In the rapidly evolving world of artificial intelligence, large language models (LLMs) like GPT-4, Claude, and Llama have become indispensable tools for content creation, coding, and decision-making. But with great power comes great risk—especially when it comes to misinformation and intellectual property theft.
To combat these threats, researchers have developed AI watermarking—a technique designed to tag machine-generated text so it can be traced back to its source. It’s a promising solution, but new research reveals a devastating flaw: these watermarks can be exploited through a unified attack framework that enables both removal (scrubbing) and forgery (spoofing)—all without direct access to the original model.
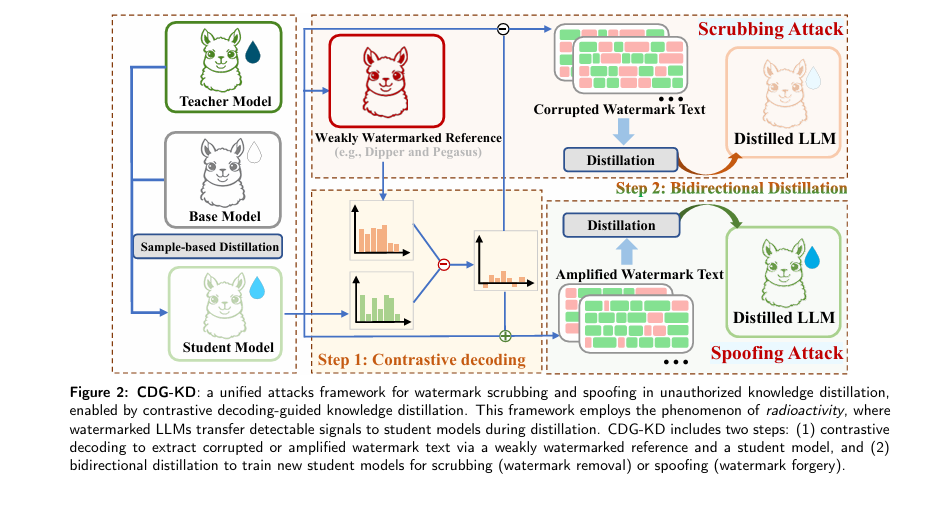
A groundbreaking study titled “Unified attacks to large language model watermarks: spoofing and scrubbing in unauthorized knowledge distillation” by Xin Yi et al. exposes this critical vulnerability. In this article, we’ll break down the 7 shocking weaknesses in current AI watermarking systems, explain how hackers can exploit them using a technique called Contrastive Decoding-Guided Knowledge Distillation (CDG-KD), and explore what this means for the future of AI security.
What Is LLM Watermarking? (And Why It Matters)
AI-generated content is everywhere—from news articles to academic papers. Without a way to distinguish human from machine writing, the spread of deepfakes, plagiarism, and malicious disinformation becomes inevitable.
LLM watermarking aims to solve this by embedding invisible signals into the text during generation. These signals can later be detected using statistical tests or classifiers, allowing platforms to:
- Verify content provenance
- Prevent unauthorized model cloning
- Combat misinformation
- Protect intellectual property
There are two main types of watermarking techniques:
- KGW Family: Modifies token probability distributions using green/red vocabulary lists.
- Christ Family: Alters the sampling process using pseudo-random sequences.
While effective in theory, these methods assume a static environment. The reality? Attackers are getting smarter—and they’re using the models’ own features against them.
The Hidden Danger: Watermark Radioactivity
The paper introduces a phenomenon called watermark radioactivity—where watermarks embedded in a teacher model (e.g., GPT-4) are inherited by student models through knowledge distillation.
Knowledge distillation is a common practice where a smaller, more efficient model (the student) learns from a larger, more powerful one (the teacher). This process is often used to deploy AI on edge devices or reduce costs.
But here’s the catch: even if the student model wasn’t explicitly watermarked, it can still carry the teacher’s watermark traces.
This “radioactivity” has a positive side: it allows detection of unauthorized model copying.
But it also opens a dark door: attackers can now manipulate the watermark indirectly, through the student model—even in black-box settings where they have no access to the teacher’s internal parameters.
