RETTA: Revolutionizing Zero-Shot Video Captioning with Retrieval-Enhanced Test-Time Adaptation
In the rapidly evolving field of vision-language modeling, the ability to automatically generate accurate and contextually relevant descriptions of video content—known as video captioning—has become a cornerstone for applications ranging from assistive technology for the visually impaired to intelligent video search engines. While supervised models have achieved remarkable performance, they rely heavily on large-scale annotated datasets, which are expensive and time-consuming to produce.
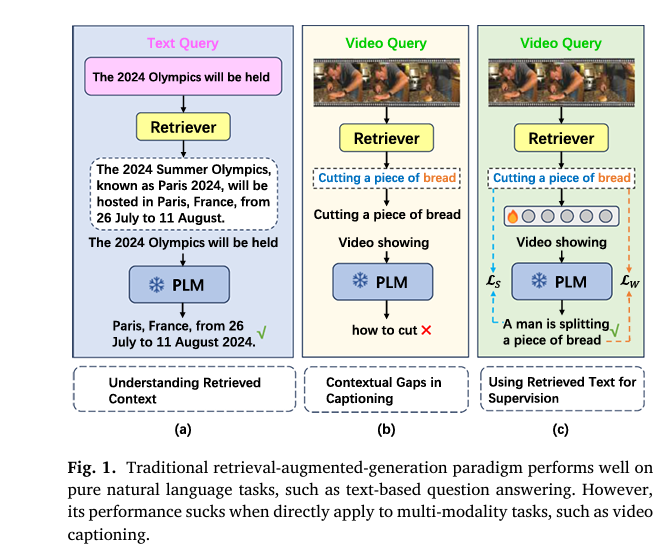
Enter zero-shot video captioning, a promising paradigm that eliminates the need for labeled training data. However, existing zero-shot methods often struggle with content awareness and semantic fidelity. To bridge this gap, researchers have introduced RETTA (Retrieval-Enhanced Test-Time Adaptation), a groundbreaking framework that leverages retrieval-augmented generation and test-time learning to deliver state-of-the-art performance—without any training.
In this article, we’ll dive deep into how RETTA works, why it outperforms existing methods, and what it means for the future of AI-powered video understanding.
What Is Zero-Shot Video Captioning?
Zero-shot video captioning refers to the task of generating natural language descriptions for videos without any task-specific training on labeled video-caption pairs. Instead, models rely on pre-trained vision and language models (VLMs) to infer meaning from visual input.
Traditional approaches often use models like CLIP or GPT-2 in isolation, but they suffer from weak semantic alignment between visual content and generated text. For instance, a model might describe a video of someone baking a cake as “a person in a kitchen,” missing critical details like ingredients or actions.
This is where RETTA comes in.
Introducing RETTA: The First Retrieval-Enhanced Framework for Zero-Shot Video Captioning
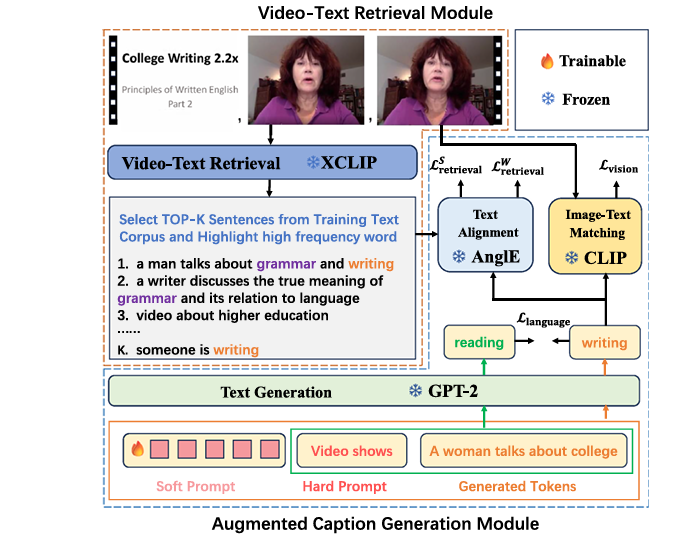
RETTA, proposed by Ma et al., is the first framework to combine four powerful pre-trained models—XCLIP, CLIP, AnglE, and GPT-2—under a zero-shot, test-time adaptation setting. Unlike conventional methods that fine-tune models on training data, RETTA adapts during inference using only a few iterations (e.g., 16), making it both fast and scalable.
