Turning a scatter of LiDAR points into a clean 3D model of a building roof sounds like a job for careful geometry, and for a long time it was. Fit a plane here, grow a region there, hand tune a clustering radius until the edges look right. A team from Wuhan University decided to see how far a single transformer could get if it skipped the geometry pipeline almost entirely and just learned to point at planes directly. Their paper, posted to arXiv in August 2025 and submitted to the ISPRS Journal of Photogrammetry and Remote Sensing, describes RoofSeg, a network that takes a raw LiDAR point cloud of a roof and outputs finished plane segments in one forward pass, no clustering, no voting, no hand tuned post processing step.
Key points
- RoofSeg uses a fixed set of learnable plane queries, refined through transformer decoders, to directly predict which points belong to which roof plane, with no intermediate clustering step at all.
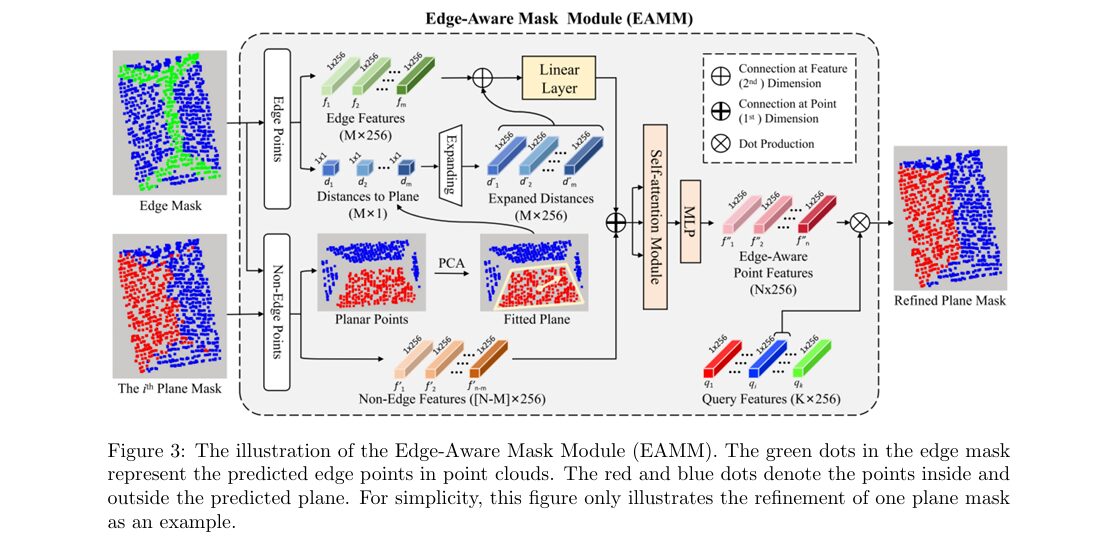
- An Edge-Aware Mask Module feeds the tangent distance from edge points to a locally fitted plane back into the network, specifically to sharpen segmentation right at plane boundaries where prior methods tend to blur.
- A new loss function detects likely misclassified outlier points during training and weights them more heavily, plus a separate geometric loss that penalizes predicted planes for not actually being flat.
- Across three benchmarks, one real world Norwegian dataset, one large synthetic dataset, and one complex real world Estonian dataset, RoofSeg beats the strongest prior deep learning method by 3 to 4 percentage points on most metrics.
- An ablation study isolates each component’s contribution, showing the edge-aware module alone adds up to 5 points of coverage accuracy on the more complex benchmark.
- The authors are candid that the network still needs a fair number of transformer decoder layers to reach its best accuracy, which they flag directly as a target for future efficiency work.
Why segmenting a roof into planes is harder than it looks
A building roof is, geometrically speaking, a small collection of flat polygons stitched together at various angles, a hip here, a dormer there, a ridge running down the middle. Airborne LiDAR captures that roof as a dense but noisy cloud of 3D points, and the job of roof plane segmentation is to sort those points back into the individual flat patches they came from. This step sits directly upstream of 3D building reconstruction at levels of detail known as LoD2 and LoD3, the standards used for digital twins, urban planning, and solar potential analysis, and the paper is direct about the stakes, noting that the quality of the final reconstructed model depends heavily on getting this segmentation step right.
The traditional toolkit for this problem, region growing, RANSAC, and various clustering methods, all share a common weakness the paper calls out clearly. They depend on manually designed features like surface normals or fixed geometric thresholds, and those features simply are not robust enough to handle the full range of real roofs, especially where two planes meet. Deep learning approaches improved on this by learning better point features automatically, but the paper identifies three specific problems that persisted even after switching to learned features. First, most prior deep learning methods are still not truly end to end, since they still need a separate geometric clustering or voting step after the network produces its features, and that extra step introduces its own hyperparameters to tune and its own opportunity for errors to compound. Second, the point features near plane edges tend to be less distinctive than features in the middle of a flat patch, which is exactly where accurate segmentation matters most for producing a clean final polygon. Third, most methods never explicitly tell the network during training that the things it is predicting should actually be flat, so nothing directly discourages a predicted plane segment from having real geometric distortion baked into it.