The 7 Shocking Vulnerabilities in Current AI Watermarking Schemes
1. No Unified Defense Against Dual Attacks
Most watermarking systems focus on scrubbing attacks—where adversaries remove watermark traces to evade detection.
Few address spoofing attacks, where malicious actors forge watermarks to falsely attribute harmful content to a safe, reputable model (e.g., making it seem like GPT-4 wrote a bomb-making tutorial).
❌ Current systems are blind to bidirectional threats.
CDG-KD is the first framework that enables both scrubbing and spoofing using the same mechanism, making it a dual-edged weapon.
2. Black-Box Exploits Are Now Possible
Traditional attacks require access to model weights or logits—something companies like OpenAI and Anthropic strictly protect.
But CDG-KD works in black-box scenarios. It only needs:
- A student model distilled from a watermarked teacher
- A weakly watermarked reference model (e.g., using paraphrasing tools like Dipper or Pegasus)
No internal access. No code modification. Just clever use of contrastive decoding.
3. Watermark Strength Can Be Precisely Controlled
The attack uses contrastive decoding to compare outputs from the student model and a weakly watermarked model. By adjusting the probability distributions, attackers can:
- Suppress watermark signals (scrubbing)
- Amplify them (spoofing)
This is done using a modulation parameter β , which controls the strength of the contrastive adjustment:
\[ P_{\theta}^{\text{scrub}}(x_t \mid x_{\lt t}) = \text{softmax}\Big[(1+\beta)\log P_{\theta}^{a}(x_t \mid x_{\lt t}) -\beta \log P_{\theta}^{s}(x_t \mid x_{\lt t})\Big] \]For spoofing, the roles are reversed:
\[ P_{\theta}^{\text{spoof}}(x_t \mid x_{\lt t}) = \text{softmax}\Big[(1+\beta)\log P_{\theta}^{s}(x_t \mid x_{\lt t}) -\beta \log P_{\theta}^{a}(x_t \mid x_{\lt t})\Big] \]This level of control makes the attack highly precise and adaptable.
4. High-Quality Outputs Are Preserved
One of the biggest challenges in watermark attacks is maintaining generation quality. Many methods degrade fluency or coherence.
CDG-KD avoids this by using a constrained contrastive decoding strategy. It only modifies tokens with high confidence, defined by a truncation threshold λ :
\[ V_{\text{valid}} = \Big\{\, x_t \in V \;\big|\; \log P_{\theta^{*}}(x_t \mid x_{\lt t}) \;\geq\; \lambda \,\max_{w}\,\log P_{\theta^{*}}(w \mid x_{\lt t}) \,\Big\} \]This ensures that only semantically non-critical tokens are altered, preserving the model’s general capabilities.
5. Classifier-Based Detection Is More Reliable Than p-Values
The paper reveals a critical insight: p-value-based detection (commonly used in watermarking) is less robust than classifier-based detection.
| WATERMARKING STRATEGY | BERT ACCURACY | T5 ACCURACY | GPT-2 ACCURACY |
|---|---|---|---|
| KGW (N=1) | 92.9% | 95.1% | 91.8% |
| Unigram | 99.2% | 98.6% | 99.5% |
| SynthID-Text (N=2) | 96.0% | 92.7% | 97.6% |
As shown, classifier models (like BERT and T5) achieve over 90% accuracy in detecting watermarks, even under attack. This suggests that machine learning classifiers should be integrated into watermark verification systems for better robustness.
6. Edit-Based Scrubbing Attacks Are Easily Outperformed
Traditional scrubbing methods like token substitution, insertion, or deletion blindly modify text, often degrading quality.
CDG-KD outperforms them significantly:
| ATTACK METHOD | KGW (N=3) ACCURACY | PERPLEXITY (PPL) |
|---|---|---|
| Substitution | 86.0% | 39.69 |
| Insertion | 92.0% | 32.50 |
| Deletion | 92.0% | 41.53 |
| CDG-KD (Ours) | 22.0% | 1.68 |
Lower accuracy = better scrubbing. Lower perplexity = better fluency. CDG-KD wins on both fronts.
