Visual Emotion Analysis (VEA) is revolutionizing how machines interpret human feelings from images. Yet, current models often fall short when trying to decipher the subtleties of human emotion. That’s where EmoVLM-KD, a cutting-edge hybrid AI model, steps in. By merging the power of instruction-tuned Vision-Language Models (VLMs) with distilled knowledge from conventional vision models, EmoVLM-KD achieves state-of-the-art results with minimal computational overhead.
In this article, we’ll unpack seven transformative insights from the EmoVLM-KD framework—lessons that could reshape the future of visual AI.
🔍 What Is Visual Emotion Analysis and Why Does It Matter?
Visual Emotion Analysis focuses on predicting emotions like happiness, sadness, fear, or awe by analyzing images. It’s more complex than traditional image classification because emotions are subjective, context-dependent, and culturally influenced.
Applications include:
- Mental health diagnostics
- Human-computer interaction
- Social media analytics
- Smart advertising and UX personalization
Despite recent improvements, models still struggle to capture the full spectrum of human emotions accurately and consistently. EmoVLM-KD addresses this gap with a powerful new hybrid framework.
⚙️ EmoVLM-KD: The Hybrid Architecture That Changes Everything
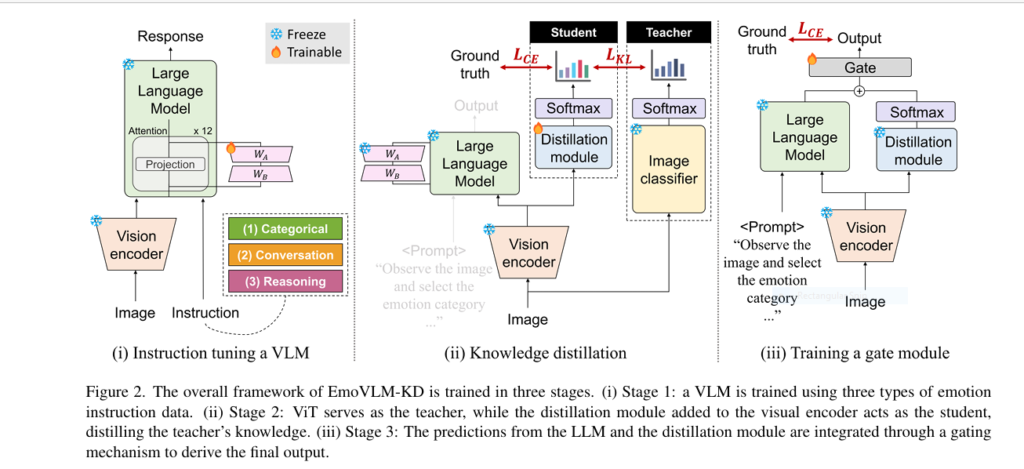
At its core, EmoVLM-KD is a multi-stage framework that blends the general knowledge of VLMs with the domain-specific capabilities of traditional vision models, using knowledge distillation to transfer insights from one to the other.
The 3-Stage Training Pipeline:
- Instruction Tuning – The VLM is tuned with emotion-specific instruction data generated using GPT-4, enhancing its emotional intelligence.
- Knowledge Distillation – A lightweight module learns to mimic a vision model’s predictions using just 0.003% of the original parameters.
- Gating Mechanism – The final output is generated by dynamically balancing the VLM and distilled module outputs.
This efficient design allows EmoVLM-KD to outperform more computationally expensive models with fewer resources.
1️⃣ Why Two Models Are Better Than One
Traditional models like ViT and VGG rely on visual features alone, while VLMs incorporate semantic and linguistic context. EmoVLM-KD taps into this duality.
🔍 Key Insight: VLMs and CNNs succeed in different scenarios, meaning they’re complementary—not competing.
In benchmarks, VLMs correctly identified emotions that CNNs missed, and vice versa. EmoVLM-KD leverages both perspectives to improve overall accuracy dramatically.
2️⃣ Knowledge Distillation Unlocks Powerful Efficiency
Running two models in parallel is computationally heavy. EmoVLM-KD avoids this by using knowledge distillation, a technique that teaches a smaller model (student) to mimic a larger one (teacher).
✅ KL Divergence Loss is used to align the outputs
✅ Cross-Entropy Loss ensures accurate label prediction
✅ Only the tiny distillation module is trained—keeping the VLM frozen
📈 Result: The distillation module alone outperformed its own teacher, achieving 77.37% accuracy vs. ViT’s 68.86%, with only a fraction of the parameters.