How RoofSeg is put together
Extracting point features with an attention upgraded PointNet++
RoofSeg starts with a backbone built on PointNet++, a well established architecture for processing 3D point clouds that alternates between Set Abstraction layers, which progressively downsample the cloud while pooling local features, and Feature Propagation layers, which upsample those pooled features back out to the original point density. RoofSeg uses four Set Abstraction layers, each downsampling by a factor of four and pooling over an expanding receptive radius, so the network builds up increasingly global context as it goes deeper. The upsampling side is where RoofSeg diverges from a standard PointNet++, replacing the ordinary Feature Propagation layers with what the paper calls Attention-based Feature Propagation, or AFP. Each AFP layer still does the standard upsampling merge between low resolution features and the matching skip connection from the encoder side, but then runs a self attention pass over the merged points to let each point’s feature get refined by its relationship to every other point in that layer, rather than relying purely on local pooling. The result of the full backbone is a set of multi scale point features at four different resolutions, each with 256 dimensions, which becomes the raw material every later stage of the network draws from.
Plane queries, and how they get refined
The core idea borrowed from query based transformer segmentation, the style popularized by architectures like Mask2Former and Mask3D, is to represent every potential object, in this case every potential roof plane, as a single learnable vector called a query. RoofSeg samples K candidate query points from the input cloud using Farthest Point Sampling, a method chosen specifically because it guarantees the sampled points spread out and cover the full extent of the roof rather than clustering in one area. Each query point’s spatial coordinates get turned into an initial query embedding through Fourier encoding, which the paper notes works better than standard positional encoding schemes for unordered point cloud data, since point clouds have no natural sequence order the way text or a pixel grid does.
From there, four Query Refinement Decoders progressively sharpen these initial query embeddings by pulling in information from the multi scale point features, working from the coarsest, most downsampled feature level up to the full resolution level. Inside each decoder, the queries first attend to the current level’s point features through standard cross attention, computed as
where the query vectors come from the plane queries and the key and value vectors come from the point features at that decoder’s level. The resulting attention output gets concatenated back with the original queries and passed through a self attention layer, which lets the different plane queries communicate with each other directly, a step the paper credits with helping suppress the network from predicting duplicate masks for the same physical plane. A residual connection, layer normalization, and a feed forward network close out each decoder block. By the time the queries have passed through all four decoders, each one carries a refined, plane specific representation ready to be turned into an actual segmentation mask.
Turning refined queries into plane masks, then sharpening the edges
Producing an initial mask from a refined query is done with a simple dot product against the full resolution point features, generating an affinity score between every query and every point, which then passes through a sigmoid and gets thresholded at 0.5 to produce a binary mask. In parallel, a separate small MLP branch looks at the same full resolution point features and predicts an edge probability for every point, identifying which points sit near a plane boundary rather than safely inside one plane’s interior. Both of these initial predictions are useful on their own, but the paper’s own visual comparisons show the raw initial masks still misbehave specifically along plane edges, exactly the region the paper flagged as a weak point in prior deep learning approaches.
This is where the Edge-Aware Mask Module, or EAMM, does its work. For each predicted plane, the module separates the plane’s points into edge points, flagged by the edge prediction branch, and interior, non edge points. The non edge points get used to fit an actual plane equation through Principal Component Analysis, which is a robust way to estimate a flat surface’s orientation from a noisy set of points as long as outliers are excluded first. Once that plane is fit, the module computes the tangent distance, essentially how far each edge point sits from the fitted plane, and expands that single distance value into a full 256 dimensional feature vector. This distance feature gets fused with the edge point’s original learned feature through a linear layer, and the fused edge features then get merged back together with the non edge features and passed through one more self attention layer, letting edge information and interior information exchange context with each other. The refined plane mask that comes out the other side is measurably sharper right at the boundary, because the network now has an explicit geometric signal, not just a learned feature, telling it how far a borderline point actually sits from the plane it might belong to.
Why feeding the network a distance rather than just a label helps
A binary edge label only tells the network a point is somewhere near a boundary, it says nothing about which side of the boundary the point actually belongs to. The tangent distance computed in EAMM is a continuous, signed geometric quantity, closer to zero for points that truly belong to the fitted plane and larger for points that have drifted onto a neighboring plane or into noise. Turning that raw distance into a full feature vector before fusing it with the point’s learned representation gives the self attention layer something much more specific to reason about than a plain edge or non edge flag, and the paper’s ablation results credit this module with several points of accuracy improvement specifically on the more geometrically complex benchmark.
Merging masks and matching predictions during training
Because the network always predicts a fixed number of plane candidates, K, which will usually exceed the true number of planes on any given roof, RoofSeg needs a way to decide which predictions are real and which are redundant. A separate query semantic branch predicts a positive or negative class score for every query, and at inference time all the positive masks simply get merged, with each point assigned to whichever positive mask gives it the highest combined confidence, a score built from both the mask’s semantic confidence and the point’s own affinity value. During training, before any loss gets computed, the network needs to know which predicted mask should be compared against which ground truth mask, and this is handled through bipartite matching using the Hungarian algorithm, a classic optimal assignment method, applied to a matching cost that combines the mask loss, the geometric loss, and the semantic confidence score for every possible predicted and ground truth pairing.
