Every knowledge distillation paper treats the training set as a fixed resource to be mined equally, epoch after epoch. A team from Zhejiang University spent a preprint asking whether that assumption was actually costing accuracy rather than protecting it, and their answer is a carefully designed framework that deliberately discards 90% of training videos each epoch and gets better results for it.
Key Points
- Using only 10% of training videos per epoch, SAKD consistently outperforms vanilla KD baselines across three video architectures and six competing distillation methods on UCF101 and Kinetics-400.
- Temporal interruption (random frame dropout or shuffle) is used not as a data augmentation trick but as a difficulty probe that reveals how much a video sample can teach the student.
- Sample distillation strength is updated every epoch per sample, so a clip that was hard to distill at epoch 10 can become easy by epoch 40 and receive more KD emphasis accordingly.
- DPP (Determinantal Point Process) sampling ensures the selected 10% of videos are diverse, not just the easiest repeated clips.
- Training time drops to roughly one quarter of standard baselines. On UCF101 with SlowFast, one method goes from 6.4 minutes to 1.5 minutes per epoch.
- The gains are smaller on CIFAR-100 (image data) than on video, which the authors attribute to lower redundancy in image datasets — a meaningful limitation to understand before adopting the method.
The Problem Hiding Inside Standard Distillation
When you distill a large video model into a small one, you are asking the student to learn from every clip in your dataset at every epoch, regardless of whether that clip is actually helping. Some videos transfer their knowledge cleanly. The student watches the teacher’s features or logits, updates its weights, and moves forward. Other videos do not. The gap between teacher and student capacity is too wide for certain clips, and the distillation loss sits high not because learning is happening but because it cannot happen at this stage of training.
The authors of arXiv:2504.00606v1 call this the distillation bottleneck. When hard to transfer and easy to transfer samples receive equal weight, the easy samples stop providing new signal after a while (the student has already learned what they offer), and the difficult ones actively drag performance down because their gradients point in the wrong direction for where the student currently sits. Forcing equal treatment across all clips essentially means the student spends a lot of time on work that does not pay off.
There is a second problem layered on top. Which clips count as hard to transfer changes as training progresses. A video that was genuinely hard at epoch 10 may be tractable at epoch 50, once the student has built up enough general capability. Standard distillation with a fixed weighting treats difficulty as static, but it is not. The SAKD framework is built around measuring and reacting to that drift.
Measuring Difficulty With Temporal Interruption
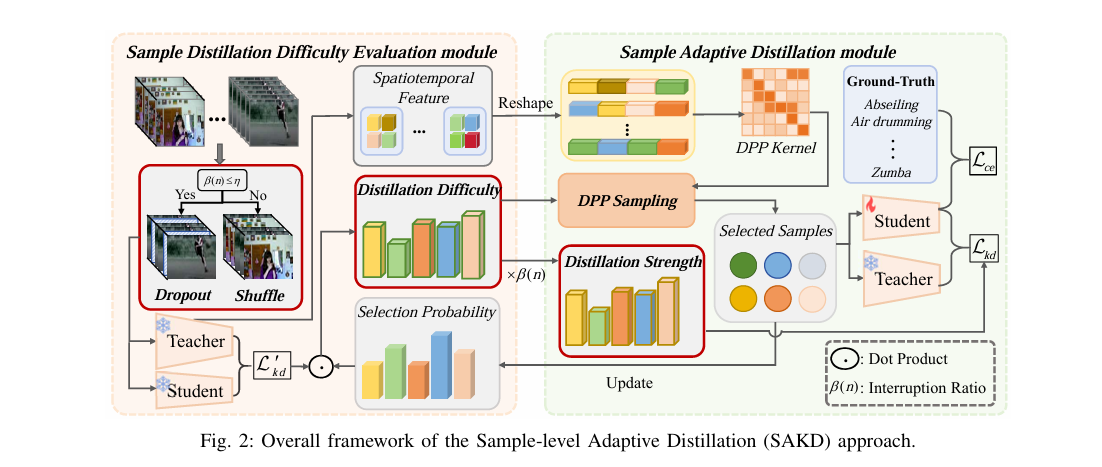
This is where the paper gets interesting, and where it differs most from prior work. To measure how difficult a video clip is to distill, the authors do not just look at the distillation loss on the clean clip. They corrupt the clip first and measure the loss on the corrupted version.
