher and student models in a shared high-dimensional space. This allows the student to better capture the teacher’s latent knowledge—even when their architectures differ significantly.
By projecting features into a common subspace using orthogonal transformations and indefinite metrics, MoKD improves the flow of information and enhances both positive knowledge (direct predictions) and dark knowledge (implicit relationships learned by the teacher).
7 Powerful Ways MoKD Revolutionizes Knowledge Distillation
Let’s dive deeper into how MoKD is transforming the landscape of model compression and knowledge transfer.
1. Eliminates Manual Hyperparameter Tuning
One of the biggest pain points in traditional knowledge distillation is the need to manually tune the weights assigned to the distillation loss and the task-specific loss.
MoKD automates this process by treating it as a multi-objective optimization problem . It dynamically adjusts the weight of each loss based on their relative improvement rates, ensuring optimal balance throughout training.
✅ Benefit : Faster experimentation cycles and reduced development time.
❌ Missed Opportunity : Without MoKD, teams waste time fine-tuning hyperparameters that MoKD optimizes automatically.
2. Solves Gradient Conflict and Dominance Issues
Gradient conflict occurs when the distillation loss and task loss push the model in opposing directions. Gradient dominance happens when one loss overwhelms the other, leading to biased learning.
MoKD resolves both issues through its gradient alignment strategy , ensuring that updates improve both objectives simultaneously.
✅ Benefit : More stable training and improved generalization.
❌ Missed Opportunity : Models trained with conventional methods risk instability, especially in complex tasks like object detection.
3. Enables High-Dimensional Subspace Alignment
MoKD uses a plug-and-play projection module that maps both teacher and student features into a shared high-dimensional space. This allows for better alignment of features, even when their original representations differ.
Unlike earlier methods that rely on fixed projections or require architectural modifications, MoKD’s approach is flexible and doesn’t alter the student model’s structure.
✅ Benefit : Better knowledge transfer without changing the student architecture.
❌ Missed Opportunity : Competing methods either underperform or require structural changes that complicate deployment.
4. Achieves State-of-the-Art Performance on ImageNet and COCO
Experiments on ImageNet-1K (image classification) and COCO (object detection) demonstrate that MoKD consistently outperforms existing distillation techniques.
For example:
- On ImageNet, MoKD achieves 79.7% Top-1 accuracy with DeiT-Tiny, surpassing previous SOTA methods.
- On COCO, MoKD improves detection performance across multiple student models, including ViDT-nano and ViDT-small.
✅ Benefit : Superior performance on benchmark datasets.
❌ Missed Opportunity : Without MoKD, models lag behind in accuracy and efficiency benchmarks.
5. Reduces Training Time Without Sacrificing Performance
Thanks to its dynamic loss balancing and gradient alignment, MoKD converges faster than traditional distillation methods.
In experiments, MoKD reached the performance level of baseline methods in 230 epochs , compared to 300 epochs required by competing approaches.
✅ Benefit : Reduced training costs and faster time-to-market.
❌ Missed Opportunity : Slower convergence means higher compute costs and delayed deployments.
6. Robust Across Teacher-Student Architectures
MoKD demonstrates strong performance across various teacher-student configurations, including:
- CNN-to-transformer
- Transformer-to-transformer
- Different-sized transformer models
This versatility makes it ideal for organizations looking to compress diverse model types without sacrificing accuracy.
✅ Benefit : Flexibility across architectures and use cases.
❌ Missed Opportunity : Many distillation methods only work well within homogeneous architectures.
7. Supports End-to-End Training Without Heuristic Design Choices
Earlier distillation methods often relied on heuristic design decisions and task-specific normalization layers. These choices could limit adaptability and introduce bias.
MoKD avoids these pitfalls by enabling end-to-end training with minimal architectural assumptions, making it easier to integrate into existing pipelines.
✅ Benefit : Plug-and-play compatibility with modern frameworks.
❌ Missed Opportunity : Heuristic-based approaches are harder to maintain and scale.
