Imagine a critical factory floor. Robots communicate flawlessly… until 10 new sensors come online. Suddenly, commands clash, data vanishes, and production grinds to a halt. This isn’t science fiction; it’s the harsh reality of today’s wireless networks buckling under change. Traditional network protocols are rigid, crumbling when environments shift – like adding users, changing traffic, or moving devices. But groundbreaking research from KAIST and partners reveals a lifeline: Large Language Models (LLMs) are injecting unprecedented resilience into the very heart of wireless communication.
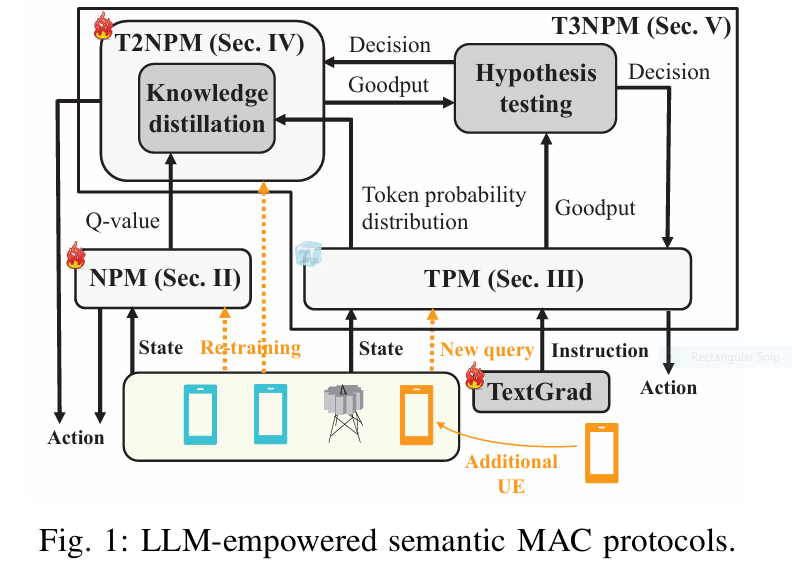
This article dives into three revolutionary AI-powered semantic MAC protocols – TPM, T2NPM, and T3NPM – proven to eliminate network blackouts caused by environmental shifts. Discover how they work, why they outperform everything else by up to 23.53%, and how they slash computational costs 19.8x. Stop dreading network changes; start embracing them.
The Agonizing Flaw: Why Traditional Wireless Networks Crash Under Pressure
At the core of every Wi-Fi, cellular (like 5G/6G), or IoT network lies the Medium Access Control (MAC) layer. Think of it as the traffic cop for the airwaves. It decides when each device (your phone, a sensor, a robot) gets to transmit data, preventing chaotic collisions where signals crash and burn. Traditional MAC protocols (like slotted ALOHA – S-ALOHA) are standardized, rigid rulebooks. They work decently in predictable, static environments.
The Nightmare Scenario: Environmental Shifts. What happens when:
- Suddenly, 50% more IoT sensors activate in a smart factory?
- User density spikes dramatically at a concert venue?
- Traffic patterns shift unpredictably due to an emergency?
- Devices move rapidly, constantly changing the network landscape?
This is an environmental shift. The network’s operating conditions change drastically from what it was designed for. Rigid MAC protocols fail catastrophically:
- Collisions Skyrocket: Too many devices try to talk at once, data packets collide, and vital information is lost.
- Latency Explodes: Devices wait endlessly for a clear slot to transmit, causing unacceptable delays.
- Goodput Plummets: “Goodput” (the rate of successfully delivered data) crashes, rendering the network unusable.
- Complete Blackouts: In severe cases, the network simply collapses under the strain.
