Struggling with noisy, unreliable pseudo-labels crippling your semi-supervised learning (SSL) models? Discover the lightweight, plug-and-play Channel-Based Ensemble (CBE) method proven to slash error rates by up to 8.72% on CIFAR10 with minimal compute overhead. This isn’t just another tweak – it’s a fundamental fix for biased, high-variance predictions.
Keywords: Semi-Supervised Learning, Pseudo-Labels, Channel-Ensemble, Unbiased Low-Variance, FixMatch Enhancement, FreeMatch Improvement, SSL Efficiency, CIFAR10 Results, CIFAR100 Results, Lightweight Ensemble.
The Pseudo-Label Problem: Why Your SSL Model is Stuck
Semi-supervised learning (SSL) promises revolutionary efficiency: train powerful models using mostly unlabeled data alongside a tiny labeled set. Techniques like FixMatch and FreeMatch dominate the State-of-the-Art (SOTA) by generating “pseudo-labels” (PLs) for unlabeled data – predictions used as training targets. But here’s the devastating flaw:
- Bias Accumulation: Self-training models inevitably make errors. These errors get recycled as pseudo-labels, poisoning the training process, especially with scarce labeled data (e.g., just 40 labels on CIFAR-10!).
- High Prediction Variance: Model predictions fluctuate wildly under different augmentations or perturbations. This inconsistency makes pseudo-labels unreliable, hindering stable learning.
- Confidence ≠ Correctness: A high confidence score (like 0.95) does not guarantee an accurate prediction. Wrong but confident PLs are catastrophic.
Result: Performance plateaus, training becomes inefficient, and the promised potential of SSL remains frustratingly out of reach. Existing solutions focus on thresholds or augmentation but ignore the core quality of the PLs themselves – their bias and variance. *(Fig 1: Original paper shows low PL accuracy & sampling rate for FixMatch/FreeMatch vs CBE)*
The Channel-Ensemble Breakthrough: Unbiased, Low-Variance PLs Made Easy
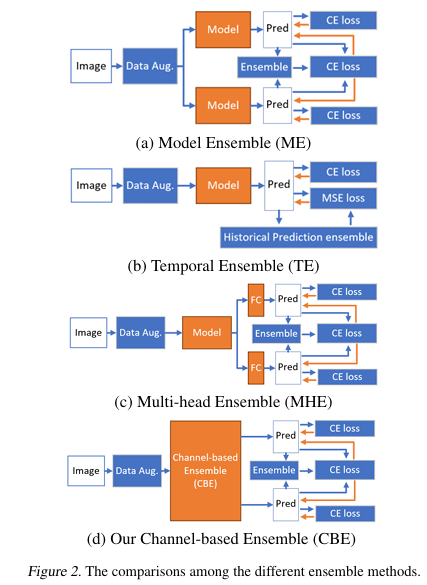
Inspired by classical ensemble wisdom (like Random Forests) but designed for modern SSL efficiency, researchers Jiaqi Wu et al. introduce the Channel-Based Ensemble (CBE). This isn’t your bulky, impractical ensemble.
How CBE Works (Simply):
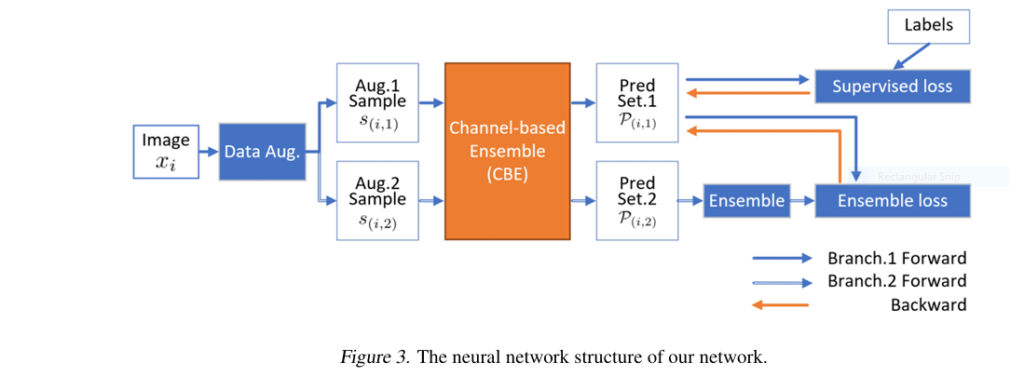
- Lightweight Multi-Head Predictor: A single base model (e.g., Wide ResNet) is modified using efficient
1x1convolutions to createMprediction “heads” (e.g., 5). Each head gets a shared base feature + a small private feature channel. (Fig 3,4) - Ensemble Prediction: For an input (weakly or strongly augmented), all
Mheads make predictions. The final pseudo-label is the average of these predictions. (Eq 2) - Chebyshev Constraint Theory: Mathematical guarantees (Lemmas 1 & 2) show ensemble error reduces with lower individual head variance and lower correlation (diversity) between heads.