🔧 Core Components of RETTA
| MODEL | ROLE | FUNCTION |
|---|---|---|
| XCLIP | Video-Text Retrieval | Retrieves relevant sentences from a text corpus based on video content |
| CLIP | Image-Text Matching | Extracts visual features and aligns frames with generated text |
| AnglE | Text Alignment | Computes semantic similarity between generated text and retrieved sentences |
| GPT-2 | Text Generation | Generates fluent, context-aware captions |
These models remain frozen—their weights are not updated. Instead, RETTA introduces learnable soft tokens that act as a communication bridge between them.
How RETTA Works: A Step-by-Step Breakdown
Step 1: Video-Text Retrieval with XCLIP
Given an input video, RETTA uses XCLIP, a video-language model pre-trained on Kinetics-600, to retrieve the most relevant sentences from a text corpus (e.g., training captions). This provides a semantic anchor for the captioning process.
To reduce noise, RETTA also extracts top-L high-frequency nouns and verbs from the retrieved sentences. These keywords serve as additional cues for content relevance.
✅ Why this matters: Retrieving multiple related sentences and key words helps the model avoid hallucination and stay grounded in visual content.
Step 2: Augmented Caption Generation with Learnable Tokens
The heart of RETTA lies in its augmented caption generation module, which uses soft prompts (learnable tokens) to guide GPT-2 during text generation.
At each autoregressive step i , the next word wi+1 is generated as:
\[ w_{i+1} = P_{\mathrm{LM}}\big(w_{\mathrm{soft}},\, w_{\mathrm{hard}},\, s_i\big) \]Where:
- wsoft : Learnable soft tokens (optimized during inference)
- whard : Fixed prompt (e.g., “Video showing”)
- si : Previously generated words
These soft tokens are updated using gradient signals from multiple loss functions, ensuring the generated text aligns with both visual content and retrieved knowledge.
Step 3: Multi-Granularity Retrieval Losses
RETTA introduces two novel loss functions to align the generated caption with retrieved information:
1. Sentence-Granularity Retrieval Loss (LSretrieval )
This loss encourages the model to generate text semantically similar to the retrieved sentences using AnglE for alignment scoring:
\[ L_{\text{S\_retrieval}} = – \sum_{k=1}^{N} p(w_k) \, \log\big(q(w_k)\big) \]Where:
\[ q(w_k) : \text{Probability of word } k \text{ from GPT-2} \] \[ p(w_k) : \text{Soft target computed as the average AnglE score between the current context } s_k \text{ and all retrieved sentences } R \]2. Word-Granularity Retrieval Loss (LWretrieval )
To handle noise in retrieved sentences, RETTA also focuses on high-frequency keywords:
\[ L_{W_{\text{retrieval}}} = – \sum_{k=1}^{N} \hat{p}(w_k) \, \log\big(q(w_k)\big) \]With:
\[ p^{(w_k)} = \frac{1}{|W|} \sum_{W \in \mathcal{W}} \text{Angle}(W, s_k) \]Where W is the set of top-L frequent words.