The corruption strategy is called temporal interruption. Given a video clip, the framework either randomly drops a fraction of frames along the temporal dimension or randomly shuffles them. Which operation happens depends on whether the current interruption ratio has crossed a threshold. Below the threshold, frames are dropped (temporal sparsity). Above it, frames are shuffled (temporal disorder across different action classes in the same batch). The interruption ratio itself grows over training according to a polynomial schedule.
where n is the current epoch and theta is set to 0.9 following the poly learning rate convention. At early epochs, beta is small and the interruption is mild. At later epochs, beta approaches 1 and the clips are significantly disrupted before being fed to the teacher and student.
Why does this help evaluate difficulty? Because a video clip that confuses the student even in its clean form will confuse it even more when frames are missing or out of order. The resulting distillation loss on the corrupted clip is a more discriminating signal of how much the teacher’s knowledge is actually getting through. The loss on a disrupted clip that is easy to distill stays relatively low, because the teacher’s decision boundaries for that class are robust. The loss on a disrupted clip that is genuinely hard to distill spikes further, because the gap was already large.
Why Temporal Interruption Over Standard Augmentation
Most data augmentation strategies (random crop, color jitter, mixup) improve generalization by adding diversity to the input distribution. Temporal interruption here serves a different purpose. It deliberately degrades temporal coherence to amplify the distillation loss signal, making it easier to separate clips where the student and teacher gap is large from clips where it is small. The augmentation is used as a diagnostic tool, not a training enrichment.
From Loss Values to Difficulty Scores
The distillation loss on interrupted clips is one of two components in the difficulty score. The other is a selection probability that corrects for repeated sampling. The full difficulty score for sample i is defined below.
where the selection probability follows.
Here omega is the number of times sample i has been selected across previous epochs and epsilon is a small smoothing constant. The intuition is that a clip selected many times in the past is probably easy, so its selection probability falls, and the formula gives it a higher difficulty score (making it less likely to be chosen again). This prevents the framework from repeatedly training on the same handful of easy clips while ignoring everything else.
There is a subtle correction built into this design. Early in training, clips with very large loss values might be mistakenly labelled as easy (because a large loss in the numerator drives difficulty down). The selection probability acts as a corrective lever. If a hard clip has been seen many times and the student still cannot learn from it, its selection probability falls, counteracting the signal from a large loss and correctly classifying it as difficult. As training progresses and the student improves, genuinely difficult clips gradually become tractable and their loss values begin to drop, which shifts the difficulty score accurately.
Adaptive Distillation Strength Per Sample
Knowing which clips are difficult is only half the problem. The other half is deciding what to do with that information during the loss computation. Standard KD uses a fixed alpha that weights the KD loss against the vanilla cross entropy loss, chosen by grid search once and left alone. SAKD replaces that fixed alpha with a per sample per epoch distillation strength below.
The first term is momentum from the previous epoch’s strength (preventing sudden swings). The second term is where the real work happens. The numerator is the interruption ratio, which grows over time, meaning distillation strength generally increases as training proceeds. The denominator is the difficulty score, so a high difficulty clip always damps the KD contribution and lets cross entropy dominate. When a clip is difficult, the student learns more from ground truth labels. When it becomes easier, the formula automatically tilts toward the teacher’s knowledge.
The optimal lambda value from the ablation is 0.1, meaning the current epoch contributes 90% of the distillation strength and the history contributes 10%. That is a fairly aggressive update, and it makes sense given that video understanding changes quickly as the student builds temporal representations over the first few dozen epochs.
A clip that is genuinely hard to distill at epoch 10 may be tractable at epoch 50. SAKD tracks this drift automatically rather than asking the practitioner to guess a fixed schedule.
Interpretation of the adaptive distillation mechanism in arXiv:2504.00606v1Selecting Diverse Clips With DPP
Difficulty scoring alone would produce a biased training subset. The easiest clips would dominate every epoch, and many of them would be visually similar. A model trained on 10% of the data consisting only of the cleanest, most repetitive examples would overfit to that subset in a different way. The authors address this with Determinantal Point Process sampling.
DPP is a probabilistic model that assigns high probability to subsets where the items are dissimilar. The framework computes feature vectors from the teacher model for each clip, builds a kernel matrix from those vectors, and then selects a subset that maximises a joint objective balancing difficulty and diversity.
The first term pushes toward selecting easy to transfer samples (low difficulty score). The second term pushes toward selecting diverse samples (high determinant of the selected feature matrix). The gamma hyperparameter (set to 0.5) balances the two. A greedy algorithm with Cholesky decomposition keeps the computation manageable.
To avoid noisy feature vectors causing unstable DPP selections, the features used for the kernel are themselves a running average of the current epoch’s teacher features and the previous epoch’s features. This momentum smoothing is the same lambda used in the distillation strength formula, creating a consistent timescale for both the diversity estimation and the strength update.
