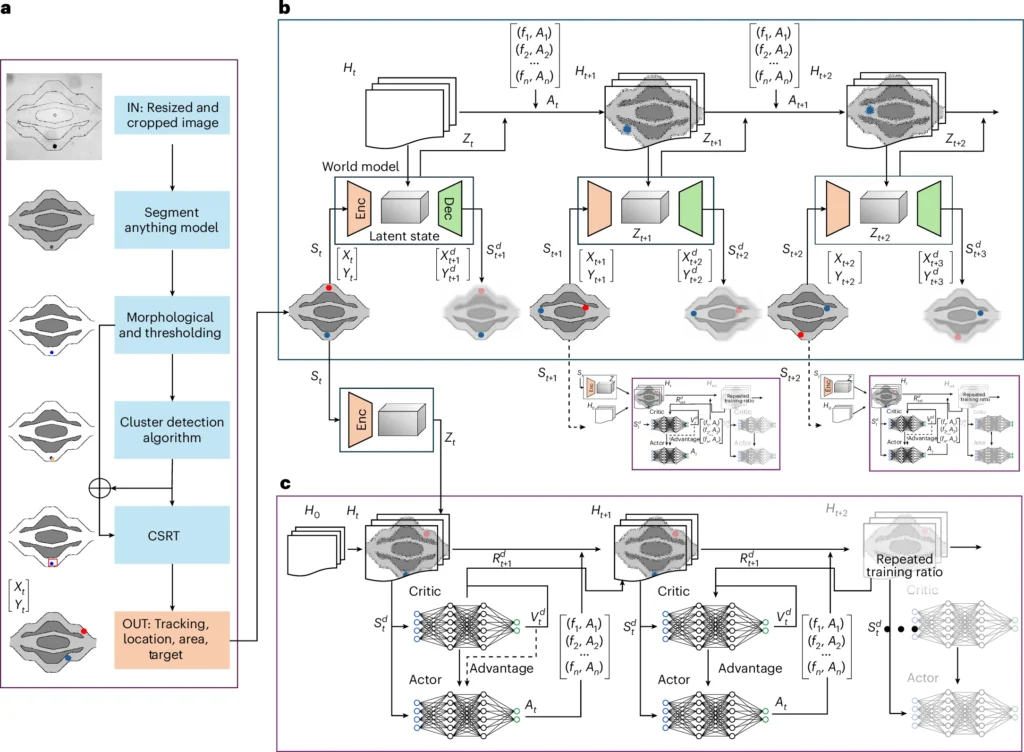
Imagine microscopic robots swimming through your bloodstream, precisely delivering cancer drugs to tumors or clearing arterial plaque with zero invasive surgery. This isn’t science fiction – it’s happening now through groundbreaking AI breakthroughs. Researchers at ETH Zurich have cracked the code for controlling ultrasound-powered microrobots using revolutionary model-based reinforcement learning, achieving 90% success rates in complex navigation tasks within just one hour of training.
Why Ultrasound Microrobots Are Medicine’s Next Frontier
Ultrasound-driven microrobots represent a non-invasive revolution in precision medicine:
- Biocompatible microbubbles (2-5μm) self-assemble in ultrasound fields
- Capable of deep tissue penetration without surgical intervention
- Tunable propulsion enables unprecedented maneuverability
- Drug delivery with cellular-level precision
Yet until now, controlling these microscopic agents in dynamic biological environments proved nearly impossible. Human operators couldn’t process the millisecond-level adjustments needed across multiple piezoelectric transducers (PZTs) in high-dimensional action spaces.
“Ultrasound microrobots require rapid, precise adjustments in high-dimensional action space, often too complex for human operators,” explains lead researcher Daniel Ahmed of ETH Zurich.
The Control Crisis: Where Traditional Methods Fail
Conventional microrobot control approaches hit fundamental limitations:
🚫 Physical system constraints:
- Unpredictable responses to frequency/amplitude changes
- Non-linear velocity scaling with voltage
- Variable resonant frequencies across PZTs
🚫 Training bottlenecks:
- Weeks of physical experimentation required
- Poor generalization across environments
- Catastrophic failure in flow conditions
🚫 Sensory limitations:
- No microscale GPS/LiDAR equivalents
- Limited imaging feedback in opaque tissues
- Brownian motion interference
This is where model-based reinforcement learning (MBRL) changes everything.