Step 4: Vision and Language Consistency Losses
To ensure the caption matches the video and remains fluent, RETTA uses two additional losses:
Vision Alignment Loss (Lvision )
Aligns generated text with sampled video frames using CLIP:
\[ L_{\text{vision}} = -\sum_{k=1}^{N} \left( \frac{1}{T_1} \sum_{F \in \mathcal{F}} \text{CLIP}(F, s_k) \right) \log \big( q(w_k) \big) \]Language Fluency Loss (Llanguage )
Maintains natural language quality by comparing outputs with and without soft prompts:
\[ L_{\text{language}} = CE\big(q(w_{i+1}), \hat{q}(w_{i+1})\big) \] where \[( q^{(w_{i+1})})\] is the output without soft tokens.Step 5: Inference and Post-Processing
During inference, the total loss is minimized over 16 iterations:
\[ L_{\text{total}} = \lambda_{l} L_{\text{language}} + \lambda_{s} L_{\text{Sretrieval}} + \lambda_{w} L_{\text{Wretrieval}} + \lambda_{v} L_{\text{vision}} \]After generating multiple candidate captions, RETTA selects the one with the highest CLIP-based similarity to the video:
\[ s^{*} = \arg\max_{m \in \{s_{1}, \dots, s_{M}\}} \left( T_{1} \sum_{F \in \mathcal{F}} \mathrm{CLIP}(F, s_{m}) \right) \]A sentence-cleaning strategy using CommonGen then refines the output for fluency and coherence.
Why RETTA Outperforms Existing Methods
RETTA sets a new benchmark in zero-shot video captioning across three major datasets:
| DATA | RETTA | PREVIOUS BEST | IMPROVEMENT |
|---|---|---|---|
| MSVD | 49.8 | 17.4 (EPT) | +32.4% |
| MSR-VTT | 24.3 | 18.6 (DeCap-COCO) | +30.6% |
| VATEX | 23.8 | 18.7 (DeCap-COCO) | +27.3% |
Source: Ma et al., Pattern Recognition, 2026
These gains are particularly significant given that CIDEr is a metric designed to measure vision-text relevance, not just linguistic fluency.
🔍 Key Advantages of RETTA
- ✅ No training required – Adapts during test time
- ✅ Fast adaptation – Only 16 iterations per video
- ✅ Robust to noise – Uses multi-granularity retrieval
- ✅ High content awareness – Leverages both sentence and keyword-level cues
- ✅ Fluent output – Enhanced with CommonGen post-processing
Ablation Studies: What Makes RETTA Tick?
The authors conducted extensive ablation studies on the VATEX dataset to validate each component:
| CONFIGURATION | BLEU@4 | METEOR | ROUGE-L | CIDER |
|---|---|---|---|---|
| Baseline | 1.4 | 9.8 | 19.4 | 8.9 |
| +LSretrieval | 2.5 | 13.3 | 22.6 | 20.8 |
| +LWretrieval | 2.6 | 12.2 | 22.1 | 14.9 |
| + Both losses | 2.4 | 13.5 | 22.9 | 21.4 |
| + Sentence cleaning | 11.4 | 16.3 | 32.6 | 23.8 |
As shown, both retrieval losses and post-processing are essential for optimal performance.
Real-World Applications of RETTA
RETTA’s zero-shot, fast-adaptation design makes it ideal for:
- 📹 Automated video summarization (e.g., YouTube, TikTok)
- 🧑🦯 Assistive technology for the visually impaired
- 🔍 Video search engines with natural language queries
- 📚 Educational content indexing
- 🌐 Multilingual captioning (with retrieval corpus in target language)
Because it doesn’t require labeled data, RETTA can be deployed immediately in new domains—no retraining needed.
Performance vs. Efficiency Trade-Off
While RETTA delivers superior performance, it comes with higher computational cost:
| METHOD | GPU MEMORY (MB) | INFERENCE TIME (S) | CIDER |
|---|---|---|---|
| DeCap-CC3M | 9656 | 0.1 | 18.4 |
| EPT | 4408 | 42.6 | 8.9 |
| RETTA | 9742 | 60.4 | 23.8 |
Despite slower inference, RETTA offers a favorable trade-off for offline or batch processing where accuracy is prioritized over speed.
