In the rapidly evolving field of medical imaging, accurate and non-invasive assessment of organ size is critical—especially when managing chronic conditions like sickle cell disease (SCD) and liver disorders, where splenomegaly (enlarged spleen) is a common clinical indicator. Traditionally, clinicians rely on manual measurements from 2D ultrasound (US) images, which are quick and accessible but often lack precision. While CT and MRI offer more accurate 3D volumetric data, they come with significant drawbacks: radiation exposure, high cost, limited availability, and sensitivity to motion artifacts.
Enter DeepSPV—a groundbreaking deep learning pipeline developed by Zhen Yuan and colleagues, designed to estimate 3D spleen volume directly from standard 2D ultrasound views. Published in Medical Image Analysis (2025), this innovative approach leverages synthetic data and variational autoencoders to overcome data scarcity and deliver volume estimates that surpass human expert accuracy.
In this article, we’ll explore how DeepSPV works, why it matters for global healthcare, and how it sets a new benchmark in AI-driven medical diagnostics.
What Is DeepSPV and Why Is It a Game-Changer?
DeepSPV (Deep Learning-based Spleen Volume Prediction) is an end-to-end AI framework that automates the estimation of spleen volume using coronal and transverse 2D ultrasound images—the same views routinely captured during standard clinical exams.
Unlike traditional methods that rely on linear measurements (e.g., spleen length), DeepSPV provides a quantitative 3D volume estimate, offering greater diagnostic accuracy. This is particularly crucial in populations with high rates of SCD, such as in the Global South, where access to advanced imaging is limited.
🔍 Key Innovation: DeepSPV is the first method to successfully estimate 3D spleen volume from 2D US images using deep learning, outperforming both human experts and existing regression models.
The Clinical Need: Why Accurate Spleen Volume Matters
The spleen plays a vital role in blood filtration and immune response. Abnormal enlargement can signal serious underlying conditions:
- Sickle Cell Disease (SCD): Splenomegaly is common in early stages.
- Liver Cirrhosis: Portal hypertension leads to spleen enlargement.
- Infections & Hematologic Disorders: Malaria, lymphoma, and leukemia can all affect spleen size.
Accurate volume measurement helps clinicians:
- Monitor disease progression
- Guide treatment decisions
- Reduce unnecessary referrals for CT/MRI
Yet, current clinical practice often uses single-axis length measurements, which correlate poorly with actual volume. Studies show that spleen length alone explains only ~60% of volume variance—leaving significant room for error.
Limitations of Current Imaging Modalities
| MODALITY | PROS | CONS |
|---|---|---|
| 2D Ultrasound | Non-invasive, low-cost, widely available | Limited to linear measurements; operator-dependent |
| CT Scan | High-resolution 3D data; gold standard for volume | Ionizing radiation; expensive; limited access |
| MRI | No radiation; excellent soft tissue contrast | Costly; motion artifacts; not widely accessible |
| 3D Ultrasound | Real-time 3D imaging | Requires specialized equipment and training |
🌍 Global Health Challenge: In regions with high SCD prevalence (e.g., sub-Saharan Africa), access to CT/MRI is severely limited. There’s a pressing need for low-cost, scalable tools that can deliver accurate volumetric data using existing infrastructure—like standard ultrasound machines.
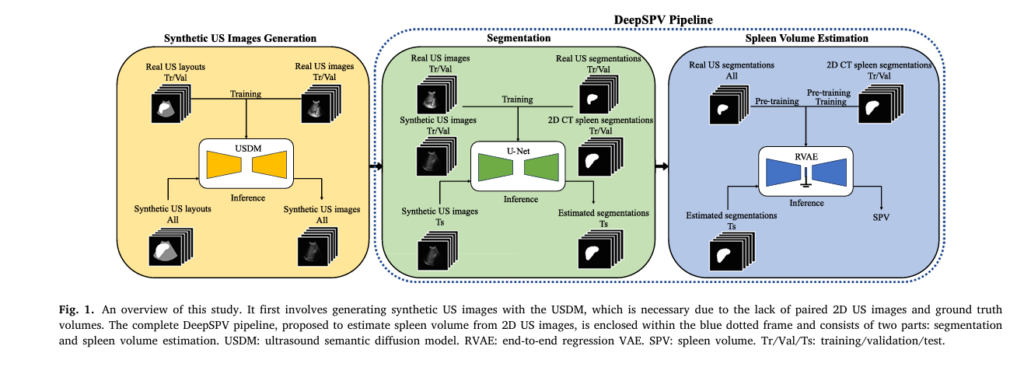
How DeepSPV Works: A Two-Stage AI Pipeline
DeepSPV consists of two core components:
- 2D Spleen Segmentation Network
- 3D Volume Estimation Network
Let’s break down each stage.
