Introduction: The Challenge of Audio-Vision Integration in Omnimodal LLMs
Omnimodal Large Language Models (OLLMs) like GPT-4o and Megrez have revolutionized how AI interacts with the world by seamlessly processing text, images, and audio. However, a critical performance gap persists: OLLMs perform significantly better with vision-text inputs than with vision-audio inputs.
For example, when asked “What’s the name of the book on the top of the pile?” in text form, models like Megrez answer correctly with “Ariel”. But when the same question is spoken, the model might respond with “Plays pleasant” — a plausible but incorrect answer. This inconsistency reveals a fundamental flaw: vision-audio integration lags far behind vision-text integration.
In this article, we dive into a groundbreaking solution proposed in the paper “Investigating and Enhancing Vision-Audio Capability in Omnimodal Large Language Models”: Self-Knowledge Distillation (Self-KD). We’ll explore why this gap exists, how Self-KD bridges it, and why this advancement is pivotal for the future of multimodal AI.
Why Vision-Audio Performance Lags Behind Vision-Text
1. The Performance Gap is Real and Widespread
The paper evaluates several OLLMs — VITA, VITA-1.5, and Megrez — across multiple benchmarks like MME, HallusionBench, and TextVQA. Text questions are converted to audio using Text-to-Speech (TTS), ensuring a fair comparison.
| MODEL | VISION-TEXT SCORE | VISION-AUDIO SCORE | PERFORMANCE DROP |
|---|---|---|---|
| VITA-8x7B | 79.45 | 18.19 | 62.20 |
| VITA-1.5-7B | 71.34 | 36.28 | 35.06 |
| Megrez-3B | 68.96 | 49.72 | 19.24 |
As shown, all models suffer a significant drop in accuracy when switching from text to audio queries, with VITA losing over 60 points. This isn’t a minor glitch — it’s a systemic issue in current OLLM architectures.
2. Attention Imbalance: Audio Queries Distract from Visual Cues
Using attention weight analysis, the authors found that:
- In text queries, OLLMs allocate strong attention to both query and image tokens.
- In audio queries, the model focuses more on the audio input itself and less on the visual information.
This imbalance explains why models generate relevant but inaccurate answers. For instance:
- Question:“What’s the least popular game in the chart?”
- Text response: ✅ Simulation
- Audio response: ❌ Puzzle (present in chart, but not the correct answer)
The model sees the chart and hears the question — but fails to integrate them effectively.
3. Weak Modality Alignment Between Vision and Audio
The paper introduces MMAlign, a new benchmark to measure alignment between modalities. It’s based on the ARO dataset and tests whether models can choose the correct caption (e.g., “The white hose is in front of the fence”) over a perturbed one.
Results show:
- Vision-text alignment is strong (e.g., 75.67% accuracy for VITA-1.5).
- Vision-audio alignment is weak (e.g., 32.83% accuracy for VITA-1.5).
This confirms the hypothesis: during training, OLLMs align vision with text and audio with text, but never directly align vision with audio.
The Root Cause: Limitations in OLLM Training Pipelines
Current OLLM training follows four stages:
- Vision-Text Alignment
- Vision-Text Supervised Fine-Tuning (SFT)
- Audio-Text Alignment
- Vision-Audio SFT
While this pipeline enables multimodal understanding, it lacks direct vision-audio alignment. The model is expected to learn vision-audio integration implicitly during SFT — but as the results show, this is insufficient.
“Conventional vision-audio SFT alone is insufficient for enabling the model to effectively integrate vision and audio.”
