Key Points
- ACAM-KD pairs a teacher generated query with student generated key and value inside a cross attention module called STCA-FF, fusing both networks’ features instead of copying the teacher outright.
- A second module, Adaptive Spatial-Channel Masking, learns separate spatial and channel masks from the fused features so distillation attention keeps shifting as the student improves rather than freezing at initialization.
- On COCO2017 the method lifts a ResNet-50 student trained under a ResNet-101 teacher by up to 1.4 mAP over the strongest prior distillation baseline, with the largest gain landing on anchor free detectors.
- On Cityscapes the DeepLabV3 student built on MobileNetV2 gains 3.09 mIoU over its unaided baseline, closing meaningful ground against its much larger DeepLabV3-ResNet101 teacher.
- An ablation shows that letting the teacher alone adapt its own mask barely moves the result. The real gain comes from involving the student in generating the fused features the mask acts on.
The Problem With Letting The Teacher Pick Every Lesson
Most feature based knowledge distillation work follows a familiar script. Take a bulky teacher network, decide which regions of its feature maps look most informative, then push the smaller student network to mimic exactly those regions. FGFI drew boxes near ground truth objects and told the student to focus there. GID went further and highlighted spots where teacher and student predictions disagreed. FKD leaned on the teacher’s own high attention areas, and FGD folded in both bounding boxes and global context. More recent entries such as MasKD and FreeKD tried to make the selection learnable rather than hand designed, using receptive tokens or frequency domain prompts pulled from the teacher. Every one of these shares a quiet assumption. The teacher already knows where to look, and the student’s job is to accept that judgment without question.
Lan and Tian push back on that assumption with a simple piece of evidence tucked into their opening figure. They track a student’s attention map across training and place it next to the teacher’s own fixed attention on the same image. At epoch 4 the student is still confused, its attention scattered loosely around the frame. By epoch 12 something interesting happens. The student’s attention tightens onto the foreground object more precisely than the teacher ever manages, since the teacher’s map never moves once training starts. Then, oddly, by epoch 24 the student’s attention drifts back toward resembling the teacher’s static pattern instead of continuing to refine its own read of the scene. Read that sequence closely and the implication is uncomfortable for the entire family of teacher driven masking methods. A frozen teacher can be actively wrong about where a student should be looking at a given moment, and forcing alignment with that fixed opinion can undo progress the student had already made on its own.