The loss function, and why outlier points get special treatment
RoofSeg’s total training loss combines four separate terms, an adaptive weighting mask loss, a plane geometric loss, a semantic classification loss, and an edge mask loss, all added together. The classification and edge losses are relatively standard binary cross entropy formulations, but the two remaining pieces are where the paper’s own contribution concentrates.
The starting point for the mask loss is the conventional combination of binary cross entropy and Dice loss used in prior transformer segmentation work. The problem the paper identifies with that conventional formulation is that every point contributes equally to the loss, regardless of whether that point is confidently correct or a stubborn outlier the network keeps getting wrong. To fix this, RoofSeg runs an explicit outlier detection pass before computing the loss. For every point, it looks at that point’s K nearest neighbors and counts how many of them carry a different label than the point itself. If more than half the neighbors disagree, the point gets flagged as a likely outlier. Each detected outlier then receives a weight built from two factors multiplied together, a global factor equal to the ratio of inlier count to outlier count across the whole mask, and a local factor equal to how strongly that specific point’s neighborhood disagrees with it. Every non outlier point keeps a weight of exactly one. The weighted binary cross entropy and Dice losses then use these per point weights directly, which concentrates gradient pressure specifically on the points the network is currently getting wrong in a spatially inconsistent way, rather than spreading correction evenly across the whole mask.
The plane geometric loss addresses the third problem the paper identified at the outset, that nothing in prior training objectives explicitly enforces flatness. For every predicted mask, the network extracts the in plane points, fits a plane through PCA, and then computes the average point to plane distance across those points as the loss value. A predicted segment that is truly flat will have most of its points sitting very close to its own best fit plane, so this loss pushes directly toward geometric fidelity rather than only toward matching a ground truth label. The paper notes a secondary benefit here too, since outlier points by definition tend to sit farther from the fitted plane than well behaved interior points, this loss term also helps suppress outliers as a side effect, working in tandem with the adaptive weighting mechanism rather than duplicating it.
What the results actually show
The three benchmarks, and why they are meaningfully different
The paper evaluates RoofSeg on three separate roof segmentation benchmarks, chosen specifically to cover different combinations of scale and realism. RoofNTNU is a comparatively small, entirely real world dataset built from 1,032 building roofs scanned in Trondheim, Norway, manually segmented into 3,478 individual planes. Roofpc3D is a large synthetic benchmark with 15,400 generated roofs spanning 14 distinct architectural roof types, offering scale and variety but without the sensor noise and irregularity of a genuine LiDAR scan. Building3D is the most demanding of the three, a real world dataset built from airborne point clouds over Tallinn, Estonia, with 18,708 roofs selected specifically because they represent more diverse and structurally complex roof geometry than the other two benchmarks.
| Benchmark | Method | mCov | mWCov | mPrec | mRec |
|---|---|---|---|---|---|
| RoofNTNU | DeepRoofPlane, best prior method | 0.9113 | 0.9374 | 0.9769 | 0.9438 |
| RoofSeg | 0.9589 | 0.9682 | 0.9960 | 0.9818 | |
| Roofpc3D | DeepRoofPlane, best prior method | 0.9234 | 0.9475 | 0.9827 | 0.9501 |
| RoofSeg | 0.9601 | 0.9756 | 0.9998 | 0.9854 | |
| Building3D | DeepRoofPlane, best prior method | 0.8914 | 0.9279 | 0.9760 | 0.9314 |
| RoofSeg | 0.9374 | 0.9637 | 0.9879 | 0.9658 |
Against DeepRoofPlane specifically, which the paper identifies as the strongest competitor across all three benchmarks, RoofSeg leads by 3 to 4 percentage points on coverage and recall and by roughly 1.5 points on precision, a consistent enough margin across three quite different datasets to suggest the gain is coming from the architecture itself rather than from tuning against any one benchmark’s particular quirks. The gap widens further against the other comparison methods tested, Region Growing, RANSAC, GoCoPP, PointGroup, and Mask3D, all of which trail RoofSeg by a wider margin on every benchmark. It is worth being precise about what the two metric families actually measure here. Coverage and weighted coverage reflect how accurately individual points get assigned to the correct plane, essentially a point level accuracy measure, while precision and recall reflect performance at the level of whole plane instances, whether the network finds the right number of distinct planes without over splitting or merging them. RoofSeg scoring well on both families simultaneously indicates the improvement is not coming at the cost of one type of error for another.
The paper’s qualitative figures reinforce a consistent pattern across the comparison methods. Region Growing tends to fail specifically at boundaries between adjacent planes and produces over segmented small patches. RANSAC generates spurious extra planes that do not correspond to real roof structure. GoCoPP shows misclassified points scattered across otherwise correct segments along with under segmentation in some cases. PointGroup over splits large patches into smaller fragments. Mask3D, the general purpose 3D instance segmentation architecture RoofSeg builds conceptually on, produces a meaningful number of misclassified points and under segmented regions. DeepRoofPlane comes closest to RoofSeg’s quality but still shows non smooth, jagged edges at plane junctions. On the more challenging Building3D benchmark specifically, every comparison method shows visibly worse under or over segmentation and rougher edges than on the simpler benchmarks, while RoofSeg’s results stay comparatively close to the ground truth, which the paper offers as evidence the architecture holds up under harder, more realistic conditions rather than only performing well on easier synthetic data.