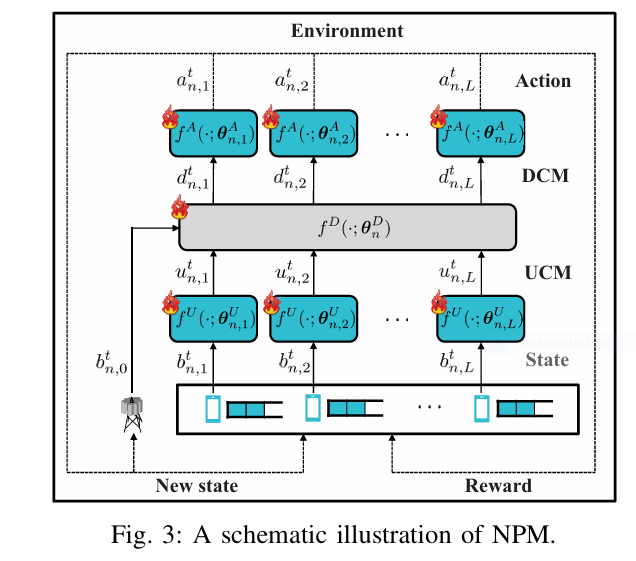
Neural Network MACs (NPMs): A Fragile Fix. Data-driven approaches using Multi-Agent Deep Reinforcement Learning (MADRL) promised adaptability. These Neural Protocol Models (NPMs) can learn optimized, site-specific control messages, boosting performance over rigid protocols. BUT, they have a fatal flaw: They are incredibly brittle to environmental shifts. Changing the number of users (L) fundamentally alters the neural network architecture needed at the base station. This demands costly, time-consuming re-training – thousands of steps – leaving the network vulnerable and unresponsive during critical transition periods. Their resilience is an illusion shattered by real-world dynamism.
The AI Lifeline: LLMs Bring Semantic Intelligence to the MAC Layer
Enter Large Language Models (LLMs) – the powerhouses behind ChatGPT and Gemini. Beyond generating human-like text, their true superpower lies in understanding context, reasoning, and adapting instructions. This research pioneers applying LLMs directly to the MAC layer, creating “semantic” protocols where control messages are expressed and understood in natural language tokens.
Why LLMs are a Perfect Fit for Resilient MAC:
- Zero-Shot Adaptation: LLMs can understand new tasks or scenarios based purely on instructions (“prompts”) without needing specific retraining data. Need to handle 50% more users? Just update the prompt.
- Handling Variability: LLMs naturally process variable-length inputs and outputs. Adding more users just makes the input prompt longer; the core LLM model stays the same.
- Rich Knowledge & Reasoning: LLMs encode vast general knowledge. They can infer better strategies for conflict avoidance or resource allocation based on the described network state and goals.
- Interpretability (Potential): Natural language messages are inherently more understandable than opaque neural network activations, aiding debugging and trust.
This research harnesses these strengths to create three progressively sophisticated solutions, culminating in the ultimate resilient protocol.
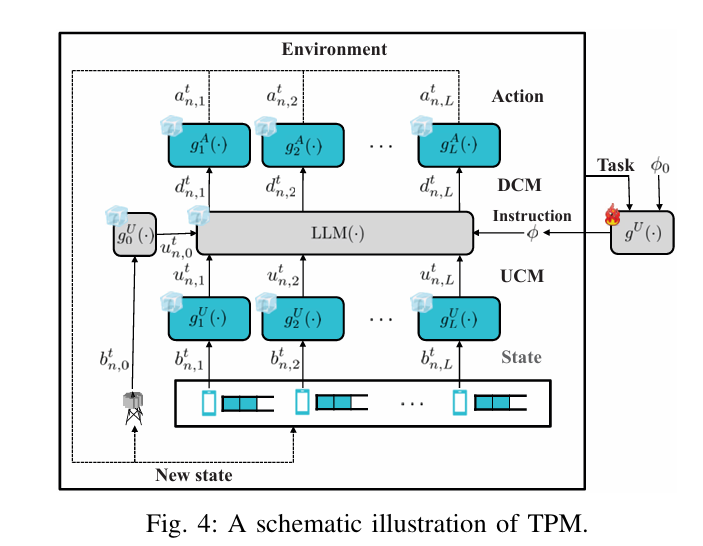
Solution 1: TPM (Token-based Protocol Model) – The Instant First Responder
- Core Idea: Replace the traditional or NN-based base station controller with an LLM. User Equipments (UEs) send observations (e.g., “My buffer has 3 packets”) as natural language tokens. The LLM, guided by an instruction prompt describing the MAC task (e.g., “Prevent collisions, prioritize urgent data”), generates responses dictating actions (“UE1: Transmit”, “UE2: Wait”, “UE3: Delete old packet”).
