Imagine training a brilliant professor (a large AI model) to teach complex physics to a middle school student (a tiny, efficient model). The professor’s expertise is vast, but their explanations are too advanced, leaving the student confused and unable to grasp the fundamentals. This is the “capacity gap problem” – the Achilles’ heel of traditional Knowledge Distillation (KD) – and it silently cripples the performance of small AI models designed for phones, sensors, and edge devices.
For years, researchers wrestled with this gap. Techniques like Teacher Assistants (TAKD) or Early Stopping (ESKD) either diluted the teacher’s valuable knowledge or failed to adapt their teaching as the student learned. The result? Students consistently underperformed, unable to reach their teacher’s potential, wasting precious computational resources during training.
The Game-Changer: Dual-Forward Path Teacher Knowledge Distillation (DFPT-KD)
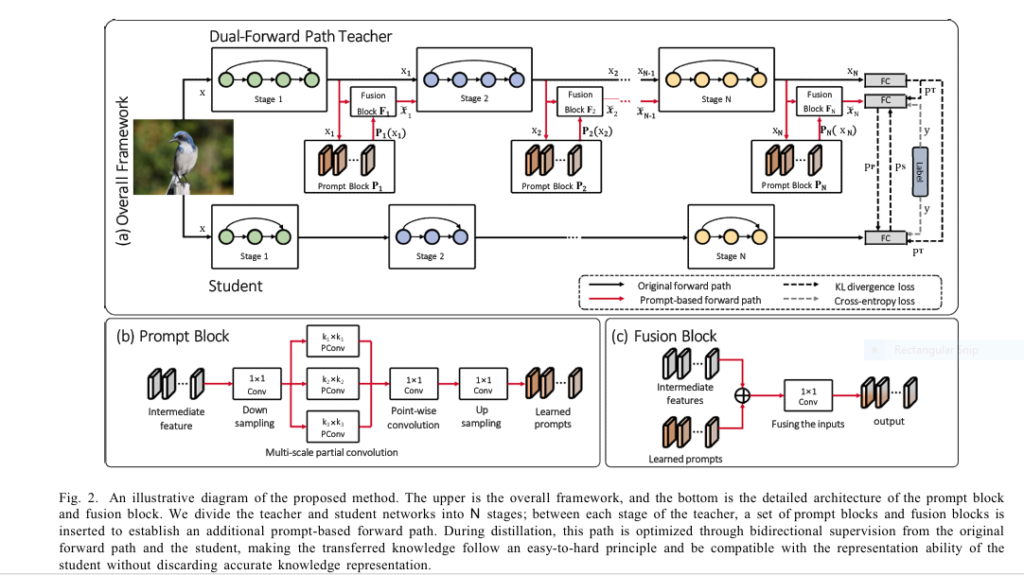
Enter Dual-Forward Path Teacher Knowledge Distillation (DFPT-KD), a revolutionary approach pioneered by researchers at Xi’an University of Technology. Forget discarding accurate knowledge or static teaching methods. DFPT-KD’s genius lies in giving the teacher two distinct ways to process information:
- The Original Path: Preserves the teacher’s pre-trained, high-accuracy knowledge – the gold standard.
- The Prompt-Based Path: A dynamic, adaptable pathway infused with lightweight “prompt blocks.”
How DFPT-KD Works (The Simple Analogy):
Think of the prompt blocks as a real-time “knowledge translator” or “simplifier” inserted into the teacher’s brain. As data flows through the teacher:
- The Original Path generates the complex, high-fidelity answer (accurate knowledge).
- The Prompt-Based Path uses the prompts to adjust the teacher’s internal feature representations, creating a simplified, student-friendly version of the knowledge (compatible knowledge).
- Crucially, only the prompt blocks are trained during distillation, keeping the teacher’s core expertise intact.
The Secret Sauce: Bidirectional Supervision
The prompt-based path isn’t trained in isolation. It receives crucial feedback from both directions:
- Teacher Supervision (
LKD(pp, pT)): Ensures the simplified knowledge doesn’t stray too far from the teacher’s original accuracy. - Student Supervision (
LKD(p): Forces the prompt-based path to adapt its output to what the student can actually understand right now.P , pS)
This creates an “easy-to-hard” learning curriculum for the student. Early in training, the prompt-based path provides highly compatible, simpler knowledge. As the student improves, the prompt-based path dynamically adjusts, offering progressively more complex insights, always perfectly matched to the student’s current ability.
Leveling Up: DFPT-KD† – The Ultimate Distillation Powerhouse
The researchers didn’t stop there. They introduced DFPT-KD† (DFPT-KDI), a powerful evolution. While DFPT-KD only trains the prompt blocks, DFPT-KDI takes the bold step of fine-tuning the entire prompt-based forward path (including the teacher’s backbone layers within that path) using a minimal learning rate.