There is a second gap the authors call out, one that gets less attention in the wider literature. Almost every masking method described above operates purely in the spatial domain, deciding which pixels matter while treating every channel of a feature map as equally important. Channels in a convolutional feature map are not interchangeable. Some encode texture, some encode shape, some barely activate at all for a given input. A masking scheme that only ever asks where to look while ignoring what to look at is leaving useful signal sitting on the table.
How ACAM-KD Works
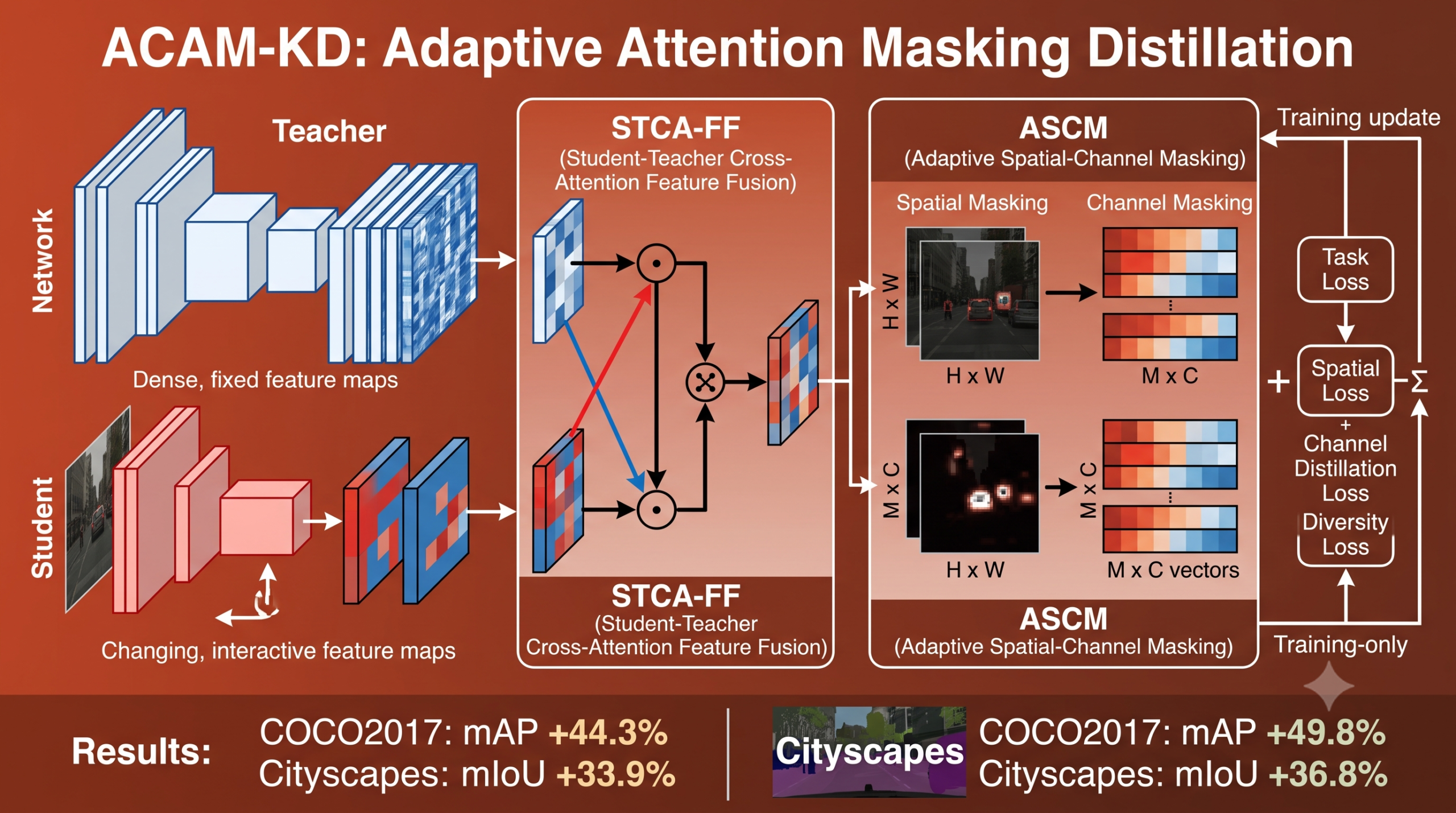
ACAM-KD answers both gaps with two modules that run back to back inside an existing feature distillation pipeline, typically attached to the neck of a detector or the decoder of a segmentation network. The first module fuses teacher and student features through attention instead of copying one onto the other. The second module turns that fused representation into spatial and channel masks that keep updating as training proceeds. You can read more about the University of Alabama at Birmingham team’s full method in the original paper on arXiv, later accepted at ICCV 2025.
Student Teacher Cross Attention Feature Fusion
STCA-FF, short for Student-Teacher Cross-Attention Feature Fusion, treats the teacher’s feature map as a question and the student’s feature map as the source of the answer. Given teacher features F superscript T and student features F superscript S, both shaped as channels by height by width, a 1 by 1 convolution projects the teacher map into a query and projects the student map into a key and a value.
The query and key are compressed to half the original channel count, which keeps the attention computation manageable at typical feature map resolutions. After flattening both tensors across their spatial dimensions, the attention weights follow the familiar scaled dot product form.
Multiplying those attention weights against the student’s value tensor produces the fused feature map that everything downstream operates on.
The choice to let the teacher generate the query rather than the student is not arbitrary. An ablation in the paper tests both directions directly, and letting the teacher ask the questions edges out the alternative by 0.2 mAP overall, with the largest gain concentrated in small object detection. The authors read this as evidence that the teacher’s features still provide a more stable reference point for retrieval, even while the student contributes the content being retrieved. Cooperation here does not mean the two networks are equal partners. It means the student finally gets a vote instead of none at all.
Adaptive Spatial-Channel Masking
Once the fused features exist, ASCM turns them into masks. The module keeps two families of learnable selection units, one operating on a pooled channel vector and one on the spatially flattened feature map, each passed through a sigmoid to produce a bounded importance weight.