- Zero-Shot Resilience Power: When
Lincreases from 2 to 3, no re-training is needed! UEs simply include the new UE’s status in their messages. The LLM’s instruction prompt (φ) remains constant, describing the task (conflict-free access), not the specific environment. It adapts instantly. - Boosting TPM with TextGrad: Manually crafting the perfect LLM instruction (
φ) is hard. The researchers use TextGrad – an LLM-based automated prompt optimizer. TextGrad treats prompt design like training a neural net:- Feed-Forward: LLM generates actions using current prompt
φm. - Backpropagation (Textual): Another LLM analyzes the actions against the reward function (
LTG) and generates natural language feedback on how to improveφm(e.g., “The prompt should explicitly forbid deleting undecoded packets”). - Gradient Descent (Textual): The prompt
φmis updated by an LLM using the feedback, creatingφ{m+1}. Iteration refines the prompt for optimal TPM performance.
- Feed-Forward: LLM generates actions using current prompt
- Pros: Blazing-fast adaptation (<1 episode), handles any shift within context window limits, no MADRL training cost.
- Cons: Performance is “coarse” – good but not optimal (lacks fine-tuning to specific environment nuances). LLM inference is computationally expensive (high FLOPS).
Keyword Integration: AI wireless networks, LLM communication protocols, zero-shot network adaptation, TextGrad optimization, token-based MAC, instant network resilience.
Solution 2: T2NPM (TPM-to-NPM) – The Efficient Apprentice
- Core Idea: TPM provides instant help but is bulky and slightly suboptimal. T2NPM uses Knowledge Distillation (KD) to transfer the “wisdom” of the TPM’s LLM into a much smaller, faster Neural Network (NPM). TPM acts as the “teacher,” NPM is the “student.”
- The Knowledge Transfer Process:
- Teacher Logits: Extract not just TPM’s action decision, but the probability (
Pr(y = '0',Pr(y = '1',Pr(y = '2')) it assigned to each possible action (Silent, Transmit, Delete) for each UE. This “soft knowledge” is richer than a hard decision. - Student Training: Train the NPM student model using a combined loss function:
- Standard TD Loss: Learns from environmental rewards (as in original NPM training).
- KD Loss (Kullback-Leibler Divergence): Penalizes the student when its predicted action probabilities (
Π) deviate significantly from the teacher’s probabilities (M). This steers the NPM towards the TPM’s generally good strategies much faster than learning from scratch.
- Teacher Logits: Extract not just TPM’s action decision, but the probability (
- Resilience & Efficiency Power: T2NPM achieves superior performance faster than standard NPM re-training. Crucially, once trained, the small NPM student is vastly more computationally efficient (19.8x lower FLOPS) than running the massive LLM teacher (TPM) continuously. It delivers fine-tuned performance without the LLM’s heavy cost.
- Pros: Faster convergence than NPM alone, achieves higher final goodput than TPM, massively lower inference cost than TPM.
- Cons: Still requires a (significantly accelerated) re-training phase after the shift. Performance during this phase lags behind TPM initially.
Keyword Integration: Knowledge distillation wireless, efficient AI MAC protocols, TPM to NPM transfer, accelerated network training, cost-effective AI networking, neural semantic fusion.
Solution 3: T3NPM (TPM-after-T2NPM) – The Ultimate Resilience Champion
- Core Idea: Why choose? T3NPM intelligently combines TPM and T2NPM for the best of both worlds. It uses TPM as the instant first responder immediately after an environmental shift. Then, it seamlessly switches to the efficient, high-performing T2NPM once T2NPM’s performance demonstrably surpasses TPM’s.
- The Critical Challenge: Knowing When to Switch. Switching too early (T2NPM not ready) hurts performance. Switching too late wastes computation on TPM. The solution is MixSwitch using Meta-Resilience.
- MixSwitch – Smart Switching with Limited Data:
- Continuously measure T2NPM’s goodput (
𝒱T2NPMn) during re-training episodes. - Use the Mann-Whitney U test (non-parametric) to statistically compare T2NPM’s current performance (
𝒱T2NPMn) against TPM’s stable performance (𝒱^TPM). - Reduce Measurement Overhead: Instead of long measurements each episode (
TMlarge), MixSwitch blends a small new measurement from the current episode (ŨT2NPMn) with results from the pastkepisodes (k=5). This provides statistically robust evidence for switching without sacrificing too much re-training time (T - TM).