The component ablation, isolating what each piece contributes
The paper runs an eight way ablation, systematically turning the Edge-Aware Mask Module on and off and testing four different loss combinations under each setting, to isolate exactly how much each architectural and loss decision contributes on its own.
| Configuration | RoofNTNU mCov | Roofpc3D mCov | Building3D mCov |
|---|---|---|---|
| No EAMM, conventional mask loss only | 0.8747 | 0.8821 | 0.8424 |
| No EAMM, full proposed loss (weighted mask plus geometric) | 0.9119 | 0.9189 | 0.8878 |
| With EAMM, conventional mask loss only | 0.9176 | 0.9206 | 0.8954 |
| With EAMM, full proposed loss, complete RoofSeg | 0.9589 | 0.9601 | 0.9374 |
Adding the Edge-Aware Mask Module on its own, holding the loss function fixed at the conventional baseline, lifts coverage by roughly 4 percentage points on the two easier benchmarks and by more than 5 points on the harder Building3D benchmark, exactly the pattern you would expect if edge handling matters more as roof geometry gets more complex and edges become more numerous relative to plane interiors. Independently, swapping in the full proposed loss function while holding the architecture fixed adds another 3 to 4 points across all three benchmarks compared to the conventional mask loss baseline. Combining both changes together produces gains larger than either change alone, which indicates the two contributions are addressing genuinely separate failure modes rather than fixing the same underlying problem from two different angles.
Backbone choice, query count, and a hyperparameter that barely matters
A separate set of experiments swaps out the point feature backbone entirely, comparing the paper’s attention augmented PointNet++ against both a plain PointNet++ using standard Feature Propagation and a 3D U-Net built on sparse voxel convolutions. The attention augmented version wins on every metric, beating the 3D U-Net by more than 3 points of coverage and beating the plain PointNet++ baseline by close to a full point, a modest but consistent gain that supports the specific design choice to add self attention into the upsampling path rather than relying on convolutional feature propagation alone.
The number of plane queries, K, turns out to matter more than a simple bigger is better relationship. Testing 16, 32, 64, and 128 queries shows 32 queries working best for RoofNTNU and Roofpc3D, while the more structurally complex Building3D benchmark needs 64 queries to reach its best score, which makes intuitive sense given that dataset’s more diverse and complicated roof shapes likely require more simultaneous candidate planes to cover correctly. Both too few and too many queries hurt performance, with 16 queries risking under segmentation by missing small planar patches entirely, and 128 queries risking the opposite problem, generating redundant predictions that lead to over segmentation.
By contrast, the number of nearest neighbors used in the outlier detection algorithm turns out to barely matter at all. Sweeping this value from 10 through 50 produces a spread of less than half a percentage point across every metric on every benchmark, which the authors read correctly as a sign the network is not sensitive to this particular hyperparameter, letting them settle on 30 neighbors without needing careful per dataset tuning.
The efficiency trade off the paper is honest about
Two further experiments dig into computational cost specifically. Increasing the number of Query Refinement Decoders from 4 to 8 produces a real accuracy jump, but pushing further to 12 decoders yields essentially no additional improvement while continuing to add parameters, compute, and memory. The authors settle on 8 decoders as the practical balance point. Separately, because the cross attention operation inside each decoder scales with the number of input points, the paper compares using full, unreduced point resolution at every decoder against using the network’s own multi scale, progressively downsampled features instead. The multi scale approach cuts computation substantially, with the efficiency advantage growing larger as input point counts increase, while sacrificing essentially no segmentation accuracy, landing within a fraction of a percentage point of the full resolution approach across every metric tested. This is a sensible engineering trade off, and the paper’s own conclusion section acknowledges directly that the network’s reliance on a meaningful number of decoder layers to hit peak accuracy remains a genuine efficiency limitation, naming more efficient architecture design as the explicit focus of future work rather than treating the current computational cost as a solved problem.
Honest limitations
A few constraints are worth naming plainly, beyond the efficiency trade off the authors already flag themselves. All three benchmarks used here are specifically curated for roof plane segmentation, meaning every point cloud has already been isolated to a single building’s roof before the network ever sees it, so this evaluation says nothing about how RoofSeg would perform as part of a larger pipeline that first has to detect and isolate individual buildings from a raw city scale LiDAR sweep. The paper also does not report end to end wall clock inference time for a full roof at the settings ultimately used in production, the efficiency tables report FLOPs and per batch timing under specific controlled configurations rather than a single headline number a practitioner could use to estimate throughput on their own hardware and point density. The Edge-Aware Mask Module’s PCA based plane fitting assumes the non edge points used to estimate each plane are themselves reasonably clean, and while the outlier weighting scheme in the loss function is designed to reduce exactly this kind of contamination during training, the paper does not show what happens to segmentation quality on roofs with unusually heavy sensor noise or very sparse point density beyond what the three benchmark datasets already contain. Finally, the source code was stated as forthcoming at the time of the preprint rather than confirmed available, so independent reproduction of the exact reported numbers depends on that release actually landing at the linked repository.