- Specialized Losses Enforce Quality:
- Low Bias (LB) Loss (Eq 6): Maximizes diversity by minimizing the correlation between the private features of different heads. Fights homogeneity, ensuring heads learn complementary perspectives.
- Low Variance (LV) Loss (Eq 8): Uses the small labeled set as an anchor. Maximizes the covariance between the ensemble prediction and the true labels on labeled data, stabilizing predictions across the model.
The Magic: CBE consolidates multiple potentially “inferior” predictions from its heads into a single theoretically guaranteed unbiased and low-variance pseudo-label. It tackles bias (via diversity) and variance (via stabilization) at the source.
Why CBE is a Game-Changer for SSL: Stunning Results & Benefits
The results on CIFAR10 and CIFAR100 speak volumes, especially in the crucial low-label regime:
Table 1: Error Rate Reductions (Lower is Better)
| Method | CIFAR10 (40 Labels) | CIFAR100 (400 Labels) | Key Improvement |
|---|---|---|---|
| FixMatch (SOTA) | 8.15% | 51.74% | Baseline |
| FixMatch + CBE | 7.21% | 51.17% | +0.94% |
| FreeMatch (SOTA) | 14.85% | 44.41% | Baseline |
| FreeMatch + CBE | 6.13% | 43.64% | +8.72% |
(Source: Adapted from Table 1, Wu et al. 2403.18407v1)
Key Advantages You Can’t Ignore:
- Massive Accuracy Gains: Up to 8.72% absolute error reduction vs SOTA methods. Unlocks performance previously impossible with limited labels.
- Unbiased & Stable PLs: Directly addresses the core failure mode of self-training – biased error accumulation and unstable predictions.
- Plug-and-Play Simplicity: Integrates into any SSL framework (FixMatch, FreeMatch, Mean Teacher) with minimal changes:
- Replace the classifier with the CBE multi-head structure.
- Use the original method’s threshold on the ensemble prediction.
- Replace the unsupervised loss with the CBE ensemble loss (Eq 3).
- Negligible Compute Overhead: Forget training 5 separate models! CBE adds only ~0.136M parameters and ~0.005M FLOPs – a rounding error compared to the base model cost. (Table 4)
- Higher Quality PLs, Lower Sampling Rate: CBE achieves higher pseudo-label accuracy while often using fewer pseudo-labels (lower Sampling Rate – SR) than FreeMatch. It provides richer correct knowledge. (Fig 1)
- Faster Convergence: Producing better PLs faster leads to more efficient training. FixMatch + CBE reached a lower error rate (5.20%) in the same training time (4096 min) or matched FixMatch’s performance in half the time (2048 min). (Table 3)
- Theoretical Foundation: Grounded in Chebyshev’s inequality and ensemble theory, providing guarantees missing from methods like Temporal Ensemble.
Implementing the Fix: How CBE Crushes Bias & Variance (Ablation Proof)
Ablation studies on CIFAR10@40 (Table 2) show the power of each component:
- Just CBE Structure (No LB/LV Loss): +4.59% over FreeMatch. Proves the ensemble structure helps, but heads become homogeneous over time, limiting gains. (Fig 5)
- CBE + LB Loss (No LV Loss): +1.43% further improvement. The Low Bias loss successfully enforces diversity, unlocking significant extra gain.
- Full CBE (LB + LV Loss): +2.20% additional improvement. The Low Variance loss stabilizes predictions, maximizing the ensemble’s potential. Total Gain: 8.72%!
Visual Proof: Confusion matrices (Fig 6) clearly show CBE generates dramatically more accurate pseudo-labels earlier and more consistently than FreeMatch alone, preventing error accumulation.