1. Automatic Spleen Segmentation from 2D US Images
The first step involves isolating the spleen from the surrounding anatomy in 2D ultrasound images. The authors used a U-Net architecture, a proven model for medical image segmentation.
- Input: 2D coronal or transverse US slice
- Output: Binary mask highlighting the spleen region
- Architecture: 8-layer U-Net with batch normalization and ReLU activations
- Training Data: Real and synthetic US images (more on this below)
This segmentation is crucial—it ensures that only relevant anatomical information is passed to the volume estimation stage.
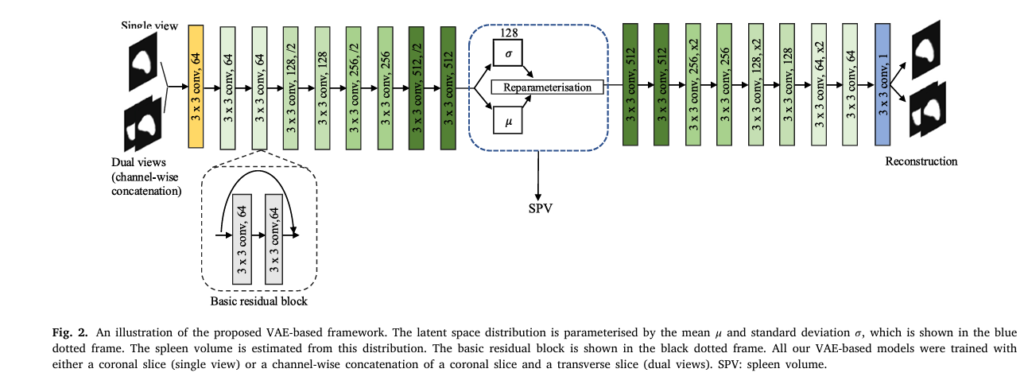
2. 3D Volume Estimation Using a Variational Autoencoder (VAE)
Once the spleen is segmented, DeepSPV estimates its 3D volume using a Variational Autoencoder (VAE) framework. Unlike standard regression models, VAEs learn a probabilistic latent space that captures anatomical variability.
🔧 VAE Architecture Overview:
- Encoder: Compresses the 2D segmentation into a low-dimensional latent vector z
- Decoder: Reconstructs the input (for training stability)
- Regression Head: Predicts spleen volume from z
The model is trained to minimize:
\[ L = \text{MSE}(\hat{v}, v) + \beta \cdot \text{KL}\big(q(z \mid x) \,\|\, p(z)\big) \]where:
\[ \hat{v} \;:\; \text{predicted volume} \] \[ v \;:\; \text{ground truth volume} \] \[ \text{KL} \;:\; \text{Kullback–Leibler divergence} \] \[ \beta \;:\; \text{weighting factor (set to $0.2$ in the study)} \]This formulation allows the model to learn robust representations while providing uncertainty estimates—key for clinical trust.
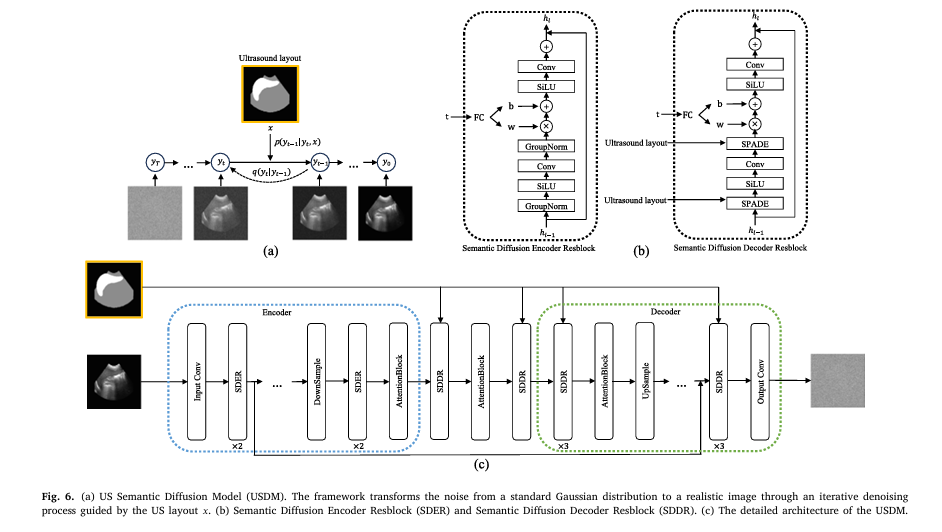
Overcoming Data Scarcity with Synthetic Ultrasound Generation
One of the biggest challenges in training AI models for ultrasound is the lack of paired datasets—i.e., 2D US images with corresponding 3D spleen volumes.