Both sets of masks feed their own distillation loss, one weighting the difference between teacher and student features by channel importance and the other by spatial importance.
For object detection the authors use six masks for each family, a number chosen empirically. For semantic segmentation on Cityscapes they instead set the mask count to nineteen. Matching that number to the dataset’s class count looks like a deliberate design choice, since it nudges each learnable mask toward specializing around a particular semantic category rather than an arbitrary spatial split. It is a small detail, easy to skim past, and one of the more thoughtful pieces of task specific tuning in the paper.
Keeping The Masks From Repeating Themselves
Learnable masks have an obvious failure mode. Nothing in the basic setup stops all of them from converging on the same region, which would waste the extra capacity of having several masks in the first place. ACAM-KD heads this off with a Dice coefficient based diversity loss that penalizes pairwise overlap between masks while normalizing by their combined magnitude.
A figure later in the paper shows five spatial masks trained on the same tennis scene, each lighting up a visibly different part of the frame, from the player’s torso to the racket to the ball’s flight path. That spread is not incidental. It is the direct, visible result of the diversity term doing its job, and a good reminder that a regularization loss most readers skim past in the equations section can be the difference between six masks that behave like copies of one idea and six masks that actually divide the labor.
The Math Behind The Combined Objective
It helps to see where the field started before looking at where ACAM-KD lands. The generic feature distillation objective that most prior work builds on applies a single mask element wise to the difference between teacher and student features.
ACAM-KD keeps that same basic shape but swaps in two masks instead of one, plus a term that keeps those masks from collapsing into each other. The full training objective sums the ordinary task loss for whichever downstream job the student is learning, the channel and spatial distillation losses, and the diversity loss, with each distillation term weighted by a coefficient the authors set to one across every experiment in the paper.
That simplicity is worth pausing on. A method that needed heavy tuning of alpha and lambda to work would be a harder sell for anyone trying to reproduce it. Setting both to a flat value of one and still beating six or more specialized baselines across three detector families and three segmentation backbones is a meaningfully stronger result than the raw mAP numbers alone suggest.
What The Numbers Show
Object Detection On COCO2017
The authors test ACAM-KD across three detector families on the COCO2017 benchmark, a dataset of roughly 118000 training images and 5000 validation images spanning 80 object categories. Every configuration pairs a ResNet-50 student against either a ResNet-101 or a much larger ResNeXt-101 teacher.
| Detector | Teacher | Student Baseline | Best Prior KD Method | ACAM-KD |
|---|---|---|---|---|
| RetinaNet (single stage) | ResNet-101, 38.9 mAP | 37.4 mAP | FreeKD, 39.9 mAP | 41.2 mAP |
| Faster R-CNN (two stage) | ResNet-101, 39.8 mAP | 38.4 mAP | MasKD / FreeKD, 40.8 mAP | 41.4 mAP |
| RepPoints (anchor free) | ResNet-101, 40.5 mAP | 38.6 mAP | MasKD, 41.1 mAP | 42.5 mAP |
Against the ResNet-101 teacher, ACAM-KD reaches 41.2 mAP with a RetinaNet student, 41.4 mAP with Faster R-CNN, and 42.5 mAP with the anchor free RepPoints detector. Every one of those numbers beats the next best published distillation method, and the anchor free case shows the largest jump, a full 1.4 mAP over MasKD. Swap in the bigger ResNeXt-101 teacher and the gains grow further still, with the RepPoints student climbing to 42.8 mAP against a 38.6 mAP baseline, a 4.2 point improvement that starts to close real ground against a teacher scoring 44.2 mAP on its own.
Semantic Segmentation On Cityscapes
Segmentation results follow the same pattern on Cityscapes, a street scene dataset built from 5000 finely annotated images captured across 50 cities. All students distill from a DeepLabV3 network with a ResNet-101 backbone scoring 78.07 mIoU on its own.
| Student Model | Baseline mIoU | Best Prior KD Method | ACAM-KD mIoU |
|---|---|---|---|
| DeepLabV3-MobileNetV2 | 73.12 | CIRKD, 75.42 | 76.21 |
| DeepLabV3-R18 | 72.96 | MasKD, 77.00 | 77.53 |
| PSPNet-R18 | 72.55 | MasKD, 75.34 | 75.99 |
The DeepLabV3-MobileNetV2 student improves from a 73.12 mIoU baseline to 76.21 mIoU, a 3.09 point gain that also beats the closest competing method by nearly a full point. DeepLabV3-R18 reaches 77.53 mIoU, within half a point of its much heavier teacher despite using a fraction of the parameters. PSPNet-R18, tested as a mismatched case where the student architecture differs from the teacher’s own DeepLabV3 design, still gains 3.44 mIoU over its own baseline, suggesting the fused attention approach is not narrowly tuned to one architecture family.