What DPP Adds Over Simple Difficulty Sorting
If you just ranked clips by difficulty and took the 10% easiest ones, you would get a biased subset. High frequency backgrounds and simple environments, and common action classes would dominate. DPP corrects this by penalising redundancy. Two clips of “swimming in a pool” that are almost identical spatiotemporally get a lower joint probability than one swimming clip plus one cycling clip, even if both are individually easy to distill. The result is a 10% subset that is both learnable and representative.
What the Numbers Actually Show
The UCF101 results are the clearest test case because the dataset is well understood and the baselines are strong. The table below summarises key comparisons on the SlowFast architecture, which is the most thoroughly ablated model in the paper.
| Base KD method | Vanilla (100% samples) | SAKD (10% samples) | SAKD 5-epoch (10%) | Time per epoch |
|---|---|---|---|---|
| KD (Hinton 2015) | 87.92% | 90.73% | 89.88% | 1.5 min vs 6.4 min |
| DKD (CVPR 2022) | 90.50% | 91.07% | 89.93% | 1.5 min vs 6.8 min |
| CTKD (AAAI 2023) | 87.12% | 90.67% | 89.61% | 1.4 min vs 6.9 min |
| CrossKD (CVPR 2024) | 90.79% | 90.82% | 90.04% | 1.5 min vs 6.5 min |
Two things stand out. First, the gains are not uniform. SAKD gives roughly a 3 percentage point boost on top of plain KD but only a marginal improvement on CrossKD, which is already a strong CVPR 2024 method. This suggests SAKD’s value is highest when the base distillation method has room to improve from better sample weighting. Stronger base methods that already handle variation across samples differently benefit less. Second, the “every five epochs” variant (Ours*) trades around one percentage point of accuracy for a further threefold reduction in training time. On UCF101 with SlowFast, that brings the epoch time from 6.4 minutes down to 1.5 minutes down to 1.4 minutes.
| Base KD method | Vanilla (100% samples) | SAKD (10% samples) | Epoch time (SAKD vs vanilla) |
|---|---|---|---|
| KD | 54.81% | 55.26% | 2.1 hr vs 2.8 hr |
| CrossKD | 58.07% | 62.18% | 2.2 hr vs 2.8 hr |
| DualKD | 56.25% | 57.02% | 2.4 hr vs 3.1 hr |
Kinetics-400 results show a more mixed picture. The absolute gains are smaller (around 0.5 to 4 percentage points depending on the base method), and the training time reduction is less dramatic than on UCF101. The CrossKD result is the standout at +4.11 percentage points over vanilla, which is a substantial jump on a 400 class benchmark. The Video Swin Transformer results also show consistent improvements, including DKD reaching 74.07% with SAKD versus 73.95% without, which is notable because the vanilla already matched the teacher’s accuracy.
If you have been following our analysis of the integrated gradients approach to knowledge distillation, the contrast here is instructive. That paper modifies the input data to guide the student toward important pixels. SAKD does not touch the inputs at all during actual training. It modifies which inputs the student sees and how much weight the distillation loss carries for each one. Both methods agree that per sample differentiation matters, but they target different parts of the training pipeline.
A Complete PyTorch Implementation
Below is a full, reproducible implementation of the SAKD framework. It includes the temporal interruption module, the difficulty scoring mechanism, the DPP selection, the per sample adaptive distillation strength, and a complete training loop with a smoke test on dummy video tensors.
Honest Limitations
What SAKD Does Not Fully Solve
Image redundancy assumption. The 10% selection ratio that works so well for video relies on video clips having high temporal redundancy. On CIFAR-100 the paper uses 50% instead of 10%, and even at 50% the gains over the vanilla baseline are marginal (often under 0.3 percentage points). Anyone applying SAKD to an image task should expect significantly smaller returns than the video numbers suggest.
Phase 1 cost on large datasets. The difficulty evaluation step runs the teacher forward pass on all training samples every epoch (or every five epochs). On Kinetics-400, which has 234,619 clips, this is a substantial computation before any student training begins. The per epoch overhead from this scan is part of what the training time numbers already include, but at larger scales this could become the bottleneck.
Fixed architecture pairs. All experiments use specific teacher/student pairs where the student architecture is a smaller version of the teacher (such as ResNet-101 teacher and ResNet-50 student). Distillation across architectures, which is common in practice when you want a ViT teacher and an efficient CNN student, is not tested.
Single label action recognition only. The benchmark tasks are clean, single label classification (one action per clip). Video understanding with multiple labels or action detection, where different temporal segments contain different actions, may require rethinking the difficulty scoring, since the loss based criterion assumes one ground truth class drives the distillation.