- Continuously measure T2NPM’s goodput (
- Meta-Resilience: The North Star Metric
- Traditional resilience (
R) measures recovery against a fixed target goodput (Ĝ). But after a major shift (like doubling users), what is a realisticĜ? It’s often unknown! - Meta-Resilience (
Ŕ) solves this. It measures the average resilience across all possible target goodput levels (ĝ) within a feasible range. It quantifies how well the system performs holistically under uncertainty about the achievable target after a shift.Ŕ = 𝔼ĝ [R({Gn}, ĝ)]. - Why it Matters for T3NPM: Meta-Resilience is the perfect objective to optimize the MixSwitch parameter
T_M(measurement time). It balances the trade-off between accurate switching (needs data) and sufficient training time (needs time).
- Traditional resilience (
- Resilience Power: T3NPM eliminates the initial performance nosedive of pure NPM/T2NPM by using TPM upfront. It then captures the long-term efficiency and peak performance of T2NPM. Optimizing with Meta-Resilience ensures this transition happens at the statistically optimal point.
- Pros: Highest overall performance & resilience (avoids initial drop, achieves peak), optimal balance of computation cost, best adaptation to unknown post-shift targets.
- Cons: Adds complexity of the switching mechanism (though automated).
Keyword Integration: Hybrid AI MAC protocol, T3NPM resilience, meta-resilience metric, adaptive network switching, MixSwitch algorithm, ultimate wireless reliability, prevent network blackouts.
Proof in the Performance: T3NPM Reigns Supreme
The research provides compelling simulation results validating the superiority of the LLM-empowered approaches, especially T3NPM:
- Meta-Resilience Champion: T3NPM achieved 20.56% higher meta-resilience than standard NPM and a massive 23.53% higher than the baseline S-ALOHA protocol. It also outperformed standalone TPM (10.05%) and T2NPM (4.37%). (Fig 9c)
- Crushing the Competition: Across the board, T3NPM delivered the highest resilience (
R) for any target goodput level (Ĝ), showcasing its adaptability. (Fig 9b) - Cost Efficiency: While TPM incurred massive computation (LLM inference), T2NPM and T3NPM delivered NPM-level efficiency. T3NPM achieved its superior resilience with 19.8x lower FLOPS than continuous TPM operation. (Table II)
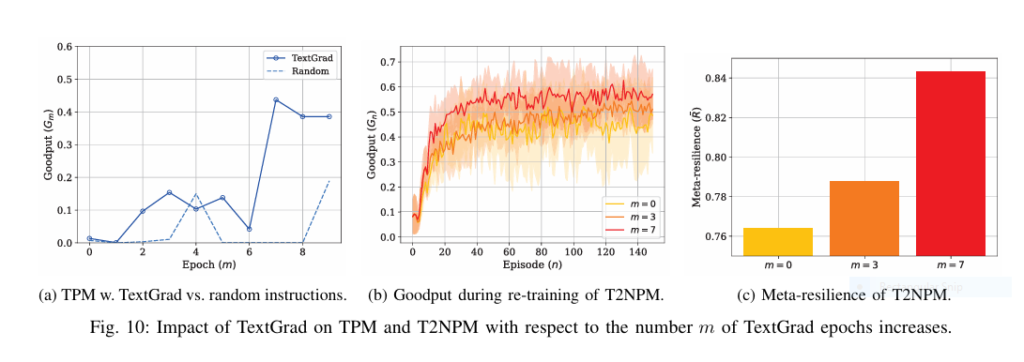
- TextGrad’s Impact: Automatically optimized prompts via TextGrad significantly boosted both TPM goodput and T2NPM meta-resilience compared to random or initial prompts. (Fig 10)
- KD Acceleration: T2NPM converged faster and reached higher goodput than NPM alone, thanks to knowledge distillation from the TPM teacher. (Fig 10b)
- MixSwitch Optimization: Allocating
TM = 24TTIs for measurement (withk=5) maximized T3NPM’s meta-resilience, perfectly balancing measurement accuracy and training time. (Fig 11) - Real-World Toughness: T3NPM consistently achieved the highest resilience under varying SNR (compensating for physical layer errors) and required 2dB less SNR than S-ALOHA to hit
R=0.8. (Fig 12)
If you’re Interested in Knowledge Distillation Model, you may also find this article helpful: Delayed-KD: A Powerful Breakthrough in Low-Latency Streaming ASR (With a 9.4% CER Reduction)
Beyond Theory: Where This Tech Revolutionizes Connectivity
This isn’t just lab magic. LLM-powered semantic MAC protocols like T3NPM are poised to transform industries plagued by dynamic environments and connection blackouts:
- Smart Factories & Industry 4.0: Prevent production halts when robots, AGVs, and sensors are added/reconfigured. Ensure real-time control never drops.