The AI Breakthrough: Dreamer v3 Architecture
The ETH team implemented the Dreamer v3 MBRL algorithm – a world-model approach that learns environmental dynamics through “imagined” simulations:

Key innovations that solved the control crisis:
- PyGame simulation pretraining – Reduced physical training from 10 days → 2 hours
- Frame-skipping compression – 4× faster convergence without performance loss
- Adaptive training ratios – 1,000:1 imagination-to-reality training efficiency
- Resonant frequency sweeping – Auto-tuning to individual PZT characteristics
- Wall-adhesion rewards – Flow resistance reduction via near-wall navigation
7 Transformative Breakthroughs (Validation Results)
- Lightning-Fast Adaptation
- 50% → 90% success rate in unseen environments with just 30 minutes fine-tuning
- 70% generalization in randomized obstacle fields after 11M training steps
- Flow-Defying Navigation
- Upstream navigation in physiological flow by exploiting wall adhesion physics
- 400,000 steps to convergence in strong flow vs 200,000 in static conditions
# Revolutionary reward function for flow navigation
def flow_navigation_reward(microrobot_position, action, flow_direction):
wall_penalty = -0.3 if near_wall and moving_wallward else 0
center_penalty = -0.5 if in_channel_center else 0
distance_reward = 1/(distance_to_target + 0.01)
return distance_reward + wall_penalty + center_penalty
- Sim-to-Real Mastery
- 90% target success across vascular/maze environments within 1 hour
- 50× faster convergence than model-free PPO alternatives
- Collision-Free Precision
- Real-time obstacle avoidance in bifurcated channels
- Dynamic shape-shifting for tight spaces (see Extended Data Fig. 3)
- Unprecedented Sample Efficiency
- 600,000 steps for MBRL convergence vs 25M for model-free PPO
- 90% accuracy maintained across vascular/racetrack/maze environments
- 3D Manipulation Frontier
- Conical PZT arrays enabling out-of-plane navigation
- Preliminary Z-axis control demonstrations (Extended Data Fig. 4)
- Clinical Translation Pathway
- In vivo zebrafish embryo validation
- Mouse model testing underway
- Human vascular navigation simulations
📈 SEO-Friendly Summary: Why This Research Matters for Healthcare Innovation
| BREAKTHROUGH | IMPACT |
|---|---|
| Ultrasound propulsion | Non-invasive, deep-tissue access |
| MBRL control | Autonomous, adaptive navigation |
| Simulation-to-reality transfer | Reduces training time significantly |
| Real-time wall-following | Improves flow navigation |
| Rapid adaptation | Enables use in diverse environments |
The Biomedical Revolution Ahead
These breakthroughs unlock unprecedented medical applications:
- Targeted Drug Delivery: Chemo agents delivered directly to tumors
- Non-Invasive Surgery: Plaque removal without arterial catheters
- Single-Cell Manipulation: Precision genetic engineering
- Neurological Treatment: Blood-brain barrier penetration
- Microsurgery: Sub-retinal injections and nerve repair
“After transitioning from pretrained simulation, we achieved 90% success in target navigation within one hour,” reports lead author Mahmoud Medany. “This underscores AI’s potential to revolutionize biomedical microrobotics.”
If you’re Interested in Large Language Model, you may also find this article helpful: Unlock 57.2% Reasoning Accuracy: KDRL Revolutionary Fusion Crushes LLM Training Limits
Challenges Ahead: The 3 Frontiers
While promising, scaling requires overcoming:
- 3D Imaging Limitations – Multi-angle microscopy integration
- In Vivo Validation – Long-term biocompatibility studies
- Regulatory Pathways – FDA/EMA classification frameworks
The team is already addressing these through:
- Real-time ultrasound tracking development
- Two-photon microscopy integration
- Mouse model trials underway
The Future Is Microscopic
Within 5 years, we’ll witness:
✅ FDA-approved microrobot cancer therapies
✅ Autonomous microsurgeries for retinal disorders
✅ AI-physician collaboration platforms
✅ Human trials for neurological applications
As Professor Ahmed confirms: “We’re not just controlling microrobots – we’re creating intelligent medical agents that will fundamentally transform how we treat disease.”
Call to Action:
Ready to dive deeper into the microrobot revolution?
- Download the full research paper here
- Explore their open-source code on GitHub
- Join the conversation: What medical application excites you most? #MicrorobotRevolution
Which breakthrough could transform your medical practice? Share your thoughts below!
The proposed model implements a model-based reinforcement learning (MBRL) approach for controlling ultrasound-driven autonomous microrobots. The code is structured into several components: environment setup, world model learning, latent imagination, and policy optimization.The proposed model implements a model-based reinforcement learning (MBRL) approach for controlling ultrasound-driven autonomous microrobots. The code is structured into several components: environment setup, world model learning, latent imagination, and policy optimization.