Inference Cost Stays Untouched
One detail worth stating plainly, since the paper itself does not dwell on it. STCA-FF and ASCM only exist during training. Once distillation finishes, the extra cross attention and masking parameters are discarded, and the deployed student runs with exactly the parameter count and FLOPs of its unaided baseline. The runtime tables in the paper, showing a ResNet-50 RetinaNet student running near 42 frames per second against a ResNeXt-101 teacher’s 29 frames per second, describe the speed the student ships with once training is finished, not a slower distilled network. For anyone weighing whether this method fits a production pipeline, that is the number that actually matters, and it is good news. All of the accuracy gain is free at inference time. The cost lands entirely during training, in the extra forward passes through the cross attention and masking modules alongside the frozen teacher network.
What The Ablations Reveal
The most telling experiment in the paper is not the headline comparison against other methods. It is the fixed versus adaptive masking test, where the authors dismantle their own system piece by piece. A RetinaNet student with no masking at all barely moves past the unaided baseline, sitting at 37.4 mAP either way. Adding a fixed mask learned offline by the teacher, the same style of approach used in MasKD, lifts that to 39.8 mAP. Then comes the comparison that matters most. Letting that teacher only mask keep adapting throughout training, rather than freezing it after one offline pass, produces almost no further improvement, landing at 39.9 mAP. Only when the student’s own features enter the fusion process through STCA-FF does performance jump again, reaching the full 41.2 mAP.
A frozen teacher can be wrong about where a student needs to look, and the fix is not simply letting the mask change over time. It is letting the student help decide where it points. Reading of Lan and Tian’s central argument, ACAM-KD, University of Alabama at Birmingham
A separate breakdown shows where the gain splits between the two mask types. Spatial masking alone reaches 40.9 mAP, channel masking alone reaches 40.4 mAP, and running them together reaches the full 41.2 mAP. Small objects respond most to spatial masking on its own, which tracks with the intuition that knowing where to look matters most when the object barely covers a handful of pixels. Medium and large objects benefit most once channel masking joins in, suggesting that for bigger objects the useful signal is less about pinpointing a location and more about which feature channels carry the relevant texture and shape information.
Where This Falls Short
No method is finished the moment a paper gets accepted, and ACAM-KD leaves several open questions. The experiments stay within object detection and semantic segmentation, both dense prediction tasks with a natural spatial structure that the spatial mask can exploit. Whether the same cross attention fusion helps for tasks with a very different output shape, pose estimation or depth estimation for instance, is untested. The mask count is set by hand, six for detection and nineteen for Cityscapes segmentation, and the paper does not report a sensitivity study showing how performance moves if that number is doubled or halved. The loss weighting terms alpha and lambda are both fixed at one across every experiment, which is convenient for reproducibility but leaves open whether more careful tuning could push results further, or whether the flat setting is itself evidence the method is unusually robust. Finally, the added training cost of running a teacher forward pass alongside a cross attention module and two mask generators is not reported in FLOPs or wall clock time anywhere in the paper, which makes it hard to judge how much longer a full training run takes compared to a plain feature distillation baseline.
A Working PyTorch Implementation
The code below implements STCA-FF and ASCM as standalone modules, wires them into the combined loss from the paper, and runs a smoke test on random tensors so you can confirm shapes and gradient flow before plugging in real teacher and student backbones. One note on faithfulness. The paper’s notation for the channel and spatial selection units is slightly inconsistent between the method text and the loss equations. This implementation follows the tensor shapes implied by the loss functions themselves, channel masks shaped as mask count by channels and spatial masks shaped as mask count by height by width, since those are the shapes the paper actually uses once it reaches the equations that matter for training.