Why This Works Wonders:
This subtle adjustment allows the knowledge transformation within the prompt-based path to become even more deeply aligned with the student’s representation capacity. It further bridges the residual gap, unlocking even higher student performance without sacrificing the original path’s accuracy.
Proven Results: Smashing Benchmarks & Even Topping Teachers
The paper validates DFPT-KD and DFPT-KD† across major datasets (CIFAR-100, ImageNet, CUB-200) and diverse model architectures (ResNet, VGG, ShuffleNet, MobileNet). The results are nothing short of spectacular:
(Keywords: Model Compression Results, State-of-the-Art Accuracy)
- CIFAR-100 (ShuffleNetV1 Student, WRN-40-2 Teacher):
- DFPT-KD: 77.67% (Surpasses Vanilla KD by ~4.15%)
- DFPT-KD†: 78.29% (Surpasses the Teacher by 2.68%!)
- ImageNet (ResNet18 Student, ResNet34 Teacher):
- DFPT-KD† achieved +1.77% Top-1 accuracy gain over Vanilla KD.
- CUB-200 (Fine-Grained Challenge):
- DFPT-KD† outperformed Vanilla KD by up to 11.48%, showcasing exceptional strength in detail-oriented tasks.
- Consistent Superiority: Both DFPT-KD and DFPT-KD† consistently outperformed numerous state-of-the-art methods (FitNet, AT, CRD, DKD, ReviewKD, etc.) across homogeneous and heterogeneous teacher-student pairs.
Table: DFPT-KD† Performance Highlights vs. Vanilla KD
| Dataset | Teacher -> Student | Top-1 Acc. Gain | Remark |
|---|---|---|---|
| CIFAR-100 | WRN-40-2 -> ShuffleNetV1 | +5.30% | Surpassed Teacher by 2.68% |
| CIFAR-100 | ResNet32x4 -> ResNet8x4 | +3.40% | Significant Capacity Gap |
| ImageNet | ResNet34 -> ResNet18 | +1.77% | Large-Scale Validation |
| ImageNet | ResNet50 -> MobileNetV2 | +2.96% | Efficient Mobile Model |
| CUB-200 (Fine-Grained) | VGG13 -> MobileNetV2 | +10.41% (DFPT-KD) | Excels in Detail Recognition |
Why DFPT-KD is a Practical Powerhouse (Beyond Academia)
(Keywords: Efficient AI Deployment, Edge AI Optimization)
The implications are massive for real-world AI deployment:
- Slash Edge AI Costs: Train vastly smaller models (ShuffleNet, MobileNet) that perform as well or better than larger teachers, reducing cloud dependency and inference costs on devices.
- Overcome Hardware Limits: Deploy sophisticated AI capabilities on microcontrollers, phones, and sensors previously constrained by model size.
- Simplify Fine-Grained AI: Achieve state-of-the-art accuracy in challenging tasks like medical imaging or wildlife identification (CUB-200 results prove this) on efficient hardware.
- Future-Proof Compression: The prompt-based tuning paradigm offers a flexible framework adaptable beyond classification (e.g., object detection, segmentation distillation).
If you’re Interested in semi-supervised learning with Knowledge Distillation model, you may also find this article helpful: Unlock 5.7% Higher Accuracy: How KD-FixMatch Crushes Noisy Labels in Semi-Supervised Learning (And Why FixMatch Falls Short)
The Future is Dual-Path: Your Next Step
(Keywords: AI Model Optimization, Knowledge Distillation Implementation)
Dual-Forward Path Teacher Knowledge Distillation isn’t just an academic curiosity; it’s a practical blueprint for overcoming the fundamental bottleneck in small model performance. By preserving accurate knowledge while dynamically generating compatible knowledge, DFPT-KD and DFPT-KD† finally deliver on the true promise of knowledge distillation: getting big model wisdom into tiny, efficient packages.
Ready to Crush the Capacity Gap in Your AI Projects?
- Deep Dive into the Paper: Explore the original research for architectural details and full results: Link to Arxiv Paper 2506.18244v1 (Use relevant anchor text).
- Experiment with Code: Watch for official implementations (or create your own based on the paper’s methodology).
- Evaluate for Your Task: Consider how DFPT-KD could optimize your specific model deployment challenges, especially on resource-constrained devices or for fine-grained tasks.
Don’t let the capacity gap limit your AI potential. Embrace the dual-path revolution and build smaller, smarter, faster models today!