The “Ours*” accuracy drop. The every five epoch variant consistently loses about one percentage point compared to the every epoch variant across both video benchmarks. For applications where peak accuracy matters and training cost is secondary, the every epoch version should be used.
Why Sample Selection Matters More for Video Than for Images
The paper’s authors make a point of showing results on both video and image benchmarks, but the larger story is about why video makes this problem genuinely important. A video clip contains temporal redundancy by design. Two clips of “playing tennis” from the same match may differ mainly in which frames were sampled. Equal treatment of both clips during distillation adds almost no incremental signal to the student but doubles the computational cost of processing them.
Action recognition models, particularly those based on SlowFast or Video Swin Transformers, are among the most expensive models to train in computer vision. SlowFast on Kinetics-400 needs training for 200 epochs with batches of 128 clips. At that scale, the difference between processing all samples and processing 10% of well selected ones amounts to hundreds of GPU hours per experiment. SAKD’s contribution is not just an accuracy improvement. It is a practical compression of the training compute itself.
This connects to the broader conversation about efficient model compression for edge deployment. Much of the distillation literature focuses on what the student learns from the teacher. SAKD shifts the question to which interactions between student and teacher are worth paying for at all. That reframing has implications beyond video. Any domain where the training set contains high redundancy (medical imaging with similar patient scans, remote sensing with overlapping tiles) could benefit from a difficulty aware selection strategy of this kind.
Frequently Asked Questions
Read the full paper from Zhejiang University and explore the method in detail.
Read on arXiv Download PDFClosing Thoughts
SAKD is a tightly argued paper that solves a real problem. The distillation bottleneck it describes is not a theoretical construct. It is something that shows up when you watch a student model’s validation accuracy plateau well before training ends, while the loss curves for the hardest clips stay stubbornly high. The authors have given that plateau a mechanism and a fix.
The core insight is that difficulty during distillation is not static and not universal across samples. A framework that measures it per clip, per epoch, and adjusts the training signal accordingly will outperform one that does not, given enough video redundancy to make selective sampling sensible. The numbers across three architectures and six baseline methods support that claim consistently.
Where the paper is more careful than many is in its honest treatment of the image benchmark. The gains on CIFAR-100 are real but modest, and the authors explain why. That kind of scope setting is more useful to a practitioner than inflated claims that fall apart at deployment. If your data is video and your training compute is limited, SAKD is worth a serious look. If your data is images, the expected benefit is marginal.
The deeper contribution here is conceptual. Treating knowledge distillation as a sample selection problem, rather than just a loss design problem, opens a different set of levers. The teacher does not just transfer knowledge. It teaches some samples cleanly and struggles with others. Knowing which is which and responding to that distinction is a sensible engineering principle, and this paper is among the first to develop it systematically for video.
Future work on extending SAKD to multi label video understanding or cross architecture teacher and student pairs would significantly broaden its applicability. The framework as published is a well executed proof of concept for the problem it defined, and that is enough to make it worth studying carefully.
Related Articles
This analysis is based on the published paper and an independent evaluation of its claims.
Pingback: 7 Revolutionary Breakthroughs in Graph-Free Knowledge Distillation (And 1 Critical Flaw That Could Derail Your AI Model) - aitrendblend.com
Pingback: 7 Shocking Truths About Heterogeneous Knowledge Distillation: The Breakthrough That’s Transforming Semantic Segmentation - aitrendblend.com
Pingback: 1 Revolutionary Breakthrough in AI Object Detection: GridCLIP vs. Two-Stage Models - aitrendblend.com
Pingback: 1 Breakthrough vs. 1 Major Flaw: CLASS-M Revolutionizes Cancer Detection in Histopathology - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in 6DoF Pose Estimation: How Uncertainty-Aware Knowledge Distillation Beats Old Methods (And Why Most Fail) - aitrendblend.com
Pingback: 7 Shocking Ways Integrated Gradients BOOST Knowledge Distillation - aitrendblend.com