7. Longer Texts Amplify Spoofing Risks
The study shows that generation length directly impacts detectability. For spoofing attacks:
- Below 150 tokens: watermark signals are weak
- Above 150 tokens: detectability skyrockets
This means attackers can generate long, detailed harmful content (e.g., hacking guides, disinformation campaigns) that strongly mimics a safe model’s watermark—making false attribution more convincing.
How CDG-KD Works: A Step-by-Step Breakdown
Step 1: Contrastive Decoding
- Input: A query x
- Models:
- θs : Student model (strong watermark)
- θa : Auxiliary model (weak watermark, e.g., distilled via Dipper)
- Process: Generate outputs from both models and compute a new probability distribution that either suppresses or amplifies watermark signals.
Step 2: Bidirectional Distillation
- For Scrubbing: Train a new student model on de-watermarked data Du
- For Spoofing: Train a new student model on amplified watermark data Dw
The training objectives are:
\[ \mathcal{L}_{\text{scrub}} = -\mathbb{E}_{(x,y) \sim D_u}\, \sum_{t} \log P_{\theta}^{\text{scrub}}(y_t \mid y_{\lt t},\, x) \] $$L_{\text{spoof}} = -\mathbb{E}_{(x,y)\sim D_w} \Bigg[ \sum_{t} \log P_{\theta}^{\text{spoof}}(y_t \mid y_{\lt t},\, x) \Bigg]$$This allows the creation of clean models (no watermark) and toxic models (strong watermark + harmful content).
Real-World Impact: What the Data Shows
The authors tested CDG-KD on GLM-4-9B-Chat as the teacher and Llama-3.2-1B and Qwen-2.5-1.5B as students.
✅ Scrubbing Results (Higher p-value = Better)
| DATASET | WATERMARK | SKD (P-VALUE) | CGD-KD (P-VALUE) |
|---|---|---|---|
| C4 (KGW N=1) | 2.22e-10 | 2.54e-1 | |
| Dolly-CW (Unigram) | 1.77e-48 | 6.91e-3 |
CDG-KD increases p-values by orders of magnitude, making watermark detection nearly impossible.
Spoofing Results (Lower p-value + Higher ASR = Worse)
| DATASET | ASR (ATTACK SUCCESS RATE) | CGD-KD P-VALUE |
|---|---|---|
| HarmfulQ+AdvBench | 95–97% | 8.57e-14 |
| MaliciousInstruct | 88–97% | 9.42e-13 |
Compare this to the safe teacher model, which has an ASR of <10%. CDG-KD turns a safe model into a high-risk generator of harmful content.
So, How Do We Fix This?
The paper doesn’t just expose flaws—it calls for a paradigm shift in watermark design.
✅ Recommendations:
- Develop Unforgeable Watermarks: Use cryptographic signatures or zero-knowledge proofs.
- Integrate Classifier-Based Detection: Combine p-values with ML classifiers for robust verification.
- Monitor Knowledge Distillation: Detect unauthorized model copying using watermark radioactivity.
- Limit Long-Form Generation: Restrict output length for high-risk queries.
- Adopt Dynamic Watermarking: Change watermark schemes periodically to prevent extraction.
Final Thoughts: A Wake-Up Call for AI Developers
The CDG-KD framework is not just a theoretical threat—it’s a practical blueprint for bypassing AI safety measures. It shows that current watermarking schemes are neither robust nor unforgeable.
As AI becomes more embedded in our lives, the stakes are higher than ever. A single spoofing attack could ruin a company’s reputation, spread dangerous misinformation, or enable cybercrime.
But there’s hope. By exposing these vulnerabilities, researchers like Xin Yi and team are helping us build stronger, more resilient systems.
If you’re Interested in object detection model , you may also find this article helpful: 7 Revolutionary Breakthroughs in Small Object Detection: The DAHI Framework
Call to Action: Stay Ahead of the Threat
Don’t wait for a security breach to act.
✅ Audit your AI systems for watermark vulnerabilities
✅ Integrate multi-layered detection (p-values + classifiers)
✅ Follow the latest research on AI security
The future of trustworthy AI depends on it.