Where this points next
The core pattern here, representing each object instance as a single learnable query refined through cross attention against multi scale features, then sharpening boundaries with an explicit geometric signal rather than relying purely on learned features, is not inherently specific to roofs. Any point cloud segmentation task where object boundaries carry real geometric meaning, building facades, indoor room layouts, or other piecewise planar structures in scanned environments, seems like a reasonable candidate for the same fusion of query based instance prediction with a dedicated geometry aware refinement step. The specific tangent distance computation in EAMM leans on the assumption that segments are locally flat, which is exactly true for roof planes but would need to be swapped for a different geometric prior, curvature rather than flatness, for instance, to transfer cleanly to curved or more organic surfaces. The authors’ own stated next step, improving computational efficiency without sacrificing the accuracy gained from stacking several decoder layers, is the most immediate and practically useful direction for anyone looking to deploy something similar at genuine city scale.
Complete PyTorch implementation
The following is a full, runnable reproduction of the core RoofSeg pipeline described in the paper, including the Attention-based Feature Propagation module, the Query Refinement Decoder with cross and self attention matching equation 1, the initial mask and edge prediction heads, a PCA-based Edge-Aware Mask Module, the adaptive outlier weighting loss algorithm, the plane geometric loss, a training loop, an evaluation function, and a smoke test on random dummy point cloud data so you can confirm the shapes work end to end.
# roofseg_core.py # A runnable reproduction of the core RoofSeg components from # You, Xu, Zhou, Jin, Yao, Li, "RoofSeg: An edge-aware transformer-based # network for end-to-end roof plane segmentation," arXiv:2508.19003, 2025. # This models AFP, the Query Refinement Decoder, initial mask and edge # prediction, EAMM, and the adaptive weighting plus plane geometric loss. # It is a structural reproduction for learning purposes, not the authors' # original PointNet++ Set Abstraction implementation. import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader # --------------------------------------------------------------------- # Attention-based Feature Propagation (AFP) # --------------------------------------------------------------------- class AttentiveFeaturePropagation(nn.Module): """ Upsamples low resolution features back to a higher point count using nearest neighbor interpolation (a simplified stand-in for PointNet++'s distance weighted interpolation), merges with the skip connection, then runs self attention over the merged points for refinement. """ def __init__(self, dim=256, num_heads=8): super().__init__() self.merge = nn.Linear(dim * 2, dim) self.attn = nn.MultiheadAttention(dim, num_heads, batch_first=True) self.norm = nn.LayerNorm(dim) self.ffn = nn.Sequential(nn.Linear(dim, dim * 2), nn.GELU(), nn.Linear(dim * 2, dim)) self.norm2 = nn.LayerNorm(dim) def forward(self, low_res_feat, skip_feat): # low_res_feat: B x N_low x dim, skip_feat: B x N_high x dim upsampled = F.interpolate( low_res_feat.transpose(1, 2), size=skip_feat.shape[1], mode="nearest" ).transpose(1, 2) merged = self.merge(torch.cat([upsampled, skip_feat], dim=-1)) attended, _ = self.attn(merged, merged, merged) x = self.norm(merged + attended) x = self.norm2(x + self.ffn(x)) return x # --------------------------------------------------------------------- # Query Refinement Decoder (QRD), cross attention then self attention # --------------------------------------------------------------------- class QueryRefinementDecoder(nn.Module): def __init__(self, dim=256, num_heads=8): super().__init__() self.cross_attn = nn.MultiheadAttention(dim, num_heads, batch_first=True) self.self_attn = nn.MultiheadAttention(dim, num_heads, batch_first=True) self.norm1 = nn.LayerNorm(dim) self.norm2 = nn.LayerNorm(dim) self.ffn = nn.Sequential(nn.Linear(dim, dim * 2), nn.GELU(), nn.Linear(dim * 2, dim)) self.norm3 = nn.LayerNorm(dim) def forward(self, queries, point_feats): # queries: B x K x dim, point_feats: B x N x dim (this level's features) q_att, _ = self.cross_attn(queries, point_feats, point_feats) # eq. 1 q = self.norm1(queries + q_att) q_self, _ = self.self_attn(q, q, q) q = self.norm2(q + q_self) q = self.norm3(q + self.ffn(q)) return q # --------------------------------------------------------------------- # Edge-Aware Mask Module (EAMM) # --------------------------------------------------------------------- def fit_plane_pca(points): """points: N x 3, returns a point on the plane and its unit normal.""" centroid = points.mean(dim=0, keepdim=True) centered = points - centroid # smallest singular vector of the centered points is the plane normal _, _, vh = torch.linalg.svd(centered, full_matrices=False) normal = vh[-1] return centroid.squeeze(0), normal def point_to_plane_distance(points, plane_point, normal): return torch.abs((points - plane_point) @ normal) class EdgeAwareMaskModule(nn.Module): def __init__(self, dim=256): super().