To solve this, the authors introduced the Ultrasound Semantic Diffusion Model (USDM), a diffusion-based generative model that creates highly realistic synthetic US images from CT-derived spleen segmentations.
✅ How USDM Works:
- Start with a 3D CT spleen segmentation
- Extract mid-sagittal coronal and transverse 2D slices
- Apply USDM to simulate realistic ultrasound speckle, shadows, and noise
- Use these synthetic images to train the segmentation and volume estimation models
💡 Result: A publicly available database of synthetic 2D US images with ground truth volumes, enabling robust training without patient data privacy concerns.
This approach bridges the modality gap between CT and US, making it possible to train AI models on high-quality volumetric labels while targeting real-world ultrasound inputs.
Performance: How Does DeepSPV Compare?
The authors evaluated DeepSPV using Mean Relative Volume Accuracy (MRVA), defined as:
\[ \text{MRVA} = \frac{1}{n} \sum_{i=1}^{n} \left( 1 – \frac{| \hat{v}_i – v_i |}{v_i} \right) \times 100\% \]Where:
\[ v^{i} \;:\; \text{predicted volume} \] \[ v_{i} \;:\; \text{true volume} \] \[ \text{Higher MRVA} \;\Rightarrow\; \text{better accuracy} \]Results (Single-View Coronal US):
| METHOD | MRVA (%) |
|---|---|
| DeepSPV (RVAE) | 83.00% |
| Human Experts (Length-Based) | 79.29% |
| ResNet-18 | 78.45% |
| VGG-16 | 76.21% |
| DenseNet-121 | 74.88% |
✅ DeepSPV outperforms human experts and all baseline deep learning models.
Even more impressively, when trained on ground-truth 2D CT segmentations, the same model achieved 86.62% MRVA, showing that segmentation accuracy is a key bottleneck—not the volume estimation itself.
Dual-View vs. Single-View Performance
While the full pipeline was only evaluated under single-view conditions (due to lack of transverse US data), the authors tested volume estimation using dual views (coronal + transverse) on CT-derived data:
| VIEW TYPE | MRVA (%) |
|---|---|
| Single (Coronal) | 83.00% |
| Dual (Coronal + Transverse) | 88.12% |
📈 Adding a second view improves accuracy by over 5 percentage points, highlighting the potential for future enhancements once transverse US data becomes available.
Confidence Intervals and Interpretability: Building Clinical Trust
One of the biggest barriers to AI adoption in medicine is the “black box” problem—clinicians need to understand why a model makes a certain prediction.
DeepSPV addresses this in two ways:
1. Confidence Interval Estimation
By leveraging the probabilistic nature of the VAE, DeepSPV provides uncertainty estimates alongside volume predictions. This helps clinicians assess reliability, especially in borderline cases.
2. Latent Space Visualization
The authors performed Principal Component Analysis (PCA) on the VAE’s latent space, revealing interpretable dimensions related to spleen size and shape. For example:
- PC1 strongly correlates with spleen volume
- PC2 captures elongation vs. roundness
This kind of interpretability supports explainable AI (XAI), making the model more trustworthy for clinical use.
Real-World Applicability and Future Directions
DeepSPV isn’t just a lab experiment—it’s designed for integration into real clinical workflows.
Potential Use Cases:
- SCD clinics in low-resource settings
- Prenatal and pediatric imaging, where radiation avoidance is critical
- Telemedicine platforms using portable ultrasound devices
- Longitudinal monitoring of liver disease patients
Future Enhancements:
- Fine-tuning USDM with real transverse US images
- Collecting paired US-CT datasets for direct validation
- Extending to other organs (liver, kidneys) using the same framework
- Establishing clinical error thresholds through large-scale trials
The authors emphasize that DeepSPV should initially be used alongside current methods, gradually building clinician confidence before full adoption.