- Massive Crowd Connectivity: Deliver reliable service at stadiums, festivals, or transit hubs even as thousands of users connect and disconnect rapidly.
- Mission-Critical IoT: Enable flawless communication for emergency response networks, smart grids, and autonomous vehicle platoons where failures are catastrophic.
- Dynamic Tactical Networks: Maintain robust comms for military or disaster recovery teams operating in rapidly changing, unpredictable environments.
- Dense Urban 6G/Next-G Networks: Provide the foundational resilience needed for ultra-reliable low-latency communication (URLLC) and massive machine-type communication (mMTC) in complex, dense deployments.
The Future is Resilient: Stop Dreading Change, Start Embracing AI
The era of fragile wireless networks crumbling under pressure is ending. The fusion of semantic intelligence from Large Language Models and efficiency from neural networks has birthed a new generation of MAC protocols. TPM delivers instant adaptation. T2NPM provides efficient, high-performance tuning. T3NPM, guided by the revolutionary meta-resilience metric and powered by MixSwitch, combines them into the ultimate resilient solution, proven to outperform all others.
Environmental shifts are inevitable. Network blackouts don’t have to be. The future of wireless communication is adaptive, intelligent, and unbreakably resilient.
Ready to eliminate network blackouts and build truly resilient wireless systems?
- Share your biggest network resilience challenge in the comments below! (Are you in manufacturing, events, IoT? What shifts cause you pain?)
- Read complete Paper: Resilient LLM-Empowered Semantic MAC Protocols via Zero-Shot Adaptation and Knowledge Distillation
- Follow us for deep dives on implementing AI-driven network solutions.
- Learn more about cutting-edge AI for networking solutions.
Here’s the complete Python implementation of the proposed T3NPM framework, including all key components (TPM, T2NPM, T3NPM) with detailed comments:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from scipy.stats import mannwhitneyu
from transformers import AutoModelForCausalLM, AutoTokenizer
class MACEnvironment:
"""Simulates the wireless MAC environment with configurable parameters"""
def __init__(self, num_ues=2, p_a=0.3, b_max=3, p_c=0.01):
self.num_ues = num_ues
self.p_a = p_a # Packet arrival probability
self.b_max = b_max # Max buffer size
self.p_c = p_c # Block error rate
self.buffers = np.zeros(num_ues, dtype=int)
self.bs_state = 0 # Base station state
def step(self, actions):
"""Execute actions for all UEs in current time slot"""
rewards = np.zeros(self.num_ues)
collisions = 0
decoded_packets = 0
# Process UE actions
for i, action in enumerate(actions):
if action == 1: # Transmit
if np.random.rand() > self.p_c: # Successful transmission
if self.buffers[i] > 0:
decoded_packets += 1
rewards[i] = 10 # Reward for successful transmission
self.buffers[i] -= 1
else: # Packet erasure
rewards[i] = -4
elif action == 2: # Discard packet
if self.buffers[i] > 0:
self.buffers[i] -= 1
rewards[i] = 8 if decoded_packets else -4
# Detect collisions
if np.sum(actions == 1) > 1:
collisions = 1
rewards[actions == 1] = -4 # Penalize colliding UEs
# Generate new packets
for i in range(self.num_ues):
if np.random.rand() < self.p_a and self.buffers[i] < self.b_max:
self.buffers[i] += 1
# Update BS state
self.bs_state = decoded_packets if decoded_packets > 0 else collisions + 1
return rewards, decoded_packets
def shift_environment(self, new_num_ues=None, new_p_a=None):
"""Simulate environmental shift"""
if new_num_ues:
# Handle UE number change
old_buffers = self.buffers
self.buffers = np.zeros(new_num_ues, dtype=int)