Real-World Applications of MoKD
MoKD isn’t just an academic breakthrough—it has practical implications for industries leveraging AI at scale:
| INDUSTRY | USE CASE | BENIFIT |
|---|---|---|
| Healthcare | Medical image analysis on mobile devices | Accurate diagnosis with lightweight models |
| Retail | Real-time product recognition in stores | Faster inference on edge devices |
| Autonomous Vehicles | Object detection for navigation | Low-latency perception systems |
| EdTech | Personalized learning apps | Efficient AI models on low-power hardware |
How to Implement MoKD in Your Projects
Implementing MoKD requires integrating the following components into your training pipeline:
✅ Step 1: Choose Your Teacher and Student Models
Select a high-capacity teacher model (e.g., RegNetY-160, ViDT-base) and a compact student model (e.g., DeiT-tiny, ViDT-nano).
✅ Step 2: Integrate the Subspace Projection Module
Add the plug-and-play projector module to align the feature spaces of both models. This can be done without altering the student model’s architecture.
✅ Step 3: Reformulate Loss Optimization
Replace fixed-weight loss combinations with MoKD’s multi-objective optimizer. This will dynamically adjust the importance of distillation and task-specific losses.
✅ Step 4: Train and Evaluate
Train the model end-to-end using PyTorch or TensorFlow. Evaluate performance on standard benchmarks like ImageNet and COCO.
If you’re Interested in deep learning based self-distillation model, you may also find this article helpful: 7 Revolutionary Ways FiGKD is Transforming Knowledge Distillation (and 1 Major Drawback)
Conclusion: Why You Should Be Using MoKD Today
MoKD represents a paradigm shift in knowledge distillation. By addressing gradient conflicts, eliminating manual tuning, and enhancing feature alignment, it enables faster, more accurate, and more scalable model compression.
If you’re still using traditional distillation techniques, you’re likely leaving performance gains on the table. Whether you’re working on image classification, object detection, or any vision-based AI application, MoKD offers a smarter, more efficient way to build deployable models.
Ready to Supercharge Your AI Models?
Don’t miss out on the future of knowledge distillation. Start experimenting with MoKD today and see how much faster and more accurately you can train compact models.
👉 Download the full paper here
👉 Try MoKD in your next project and share your results below!
Have questions about implementation or want to contribute to open-source distillation tools? Join our community forum and connect with fellow AI practitioners.
Call to Action:
Are you already using MoKD in your workflow? Share your experience in the comments below!
Want to stay updated on the latest AI research and optimization techniques? Subscribe to our newsletter for weekly insights and tutorials.
To implement the MoKD (Multi-Task Optimization for Knowledge Distillation) model as described in the paper, we need to address two core components: multi-task optimization to balance distillation and task losses, and subspace learning to align teacher and student features. Below is the PyTorch implementation:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Optimizer
class MoKD(nn.Module):
def __init__(self, teacher, student, n_dim=128):
"""
Args:
teacher: Pre-trained teacher model (frozen)
student: Student model to be distilled
n_dim: Dimension of the shared subspace
"""
super().__init__()
self.teacher = teacher
self.student = student
# Freeze teacher parameters
for param in self.teacher.parameters():
param.requires_grad = False
# Get feature dimensions
teacher_dim = teacher.feature_dim
student_dim = student.feature_dim
# Subspace projection matrices (orthogonal initialization)
self.P_t = nn.Parameter(torch.empty(teacher_dim, n_dim))
self.P_s = nn.Parameter(torch.empty(student_dim, n_dim))