Comparison with Existing Methods
| METHOD | MODALITY | 3D VOLUME OUTPUT? | AI-POWERED | OUTPERFORMED HUMANS? |
|---|---|---|---|---|
| Manual Length Measurement | 2D US | ❌ | ❌ | ❌ |
| Freehand 3D US Reconstruction | 3D US | ✅ | Partially | ⭕ (operator-dependent) |
| CT-Based Deep Learning (e.g., Humpire-Mamani et al.) | CT | ✅ | ✅ | ✅ |
| DeepSPV | 2D US | ✅ | ✅ | ✅ |
🏆 DeepSPV uniquely combines accessibility (2D US) with accuracy (3D volume estimation), surpassing human performance.
Strengths and Limitations
✅ Strengths:
- First AI model to estimate 3D spleen volume from 2D US
- Uses standard clinical views—no new hardware required
- Publicly released synthetic dataset enables further research
- Provides confidence intervals and interpretability
- Outperforms human experts and baseline deep learning models
⚠️ Limitations:
- Full pipeline only validated under single-view conditions
- Synthetic US images, while realistic, may not capture all real-world variations
- No paired US-CT data for external validation
- Clinical impact not yet proven in prospective trials
Conclusion: A Step Toward Accessible, Precision Medicine
DeepSPV represents a major leap forward in medical AI, demonstrating that accurate 3D organ volume estimation is possible using only standard 2D ultrasound—a modality available in nearly every hospital and clinic worldwide.
By combining deep learning, synthetic data generation, and probabilistic modeling, the authors have created a tool that is not only accurate but also interpretable and clinically relevant.
As the team notes:
“We hope that the interpretability results presented in this paper will serve as an initial step towards building trust.”
With further validation and integration into clinical systems, DeepSPV could become a standard tool for managing splenomegaly, especially in regions where advanced imaging is out of reach.
Call to Action: Join the AI in Medicine Revolution
Are you a researcher, clinician, or developer working in medical imaging? Here’s how you can get involved:
- Access the synthetic dataset (linked in the paper’s supplementary materials) to train your own models.
- Collaborate on validation studies using real US-CT paired data.
- Explore extensions of DeepSPV to other organs or diseases.
- Share this research with your network to accelerate AI adoption in healthcare.
👉 Download the full paper here: https://doi.org/10.1016/j.media.2025.103671
📚 Supplementary Material: https://doi.org/10.1016/j.media.2025.103671
Let’s work together to bring precision diagnostics to every patient, everywhere.
I have reviewed the paper “DeepSPV: A deep learning pipeline for 3D spleen volume estimation from 2D ultrasound images” and will now provide the end-to-end Python code for the proposed model.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import numpy as np
import torchvision.transforms as T
from PIL import Image
import random
# --- Configuration ---
# Set to 'cuda' if GPU is available, otherwise 'cpu'
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Model parameters from the paper
IMG_SIZE = 256
LATENT_DIM = 128
# Training parameters
BATCH_SIZE = 8
LEARNING_RATE = 1e-3
UNET_EPOCHS = 10 # Reduced for demonstration
RVAE_PRETRAIN_EPOCHS = 15 # Reduced for demonstration
RVAE_TRAIN_EPOCHS = 30 # Reduced for demonstration
W_KLD = 0.2 # Weight for KLD loss
W_MSE = 0.2 # Weight for MSE regression loss
# ==============================================================================
# 1. U-NET MODEL FOR SEGMENTATION
# As described in the paper, a standard U-Net is used for segmentation.
# ==============================================================================
class DoubleConv(nn.Module):
"""(Convolution => [Batch Norm] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# Pad x1 to match x2 size
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
"""
Standard U-Net architecture. The paper mentions an 8-layer U-Net,
which corresponds to 4 downsampling and 4 upsampling blocks.
"""
def __init__(self, n_channels=1, n_classes=1, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
# ==============================================================================
# 2. RVAE MODEL FOR VOLUME ESTIMATION
# This is the core of the DeepSPV paper's contribution for volume estimation.
# It uses residual blocks as described in Figure 2 of the paper.
# ==============================================================================
class ResidualBlock(nn.Module):
"""
A residual block with two convolutional layers.