To implement the Dual-Forward Path Teacher Knowledge Distillation (DFPT-KD) model, here’s the complete PyTorch code based on the paper’s specifications. The implementation includes the prompt blocks, fusion blocks, dual-path teacher, and distillation training logic:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
class PromptBlock(nn.Module):
"""
Lightweight prompt block with multi-scale partial convolutions
r1: Channel downsampling ratio (default=4)
r2: Partial convolution ratio (default=0.5)
"""
def __init__(self, in_channels, r1=4, r2=0.5):
super().__init__()
self.down_channels = max(1, in_channels // r1)
self.partial_channels = int(self.down_channels * r2)
self.group_size = self.partial_channels // 3
# 1x1 downsampling convolution
self.down_conv = nn.Sequential(
nn.Conv2d(in_channels, self.down_channels, 1),
nn.BatchNorm2d(self.down_channels),
nn.ReLU(inplace=True)
)
# Multi-scale partial convolutions
self.conv3x3 = nn.Sequential(
nn.Conv2d(self.group_size, self.group_size, 3, padding=1),
nn.BatchNorm2d(self.group_size),
nn.ReLU(inplace=True)
)
self.conv5x5 = nn.Sequential(
nn.Conv2d(self.group_size, self.group_size, 5, padding=2),
nn.BatchNorm2d(self.group_size),
nn.ReLU(inplace=True)
)
self.conv7x7 = nn.Sequential(
nn.Conv2d(self.group_size, self.group_size, 7, padding=3),
nn.BatchNorm2d(self.group_size),
nn.ReLU(inplace=True)
)
# Pointwise convolutions
self.pointwise1 = nn.Conv2d(self.group_size, self.group_size, 1)
self.pointwise2 = nn.Conv2d(self.group_size, self.group_size, 1)
self.pointwise3 = nn.Conv2d(self.group_size, self.group_size, 1)
# 1x1 upsampling convolution
self.up_conv = nn.Conv2d(self.down_channels, in_channels, 1)
def forward(self, x):
identity = x
x = self.down_conv(x)
# Split channels into four groups
groups = torch.split(x, [
self.group_size,
self.group_size,
self.group_size,
self.down_channels - 3*self.group_size
], dim=1)
# Process first three groups with different kernel sizes
g1 = self.pointwise1(self.conv3x3(groups[0]))
g2 = self.pointwise2(self.conv5x5(groups[1]))
g3 = self.pointwise3(self.conv7x7(groups[2]))
g4 = groups[3] # Identity branch
# Concatenate processed groups
x = torch.cat([g1, g2, g3, g4], dim=1)
x = self.up_conv(x)
return x + identity # Residual connection
class FusionBlock(nn.Module):
"""Feature fusion block with adaptive weighting"""
def __init__(self, in_channels):
super().__init__()
self.fusion = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 1),
nn.Sigmoid() # Adaptive weighting
)
def forward(self, x):
weights = self.fusion(x)
return x * weights
class DualPathTeacher(nn.Module):
"""
Dual-forward path teacher with prompt-based path
teacher_model: Pre-trained teacher model (e.g., ResNet34)
num_stages: Number of stages to insert prompt blocks
"""
def __init__(self, teacher_model, num_stages=4):
super().__init__()
self.teacher = teacher_model
self.freeze_teacher()
# Split teacher into stages
self.stages = nn.ModuleList([
nn.Sequential(
self.teacher.conv1,
self.teacher.bn1,
self.teacher.relu,
self.teacher.maxpool
),
self.teacher.layer1,
self.teacher.layer2,
self.teacher.layer3,
self.teacher.layer4
])
# Prompt and fusion blocks
self.prompt_blocks = nn.ModuleList()
self.fusion_blocks = nn.ModuleList()
# Get channel dimensions for each stage
in_channels = [
64,
self.stages[1][-1].bn3.num_features,
self.stages[2][-1].bn3.num_features,
self.stages[3][-1].bn3.num_features
]
# Create prompt and fusion blocks for each stage
for i in range(num_stages):
self.prompt_blocks.append(PromptBlock(in_channels[i]))
self.fusion_blocks.append(FusionBlock(in_channels[i]))
# New classification head for prompt path
self.prompt_head = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(in_channels[-1], self.teacher.fc.out_features)
)
def freeze_teacher(self):
"""Freeze original teacher parameters"""
for param in self.teacher.parameters():
param.requires_grad = False
def forward_original(self, x):
"""Original teacher forward path"""
return self.teacher(x)
def forward_prompt(self, x):
"""Prompt-based forward path"""
# Initial layers
x = self.stages[0](x)
# Process through stages with prompt blocks
for i in range(1, len(self.stages)):
x = self.stages[i](x)