# acam_kd.py # Reference style implementation of ACAM-KD # Lan and Tian, ACAM-KD, Adaptive and Cooperative Attention Masking for Knowledge Distillation # arXiv:2503.06307 import torch import torch.nn as nn import torch.nn.functional as F class STCAFeatureFusion(nn.Module): """Student-Teacher Cross-Attention Feature Fusion (STCA-FF). Teacher features supply the query. Student features supply the key and the value. This mirrors the ablation in the paper showing that a teacher generated query outperforms a student generated one. """ def __init__(self, channels, reduction=2): super().__init__() reduced = max(channels // reduction, 8) self.q_proj = nn.Conv2d(channels, reduced, kernel_size=1) self.k_proj = nn.Conv2d(channels, reduced, kernel_size=1) self.v_proj = nn.Conv2d(channels, channels, kernel_size=1) self.scale = reduced ** 0.5 def forward(self, feat_teacher, feat_student): # feat_teacher, feat_student: (B, C, H, W), already spatially aligned b, c, h, w = feat_teacher.shape q = self.q_proj(feat_teacher).flatten(2).transpose(1, 2) # (B, HW, Cq) k = self.k_proj(feat_student).flatten(2) # (B, Cq, HW) v = self.v_proj(feat_student).flatten(2).transpose(1, 2) # (B, HW, C) attn = torch.bmm(q, k) / self.scale # (B, HW, HW) attn = F.softmax(attn, dim=-1) fused = torch.bmm(attn, v) # (B, HW, C) fused = fused.transpose(1, 2).reshape(b, c, h, w) return fused class AdaptiveSpatialChannelMasking(nn.Module): """Adaptive Spatial-Channel Masking (ASCM). Produces M channel masks of shape (M, C) and M spatial masks of shape (M, H, W) from the fused teacher student features. """ def __init__(self, channels, num_masks=6): super().__init__() self.num_masks = num_masks self.channel_units = nn.Parameter(torch.randn(num_masks, channels) * 0.02) self.spatial_units = nn.Parameter(torch.randn(num_masks, channels) * 0.02) def forward(self, fused): # fused: (B, C, H, W) b, c, h, w = fused.shape v = fused.mean(dim=[2, 3]) # (B, C) spatially pooled vector z = fused.flatten(2) # (B, C, HW) # channel masks: (B, M, C) channel_logits = torch.einsum("bc,mc->bm", v, self.channel_units) channel_mask = torch.sigmoid(channel_logits).unsqueeze(-1) * torch.sigmoid(self.channel_units).unsqueeze(0) # spatial masks: (B, M, HW) then reshaped to (B, M, H, W) spatial_logits = torch.einsum("bchw,mc->bmhw", fused, self.spatial_units) spatial_mask = torch.sigmoid(spatial_logits) return channel_mask, spatial_mask def masked_distill_loss_channel(feat_teacher, feat_student_aligned, channel_mask, eps=1e-6): # channel_mask: (B, M, C), feature diff: (B, C, H, W) b, m, c = channel_mask.shape diff = feat_teacher - feat_student_aligned # (B, C, H, W) h, w = diff.shape[-2:] total = torch.tensor(0.0, device=diff.device) for mi in range(m): weight = channel_mask[:, mi, :].view(b, c, 1, 1) # (B, C, 1, 1) norm = weight.sum(dim=1).clamp_min(eps) * h * w term = ((weight * diff) ** 2).sum(dim=[1, 2, 3]) / norm.squeeze() total = total + term.mean() return total / m def masked_distill_loss_spatial(feat_teacher, feat_student_aligned, spatial_mask, eps=1e-6): # spatial_mask: (B, M, H, W), feature diff: (B, C, H, W) b, m, h, w = spatial_mask.shape diff = feat_teacher - feat_student_aligned c = diff.shape[1] total = torch.tensor(0.0, device=diff.device) for mi in range(m): weight = spatial_mask[:, mi, :, :].unsqueeze(1) # (B, 1, H, W) norm = weight.sum(dim=[2, 3]).clamp_min(eps) * c term = ((weight * diff) ** 2).sum(dim=[1, 2, 3]) / norm.squeeze() total = total + term.mean() return total / m def diversity_loss(masks, eps=1e-6): # masks: (B, M, N) where N