RETTA for Image Captioning Too?
Yes! The authors show that by replacing XCLIP with CLIP, RETTA can be adapted for zero-shot image captioning. On MS-COCO, it achieves a CIDEr of 45.0, outperforming ZeroCap (+31.9) and EPT (+27.8).
| METHOD | CIDER |
|---|---|
| ZeroCap | 13.1 |
| MAGIC | 49.3 |
| RETTA | 45.0 |
This demonstrates the flexibility of the RETTA framework across modalities.
Limitations and Future Work
While RETTA is a major leap forward, it has some limitations:
- 🔒 Relies on a rich retrieval corpus – Performance drops if the corpus lacks relevant descriptions
- ⏱️ Slower inference – Due to multiple model integrations
- 🧠 Limited by pre-trained model capabilities – Cannot surpass the knowledge bounds of GPT-2 or CLIP
Future work includes:
- Building larger, more diverse retrieval corpora
- Extending to cross-domain video captioning
- Exploring lightweight model variants for real-time use
Conclusion: The Future of Zero-Shot Video Understanding
RETTA represents a paradigm shift in zero-shot video captioning. By combining retrieval, test-time adaptation, and multi-model collaboration, it achieves unprecedented performance without any training.
Its success highlights the power of modular AI systems—where frozen, pre-trained models are connected via learnable interfaces to solve complex tasks on the fly.
As vision-language models continue to evolve, frameworks like RETTA will pave the way for smarter, more adaptive AI systems that understand our world in real time.
Ready to Try RETTA?
Want to implement RETTA in your own video analysis pipeline? The authors plan to open-source their code, making it easy to integrate into your applications.
👉 Stay updated by following the official GitHub repository (coming soon).
👉 Subscribe to our newsletter for the latest in AI-powered video understanding.
👉 Share this article if you believe in the future of zero-shot AI!
Here is the end-to-end Python code for the RETTA (Retrieval-Enhanced Test-Time Adaptation) model as proposed in the paper.
# ==============================================================================
# RETTA: Retrieval-Enhanced Test-Time Adaptation for Zero-Shot Video Captioning
#
# This script provides a complete end-to-end implementation of the RETTA model
# as described in the paper. The model leverages several pre-trained frozen
# models to perform zero-shot video captioning through test-time adaptation.
#
# Paper: "RETTA: Retrieval-enhanced test-time adaptation for zero-shot video captioning"
#
# The implementation is consolidated into a single class for clarity and ease of use.
# ==============================================================================
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import (
CLIPProcessor, CLIPModel, CLIPImageProcessor,
XCLIPProcessor, XCLIPModel,
GPT2LMHeadModel, GPT2Tokenizer,
AutoTokenizer, AutoModel,
T5ForConditionalGeneration, T5Tokenizer
)
from torch.nn import functional as F
from collections import Counter
import numpy as np
import re
# Suppress warnings from the transformers library for cleaner output
import warnings
warnings.filterwarnings("ignore")
class RETTA(nn.Module):
"""
Implementation of the RETTA model for Zero-Shot Video Captioning.
This class integrates four main pre-trained models:
1. XCLIP: For video-text retrieval to get relevant sentence candidates.
2. CLIP: For image-text matching to guide generation (L_vision).
3. GPT-2: As the language model for generating captions.
4. AnglE: For calculating semantic similarity between texts (L_retrieval).
Additionally, it uses CommonGen for post-processing the generated caption.