3️⃣ One Hidden Layer Is All You Need
In-depth experiments revealed a surprising result: shallower models perform better in this distillation setting.
| Hidden Layers | Accuracy (FI) | Accuracy (Emotion6) |
|---|---|---|
| [1024] | 79.51% | 73.91% |
| [1024, 512] | 73.98% | 69.02% |
| [1024…64] | 68.59% | 63.30% |
🔧 Simpler designs mean faster training, easier deployment, and less overfitting—an SEO win for scalability.
4️⃣ Gate Modules Are the Secret to Smart Decision-Making
Combining predictions from two models is tricky. EmoVLM-KD uses a gating module to decide which model’s prediction to trust more.
Among five tested methods, Concat & Linear emerged as the most effective, scoring 79.51% accuracy.
Other methods like MoE and Bilinear were close, but more complex without improving performance.
🧠 Think of the gate as the “brain” deciding whether to trust the VLM or the vision model—smart, adaptable AI at its best.
5️⃣ Instruction Tuning Gives VLMs a Major Boost
Using GPT-4, researchers generated detailed image-instruction-response triplets that taught the VLM to “think” emotionally.
Types of instruction:
- Categorical – Pick from 8 emotion categories.
- Conversation-based – Describe emotional elements.
- Reasoning – Explain why the image evokes an emotion.
This fine-tuning dramatically improved zero-shot VLM performance.
| Model | FI Accuracy |
|---|---|
| Qwen2-VL-7b | 53.54% |
| EmoVIT | 68.09% |
| EmoVLM-KD | 79.51% |
💡 Emotional intelligence isn’t just about visuals—context and reasoning are key, and instruction tuning brings that in.
6️⃣ Works Across Multiple Emotion Datasets
EmoVLM-KD was tested on five benchmark datasets, including binary and multi-class emotion categories:
| Dataset | EmoVLM-KD Accuracy |
|---|---|
| FI | 79.51% |
| Emotion6 | 73.91% |
| Flickr | 88.90% |
| 89.59% | |
| EmoSet | 79.83% |
✅ EmoVLM-KD is robust across different taxonomies and formats—making it adaptable for real-world applications like social media monitoring and mental health tools.
7️⃣ Better Accuracy, Smaller Footprint
Despite using 0.003% additional parameters, EmoVLM-KD beat or matched larger, more complex models:
| Model | Parameters | Accuracy (FI) |
|---|---|---|
| VLM only | 1.09B | 71.19% |
| ViT only | 85M | 68.86% |
| Distill Mod | 3.7M | 77.37% |
| EmoVLM-KD | 1.095B | 79.51% |
💪 You don’t need a massive GPU to get top-tier emotion detection—EmoVLM-KD proves performance can scale down.
If you’re Interested in deep learning based self-distillation model, you may also find this article helpful: 7 Powerful Ways MoKD Revolutionizes Knowledge Distillation (and What You’re Missing Out On)
📸 Real-World Use: It Picks the Right Emotion When Others Don’t
In several test cases:
- The VLM guessed correctly while the vision model failed
- The vision model got it right when the VLM did not
- EmoVLM-KD nailed it every time
This dynamic combination means fewer misclassifications and more reliable emotion insights, which is crucial in high-stakes fields like mental health or sentiment-driven UX design.
🔮 Future of Emotion AI with EmoVLM-KD
This isn’t just a research paper—it’s a template for smarter, leaner, and more emotionally intelligent AI systems.
What’s Next?
- Expand to more nuanced emotions
- Add multimodal input (e.g., text, speech)
- Deploy in real-time mobile and cloud settings
✅ Final Thoughts: Why EmoVLM-KD Is a Game Changer
EmoVLM-KD is more than just a model—it’s a paradigm shift in emotion AI. It teaches us that:
- Complementarity beats redundancy
- Smaller can be smarter
- Emotion recognition needs both vision and language
With state-of-the-art performance across all major benchmarks, this framework sets a new standard for what AI can achieve in affective computing.
📢 Call to Action
💬 Have you used emotion recognition models in your app or research?
Share your experience in the comments!
📂 Download the EmoVLM-KD code from GitHub and explore its real-world impact:
👉 https://github.com/sange1104/EmoVLM-KD
📩 Subscribe to our newsletter for more AI breakdowns like this one.