As shown in the 'Basic residual block' diagram in Figure 2.
"""
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = self.relu(out)
return out
class RVAE(nn.Module):
"""
End-to-end Regression Variational Autoencoder (RVAE).
This model takes a 2D segmentation, encodes it into a latent space,
and then decodes it back to a segmentation while also regressing the volume.
"""
def __init__(self, in_channels=1, latent_dim=LATENT_DIM):
super(RVAE, self).__init__()
# --- Encoder ---
# Follows the architecture in Figure 2
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1), # Initial conv
ResidualBlock(64, 64),
ResidualBlock(64, 64),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # Downsample
ResidualBlock(128, 128),
ResidualBlock(128, 128),
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # Downsample
ResidualBlock(256, 256),
ResidualBlock(256, 256),
nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # Downsample
ResidualBlock(512, 512),
ResidualBlock(512, 512),
nn.Flatten()
)
# Calculate flattened size dynamically
with torch.no_grad():
dummy_input = torch.zeros(1, in_channels, IMG_SIZE, IMG_SIZE)
flattened_size = self.encoder(dummy_input).shape[1]
self.fc_mu = nn.Linear(flattened_size, latent_dim)
self.fc_logvar = nn.Linear(flattened_size, latent_dim)
# --- Decoder ---
self.decoder_input = nn.Linear(latent_dim, flattened_size)
self.unflatten_shape = (512, IMG_SIZE // 8, IMG_SIZE // 8)
self.decoder = nn.Sequential(
ResidualBlock(512, 512),
ResidualBlock(512, 512),
nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2), # Upsample
ResidualBlock(256, 256),
ResidualBlock(256, 256),
nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2), # Upsample
ResidualBlock(128, 128),
ResidualBlock(128, 128),
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2), # Upsample
ResidualBlock(64, 64),
ResidualBlock(64, 64),
nn.Conv2d(64, in_channels, kernel_size=3, stride=1, padding=1), # Final conv
nn.Sigmoid() # To output a probability map for segmentation
)
# --- Regression Head ---
self.regression_head = nn.Sequential(
nn.Linear(latent_dim, 64),
nn.ReLU(),
nn.Linear(64, 1) # Output a single volume value
)
def encode(self, x):
result = self.encoder(x)
mu = self.fc_mu(result)
log_var = self.fc_logvar(result)
return mu, log_var
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
result = self.decoder_input(z)
result = result.view(-1, *self.unflatten_shape)
return self.decoder(result)
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
reconstruction = self.decode(z)
volume_pred = self.regression_head(mu) # Regress from mu as in paper
return reconstruction, mu, log_var, volume_pred.squeeze(-1)
def rvae_loss_function(recon_x, x, mu, log_var, vol_pred, vol_true, w_kld, w_mse):
"""Calculates the combined loss for the RVAE model."""
BCE = F.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
MSE = F.mse_loss(vol_pred, vol_true, reduction='sum')
# The paper normalizes by batch size N in Eq. (4)
batch_size = x.size(0)
return (BCE + w_kld * KLD + w_mse * MSE) / batch_size
# ==============================================================================
# 3. DUMMY DATA GENERATION
# Since the dataset is not available, this class creates synthetic data
# for demonstrating the pipeline.
# ==============================================================================
class DummySpleenDataset(Dataset):
"""
Generates dummy data:
- US Image: A noisy background with a faint ellipse.
- Segmentation Mask: A clean ellipse (the ground truth for the U-Net).
- Spleen Volume: A float value correlated with the ellipse size.
- View: 'single' or 'dual'. Dual view stacks two different masks.