"""
def __init__(self, device="cuda" if torch.cuda.is_available() else "cpu"):
super(RETTA, self).__init__()
self.device = device
print(f"Initializing RETTA on device: {self.device}")
# ================== 1. Load Pre-trained Models ==================
# These models are frozen during the process; only the soft prompts are trained.
# --- XCLIP for Video-Text Retrieval ---
# Used to retrieve relevant text descriptions for a given video.
print("Loading XCLIP model...")
self.xclip_model = XCLIPModel.from_pretrained("microsoft/xclip-base-patch16-kinetics-600").to(self.device)
self.xclip_processor = XCLIPProcessor.from_pretrained("microsoft/xclip-base-patch16-kinetics-600")
# --- CLIP for Image-Text Matching (L_vision) ---
# Used to score the alignment between video frames and generated text.
print("Loading CLIP model...")
self.clip_model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(self.device)
self.clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
self.clip_image_processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
# --- GPT-2 for Text Generation ---
# The core language model that generates the caption.
print("Loading GPT-2 model...")
self.gpt2_model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2-medium").to(self.device)
self.gpt2_tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2-medium")
self.gpt2_tokenizer.pad_token = self.gpt2_tokenizer.eos_token
# --- AnglE for Text-Text Similarity (L_retrieval) ---
# Used to measure similarity between generated text and retrieved sentences.
print("Loading AnglE model...")
self.angle_tokenizer = AutoTokenizer.from_pretrained('WhereIsAI/UAE-Large-V1')
self.angle_model = AutoModel.from_pretrained('WhereIsAI/UAE-Large-V1').to(self.device)
# --- CommonGen for Sentence Cleaning ---
# A T5 model fine-tuned for constrained text generation to improve fluency.
print("Loading CommonGen model...")
self.commongen_model = T5ForConditionalGeneration.from_pretrained("mrm8488/t5-base-finetuned-common_gen").to(self.device)
self.commongen_tokenizer = T5Tokenizer.from_pretrained("mrm8488/t5-base-finetuned-common_gen")
# Freeze all model parameters
for model in [self.xclip_model, self.clip_model, self.gpt2_model, self.angle_model, self.commongen_model]:
for param in model.parameters():
param.requires_grad = False
print("All models loaded and frozen successfully.")
# ================== 2. Helper Functions ==================
def _get_angle_embedding(self, text):
"""Computes the AnglE embedding for a given text."""
inputs = self.angle_tokenizer(text, padding=True, truncation=True, return_tensors='pt').to(self.device)
with torch.no_grad():
outputs = self.angle_model(**inputs)
embedding = F.normalize(outputs.last_hidden_state[:, 0], p=2, dim=1)
return embedding
def _get_angle_similarity(self, text1, text2):
"""Computes cosine similarity between two texts using AnglE."""
emb1 = self._get_angle_embedding(text1)
emb2 = self._get_angle_embedding(text2)
return F.cosine_similarity(emb1, emb2, dim=1)
def _filter_redundant_frames(self, frames, threshold=0.9):
"""
Filters redundant frames based on CLIP similarity, as described in Section 4.2.
Args:
frames (list of PIL Images): The frames extracted from the video.
threshold (float): Similarity threshold to identify redundant frames.
Returns:
list of PIL Images: A list of keyframes.
"""
if not frames:
return []
keyframes = [frames[0]]
anchor_frame = frames[0]
# Get CLIP embeddings for all frames at once for efficiency
with torch.no_grad():
inputs = self.clip_image_processor(images=frames, return_tensors="pt").to(self.device)
image_features = self.clip_model.get_image_features(**inputs)
image_features = F.normalize(image_features)
anchor_features = image_features[0]
for i in range(1, len(frames)):
current_features = image_features[i]
similarity = torch.dot(anchor_features, current_features)
if similarity < threshold:
keyframes.append(frames[i])
anchor_features = current_features # Update anchor
return keyframes
# ================== 3. Core Modules of RETTA ==================
def video_text_retrieval(self, video_frames, text_corpus, k=15, freq_size=5):
"""
Retrieves relevant sentences and high-frequency words from a text corpus. (Section 3.1)
Args:
video_frames (list of PIL Images): Frames from the input video.
text_corpus (list of str): A corpus of sentences to retrieve from.
k (int): The number of top sentences to retrieve.
freq_size (int): The number of high-frequency nouns/verbs to extract.