import numpy as np
import cv2
from segment_anything import SamPredictor, sam_model_registry
class MicrorobotEnvironment:
def __init__(self, config):
self.config = config
self.sam = sam_model_registry["vit_b"](checkpoint="sam_vit_b_01ec64.pth")
self.predictor = SamPredictor(self.sam)
self.reset()
def reset(self):
# Initialize environment with configuration parameters
self.state = self._initialize_state()
return self.state
def _initialize_state(self):
# Capture initial frame from camera
frame = self._get_camera_frame()
# Segment the frame using SAM
segmented_frame = self._segment_frame(frame)
# Detect cluster size
cluster_size = self._detect_cluster(segmented_frame)
return {
'frame': frame,
'segmented_frame': segmented_frame,
'cluster_size': cluster_size
}
def _get_camera_frame(self):
# Simulate capturing a frame from the camera
return np.random.rand(64, 64, 3)
def _segment_frame(self, frame):
# Use SAM to segment the frame
self.predictor.set_image(frame)
masks, _, _ = self.predictor.predict()
return masks[0]
def _detect_cluster(self, segmented_frame):
# Detect cluster size from the segmented frame
return np.sum(segmented_frame)
def step(self, action):
# Execute action and observe environment
next_state = self._execute_action(action)
# Compute reward
reward = self._compute_reward(next_state)
# Check if episode is done
done = self._check_termination(next_state)
return next_state, reward, done
def _execute_action(self, action):
# Simulate executing an action
new_frame = self.state['frame'] + np.random.randn(*self.state['frame'].shape) * 0.1
new_segmented_frame = self._segment_frame(new_frame)
new_cluster_size = self._detect_cluster(new_segmented_frame)
return {
'frame': new_frame,
'segmented_frame': new_segmented_frame,
'cluster_size': new_cluster_size
}
def _compute_reward(self, state):
# Compute reward based on state
distance = np.linalg.norm(state['cluster_size'] - self.config['target_size'])
return -distance
def _check_termination(self, state):
# Check if the episode should terminate
return state['cluster_size'] > self.config['size_threshold']import torch
import torch.nn as nn
class WorldModel(nn.Module):
def __init__(self, latent_dim):
super(WorldModel, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=2),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2),
nn.ReLU(),
nn.Flatten(),
nn.Linear(32 * 14 * 14, latent_dim)
)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 32 * 14 * 14),
nn.Unflatten(1, (32, 14, 14)),
nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(16, 3, kernel_size=3, stride=2),
nn.Sigmoid()
)
self.dynamics = nn.LSTM(latent_dim, latent_dim)
self.reward_predictor = nn.Linear(latent_dim, 1)
def forward(self, x):
z = self.encoder(x)
reconstructed = self.decoder(z)
return reconstructed
def predict_dynamics(self, z, hidden=None):
out, hidden = self.dynamics(z.unsqueeze(0), hidden)
return out.squeeze(0), hidden
def predict_reward(self, z):
return self.reward_predictor(z)import torch.optim as optim
class PolicyOptimizer:
def __init__(self, world_model, latent_dim, action_dim):
self.world_model = world_model
self.actor = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, action_dim)
)
self.critic = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
self.optimizer = optim.Adam(list(world_model.parameters()) +
list(self.actor.parameters()) +
list(self.critic.parameters()), lr=1e-3)
def train_step(self, initial_state):
# Generate imagined trajectories
trajectories = self._generate_trajectories(initial_state)
# Evaluate trajectories
rewards = self._evaluate_trajectories(trajectories)
# Update policy and value networks
loss = self._update_policy_and_value_networks(trajectories, rewards)
return loss
def _generate_trajectories(self, initial_state):
# Start with the initial state
state = initial_state
trajectories = []
for _ in range(10): # Number of steps to imagine
action = self.actor(state)
next_state, reward = self._simulate_step(state, action)
trajectories.append((state, action, reward))
state = next_state
return trajectories
def _simulate_step(self, state, action):
# Predict next state and reward
next_state, _ = self.world_model.predict_dynamics(state)
reward = self.world_model.predict_reward(next_state)
return next_state, reward
def _evaluate_trajectories(self, trajectories):
# Calculate total rewards for each trajectory
total_rewards = [sum(r for _, _, r in traj) for traj in trajectories]
return total_rewards
def _update_policy_and_value_networks(self, trajectories, rewards):
# Convert trajectories to tensors
states, actions, _ = zip(*trajectories)
states = torch.stack(states)
actions = torch.stack(actions)
rewards = torch.tensor(rewards)
# Calculate advantages
values = self.critic(states).squeeze()
advantages = rewards - values.detach()
# Actor loss
actor_loss = -(advantages * actions.log_prob()).mean()
# Critic loss
critic_loss = advantages.pow(2).mean()
# Total loss
total_loss = actor_loss + 0.5 * critic_loss
# Backpropagation
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return total_loss.item()def train():
config = {
'target_size': 100,
'size_threshold': 200
}
env = MicrorobotEnvironment(config)
world_model = WorldModel(latent_dim=128)
policy_optimizer = PolicyOptimizer(world_model, latent_dim=128, action_dim=4)
num_episodes = 100
for episode in range(num_episodes):
state = env.reset()
done = False
total_reward = 0
while not done:
# Convert state to tensor
state_tensor = torch.tensor(state['frame'], dtype=torch.float32).permute(2, 0, 1).unsqueeze(0)
# Get action from policy optimizer
action = policy_optimizer.actor(state_tensor)
# Take step in environment
next_state, reward, done = env.step(action.detach().numpy())
total_reward += reward
state = next_state
print(f"Episode {episode}, Total Reward: {total_reward}")
if __name__ == "__main__":
train()If you’re Interested in Large Language Model, you may also find this article helpful: 7 Revolutionary Insights About ToDi (Token-wise Distillation): The Future of Language Model Efficiency
Pingback: 7 Groundbreaking Innovations in Cardiac Digital Twins: Unlocking the Future of Precision Cardiology (and 3 Major Challenges Holding It Back) - aitrendblend.com