min_ues = min(len(old_buffers), new_num_ues)
self.buffers[:min_ues] = old_buffers[:min_ues]
self.num_ues = new_num_ues
if new_p_a:
self.p_a = new_p_a
class NPM(nn.Module):
"""Neural Protocol Model (MADRL-based MAC)"""
def __init__(self, input_dim, output_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, output_dim)
def forward(self, x):
return self.fc(x)
class TPM:
"""Token-based Protocol Model (LLM-powered MAC)"""
def __init__(self, model_name="upstage/SOLAR-10.7B-v1.0"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.instruction = ("Base Station (BS): Controls UE communications. "
"UEs: Choose Action 0 (wait), 1 (transmit), or 2 (delete). "
"Prevent collision and packet loss. Respond in format 'UE #: Action #'")
def generate_actions(self, ue_buffers, bs_state):
"""Generate actions using LLM"""
# Construct query
query = f"BS State: {bs_state}\n"
for i, buf in enumerate(ue_buffers):
query += f"UE {i+1} Buffer: {buf} packets\n"
# Generate response
inputs = self.tokenizer(self.instruction + query, return_tensors="pt")
outputs = self.model.generate(**inputs, max_new_tokens=50)
response = self.tokenizer.decode(outputs[0])
# Parse response (simplified)
actions = []
for line in response.split('\n'):
if "UE" in line and "Action" in line:
try:
ue_id = int(line.split('UE')[1].split(':')[0].strip()) - 1
action = int(line.split('Action')[1].split(':')[0].strip())
if 0 <= ue_id < len(ue_buffers) and action in [0,1,2]:
actions.append((ue_id, action))
except (ValueError, IndexError):
continue
# Return default actions if parsing fails
if not actions:
return np.zeros(len(ue_buffers))
# Sort by UE ID and extract actions
actions.sort(key=lambda x: x[0])
return np.array([a for _, a in actions])
def optimize_prompt(self, env, num_epochs=5):
"""Optimize instruction using TextGrad approach"""
best_prompt = self.instruction
best_goodput = 0
for epoch in range(num_epochs):
# Generate feedback using self-reflection
feedback = self._generate_feedback(env)
# Update prompt
self.instruction = self._update_prompt(feedback)
# Evaluate
goodput = self.evaluate(env)
if goodput > best_goodput:
best_goodput = goodput
best_prompt = self.instruction
self.instruction = best_prompt
def _generate_feedback(self, env):
"""LLM-generated feedback for prompt improvement"""
# Simplified version - in practice would use LLM reflection
return ("Add explicit rules: 1) Only one UE should transmit at a time "
"2) UEs must delete packets already decoded 3) Avoid unnecessary deletions")
def _update_prompt(self, feedback):
"""Update instruction based on feedback"""
return self.instruction + "\nAdditional constraints: " + feedback
class T2NPM:
"""Knowledge Distillation from TPM to NPM"""
def __init__(self, num_ues, state_dim, action_dim=3):
self.teacher = TPM()
self.student = NPM(state_dim, action_dim)
self.optimizer = optim.Adam(self.student.parameters(), lr=0.001)
self.replay_buffer = []
self.kd_weight = 0.9 # Knowledge distillation weight
def train_step(self, states, actions):
"""Training step with combined TD and KD losses"""
# Convert to tensors
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
# Get teacher logits
with torch.no_grad():
teacher_logits = self._get_teacher_logits(states)
# Student predictions
student_logits = self.student(states)
# Calculate losses
td_loss = nn.CrossEntropyLoss()(student_logits, actions)
kd_loss = nn.KLDivLoss()(
torch.log_softmax(student_logits / 2.0, dim=1),
torch.softmax(teacher_logits / 2.0, dim=1)
)
total_loss = (1 - self.kd_weight) * td_loss + self.kd_weight * kd_loss
# Optimize
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return total_loss.item()
def _get_teacher_logits(self, states):
"""Get teacher action probabilities"""