Returns:
tuple: (retrieved_sentences, high_frequency_words)
"""
# Process video and text for XCLIP
inputs = self.xclip_processor(
text=text_corpus,
videos=list(video_frames), # XCLIP expects a list of frames
return_tensors="pt",
padding=True,
).to(self.device)
# Get video and text features
with torch.no_grad():
outputs = self.xclip_model(**inputs)
# Compute similarity scores
logits_per_video = outputs.logits_per_video
probs = logits_per_video.softmax(dim=1)
# Get top-k sentences
top_k_indices = torch.topk(probs.squeeze(), k).indices.cpu().numpy()
retrieved_sentences = [text_corpus[i] for i in top_k_indices]
# Extract high-frequency nouns and verbs (simplified version)
all_words = []
for sentence in retrieved_sentences:
# Simple regex to find words, could be replaced with NLTK for POS tagging
words = re.findall(r'\b\w+\b', sentence.lower())
all_words.extend(words)
word_counts = Counter(all_words)
# In a real scenario, you would filter for nouns/verbs here.
# For simplicity, we take the most common words.
high_frequency_words = [word for word, _ in word_counts.most_common(freq_size)]
return retrieved_sentences, high_frequency_words
def clean_caption_with_commongen(self, caption):
"""
Cleans the generated caption using CommonGen for better fluency. (Section 3.3)
Args:
caption (str): The noisy caption generated by the model.
Returns:
str: A cleaned, more fluent caption.
"""
# Extract key elements (nouns/verbs). Simple regex used for demonstration.
# A proper implementation would use a POS tagger.
words = re.findall(r'\b\w{3,}\b', caption.lower()) # Get words with 3+ letters
# For this example, we'll just use all unique words as keywords
keywords = " ".join(sorted(list(set(words))))
input_text = f"generate a sentence with: {keywords}"
input_ids = self.commongen_tokenizer.encode(input_text, return_tensors="pt").to(self.device)
with torch.no_grad():
output_ids = self.commongen_model.generate(
input_ids,
max_length=32,
num_beams=5,
early_stopping=True
)
cleaned_caption = self.commongen_tokenizer.decode(output_ids[0], skip_special_tokens=True)
return cleaned_caption
def generate_caption(self, video_frames, text_corpus, config):
"""
The main function to generate a caption for a video.
This function orchestrates the entire RETTA process.
Args:
video_frames (list of PIL Images): Input video frames.
text_corpus (list of str): Text corpus for retrieval.
config (dict): A dictionary of hyperparameters.
Returns:
str: The final, cleaned video caption.
"""
# --- Hyperparameters ---
num_soft_tokens = config.get("num_soft_tokens", 5)
lr = config.get("lr", 1e-4)
weight_decay = config.get("weight_decay", 0.3)
num_iterations = config.get("num_iterations", 16)
max_seq_len = config.get("max_seq_len", 15)
lambda_l = config.get("lambda_l", 1.6)
lambda_s = config.get("lambda_s", 1.0)
lambda_w = config.get("lambda_w", 0.8)
lambda_v = config.get("lambda_v", 0.3)
num_candidate_words = config.get("num_candidate_words", 100)
hard_prompts = ["Video showing", "Video of", "Video shows"]
# ================== Step 1: Video-Text Retrieval ==================
retrieved_sentences, high_freq_words = self.video_text_retrieval(video_frames, text_corpus)
print(f"Retrieved Sentences: {retrieved_sentences[:3]}")
print(f"High-Frequency Words: {high_freq_words}")
# ================== Step 2: Test-Time Adaptation ==================
# --- Initialize learnable soft prompts ---
soft_prompt_embeddings = torch.randn(
1, num_soft_tokens, self.gpt2_model.config.n_embd,
device=self.device, requires_grad=True
)
optimizer = optim.AdamW([soft_prompt_embeddings], lr=lr, weight_decay=weight_decay)
# --- Filter frames for efficiency ---
keyframes = self._filter_redundant_frames(video_frames)
if not keyframes:
print("Warning: No keyframes found after filtering.")