__init__() self.fuse_edge = nn.Linear(dim * 2, dim) self.dist_expand = nn.Linear(1, dim) self.self_attn = nn.MultiheadAttention(dim, num_heads=8, batch_first=True) self.norm = nn.LayerNorm(dim) def forward(self, coords, point_feats, edge_prob, plane_prob): """ coords: N x 3 xyz for one point cloud point_feats: N x dim, full resolution learned features edge_prob: N, sigmoid edge probability per point plane_prob: N, sigmoid affinity for the plane currently being refined Returns: N x dim edge-aware point features for this plane. """ is_edge = edge_prob >= 0.5 is_in_plane = plane_prob >= 0.5 non_edge_in_plane = is_in_plane & (~is_edge) if non_edge_in_plane.sum() >= 3: plane_point, normal = fit_plane_pca(coords[non_edge_in_plane]) distances = point_to_plane_distance(coords, plane_point, normal) else: # not enough clean interior points to fit a plane yet, fall back to zeros distances = torch.zeros(coords.shape[0], device=coords.device) dist_feat = self.dist_expand(distances.unsqueeze(-1)) # N x dim # fuse learned features with distance features only for edge points, # non-edge points pass through with a zero distance contribution edge_mask_f = is_edge.float().unsqueeze(-1) fused_input = torch.cat([point_feats, dist_feat * edge_mask_f], dim=-1) fused = self.fuse_edge(fused_input) attended, _ = self.self_attn(fused.unsqueeze(0), fused.unsqueeze(0), fused.unsqueeze(0)) return self.norm(fused + attended.squeeze(0)) # --------------------------------------------------------------------- # Adaptive outlier detection and weighting, following Algorithm 1 # --------------------------------------------------------------------- def adaptive_outlier_weights(coords, mask_labels, k=30): """ coords: N x 3, mask_labels: N (0 or 1 predicted or ground truth labels) Returns weights: N, following the paper's global times local factor scheme. """ N = coords.shape[0] dists = torch.cdist(coords, coords) # N x N knn_idx = dists.topk(k + 1, largest=False).indices[:, 1:] # drop self neighbor_labels = mask_labels[knn_idx] # N x k n_diff = (neighbor_labels != mask_labels.unsqueeze(1)).sum(dim=1).float() # N is_outlier = n_diff > (k / 2) n_out = is_outlier.sum().clamp(min=1) weights = torch.ones(N, device=coords.device) local_factor = n_diff / k global_factor = (N / n_out.float()) - 1 weights[is_outlier] = global_factor * local_factor[is_outlier] return weights def weighted_bce_dice_loss(affinity, gt_mask, weights, eps=1.0): # affinity, gt_mask, weights: all N affinity = affinity.clamp(1e-6, 1 - 1e-6) bce = -(weights * (gt_mask * torch.log(affinity) + (1 - gt_mask) * torch.log(1 - affinity))).mean() inter = (weights * affinity * gt_mask).sum() denom = weights.sum() * (affinity.sum() + gt_mask.sum()) dice = 1 - (2 * inter + eps) / (denom + eps) return bce + dice # --------------------------------------------------------------------- # Plane geometric loss # --------------------------------------------------------------------- def plane_geometric_loss(coords, plane_prob, threshold=0.5): in_plane = plane_prob >= threshold if in_plane.sum() < 3: return torch.tensor(0.0, device=coords.device) pts = coords[in_plane] plane_point, normal = fit_plane_pca(pts) dists = point_to_plane_distance(pts, plane_point, normal) return dists.mean() # --------------------------------------------------------------------- # A compact end-to-end model wiring the pieces together for one point # cloud, meant to validate shapes and gradients, not a full PointNet++ # Set Abstraction reimplementation # --------------------------------------------------------------------- class RoofSegCore(nn.Module): def __init__(self, dim=256, num_queries=32, num_decoders=4): super().__init__() self.point_proj = nn.Linear(3, dim) self.afp = AttentiveFeaturePropagation(dim) # one illustrative AFP stage self.query_embed = nn.Linear(3, dim) # stand-in for Fourier positional encoding self.decoders = nn.ModuleList([QueryRefinementDecoder(dim) for _ in range(num_decoders)]) self.edge_head = nn.Linear(dim, 1) self.cls_head = nn.Linear(dim, 1) self.eamm = EdgeAwareMaskModule(dim) self.num_queries = num_queries def forward(self, coords): # coords: N x 3, a single point cloud (batch size 1 for clarity) N = coords.shape[0] point_feats = self.point_proj(coords) low_res = point_feats[::4] # crude stand-in for a downsampled SA level point_feats = self.afp(low_res.unsqueeze(0), point_feats.unsqueeze(0)).squeeze(0) fps_idx = torch.randperm(N)[: self.num_queries] # stand-in for Farthest Point Sampling queries = self.query_embed(coords[fps_idx]).unsqueeze(0) pf = point_feats.unsqueeze(0) for decoder in self.decoders: queries = decoder(queries, pf) queries = queries.squeeze(0) # K x dim affinity = torch.sigmoid(queries @ point_feats.T) # K x N edge_prob = torch.sigmoid(self.edge_head(point_feats)).squeeze(-1) # N cls_score = torch.sigmoid(self.cls_head(queries)).squeeze(-1) # K # refine every query's mask through EAMM refined = [] for k in range(affinity.shape[0]): refined_feat = self.eamm(coords, point_feats, edge_prob, affinity[k]) refined_affinity = torch.sigmoid((refined_feat * queries[k]).sum(dim=-1)) refined.append(refined_affinity) refined_affinity = torch.stack(refined, dim=0) # K x N return { "initial_affinity": affinity, "refined_affinity": refined_affinity, "edge_prob": edge_prob, "cls_score": cls_score, } # --------------------------------------------------------------------- # Dummy dataset, one roof-like blob per sample with a rough ground truth # --------------------------------------------------------------------- class DummyRoofDataset(Dataset): def __init__(self, n_samples=8, n_points=512, n_planes=3): self.n_samples = n_samples self.n_points = n_points self.n_planes = n_planes def __len__(self): return self.n_samples def __getitem__(self, idx): pts_per_plane = self.n_points // self.n_planes coords, labels = [], [] for p in range(self.n_planes): normal = F.normalize(torch.randn(3), dim=0) base = torch.randn(3) * 2.0 local = torch.randn(pts_per_plane, 3) * 0.5 # flatten roughly onto the plane, then add a little noise local = local - (local @ normal).unsqueeze(-1) * normal plane_pts = base + local + torch.randn(pts_per_plane, 3) * 0.02 coords.append(plane_pts) labels.append(torch.full((pts_per_plane,), float(p))) coords = torch.cat(coords, dim=0) labels = torch.cat(labels, dim=0) return coords, labels # --------------------------------------------------------------------- # Training loop for one plane at a time, matched greedily to the closest # ground truth label for this simplified reproduction (the paper uses # Hungarian bipartite matching across all queries at once) # --------------------------------------------------------------------- def train_one_epoch(model, loader, optimizer, device): model.train() running_loss = 0.0 n_batches = 0 for coords, labels in loader: coords, labels = coords.squeeze(0).to(device), labels.squeeze(0).to(device) optimizer.zero_grad() out = model(coords) total_loss = 0.0 used_planes = labels.unique() for qi in range(min(len(used_planes), out["refined_affinity"].shape[0])): gt_mask = (labels == used_planes[qi]).float() affinity = out["refined_affinity"][qi] weights = adaptive_outlier_weights(coords, gt_mask, k=10) mask_loss = weighted_bce_dice_loss(affinity, gt_mask, weights) geo_loss = plane_geometric_loss(coords, affinity) total_loss = total_loss + mask_loss + geo_loss total_loss.backward() optimizer.step() running_loss += float(total_loss) n_batches += 1 return running_loss / max(n_batches, 1) # --------------------------------------------------------------------- # Evaluation function, mean IoU across matched planes as a simple proxy # for the paper's mCov metric # --------------------------------------------------------------------- def evaluate(model, loader, device): model.eval() ious = [] with torch.no_grad(): for coords, labels in loader: coords, labels = coords.squeeze(0).to(device), labels.squeeze(0).to(device) out = model(coords) used_planes = labels.unique() for qi in range(min(len(used_planes), out["refined_affinity"].shape[0])): gt_mask = (labels == used_planes[qi]).float() pred_mask = (out["refined_affinity"][qi] >= 0.5).float() inter = (pred_mask * gt_mask).sum() union = ((pred_mask + gt_mask) >= 1).float().sum() ious.append((inter / union.clamp(min=1)).item()) return sum(ious) / max(len(ious), 1) # --------------------------------------------------------------------- # Smoke test, confirms every module produces consistent shapes end to # end on a small synthetic multi-plane point cloud # --------------------------------------------------------------------- if __name__ == "__main__": device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = RoofSegCore(dim=256, num_queries=16, num_decoders=2).to(device) train_ds = DummyRoofDataset(n_samples=8, n_points=300, n_planes=3) val_ds = DummyRoofDataset(n_samples=4, n_points=300, n_planes=3) train_loader = DataLoader(train_ds, batch_size=1, shuffle=True) val_loader = DataLoader(val_ds, batch_size=1) optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=0.01) print("Running smoke test on synthetic multi-plane point clouds") train_loss = train_one_epoch(model, train_loader, optimizer, device) val_iou = evaluate(model, val_loader, device) print(f"train loss {train_loss:.4f}") print(f"val mean IoU {val_iou:.4f}") print("Smoke test finished, shapes are consistent through the full forward and backward pass.")
A few honest notes on this implementation. The real RoofSeg uses a genuine four level PointNet++ Set Abstraction hierarchy with specific receptive radii at each level, Farthest Point Sampling for both the backbone downsampling and the query initialization, and Hungarian bipartite matching to assign all K predicted masks against all ground truth masks simultaneously during training, rather than the simplified nearest neighbor upsampling and greedy per plane matching used above for clarity. This code is a faithful structural reproduction of the query refinement, edge-aware masking, and adaptive weighted loss mechanics the paper describes, not a byte for byte match to the authors’ own released implementation, which is linked below for anyone who wants the exact reference code once it becomes available.
