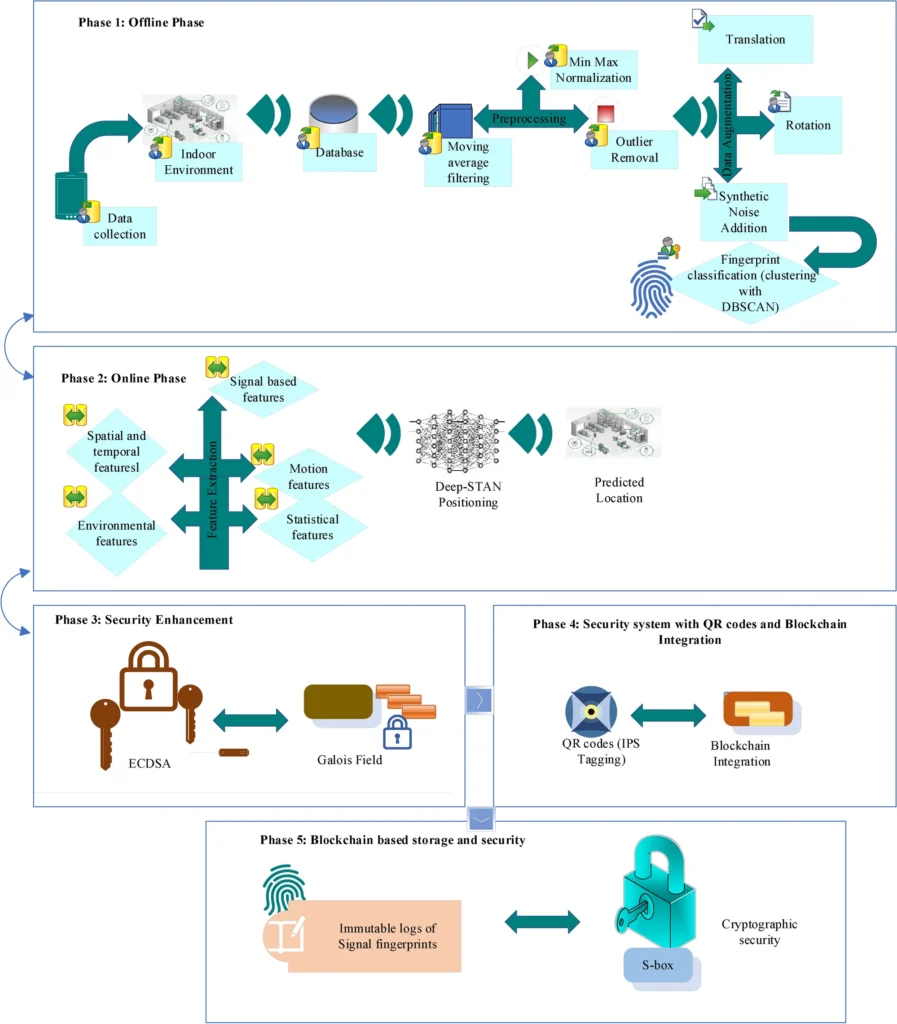
High-Accuracy Indoor Positioning Systems: Using Galois Field Cryptography and Hybrid Deep Learning
Indoor positioning systems (IPS) have emerged as a critical technology in the age of smart manufacturing, logistics, and enterprise solutions. Unlike GPS, which relies on satellite signals that cannot penetrate building structures, IPS provides accurate location tracking within enclosed environments. This capability has become indispensable for warehouses, hospitals, shopping malls, airports, and manufacturing facilities where […]