return "Could not process video."
clip_image_inputs = self.clip_processor(images=keyframes, return_tensors="pt").to(self.device)
with torch.no_grad():
image_features = self.clip_model.get_image_features(**clip_image_inputs)
generated_captions = []
for i in range(num_iterations):
print(f"\n--- Iteration {i+1}/{num_iterations} ---")
# --- Setup prompts ---
hard_prompt = np.random.choice(hard_prompts)
hard_prompt_ids = self.gpt2_tokenizer.encode(hard_prompt, return_tensors="pt").to(self.device)
hard_prompt_embeds = self.gpt2_model.transformer.wte(hard_prompt_ids)
# This will store the generated sequence for this iteration
generated_ids = []
# --- Autoregressive Generation with Optimization ---
for step in range(max_seq_len):
if step == 0:
# At the first step, combine soft and hard prompts
current_embeds = torch.cat([soft_prompt_embeddings, hard_prompt_embeds], dim=1)
else:
# After the first step, use the embedding of the last generated token
last_token_id = torch.tensor([[generated_ids[-1]]], device=self.device)
last_token_embed = self.gpt2_model.transformer.wte(last_token_id)
current_embeds = torch.cat([current_embeds, last_token_embed], dim=1)
# Get GPT-2 logits
outputs = self.gpt2_model(inputs_embeds=current_embeds)
next_token_logits = outputs.logits[:, -1, :]
# Get top candidate words for loss calculation
top_k_logits, top_k_indices = torch.topk(next_token_logits, num_candidate_words)
candidate_words = self.gpt2_tokenizer.convert_ids_to_tokens(top_k_indices.squeeze().cpu().numpy())
# --- Calculate Losses (Section 3.2) ---
# Formulate candidate sentences for loss calculation
current_text = self.gpt2_tokenizer.decode(generated_ids)
candidate_sentences = [f"{current_text} {word}".strip() for word in candidate_words]
# L_retrieval^S (Eq. 2 & 3)
sim_s = self._get_angle_similarity(candidate_sentences, retrieved_sentences)
p_wk_s = sim_s.mean(dim=0) # Average over retrieved sentences
q_wk = F.softmax(top_k_logits.squeeze(), dim=0)
loss_retrieval_s = F.kl_div(q_wk.log(), p_wk_s, reduction='sum')
# L_retrieval^W (Eq. 4 & 5)
sim_w = self._get_angle_similarity(candidate_sentences, high_freq_words)
p_wk_w = sim_w.mean(dim=0) # Average over high-freq words
loss_retrieval_w = F.kl_div(q_wk.log(), p_wk_w, reduction='sum')
# L_vision (Eq. 6)
text_inputs = self.clip_processor(text=candidate_sentences, return_tensors="pt", padding=True).to(self.device)
with torch.no_grad():
text_features = self.clip_model.get_text_features(**text_inputs)
sim_v = (image_features @ text_features.T).mean(dim=0) # Average over keyframes
p_wk_v = F.softmax(sim_v, dim=0)
loss_vision = F.kl_div(q_wk.log(), p_wk_v, reduction='sum')
# L_language (Eq. 7 & 8)
with torch.no_grad():
# Get logits without the soft prompt
if not generated_ids:
prompt_for_lang_loss = hard_prompt_embeds
else:
generated_embeds = self.gpt2_model.transformer.wte(torch.tensor([generated_ids], device=self.device))
prompt_for_lang_loss = torch.cat([hard_prompt_embeds, generated_embeds], dim=1)
vanilla_outputs = self.gpt2_model(inputs_embeds=prompt_for_lang_loss)
vanilla_logits = vanilla_outputs.logits[:, -1, :]
vanilla_prob = F.softmax(vanilla_logits, dim=-1)
current_prob = F.softmax(next_token_logits, dim=-1)
loss_language = F.cross_entropy(current_prob, vanilla_prob.squeeze())
# Total Loss (Eq. 9)
total_loss = (lambda_l * loss_language +
lambda_s * loss_retrieval_s +
lambda_w * loss_retrieval_w +
lambda_v * loss_vision)
# --- Optimization Step ---
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# --- Generate next token ---
# We use the optimized distribution to sample the next token
next_token_id = torch.argmax(next_token_logits, dim=-1).item()
if next_token_id == self.gpt2_tokenizer.eos_token_id:
break
generated_ids.append(next_token_id)
# Decode the generated sentence for this iteration
iter_caption = self.gpt2_tokenizer.decode(generated_ids, skip_special_tokens=True)
generated_captions.append(iter_caption)
print(f"Generated Caption: '{iter_caption}' | Loss: {total_loss.item():.4f}")
# ================== Step 3: Select Best Caption and Clean ==================
# Select the best caption based on CLIP similarity (Eq. 10)
if not generated_captions:
return "Failed to generate any captions."