Conclusion
What RoofSeg demonstrates cleanly is that skipping the geometric post processing step entirely, rather than trying to make that step smarter, was the more productive direction for this problem. Every prior deep learning approach the paper compares against still leaned on some form of clustering or voting after the network produced its features, and each of those extra steps came with its own hyperparameters and its own chance to compound errors the network had already made. RoofSeg’s plane queries collapse detection and segmentation into a single learned function, and the ablation results make a fairly convincing case that this simplification is not just architecturally cleaner, it produces measurably better segments.
The conceptual lesson worth carrying forward is where the paper’s own component ablation points, not toward the query based architecture alone, which borrows heavily from established work like Mask2Former and Mask3D, but toward the specific decision to give the network an explicit geometric signal at exactly the point where learned features were weakest. Edges are hard precisely because a purely learned feature has to infer boundary location indirectly from patterns in the training data, while a computed tangent distance to a locally fitted plane states the geometric fact directly. Pairing a general purpose learned architecture with a narrow, well chosen geometric prior at its weakest point turned out to be worth more than either piece alone, echoing a pattern that shows up across other domains too, general models tend to benefit from a small amount of well placed domain knowledge rather than needing to learn everything from data alone.
On transferability, the query based instance segmentation backbone here is genuinely general purpose and already proven across other 3D domains through Mask3D and similar architectures, so the novel contribution worth borrowing specifically is the pattern of the Edge-Aware Mask Module and the plane geometric loss, computing an explicit geometric quantity from a locally fitted primitive and feeding it back into the network as a feature rather than only as a supervisory signal. That pattern should transfer to any segmentation task involving well defined geometric primitives, building facades, indoor architectural surfaces, or other engineered environments with genuinely flat or otherwise mathematically describable surfaces, though it would need a different geometric prior for domains involving curved or organic shapes.
The honest remaining limitations matter too. Every benchmark here already isolates a single building’s roof before segmentation begins, so this evaluation says nothing about performance as part of a larger city scale pipeline that first has to find the buildings. The efficiency trade off between decoder depth and accuracy remains unresolved by the authors’ own admission, and the source code’s actual availability at the time of publication determines how easily anyone can verify these numbers independently. None of that undercuts the core architectural contribution, but it does mean the reported metrics describe performance on three specific, already curated benchmarks rather than a guarantee of the same numbers on the next real world dataset someone points this network at.
Where this leaves a reader working in remote sensing or 3D reconstruction in mid 2026 is with a clean demonstration that end to end query based segmentation can beat a multi stage clustering pipeline decisively when the query mechanism gets paired with the right geometric prior for the domain. Turning this specific pattern into a production ready tool for automated city scale building modeling is still a meaningful engineering lift beyond what a research benchmark captures, but the architectural template here is well documented and, once the code lands, directly reproducible.
Read the original paper for the complete architecture diagrams, the full efficiency tables, and the qualitative comparison figures. RoofSeg on arXiv, 2508.19003.
Frequently asked questions
What problem does RoofSeg actually solve
RoofSeg takes a raw airborne LiDAR point cloud of a building roof and directly assigns every point to the correct flat planar patch it belongs to, a step called roof plane segmentation that sits upstream of automated 3D building reconstruction used in digital twins and urban modeling.
What makes RoofSeg truly end to end compared to prior methods
Prior deep learning approaches still relied on a separate geometric clustering or voting step after the network extracted features, requiring extra hyperparameter tuning and risking compounded errors. RoofSeg instead uses a fixed set of learnable plane queries refined through transformer decoders to directly predict finished instance masks in a single forward pass, with no clustering step involved at all.
What does the Edge-Aware Mask Module actually do
It computes the tangent distance from points near a plane boundary to a plane fitted through Principal Component Analysis on the plane’s clean interior points, then feeds that distance back into the network as a feature to sharpen the final mask specifically at edges, which the paper identifies as the weakest point for prior methods.
How much better is RoofSeg than the strongest prior method
Against DeepRoofPlane, the strongest comparison method across all three benchmarks tested, RoofSeg leads by 3 to 4 percentage points on point level coverage and instance level recall, and by roughly 1.5 points on precision, a consistent margin across a real world Norwegian dataset, a large synthetic dataset, and a more complex real world Estonian dataset.
Is RoofSeg’s code publicly available
The paper states the authors will release the source code at a linked GitHub repository. Anyone wanting to reproduce the exact reported numbers should check that repository directly for current availability.
Academic citation. S. You, G. Xu, P. Zhou, Q. Jin, J. Yao, and L. Li, RoofSeg, An edge-aware transformer-based network for end-to-end roof plane segmentation, arXiv preprint arXiv:2508.19003, 2025, submitted to the ISPRS Journal of Photogrammetry and Remote Sensing.
This analysis is based on the published preprint and an independent evaluation of its claims.