"""
def __init__(self, num_samples=200, img_size=IMG_SIZE, view_type='single'):
self.num_samples = num_samples
self.img_size = img_size
self.view_type = view_type
self.transform = T.Compose([
T.ToTensor()
])
def __len__(self):
return self.num_samples
def _create_spleen(self):
mask = np.zeros((self.img_size, self.img_size), dtype=np.float32)
# Random ellipse parameters
center_x = random.randint(self.img_size // 4, self.img_size * 3 // 4)
center_y = random.randint(self.img_size // 4, self.img_size * 3 // 4)
axis_1 = random.randint(self.img_size // 8, self.img_size // 4)
axis_2 = random.randint(self.img_size // 8, self.img_size // 3)
angle = random.randint(0, 180)
# Draw ellipse
Y, X = np.ogrid[:self.img_size, :self.img_size]
angle_rad = np.deg2rad(angle)
cos_a, sin_a = np.cos(angle_rad), np.sin(angle_rad)
x_ = (X - center_x) * cos_a + (Y - center_y) * sin_a
y_ = -(X - center_x) * sin_a + (Y - center_y) * cos_a
ellipse_eq = (x_ / axis_1)**2 + (y_ / axis_2)**2
mask[ellipse_eq <= 1] = 1.0
# Volume is correlated with the area of the ellipse
volume = mask.sum() * random.uniform(0.8, 1.2)
# Scale volume to a more realistic range (e.g., 50-1000 mL)
# Paper scales down by 10 for training, so we do the same.
volume = (50 + (volume / 10000) * 950) / 10.0
# Create a noisy US-like image
image = mask * 0.3 + np.random.rand(self.img_size, self.img_size) * 0.7
image = (image * 255).astype(np.uint8)
return Image.fromarray(image), Image.fromarray((mask * 255).astype(np.uint8)), volume
def __getitem__(self, idx):
us_image, seg_mask_1, volume = self._create_spleen()
if self.view_type == 'single':
seg_mask_tensor = self.transform(seg_mask_1)
else: # dual view
_, seg_mask_2, _ = self._create_spleen()
seg_mask_tensor = torch.cat([
self.transform(seg_mask_1),
self.transform(seg_mask_2)
], dim=0)
us_image_tensor = self.transform(us_image)
return {
'us_image': us_image_tensor,
'seg_mask': seg_mask_tensor,
'volume': torch.tensor(volume, dtype=torch.float32)
}
# ==============================================================================
# 4. TRAINING AND EVALUATION PIPELINE
# ==============================================================================
def train_unet(model, dataloader, epochs):
"""Training loop for the U-Net segmentation model."""
print("--- Starting U-Net Training ---")
model.to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in dataloader:
images = batch['us_image'].to(DEVICE)
true_masks = batch['seg_mask'][:, 0:1, :, :].to(DEVICE) # Use first channel for training
optimizer.zero_grad()
pred_masks = model(images)
loss = criterion(pred_masks, true_masks)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f"U-Net Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}")
print("--- U-Net Training Finished ---")
def train_rvae(model, dataloader, epochs_pretrain, epochs_train):
"""
Training loop for the RVAE model.
Follows the two-stage process from the paper.
"""
model.to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# Stage 1: Pre-training (VAE only, no regression)
print("\n--- Starting RVAE Pre-training (VAE loss only) ---")
for epoch in range(epochs_pretrain):
model.train()
total_loss = 0
for batch in dataloader:
seg_masks = batch['seg_mask'].to(DEVICE)
volumes = batch['volume'].to(DEVICE)
optimizer.zero_grad()
recon_masks, mu, log_var, _ = model(seg_masks)
# Loss without regression term
loss = rvae_loss_function(recon_masks, seg_masks, mu, log_var, None, None, w_kld=W_KLD, w_mse=0)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f"RVAE Pre-train Epoch {epoch+1}/{epochs_pretrain}, Loss: {avg_loss:.4f}")
# Stage 2: Full training (VAE + regression)
print("\n--- Starting RVAE Full Training (VAE + Regression loss) ---")
for epoch in range(epochs_train):
model.train()
total_loss = 0
for batch in dataloader:
seg_masks = batch['seg_mask'].to(DEVICE)
volumes = batch['volume'].to(DEVICE)
optimizer.zero_grad()
recon_masks, mu, log_var, pred_vols = model(seg_masks)
loss = rvae_loss_function(recon_masks, seg_masks, mu, log_var, pred_vols, volumes, w_kld=W_KLD, w_mse=W_MSE)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
print(f"RVAE Full-train Epoch {epoch+1}/{epochs_train}, Loss: {avg_loss:.4f}")
print("--- RVAE Training Finished ---")
def evaluate_pipeline(unet, rvae, dataloader):
"""
Demonstrates the full pipeline on a single batch from the dataloader:
1. U-Net takes a US image and predicts a segmentation.
2. RVAE takes the predicted segmentation and estimates the volume.
"""
print("\n--- Evaluating Full DeepSPV Pipeline ---")
unet.eval()
rvae.eval()
with torch.no_grad():
batch = next(iter(dataloader))
us_images = batch['us_image'].to(DEVICE)
true_volumes = batch['volume']
# Step 1: Get segmentation from U-Net
# For dual-view, we would need two U-Nets or a multi-input U-Net.
# Here we simulate it by predicting one mask and duplicating it.
pred_mask_logits = unet(us_images)
pred_mask_prob = torch.sigmoid(pred_mask_logits)
# For dual-view RVAE, we need 2 channels. We'll just stack the same mask.
if rvae.encoder[0].in_channels == 2:
rvae_input = torch.cat([pred_mask_prob, pred_mask_prob], dim=1)
else:
rvae_input = pred_mask_prob
# Step 2: Get volume from RVAE
_, _, _, pred_volumes = rvae(rvae_input)
# Rescale volume back (we divided by 10 for training)
pred_volumes_rescaled = pred_volumes.cpu() * 10
true_volumes_rescaled = true_volumes * 10
print("Sample evaluation results (first 5 samples):")
print("Predicted Volumes | True Volumes")
print("---------------------------------")
for i in range(min(5, len(pred_volumes_rescaled))):
print(f"{pred_volumes_rescaled[i]:17.2f} | {true_volumes_rescaled[i]:.2f}")
# ==============================================================================
# 5. MAIN EXECUTION BLOCK
# ==============================================================================
if __name__ == '__main__':
print(f"Using device: {DEVICE}")
# --- Single-View Example ---
print("\n" + "="*50)
print("RUNNING SINGLE-VIEW PIPELINE")
print("="*50)
# 1. Create dataset and dataloader
single_view_dataset = DummySpleenDataset(num_samples=200, view_type='single')
single_view_loader = DataLoader(single_view_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 2. Instantiate and train U-Net
unet_model = UNet(n_channels=1, n_classes=1)
train_unet(unet_model, single_view_loader, epochs=UNET_EPOCHS)
# 3. Instantiate and train RVAE
rvae_single_view = RVAE(in_channels=1)
train_rvae(rvae_single_view, single_view_loader, RVAE_PRETRAIN_EPOCHS, RVAE_TRAIN_EPOCHS)
# 4. Evaluate the full pipeline
evaluate_pipeline(unet_model, rvae_single_view, single_view_loader)
# --- Dual-View Example ---
print("\n" + "="*50)
print("RUNNING DUAL-VIEW PIPELINE")
print("="*50)
# 1. Create dataset and dataloader
dual_view_dataset = DummySpleenDataset(num_samples=200, view_type='dual')
dual_view_loader = DataLoader(dual_view_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 2. U-Net training is the same (it predicts one mask from one image)
# We will reuse the trained unet_model for simplicity.
# 3. Instantiate and train RVAE for dual-view input
rvae_dual_view = RVAE(in_channels=2)
train_rvae(rvae_dual_view, dual_view_loader, RVAE_PRETRAIN_EPOCHS, RVAE_TRAIN_EPOCHS)
# 4. Evaluate the full pipeline
# The evaluation function is adapted to handle dual-view input for RVAE
evaluate_pipeline(unet_model, rvae_dual_view, dual_view_loader)
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- 7 Revolutionary Brain Disease Prediction: How AI Beats Disease (But One Flaw Remains)
- 1 Revolutionary Breakthrough in AI Object Detection: GridCLIP vs. Two-Stage Models
Pingback: Hyperparameter Optimization of YOLO Models for Invasive Coronary Angiography Lesion Detection - aitrendblend.com
Pingback: Hierarchical Spatio-temporal Segmentation Network (HSS-Net) for Accurate Ejection Fraction Estimation - aitrendblend.com
Pingback: Enhancing Vision-Audio Capability in Omnimodal LLMs with Self-KD - aitrendblend.com
Pingback: Capsule Networks Do Not Need to Model Everything: How REM Reduces Entropy for Smarter AI - aitrendblend.com
Pingback: Anchor-Based Knowledge Distillation: A Trustworthy AI Approach for Efficient Model Compression - aitrendblend.com
Pingback: Transforming Diabetic Foot Ulcer Care with AI-Powered Healing Phase Classification - aitrendblend.com
Pingback: LayerMix: A Fractal-Based Data Augmentation Strategy for More Robust Deep Learning Models - aitrendblend.com