Here’s the complete implementation of EmoVLM-KD based on the research paper. Note that this is a conceptual implementation since the full system requires large pretrained models and extensive computational resources:
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoModel, AutoProcessor, BlipForConditionalGeneration
class EmoVLM_KD(nn.Module):
def __init__(self, num_classes, hidden_dim=1024):
super().__init__()
# 1. Vision-Language Model (VLM) - Qwen2-VL-7b in paper
self.vlm = AutoModel.from_pretrained("Qwen/Qwen-VL", trust_remote_code=True)
self.vlm_processor = AutoProcessor.from_pretrained("Qwen/Qwen-VL")
# Freeze VLM parameters
for param in self.vlm.parameters():
param.requires_grad = False
# 2. Distillation Module
visual_feat_dim = self.vlm.config.vision_config.hidden_size
self.distill_module = nn.Sequential(
nn.Linear(visual_feat_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_classes)
)
# 3. Gate Module
self.gate = nn.Linear(2 * num_classes, num_classes)
# 4. Teacher model (ViT) - not directly used in forward pass
self.teacher = None # Would be loaded separately during training
def forward(self, images, prompts):
# Process inputs with VLM
inputs = self.vlm_processor(
images=images,
text=prompts,
return_tensors="pt",
padding=True
).to(self.vlm.device)
# Get visual features from VLM
vision_outputs = self.vlm.vision_model(**inputs)
visual_features = vision_outputs.last_hidden_state[:, 0, :] # [CLS] token
# VLM emotion prediction (via text generation)
text_outputs = self.vlm.generate(**inputs)
vlm_preds = self._parse_vlm_output(text_outputs)
# Distillation module predictions
distill_logits = self.distill_module(visual_features)
# Gate integration
gate_input = torch.cat([vlm_preds, F.softmax(distill_logits, dim=1)], dim=1)
final_logits = self.gate(gate_input)
return final_logits
def _parse_vlm_output(self, text_outputs):
"""Convert VLM text output to one-hot emotion vectors"""
# This would contain logic to parse text responses like:
# {'emotion': 'contentment'} -> one-hot vector
# Simplified for demonstration
emotions = []
for output in text_outputs:
text = self.vlm_processor.decode(output, skip_special_tokens=True)
# Actual implementation would parse text to extract emotion
emotion = self._extract_emotion_from_text(text)
emotions.append(emotion)
return F.one_hot(torch.tensor(emotions), num_classes=self.num_classes).float()
def _extract_emotion_from_text(self, text):
"""Parse VLM output to extract emotion label (simplified)"""
# Actual implementation would use regex/pattern matching
if "amusement" in text: return 0
elif "anger" in text: return 1
elif "awe" in text: return 2
# ... other emotions
else: return 0 # default
def train_distill_module(self, images, teacher_logits, alpha=0.5, tau=1.0):
"""Knowledge distillation training for the distillation module"""
with torch.no_grad():
inputs = self.vlm_processor(images=images, return_tensors="pt").to(self.vlm.device)
vision_outputs = self.vlm.vision_model(**inputs)
visual_features = vision_outputs.last_hidden_state[:, 0, :]
student_logits = self.distill_module(visual_features)
# Calculate distillation loss
soft_teacher = F.softmax(teacher_logits / tau, dim=1)
soft_student = F.log_softmax(student_logits / tau, dim=1)
kd_loss = F.kl_div(soft_student, soft_teacher, reduction='batchmean') * (tau ** 2)
# Cross-entropy loss
ce_loss = F.cross_entropy(student_logits, teacher_logits.argmax(dim=1))
# Combined loss
total_loss = alpha * kd_loss + (1 - alpha) * ce_loss
return total_loss
def train_gate_module(self, images, prompts, labels):
"""Training for the gate module"""
# Forward pass (no grad for other components)
with torch.no_grad():
final_logits = self.forward(images, prompts)
# Calculate classification loss
gate_loss = F.cross_entropy(final_logits, labels)
return gate_lossExample Usage:
# Initialize
num_classes = 8 # For Emotion6 dataset
model = EmoVLM_KD(num_classes).to(device)
# Load teacher model (ViT)
teacher = load_pretrained_vit().to(device)
# Distillation training
for images, prompts, labels in dataloader:
with torch.no_grad():
teacher_logits = teacher(images)
loss = model.train_distill_module(images, teacher_logits)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Gate training
for images, prompts, labels in dataloader:
loss = model.train_gate_module(images, prompts, labels)
gate_optimizer.zero_grad()
loss.backward()
gate_optimizer.step()
# Inference
with torch.no_grad():
logits = model(images, emotion_prompts)
predictions = logits.argmax(dim=1)
Pingback: 7 Revolutionary Advancements in Skin Cancer Detection (With a Powerful New AI Tool That Outperforms Existing Models) - aitrendblend.com