is C for channel masks or H*W for spatial masks b, m, n = masks.shape flat = masks.reshape(b, m, n) gram = torch.bmm(flat, flat.transpose(1, 2)) # (B, M, M) pairwise dot products diag = torch.diagonal(gram, dim1=1, dim2=2) # (B, M) off_diag_sum = gram.sum(dim=[1, 2]) - diag.sum(dim=1) denom = (2 * diag.sum(dim=1)).clamp_min(eps) return (off_diag_sum / denom).mean() class ACAMKD(nn.Module): """Full ACAM-KD module, combining STCA-FF, ASCM, and the three losses into the objective used for feature based distillation.""" def __init__(self, teacher_channels, student_channels, num_masks=6, alpha=1.0, lam=1.0): super().__init__() self.align = nn.Conv2d(student_channels, teacher_channels, kernel_size=1) self.fusion = STCAFeatureFusion(teacher_channels) self.masking = AdaptiveSpatialChannelMasking(teacher_channels, num_masks=num_masks) self.alpha = alpha self.lam = lam def forward(self, feat_teacher, feat_student): feat_student_aligned = self.align(feat_student) fused = self.fusion(feat_teacher, feat_student_aligned) channel_mask, spatial_mask = self.masking(fused) l_channel = masked_distill_loss_channel(feat_teacher, feat_student_aligned, channel_mask) l_spatial = masked_distill_loss_spatial(feat_teacher, feat_student_aligned, spatial_mask) b, m, c = channel_mask.shape h, w = spatial_mask.shape[-2:] l_div = diversity_loss(channel_mask) + diversity_loss(spatial_mask.reshape(b, m, h * w)) l_distill = self.alpha * (l_channel + l_spatial) + self.lam * l_div return l_distill, {"l_channel": l_channel.item(), "l_spatial": l_spatial.item(), "l_div": l_div.item()} def train_step(acam_module, task_loss_fn, feat_teacher, feat_student, task_output, task_target, optimizer): optimizer.zero_grad() task_loss = task_loss_fn(task_output, task_target) distill_loss, logs = acam_module(feat_teacher, feat_student) total_loss = task_loss + distill_loss total_loss.backward() optimizer.step() logs["task_loss"] = task_loss.item() logs["total_loss"] = total_loss.item() return logs def evaluate(acam_module, feat_teacher_batches, feat_student_batches): acam_module.eval() total = 0.0 with torch.no_grad(): for ft, fs in zip(feat_teacher_batches, feat_student_batches): loss, _ = acam_module(ft, fs) total += loss.item() acam_module.train() return total / len(feat_teacher_batches) if __name__ == "__main__": torch.manual_seed(0) # Dummy feature maps standing in for an FPN level from a teacher and a student batch, teacher_c, student_c, height, width = 2, 256, 128, 20, 20 feat_teacher = torch.randn(batch, teacher_c, height, width) feat_student = torch.randn(batch, student_c, height, width) acam = ACAMKD(teacher_channels=teacher_c, student_channels=student_c, num_masks=6) optimizer = torch.optim.SGD(acam.parameters(), lr=0.01, momentum=0.9) # Stand in task loss and task output, since a real detector head is out of scope here dummy_task_output = torch.randn(batch, 10, requires_grad=True) dummy_task_target = torch.randn(batch, 10) task_loss_fn = nn.MSELoss() print("Running ACAM-KD smoke test on dummy tensors") for step in range(3): logs = train_step(acam, task_loss_fn, feat_teacher, feat_student, dummy_task_output, dummy_task_target, optimizer) print(f"step {step} total_loss {logs['total_loss']:.4f} l_channel {logs['l_channel']:.4f} " f"l_spatial {logs['l_spatial']:.4f} l_div {logs['l_div']:.4f}") eval_loss = evaluate(acam, [feat_teacher], [feat_student]) print(f"eval distillation loss {eval_loss:.4f}") assert logs["total_loss"] == logs["total_loss"], "loss produced NaN" print("Smoke test passed. Shapes and gradients look correct.")