Pingback: 5 Revolutionary Breakthroughs in AI Safety: How CONFIDERAI Eliminates Prediction Failures While Boosting Trust (But Watch Out for Hidden Risks) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in AI Medical Imaging: The Good, the Bad, and the Future of RIIR - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Cell Shape Analysis: How a Powerful New Model Outshines Old Methods - aitrendblend.com
Pingback: 7 Revolutionary Clustering Breakthroughs: Why Gauging-β Outperforms (And When It Fails) - aitrendblend.com
Pingback: 7 Shocking Ways SuperCM Boosts Accuracy (And 1 Fatal Flaw You Must Avoid) - aitrendblend.com
Pingback: FRIES: A Groundbreaking Framework for Inconsistency Estimation of Saliency Metrics - aitrendblend.com
Pingback: Hyperparameter Optimization of YOLO Models for Invasive Coronary Angiography Lesion Detection - aitrendblend.com
Pingback: GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing - aitrendblend.com
Pingback: Quantum Self-Attention in Vision Transformers: A 99.99% More Efficient Path for Biomedical Image Classification - aitrendblend.com
Pingback: Task-Specific Knowledge Distillation in Medical Imaging: A Breakthrough for Efficient Segmentation - aitrendblend.com
Pingback: Hierarchical Spatio-temporal Segmentation Network (HSS-Net) for Accurate Ejection Fraction Estimation - aitrendblend.com
Pingback: Enhancing Vision-Audio Capability in Omnimodal LLMs with Self-KD - aitrendblend.com
Pingback: VRM: Knowledge Distillation via Virtual Relation Matching – A Breakthrough in Model Compression - aitrendblend.com
Pingback: ConvAttenMixer: Revolutionizing Brain Tumor Detection with Convolutional Mixer and Attention Mechanisms - aitrendblend.com
Pingback: A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models - aitrendblend.com
Pingback: Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging - aitrendblend.com
Pingback: Capsule Networks Do Not Need to Model Everything: How REM Reduces Entropy for Smarter AI - aitrendblend.com
Pingback: Revolutionizing Digital Pathology: A Deep Dive into GrEp for Superior Epithelial Cell Classification - aitrendblend.com
Pingback: Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty - aitrendblend.com
Pingback: CMFDNet: Revolutionizing Polyp Segmentation with Cross-Mamba and Feature Discovery - aitrendblend.com
Pingback: Customized Vision-Language Representations for Industrial Qualification: Bridging AI and Expert Knowledge in Additive Manufacturing - aitrendblend.com
Pingback: BiMT-TCN: Revolutionizing Stock Price Prediction with Hybrid Deep Learning - aitrendblend.com
Pingback: Anchor-Based Knowledge Distillation: A Trustworthy AI Approach for Efficient Model Compression - aitrendblend.com
Pingback: AMGF-GNN: Adaptive Multi-Graph Fusion for Tumor Grading in Pathology Images - aitrendblend.com
Pingback: PSO-Optimized Fractional Order CNNs for Enhanced Breast Cancer Detection - aitrendblend.com
Pingback: Building Electrical Consumption Forecasting with Hybrid Deep Learning | Smart Energy Management - aitrendblend.com
Pingback: Modifying Final Splits of Classification Trees (MDFS) for Subpopulation Targeting - aitrendblend.com
Pingback: RetiGen: Revolutionizing Retinal Diagnostics with Domain Generalization and Test-Time Adaptation - aitrendblend.com
Pingback: Transforming Diabetic Foot Ulcer Care with AI-Powered Healing Phase Classification - aitrendblend.com
Pingback: UniForCE: A Robust Method for Discovering Clusters and Estimating Their Number Using Local Unimodality - aitrendblend.com
Pingback: LayerMix: A Fractal-Based Data Augmentation Strategy for More Robust Deep Learning Models - aitrendblend.com
Pingback: FAST: Revolutionary AI Framework Accelerates Industrial Anomaly Detection by 100x - aitrendblend.com
Pingback: U-Mamba2-SSL: The Groundbreaking AI Framework Revolutionizing Tooth & Pulp Segmentation in CBCT Scans - aitrendblend.com
Pingback: Stabilizing Uncertain Stochastic Systems: A Deep Learning Approach to Inverse Optimal Control - aitrendblend.com
Pingback: Balancing the Tension: How a New AI Strategy Solves the Hidden Conflict in Semi-Supervised Image Segmentation - aitrendblend.com
Pingback: MedDINOv3: Revolutionizing Medical Image Segmentation with Adaptable Vision Foundation Models - aitrendblend.com
Pingback: SegTrans: The Breakthrough Framework That Makes AI Segmentation Models Vulnerable to Transfer Attacks - aitrendblend.com
Pingback: Next-Gen Data Security: A Deep Dive into Multi-Layered Steganography Using Huffman Coding and Deep Learning - aitrendblend.com
Pingback: Revolutionizing Medical Imaging: How a Compact, Programmable Ultrasound Array Unlocks High-Contrast Elastography for Bones and Tumors - aitrendblend.com
Pingback: Revolutionary AI Breakthrough: How Anatomy-Guided Deep Learning Is Transforming Breast Cancer Detection in PET-CT ScansAnatomy-Guided Deep LearningRevolutionary AI Breakthrough: How Anatomy-Guided Deep Learning Is Transforming Breast Cancer Detection in P