clip_text_inputs = self.clip_processor(text=generated_captions, return_tensors="pt", padding=True).to(self.device)
with torch.no_grad():
text_features = self.clip_model.get_text_features(**clip_text_inputs)
# Calculate similarity between each generated caption and the video (averaged over frames)
similarities = (image_features @ text_features.T).mean(dim=0)
best_caption_idx = torch.argmax(similarities).item()
best_caption = generated_captions[best_caption_idx]
print(f"\nBest caption before cleaning: '{best_caption}'")
# Clean the best caption using CommonGen
final_caption = self.clean_caption_with_commongen(best_caption)
print(f"Final cleaned caption: '{final_caption}'")
return final_caption
# ==============================================================================
# Example Usage
# ==============================================================================
if __name__ == '__main__':
# --- 1. Setup ---
# In a real application, you would load a video and extract its frames.
# Here, we simulate this with placeholder data.
print("Setting up mock data for demonstration...")
# Mock video frames (e.g., 16 frames of size 224x224)
# Replace this with your actual video frame loading logic.
# For example, using OpenCV or PyAV.
from PIL import Image
mock_video_frames = [Image.new('RGB', (224, 224), color = (i * 10, 100, 200)) for i in range(16)]
# Mock text corpus for retrieval
# This should be the text from the training split of your dataset (e.g., MSR-VTT)
mock_text_corpus = [
"a man is playing a guitar",
"a woman is chopping vegetables in a kitchen",
"two people are playing ping pong",
"a group of friends are laughing",
"a tutorial on how to bake a cake",
"someone is writing on a whiteboard",
"a car is driving down a city street at night",
"a cat is sleeping on a couch",
"a person is demonstrating a science experiment",
"a man talks about grammar and writing",
"a writer discusses the true meaning of grammar",
"video about higher education",
"someone is writing something",
"a man is splitting a piece of bread",
"cooking shrimp in oil",
]
# --- 2. Initialize Model ---
retta_model = RETTA()
# --- 3. Define Hyperparameters ---
config = {
"num_soft_tokens": 5,
"lr": 1e-4,
"weight_decay": 0.3,
"num_iterations": 16, # Paper uses 16
"max_seq_len": 15,
"lambda_l": 1.6,
"lambda_s": 1.0,
"lambda_w": 0.8,
"lambda_v": 0.3,
"num_candidate_words": 100,
}
# --- 4. Generate Caption ---
print("\nStarting video captioning process...")
final_caption = retta_model.generate_caption(mock_video_frames, mock_text_corpus, config)
print("\n" + "="*50)
print(f" FINAL GENERATED CAPTION")
print("="*50)
print(final_caption)
print("="*50)
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- 1 Revolutionary Breakthrough in AI Object Detection: GridCLIP vs. Two-Stage Models
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.com/join?ref=QCGZMHR6
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/cs/register-person?ref=OMM3XK51