Conclusion & Call to Action: Ditch Noisy Pseudo-Labels, Embrace CBE
The Channel-Based Ensemble (CBE) isn’t an incremental step; it’s a paradigm shift for semi-supervised learning. By directly generating unbiased and low-variance pseudo-labels through a theoretically sound, computationally efficient ensemble mechanism, it solves the core problem plaguing self-training methods.
The evidence is undeniable: Significant error reductions on standard benchmarks (CIFAR10/100), especially with scarce labels, minimal overhead, seamless integration, and faster convergence. Stop letting noisy pseudo-labels sabotage your SSL results.
Ready to implement unbiased, low-variance pseudo-labels?
- Read the Paper: Dive deeper into the Channel-Ensemble approach: A Channel-ensemble Approach: Unbiased and Low-variance Pseudo-labels is Critical for Semi-supervised Classification (2403.18407v1)
- Check the Code: Look for the authors’ official implementation (likely on GitHub soon – search paper title).
- Revolutionize Your SSL Pipeline: Integrate CBE into your next FixMatch, FreeMatch, or custom SSL project. Experience the performance leap firsthand!
- Share & Discuss: Have you tried CBE or faced pseudo-label challenges? Share your experiences or questions in the comments below!
Don’t settle for biased, unstable pseudo-labels. Leverage CBE and unlock the true potential of your semi-supervised learning models today!
Below is the complete implementation of the Channel-Based Ensemble (CBE) model as described in the paper. The code includes the model architecture, specialized losses, and ensemble pseudo-label generation:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.cuda.amp import autocast
class ChannelBasedEnsemble(nn.Module):
def __init__(self, backbone, num_classes=10, num_heads=5, C_G=64):
"""
Channel-Based Ensemble (CBE) Model
Args:
backbone: Feature extractor (e.g., WideResNet)
num_classes: Number of output classes
num_heads: Number of prediction heads (M)
C_G: Private feature channels per head
"""
super().__init__()
self.backbone = backbone
self.num_heads = num_heads
self.C_G = C_G
self.C_F = backbone.output_dim # Original feature channels
# Expansion layer (1x1 conv equivalent)
self.expand = nn.Linear(self.C_F, self.C_F + num_heads * C_G)
# Prediction heads
self.heads = nn.ModuleList([
nn.Linear(self.C_F + C_G, num_classes) for _ in range(num_heads)
])
def forward(self, x):
# Feature extraction
f = self.backbone(x) # [batch, C_F]
# Feature expansion
expanded = self.expand(f) # [batch, C_F + M*C_G]
# Split into shared and private features
shared = expanded[:, :self.C_F] # [batch, C_F]
private = expanded[:, self.C_F:] # [batch, M*C_G]
# Split private features per head
private_list = torch.split(private, self.C_G, dim=1) # M x [batch, C_G]
# Generate predictions per head
logits_list = []
for i in range(self.num_heads):
head_input = torch.cat([shared, private_list[i]], dim=1)
logits_list.append(self.heads[i](head_input))
return logits_list, private_list
class CBELoss(nn.Module):
def __init__(self, num_heads=5, lambda_l=1.0, lambda_e=1.0, lambda_fu=1.0, lambda_lv=1.0):
"""
CBE Loss Function
Combines:
- Supervised loss (L_l)
- Ensemble consistency loss (L_e)
- Low Bias loss (L_fu)
- Low Variance loss (L_lv)
"""
super().__init__()
self.num_heads = num_heads
self.lambda_l = lambda_l
self.lambda_e = lambda_e
self.lambda_fu = lambda_fu
self.lambda_lv = lambda_lv
def low_bias_loss(self, private_list):
"""
Low Bias Loss (L_fu) - Maximizes feature decorrelation
"""
# Stack private features: [batch, num_heads, C_G]
private_stack = torch.stack(private_list, dim=1)
batch_size, _, C_G = private_stack.shape
# Compute Gram matrix
gram = torch.bmm(private_stack, private_stack.transpose(1, 2)) # [batch, M, M]
# Remove diagonals and normalize
off_diag = gram - torch.diag_embed(gram.diagonal(dim1=1, dim2=2))
loss = off_diag.norm(p='fro') / (self.num_heads * (self.num_heads - 1) * batch_size)
return loss
def low_variance_loss(self, ensemble_conf, targets):
"""
Low Variance Loss (L_lv) - Stabilizes predictions
"""