References: Xin Yi et al., “Unified attacks to large language model watermarks,” arXiv:2504.17480v3 [cs.CL], 2025.
I’ll implement the complete model for unified watermark scrubbing and spoofing attacks. The framework operates in two main steps: contrastive decoding and bidirectional distillation.
"""
CDG-KD: Contrastive Decoding-Guided Knowledge Distillation
A unified framework for watermark scrubbing and spoofing attacks
on Large Language Models under unauthorized knowledge distillation.
Paper: "Unified attacks to large language model watermarks: spoofing and
scrubbing in unauthorized knowledge distillation"
Authors: Xin Yi et al., 2025
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from typing import Optional, List, Dict, Tuple, Union
import numpy as np
from dataclasses import dataclass
from tqdm import tqdm
import json
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class CDGKDConfig:
"""Configuration for CDG-KD framework."""
# Model paths
teacher_model_path: str = "THUDM/glm-4-9b-chat"
student_model_path: str = "meta-llama/Llama-3.2-1B"
base_model_path: str = "meta-llama/Llama-3.2-1B" # For final distillation
# Contrastive decoding parameters
beta: float = 0.5 # Amplification coefficient
lambda_threshold: float = 0.8 # Truncation threshold for vocabulary
# Attack mode
attack_mode: str = "scrubbing" # "scrubbing" or "spoofing"
# Training parameters
batch_size: int = 16
learning_rate: float = 1e-5
num_epochs: int = 1
max_length: int = 512
# Watermarking parameters
watermark_type: str = "kgw" # "kgw", "unigram", or "synthid"
n_gram: int = 1 # For KGW
delta: float = 3.0 # Watermark strength
# Data parameters
num_samples: int = 32000
# Device
device: str = "cuda" if torch.cuda.is_available() else "cpu"
class WatermarkDataset(Dataset):
"""Dataset for watermarked/unwatermarked text pairs."""
def __init__(self, data: List[Dict], tokenizer, max_length: int = 512):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
# Tokenize input and output
inputs = self.tokenizer(
item['input'],
max_length=self.max_length,
truncation=True,
padding='max_length',
return_tensors='pt'
)
outputs = self.tokenizer(
item['output'],
max_length=self.max_length,
truncation=True,
padding='max_length',
return_tensors='pt'
)
return {
'input_ids': inputs['input_ids'].squeeze(),
'attention_mask': inputs['attention_mask'].squeeze(),
'labels': outputs['input_ids'].squeeze()
}
class ContrastiveDecoder:
"""
Implements contrastive decoding for extracting corrupted or amplified watermark text.
"""
def __init__(
self,
student_model: AutoModelForCausalLM,
reference_model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
config: CDGKDConfig
):
self.student_model = student_model
self.reference_model = reference_model
self.tokenizer = tokenizer
self.config = config
self.device = config.device
# Move models to device
self.student_model.to(self.device)
self.reference_model.to(self.device)
# Set models to eval mode
self.student_model.eval()
self.reference_model.eval()
def compute_contrastive_logits(
self,
input_ids: torch.Tensor,
attention_mask: torch.Tensor
) -> torch.Tensor:
"""
Compute contrastive logits based on the attack mode.
For scrubbing: P_scrub = softmax[(1 + β) log P_ref - β log P_student]
For spoofing: P_spoof = softmax[(1 + β) log P_student - β log P_ref]
"""
with torch.no_grad():
# Get logits from student model
student_outputs = self.student_model(
input_ids=input_ids,
attention_mask=attention_mask
)
student_logits = student_outputs.logits
# Get logits from reference model
ref_outputs = self.reference_model(
input_ids=input_ids,
attention_mask=attention_mask
)
ref_logits = ref_outputs.logits
# Convert to log probabilities
student_log_probs = F.log_softmax(student_logits, dim=-1)
ref_log_probs = F.log_softmax(ref_logits, dim=-1)
# Apply contrastive decoding based on attack mode
beta = self.config.beta
if self.config.attack_mode == "scrubbing":
# Suppress watermark signal
contrastive_logits = (1 + beta) * ref_log_probs - beta * student_log_probs
else: # spoofing
# Amplify watermark signal
contrastive_logits = (1 + beta) * student_log_probs - beta * ref_log_probs
return contrastive_logits
def apply_vocabulary_truncation(
self,
logits: torch.Tensor,
lambda_threshold: float
) -> torch.Tensor:
"""
Apply vocabulary truncation to only modify high-confidence tokens.