Where ACAM-KD Ends Up
ACAM-KD’s central achievement is fairly narrow to state and fairly broad in consequence. Give the student a real vote in deciding what to learn next, using attention instead of a copy operation, and measurable accuracy follows across three different detector families and three different segmentation backbones without touching inference cost. The numbers back that up consistently rather than in one cherry picked configuration, from a 1.4 mAP gain distilling into RepPoints to a 3.44 mIoU gain distilling into PSPNet-R18.
The more interesting shift is conceptual. Knowledge distillation has largely been framed as a one way transfer, a smaller network copying a larger one as faithfully as budget allows. ACAM-KD treats it closer to a negotiation, where the teacher still sets the terms of the query but the student supplies the content being retrieved and, through the masks that follow, helps decide which of that content is worth emphasizing at a given moment in training. The fixed versus adaptive masking ablation makes clear that adaptability alone, without that negotiation, buys almost nothing. It is the interaction that matters, not just the ability to change over time.
Nothing about the cross attention fusion or the mask generation is specific to convolutional backbones or to detection and segmentation heads. The same fuse then mask pattern could plausibly extend to distilling vision transformers, where attention is already the native operation rather than something added on for this purpose, or to graph neural networks, where a node level analog of the spatial mask could highlight which nodes in a graph carry the most transferable structure. Federated settings, where a shared global model distills into many mismatched local models under tight bandwidth limits, are another natural fit, since the interaction cost between one teacher and one student is exactly what this method is built around.
None of that erases the open questions raised earlier. The mask counts are hand set, the extra training cost is unreported, and every result sits inside object detection and segmentation on two benchmark datasets. A reader deciding whether to build on this work should treat the headline mAP and mIoU numbers as strong evidence for the two tasks tested, and as a reasonable but unproven hypothesis for anything else.
Strip away the acronym and the equations, and ACAM-KD is making a fairly commonsense argument dressed up in attention math. A teacher that never updates its opinion about where a student should be looking is going to be wrong some of the time, and letting the student push back, even a little, turns out to be worth more than making that same fixed opinion merely adjustable.
Frequently Asked Questions
What problem does ACAM-KD solve in knowledge distillation
It replaces fixed, teacher only feature selection with a cross attention fusion between teacher and student features, followed by masks that keep updating throughout training instead of freezing after one offline pass.
How is ACAM-KD different from MasKD or FreeKD
MasKD learns receptive tokens from the teacher alone in one offline pass, and FreeKD builds a frequency domain prompt from teacher features. Both keep the student passive. ACAM-KD instead lets the student contribute the key and value inside a cross attention module, so the resulting mask reflects both networks rather than the teacher by itself.
Does ACAM-KD make the student model slower at inference
No. The cross attention fusion module and the mask generators only run during training. Once distillation finishes, the student keeps its original parameter count and FLOPs, so deployment speed is unaffected.
Which datasets and models were used to test ACAM-KD
Object detection results come from COCO2017 across RetinaNet, Faster R-CNN, and RepPoints detectors, using ResNet-50 students against ResNet-101 or ResNeXt-101 teachers. Segmentation results come from Cityscapes using DeepLabV3 and PSPNet students with ResNet-18 or MobileNetV2 backbones against a DeepLabV3-ResNet101 teacher.
Why does the mask count change between detection and segmentation experiments
For detection the authors use six masks per family, chosen empirically. For Cityscapes segmentation they set the count to nineteen to match the number of semantic classes, encouraging each mask to specialize around a category rather than an arbitrary region.
What does the diversity loss do
It penalizes overlap between the learnable masks using a Dice coefficient based term, which stops every mask from converging on the same region and keeps them covering complementary parts of the feature map.
Read the full method, tables, and ablations directly from the source.
This analysis is based on the published paper and an independent evaluation of its claims.
Pingback: Hierarchical Spatio-temporal Segmentation Network (HSS-Net) for Accurate Ejection Fraction Estimation - aitrendblend.com
Pingback: A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models - aitrendblend.com
Pingback: Capsule Networks Do Not Need to Model Everything: How REM Reduces Entropy for Smarter AI - aitrendblend.com
Pingback: Anchor-Based Knowledge Distillation: A Trustworthy AI Approach for Efficient Model Compression - aitrendblend.com
Pingback: LayerMix: A Fractal-Based Data Augmentation Strategy for More Robust Deep Learning Models - aitrendblend.com