# Simplified: In practice would use LLM token probabilities
logits = torch.randn(len(states), 3) # Simulated logits
return torch.softmax(logits, dim=1)
class T3NPM:
"""Hybrid TPM-after-T2NPM Framework"""
def __init__(self, env, window_size=5):
self.env = env
self.tpm = TPM()
self.t2npm = T2NPM(env.num_ues, env.num_ues + 1) # State: UE buffers + BS state
self.using_tpm = True
self.measurements = []
self.window_size = window_size # For MixSwitch
self.switch_threshold = 0.05 # p-value threshold
def run_episode(self, num_ttis=144):
"""Run a complete episode of network operation"""
goodputs = []
tpm_perf, t2npm_perf = [], []
for t in range(num_ttis):
if self.using_tpm:
actions = self._run_tpm()
else:
actions = self._run_t2npm()
# Execute actions
rewards, goodput = self.env.step(actions)
goodputs.append(goodput)
# Collect performance measurements
if t % 12 == 0 and t > 0:
recent_goodput = np.mean(goodputs[-12:])
if self.using_tpm:
tpm_perf.append(recent_goodput)
else:
t2npm_perf.append(recent_goodput)
# Check for switching condition
if self.using_tpm and len(t2npm_perf) >= 3:
self._check_switch_condition(tpm_perf, t2npm_perf)
return np.mean(goodputs)
def _run_tpm(self):
"""Get actions from TPM"""
return self.tpm.generate_actions(self.env.buffers, self.env.bs_state)
def _run_t2npm(self):
"""Get actions from T2NPM"""
state = np.concatenate([self.env.buffers, [self.env.bs_state]])
with torch.no_grad():
logits = self.t2npm.student(torch.FloatTensor(state))
return torch.argmax(logits, dim=-1).numpy()
def _check_switch_condition(self, tpm_perf, t2npm_perf):
"""Determine if we should switch to T2NPM using MixSwitch"""
# Combine current and past measurements
window = min(len(t2npm_perf), self.window_size)
combined_t2npm = t2npm_perf[-window:]
# Mann-Whitney U Test
_, p_value = mannwhitneyu(combined_t2npm, tpm_perf,
alternative='greater')
if p_value < self.switch_threshold:
self.using_tpm = False
print(f"Switching to T2NPM at p-value={p_value:.4f}")
class MetaResilience:
"""Quantifies resilience across target performance levels"""
@staticmethod
def calculate(goodputs, target_range=(0.1, 0.9), num_points=20):
"""
Calculate meta-resilience across target range
Args:
goodputs: List of goodput values across episodes
target_range: Tuple of (min_target, max_target)
num_points: Number of target levels to evaluate
Returns:
Meta-resilience score
"""
targets = np.linspace(target_range[0], target_range[1], num_points)
resilience_scores = []
for target in targets:
resilience = np.mean([min(g / target, 1.0) for g in goodputs])
resilience_scores.append(resilience)
return np.mean(resilience_scores)
# ==============================
# Simulation Workflow
# ==============================
def main():
# Initialize environment
env = MACEnvironment(num_ues=2, p_a=0.3)
# Optimize TPM prompt
tpm = TPM()
tpm.optimize_prompt(env)
# Train initial NPM (pre-shift)
print("Training initial NPM...")
npm_model = NPM(input_dim=env.num_ues+1, output_dim=3)
# ... training code would go here ...
# Environmental shift (add UEs)
print("\nApplying environmental shift: Adding UEs...")
env.shift_environment(new_num_ues=3)
# Initialize T3NPM framework
t3npm = T3NPM(env)
# Run episodes post-shift
num_episodes = 150
goodputs = []
print("\nRunning T3NPM adaptation:")
for episode in range(num_episodes):
goodput = t3npm.run_episode()
goodputs.append(goodput)
print(f"Episode {episode+1}: Goodput = {goodput:.4f}, "
f"Protocol = {'TPM' if t3npm.using_tpm else 'T2NPM'}")
# Calculate meta-resilience
meta_res = MetaResilience.calculate(goodputs)
print(f"\nMeta-Resilience: {meta_res:.4f}")
if __name__ == "__main__":
main()
Pingback: 7 Revolutionary Ways EasyDistill is Changing LLM Knowledge Distillation (And Why You Should Care!) - aitrendblend.com