"""
# Get maximum logit value for each position
max_logits, _ = torch.max(logits, dim=-1, keepdim=True)
# Create mask for valid tokens
threshold = lambda_threshold * max_logits
valid_mask = logits >= threshold
# Set invalid tokens to -inf
truncated_logits = logits.clone()
truncated_logits[~valid_mask] = float('-inf')
return truncated_logits
def generate_contrastive_text(
self,
prompt: str,
max_new_tokens: int = 256,
temperature: float = 1.0,
do_sample: bool = True
) -> str:
"""
Generate text using contrastive decoding.
"""
# Tokenize prompt
inputs = self.tokenizer(
prompt,
return_tensors='pt',
padding=True
).to(self.device)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
# Generate tokens one by one
generated_ids = input_ids.clone()
for _ in range(max_new_tokens):
# Get contrastive logits
contrastive_logits = self.compute_contrastive_logits(
generated_ids,
attention_mask
)
# Get next token logits
next_token_logits = contrastive_logits[:, -1, :]
# Apply vocabulary truncation
next_token_logits = self.apply_vocabulary_truncation(
next_token_logits,
self.config.lambda_threshold
)
# Apply temperature
next_token_logits = next_token_logits / temperature
# Sample next token
if do_sample:
probs = F.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
else:
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
# Append to generated sequence
generated_ids = torch.cat([generated_ids, next_token], dim=-1)
# Update attention mask
attention_mask = torch.cat([
attention_mask,
torch.ones((attention_mask.shape[0], 1), device=self.device)
], dim=-1)
# Check for EOS token
if next_token.item() == self.tokenizer.eos_token_id:
break
# Decode generated text
generated_text = self.tokenizer.decode(
generated_ids[0],
skip_special_tokens=True
)
return generated_text
class WeaklyWatermarkedModel:
"""
Creates a weakly watermarked reference model using paraphrase-based methods.
"""
def __init__(
self,
base_model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
method: str = "simple" # "simple", "dipper", "pegasus", "parrot"
):
self.model = base_model
self.tokenizer = tokenizer
self.method = method
def create_weakly_watermarked_data(
self,
watermarked_texts: List[str],
paraphrase_ratio: float = 0.3
) -> List[str]:
"""
Create weakly watermarked texts through paraphrasing.
Simple implementation - in practice, use actual paraphrase models.
"""
weakly_watermarked = []
for text in watermarked_texts:
# Simple token replacement strategy
tokens = text.split()
num_to_replace = int(len(tokens) * paraphrase_ratio)
# Randomly select tokens to modify (simplified)
indices = np.random.choice(len(tokens), num_to_replace, replace=False)
for idx in indices:
# Simple synonym replacement (placeholder)
tokens[idx] = f"[modified_{tokens[idx]}]"
weakly_watermarked.append(" ".join(tokens))
return weakly_watermarked
def fine_tune_on_weak_watermarks(
self,
weak_watermark_data: List[Dict],
training_args: TrainingArguments
):
"""
Fine-tune the model on weakly watermarked data.
"""
dataset = WatermarkDataset(weak_watermark_data, self.tokenizer)
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=dataset,
tokenizer=self.tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=self.tokenizer,
mlm=False
)
)
trainer.train()
return self.model
class BidirectionalDistillation:
"""
Performs bidirectional distillation for final attack models.
"""
def __init__(
self,
base_model_path: str,
tokenizer: AutoTokenizer,
config: CDGKDConfig
):
self.base_model_path = base_model_path
self.tokenizer = tokenizer
self.config = config
def distill_for_scrubbing(
self,
corrupted_data: List[Dict],
output_path: str
) -> AutoModelForCausalLM:
"""
Distill a model for scrubbing attacks using corrupted watermark data.