# Insert prompt and fusion after stage (except last)
if i < len(self.stages) - 1:
prompt = self.prompt_blocks[i-1](x)
x = self.fusion_blocks[i-1](x + prompt)
# Prompt path classification head
return self.prompt_head(x)
def forward(self, x):
"""Dual forward paths"""
with torch.no_grad():
original_out = self.forward_original(x)
prompt_out = self.forward_prompt(x)
return original_out, prompt_out
class DFPTKD:
"""Dual-Forward Path Teacher Knowledge Distillation"""
def __init__(self, teacher, student, alpha=0.5, beta=0.5, lambda_val=0.7):
self.dual_teacher = DualPathTeacher(teacher)
self.student = student
self.alpha = alpha # CE loss weight
self.beta = beta # KD loss weight
self.lambda_val = lambda_val # Prompt path supervision weight
# Optimizers (only prompt path parameters)
prompt_params = list(self.dual_teacher.prompt_blocks.parameters()) + \
list(self.dual_teacher.fusion_blocks.parameters()) + \
list(self.dual_teacher.prompt_head.parameters())
self.optimizer_teacher = torch.optim.SGD(prompt_params, lr=0.05, momentum=0.9)
self.optimizer_student = torch.optim.SGD(self.student.parameters(), lr=0.05, momentum=0.9)
# Loss functions
self.ce_loss = nn.CrossEntropyLoss()
self.kl_loss = nn.KLDivLoss(reduction='batchmean')
def train_step(self, data, targets, temperature=4):
# ------------------------
# Train prompt path
# ------------------------
self.optimizer_teacher.zero_grad()
# Forward passes
teacher_orig, teacher_prompt = self.dual_teacher(data)
student_out = self.student(data)
# Bidirectional supervision loss
ce_prompt = self.ce_loss(teacher_prompt, targets)
kl_teacher = self.kl_loss(
F.log_softmax(teacher_prompt / temperature, dim=1),
F.softmax(teacher_orig.detach() / temperature, dim=1)
)
kl_student = self.kl_loss(
F.log_softmax(teacher_prompt / temperature, dim=1),
F.softmax(student_out.detach() / temperature, dim=1)
)
loss_prompt = (self.lambda_val * ce_prompt +
(1 - self.lambda_val) * (kl_teacher + kl_student))
loss_prompt.backward()
self.optimizer_teacher.step()
# ------------------------
# Train student
# ------------------------
self.optimizer_student.zero_grad()
# Forward passes (recompute for updated prompt path)
with torch.no_grad():
teacher_orig, teacher_prompt = self.dual_teacher(data)
student_out = self.student(data)
# Student loss
ce_student = self.ce_loss(student_out, targets)
kl_orig = self.kl_loss(
F.log_softmax(student_out / temperature, dim=1),
F.softmax(teacher_orig / temperature, dim=1)
)
kl_prompt = self.kl_loss(
F.log_softmax(student_out / temperature, dim=1),
F.softmax(teacher_prompt / temperature, dim=1)
)
loss_student = (self.alpha * ce_student +
self.beta * (kl_orig + kl_prompt))
loss_student.backward()
self.optimizer_student.step()
return loss_prompt.item(), loss_student.item()
class DFPTKDI(DFPTKD):
"""Enhanced DFPT-KD with full prompt path fine-tuning"""
def __init__(self, teacher, student, alpha=0.5, beta=0.5, lambda_val=0.7):
super().__init__(teacher, student, alpha, beta, lambda_val)
# Unfreeze teacher backbone for prompt path
for param in self.dual_teacher.stages.parameters():
param.requires_grad = True
# Lower learning rate for backbone
prompt_path_params = [
{'params': self.dual_teacher.stages.parameters(), 'lr': 0.005},
{'params': self.dual_teacher.prompt_blocks.parameters()},
{'params': self.dual_teacher.fusion_blocks.parameters()},
{'params': self.dual_teacher.prompt_head.parameters()}
]
self.optimizer_teacher = torch.optim.SGD(prompt_path_params, lr=0.05, momentum=0.9)
# Example Usage
if __name__ == "__main__":
# Initialize models
teacher = models.resnet34(pretrained=True)
student = models.resnet18(pretrained=False)
# Create distiller
distiller = DFPTKDI(teacher, student)
# Training loop example
for epoch in range(100):
for data, targets in train_loader: # Your data loader
loss_prompt, loss_student = distiller.train_step(data, targets)
print(f"Epoch: {epoch} | Prompt Loss: {loss_prompt:.4f} | "
f"Student Loss: {loss_student:.4f}")
# Save distilled student
torch.save(distiller.student.state_dict(), "distilled_student.pth")
Pingback: 97% Smaller, 93% as Accurate: Revolutionizing Retinal Disease Detection on Edge Devices - aitrendblend.com