# Flatten predictions and targets
P = ensemble_conf.flatten()
Y = targets.flatten()
# Compute Pearson correlation
cov = torch.cov(torch.stack([P, Y]))
corr = cov[0, 1] / (P.std() * Y.std() + 1e-8)
return 1 - corr
def forward(self, logits_list, private_list, ensemble_conf, targets, mask_sample=None):
"""
Calculate total CBE loss
Args:
logits_list: List of head predictions
private_list: List of private features
ensemble_conf: Ensemble prediction probabilities
targets: Ground truth labels
mask_sample: Sample selection mask for unlabeled data
"""
# Supervised loss (L_l)
sup_loss = 0
for logits in logits_list:
sup_loss += F.cross_entropy(logits, targets)
sup_loss /= self.num_heads
# Ensemble consistency loss (L_e)
cons_loss = 0
if mask_sample is not None:
for logits in logits_list:
# Soft cross-entropy for soft targets
log_probs = F.log_softmax(logits, dim=1)
cons_loss += -(ensemble_conf * log_probs).sum(dim=1)
# Apply sample selection mask
cons_loss = (cons_loss * mask_sample).sum()
cons_loss /= (mask_sample.sum() * self.num_heads + 1e-8)
# Low Bias loss (L_fu)
lb_loss = self.low_bias_loss(private_list)
# Low Variance loss (L_lv)
lv_loss = self.low_variance_loss(ensemble_conf, targets)
# Weighted sum
total_loss = (self.lambda_l * sup_loss +
self.lambda_e * cons_loss +
self.lambda_fu * lb_loss +
self.lambda_lv * lv_loss)
return total_loss
def generate_pseudo_labels(logits_list, threshold=0.95):
"""
Generate ensemble pseudo-labels with thresholding
Args:
logits_list: List of head predictions
threshold: Confidence threshold
Returns:
ensemble_conf: Ensemble probabilities
mask_sample: Sample selection mask
"""
# Compute confidences
conf_list = [F.softmax(logits, dim=1) for logits in logits_list]
# Ensemble confidence (average)
ensemble_conf = torch.stack(conf_list).mean(dim=0)
# Confidence-based masking
max_conf, _ = ensemble_conf.max(dim=1)
mask_sample = (max_conf >= threshold).float()
return ensemble_conf, mask_sample
# Example Backbone (WideResNet)
class WideResNet(nn.Module):
def __init__(self, widen_factor=2, num_classes=10):
super().__init__()
# Simplified WRN architecture
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.block1 = self._make_block(16, 16 * widen_factor, stride=1)
self.block2 = self._make_block(16 * widen_factor, 32 * widen_factor, stride=2)
self.block3 = self._make_block(32 * widen_factor, 64 * widen_factor, stride=2)
self.bn = nn.BatchNorm2d(64 * widen_factor)
self.relu = nn.ReLU(inplace=True)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.output_dim = 64 * widen_factor
def _make_block(self, in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, stride, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv1(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.bn(x)
x = self.relu(x)
x = self.avgpool(x)
return x.flatten(1)
# Example Usage
if __name__ == "__main__":
# Hyperparameters
num_classes = 10
num_heads = 5
C_G = 64
batch_size = 32
# Create model
backbone = WideResNet(widen_factor=2, num_classes=num_classes)
model = ChannelBasedEnsemble(backbone, num_classes, num_heads, C_G)
# Loss function
criterion = CBELoss(num_heads=num_heads)
# Example data
x_labeled = torch.randn(batch_size, 3, 32, 32)
y_labeled = torch.randint(0, num_classes, (batch_size,))
x_unlabeled = torch.randn(batch_size, 3, 32, 32)
# Forward pass (labeled data)
logits_list, private_list = model(x_labeled)
# Generate pseudo-labels (unlabeled data)
with torch.no_grad():
ul_logits, _ = model(x_unlabeled)
ensemble_conf, mask_sample = generate_pseudo_labels(ul_logits)
# Convert labels to one-hot
targets = F.one_hot(y_labeled, num_classes).float()
# Compute losses
loss = criterion(
logits_list=logits_list,
private_list=private_list,
ensemble_conf=ensemble_conf,
targets=targets,
mask_sample=mask_sample
)
print(f"Total loss: {loss.item():.4f}")If you’re Interested in semi-supervised learning, you may also find this article helpful: Revolutionize Change Detection: How SemiCD-VL Cuts Labeling Costs 5X While Boosting Accuracy
Pingback: 7 Powerful Reasons Why BaCon Outperforms and Fixes Broken Semi-Supervised Learning Systems - aitrendblend.com