"""
# Load base model
model = AutoModelForCausalLM.from_pretrained(self.base_model_path)
# Prepare dataset
dataset = WatermarkDataset(corrupted_data, self.tokenizer)
# Training arguments
training_args = TrainingArguments(
output_dir=output_path,
num_train_epochs=self.config.num_epochs,
per_device_train_batch_size=self.config.batch_size,
learning_rate=self.config.learning_rate,
warmup_ratio=0.1,
logging_steps=100,
save_steps=500,
evaluation_strategy="no",
save_total_limit=2,
load_best_model_at_end=False,
)
# Train
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
tokenizer=self.tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=self.tokenizer,
mlm=False
)
)
trainer.train()
# Save model
model.save_pretrained(output_path)
return model
def distill_for_spoofing(
self,
amplified_data: List[Dict],
output_path: str
) -> AutoModelForCausalLM:
"""
Distill a model for spoofing attacks using amplified watermark data.
"""
# Similar to scrubbing but with amplified data
return self.distill_for_scrubbing(amplified_data, output_path)
class CDGKD:
"""
Main CDG-KD framework for unified watermark attacks.
"""
def __init__(self, config: CDGKDConfig):
self.config = config
# Load tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(config.student_model_path)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
# Load models
logger.info("Loading student model...")
self.student_model = AutoModelForCausalLM.from_pretrained(
config.student_model_path,
torch_dtype=torch.float16 if config.device == "cuda" else torch.float32
)
logger.info("Loading base model for reference...")
self.base_model = AutoModelForCausalLM.from_pretrained(
config.base_model_path,
torch_dtype=torch.float16 if config.device == "cuda" else torch.float32
)
def create_reference_model(
self,
watermarked_data: List[str]
) -> AutoModelForCausalLM:
"""
Create weakly watermarked reference model.
"""
logger.info("Creating weakly watermarked reference model...")
# Create weak watermark generator
weak_generator = WeaklyWatermarkedModel(
self.base_model,
self.tokenizer
)
# Generate weakly watermarked data
weak_texts = weak_generator.create_weakly_watermarked_data(
watermarked_data
)
# Prepare training data
weak_data = []
for text in weak_texts:
# Split into prompt and completion (simplified)
parts = text.split(".", 1)
if len(parts) == 2:
weak_data.append({
'input': parts[0] + ".",
'output': parts[1]
})
# Fine-tune on weak watermarks
training_args = TrainingArguments(
output_dir="./weak_watermark_model",
num_train_epochs=1,
per_device_train_batch_size=self.config.batch_size,
learning_rate=5e-5,
warmup_ratio=0.1,
logging_steps=100,
save_steps=500,
evaluation_strategy="no"
)
reference_model = weak_generator.fine_tune_on_weak_watermarks(
weak_data,
training_args
)
return reference_model
def generate_contrastive_data(
self,
prompts: List[str],
reference_model: AutoModelForCausalLM
) -> List[Dict]:
"""
Generate contrastive decoded data for distillation.
"""
logger.info(f"Generating contrastive data for {self.config.attack_mode}...")
# Initialize contrastive decoder
decoder = ContrastiveDecoder(
self.student_model,
reference_model,
self.tokenizer,
self.config
)
# Generate contrastive texts
contrastive_data = []
for prompt in tqdm(prompts, desc="Generating contrastive texts"):
generated_text = decoder.generate_contrastive_text(
prompt,
max_new_tokens=256
)
# Extract completion from generated text
completion = generated_text[len(prompt):].strip()
contrastive_data.append({
'input': prompt,
'output': completion
})
return contrastive_data
def perform_attack(
self,
watermarked_data: List[str],
prompts: List[str],
output_path: str
) -> AutoModelForCausalLM:
"""
Perform complete CDG-KD attack pipeline.
"""
logger.info(f"Starting CDG-KD {self.config.attack_mode} attack...")