nn.init.orthogonal_(self.P_t)
nn.init.orthogonal_(self.P_s)
# Diagonal matrix for indefinite metric
self.D = nn.Parameter(torch.ones(n_dim))
# Task loss weighting parameters (logits for softmax)
self.logit_pi = nn.Parameter(torch.zeros(2)) # [distill, task]
def project_features(self, teacher_feats, student_feats):
"""Project features to shared subspace using Eq (16)"""
projected_teacher = torch.matmul(teacher_feats, self.P_t)
projected_student = torch.matmul(student_feats, self.P_s)
return projected_teacher, projected_student
def compute_similarity(self, projected_teacher, projected_student):
"""Compute feature similarity using indefinite metric (Eq 16)"""
return torch.sum(projected_teacher * self.D * projected_student, dim=1)
def forward(self, x):
# Teacher forward (frozen)
with torch.no_grad():
t_feats, t_logits = self.teacher(x, return_features=True)
# Student forward
s_feats = self.student.backbone(x)
s_logits = self.student.head(s_feats)
# Subspace projection
proj_t, proj_s = self.project_features(t_feats, s_feats)
return {
't_logits': t_logits,
's_logits': s_logits,
'proj_t': proj_t,
'proj_s': proj_s
}
def compute_losses(self, outputs, y):
# Distillation losses
s_logits = outputs['s_logits']
t_logits = outputs['t_logits']
proj_t = outputs['proj_t']
proj_s = outputs['proj_s']
# KL divergence for logits
L_kl = F.kl_div(
F.log_softmax(s_logits, dim=1),
F.softmax(t_logits, dim=1),
reduction='batchmean'
)
# Feature similarity loss
similarity = self.compute_similarity(proj_t, proj_s)
L_sim = -torch.mean(similarity) # Maximize similarity
# Total distillation loss
L_distill = L_kl + L_sim
# Task loss
L_task = F.cross_entropy(s_logits, y)
return L_distill, L_task
def compute_weighted_loss(self, L_distill, L_task):
"""Compute multi-task loss with adaptive weights (FAMO algorithm)"""
# Get task weights via softmax
pi_weights = F.softmax(self.logit_pi, dim=0)
# Log losses for numerical stability
log_L_distill = torch.log(L_distill + 1e-8)
log_L_task = torch.log(L_task + 1e-8)
# Combined loss (Eq 15)
loss_total = pi_weights[0] * log_L_distill + pi_weights[1] * log_L_task
return loss_total, pi_weights
class MoKDOptimizer(Optimizer):
"""Optimizer implementing FAMO algorithm for MoKD"""
def __init__(self, model_params, pi_params, lr=1e-3, lr_pi=1e-2):
defaults = {'lr': lr}
super().__init__(model_params, defaults)
self.pi_params = pi_params
self.lr_pi = lr_pi
@torch.no_grad()
def step(self, loss_total, L_distill, L_task, pi_weights, closure=None):
# Update model parameters
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
p.add_(p.grad, alpha=-group['lr'])
# Update pi parameters (Eq 15)
log_L_distill = torch.log(L_distill + 1e-8)
log_L_task = torch.log(L_task + 1e-8)
# Compute gradient for pi
grad_pi = loss_total * torch.stack([log_L_distill, log_L_task])
# Update logit_pi
self.pi_params.data.add_(grad_pi, alpha=-self.lr_pi)
# Renormalize using softmax
new_weights = F.softmax(self.pi_params, dim=0)
self.pi_params.data.copy_(torch.log(new_weights + 1e-8))Training Loop Pseudocode:
model = MoKD(teacher, student)
opt_model = MoKDOptimizer(
model.student.parameters(),
model.logit_pi,
lr=0.001,
lr_pi=0.01
)
for x, y in dataloader:
# Forward pass
outputs = model(x)
L_distill, L_task = model.compute_losses(outputs, y)
# Compute weighted loss
loss_total, pi_weights = model.compute_weighted_loss(L_distill, L_task)
# Backpropagation
loss_total.backward()
# Update parameters
opt_model.step(loss_total, L_distill, L_task, pi_weights)
# Zero gradients
opt_model.zero_grad()Post-Training:
# Save distilled student
torch.save(model.student.state_dict(), 'distilled_student.pth')
# For deployment:
final_student = StudentModel()
final_student.load_state_dict(torch.load('distilled_student.pth'))
Pingback: 🔥 7 Breakthrough Lessons from EmoVLM-KD: How Combining AI Models Can Dramatically Boost Emotion Recognition AI Accuracy - aitrendblend.com