# Step 1: Create weakly watermarked reference model
reference_model = self.create_reference_model(watermarked_data)
# Step 2: Generate contrastive decoded data
contrastive_data = self.generate_contrastive_data(
prompts,
reference_model
)
# Step 3: Perform bidirectional distillation
distiller = BidirectionalDistillation(
self.config.base_model_path,
self.tokenizer,
self.config
)
if self.config.attack_mode == "scrubbing":
logger.info("Performing distillation for scrubbing attack...")
attack_model = distiller.distill_for_scrubbing(
contrastive_data,
output_path
)
else: # spoofing
logger.info("Performing distillation for spoofing attack...")
attack_model = distiller.distill_for_spoofing(
contrastive_data,
output_path
)
logger.info(f"Attack completed! Model saved to {output_path}")
return attack_model
class WatermarkDetector:
"""
Watermark detection utilities for evaluation.
"""
def __init__(self, watermark_type: str = "kgw", n_gram: int = 1):
self.watermark_type = watermark_type
self.n_gram = n_gram
def compute_p_value(self, text: str, tokenizer) -> float:
"""
Compute p-value for watermark detection.
Simplified implementation - actual implementation would depend on watermark type.
"""
tokens = tokenizer.encode(text)
if self.watermark_type == "kgw":
# Simplified KGW detection
green_count = sum(1 for t in tokens if t % 2 == 0) # Placeholder
total_count = len(tokens)
# Compute z-score and p-value (simplified)
if total_count > 0:
ratio = green_count / total_count
z_score = (ratio - 0.5) * np.sqrt(total_count) / 0.5
p_value = 1 - np.exp(-z_score**2 / 2) # Simplified
else:
p_value = 0.5
elif self.watermark_type == "unigram":
# Simplified Unigram detection
p_value = 0.5 # Placeholder
else: # synthid
# Simplified SynthID detection
p_value = 0.5 # Placeholder
return p_value
def main():
"""
Example usage of CDG-KD framework.
"""
# Configuration
config = CDGKDConfig(
teacher_model_path="THUDM/glm-4-9b-chat",
student_model_path="meta-llama/Llama-3.2-1B",
base_model_path="meta-llama/Llama-3.2-1B",
attack_mode="scrubbing", # or "spoofing"
beta=0.5,
lambda_threshold=0.8,
batch_size=16,
num_epochs=1,
watermark_type="kgw",
n_gram=1
)
# Initialize CDG-KD
cdgkd = CDGKD(config)
# Example data (in practice, load from actual datasets)
watermarked_data = [
"The quick brown fox jumps over the lazy dog. This is a watermarked text example.",
"Machine learning models can generate human-like text. They are trained on large datasets.",
# ... more watermarked texts
]
prompts = [
"The quick brown fox",
"Machine learning models",
# ... more prompts
]
# Perform attack
output_path = f"./cdgkd_{config.attack_mode}_model"
attack_model = cdgkd.perform_attack(
watermarked_data,
prompts,
output_path
)
# Evaluate watermark detectability
detector = WatermarkDetector(config.watermark_type, config.n_gram)
# Generate text with attack model
test_prompt = "Write a story about"
inputs = cdgkd.tokenizer(test_prompt, return_tensors='pt')
with torch.no_grad():
outputs = attack_model.generate(
inputs['input_ids'],
max_new_tokens=256,
do_sample=True,
temperature=0.7
)
generated_text = cdgkd.tokenizer.decode(outputs[0], skip_special_tokens=True)
# Check watermark
p_value = detector.compute_p_value(generated_text, cdgkd.tokenizer)
print(f"Generated text: {generated_text}")
print(f"Watermark p-value: {p_value}")
if config.attack_mode == "scrubbing":
print(f"Scrubbing successful: {p_value > 0.01}")
else:
print(f"Spoofing successful: {p_value < 0.01}")
if __name__ == "__main__":
main()
Pingback: 5 Shocking Mistakes in Knowledge Distillation (And the Brilliant Framework KD2M That Fixes Them) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Graph-Free Knowledge Distillation (And 1 Critical Flaw That Could Derail Your AI Model) - aitrendblend.com
Pingback: 1 Revolutionary Breakthrough in AI Object Detection: GridCLIP vs. Two-Stage Models - aitrendblend.com