— Hu et al., 2025
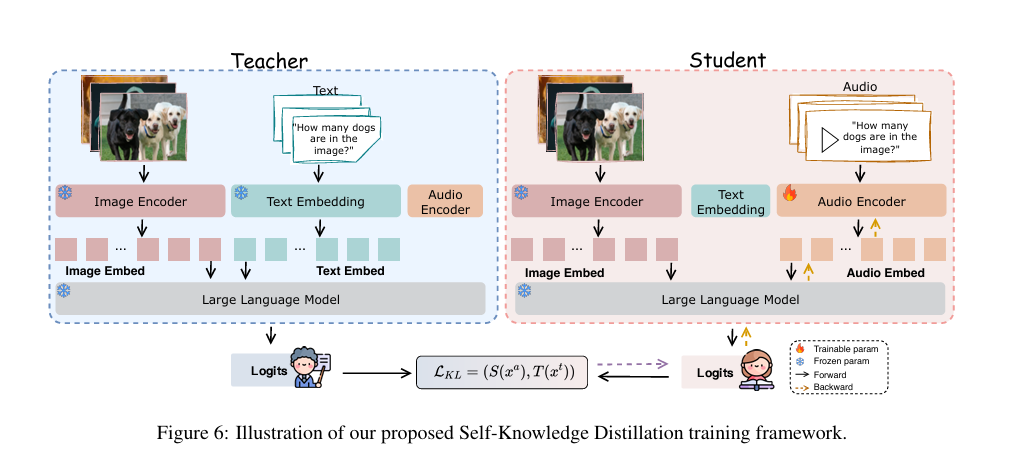
Introducing Self-Knowledge Distillation (Self-KD)
To close the vision-audio performance gap, the authors propose Self-Knowledge Distillation (Self-KD) — a novel training framework where:
- The vision-text component of the OLLM acts as the teacher.
- The vision-audio component acts as the student.
- The student learns to mimic the teacher’s behavior, even when the input modality differs.
How Self-KD Works
Self-KD leverages the KL divergence between the teacher’s output distribution and the student’s:
\[ \mathcal{L}_{\text{Self-KD}} = \mathbb{E}_{x_a \sim X_A, \; x_t \sim X_T, \; y \sim Y} \Big[ \log p_S(y \mid x_a) \, p_T(y \mid x_t) \Big] \]Where:
\[ \begin{aligned} p_{T}(y \mid x_{t}) &: \; \text{Teacher model’s output (vision-text)} \\ p_{S}(y \mid x_{a}) &: \; \text{Student model’s output (vision-audio)} \\ x_{t} &: \; \text{Text query} \\ x_{a} &: \; \text{Audio query} \\ y &: \; \text{Ground truth answer} \end{aligned} \]The total training loss combines Self-KD and standard SFT:
\[ L = \alpha \, L_{\text{Self-KD}} \;+\; (1-\alpha) \, L_{\text{SFT}} \]Here, α controls the balance between distillation and direct supervision.
🔍 Key Insight: Unlike traditional KD, Self-KD uses different inputs (text vs. audio) for teacher and student, making it a cross-modal distillation technique.
Experimental Results: Self-KD Delivers Significant Gains
The authors tested Self-KD on InternVL2 and Qwen2VL models of varying sizes.
Table: Vision-Audio Performance Before and After Self-KD
| MODEL | SFT ONLY | SELF-KD | IMPROVEMENT |
|---|---|---|---|
| InternVL2-1B | 21.16 | 33.84 | +12.68 |
| InternVL2-2B | 22.52 | 36.58 | +14.06 |
| InternVL2-4B | 32.22 | 42.30 | +10.08 |
| InternVL2-8B | 38.71 | 51.45 | +12.74 |
| Qwen2VL-2B | 46.21 | 52.58 | +6.37 |
| Qwen2VL-7B | 67.75 | 68.27 | +0.52 |
- Average improvement: +9.5 points
- Best gain: +14.06 (InternVL2-2B)
Even on models already strong in vision-audio tasks (like Qwen2VL-7B), Self-KD provides a small but consistent boost.
Why Self-KD Works: Behavioral Alignment
1. Attention Weights Become More Balanced
After Self-KD training, the student model’s attention pattern closely matches the teacher’s:
- Higher attention to vision tokens during audio queries.
- Lower self-attention on query tokens, reducing over-focus on audio input.
This behavioral alignment ensures the model integrates both modalities effectively.
2. Improved Modality Alignment on MMAlign
| MODEL | RELATION (SFT) | RELATION (SELF-KD) | ATTRIBUTE (SFT) | ATTRIBUTE (SELF-KD) |
|---|---|---|---|---|
| InternVL2-1B | 42.67 | 50.67 | 45.33 | 47.33 |
| InternVL2-8B | 53.33 | 57.33 | 54.67 | 56.00 |
| Qwen2VL-7B | 71.00 | 71.33 | 58.33 | 61.67 |
Self-KD improves both relation and attribute understanding, proving it enhances semantic alignment between vision and audio.
Ablation Study: Finding the Optimal KD Ratio
The hyperparameter α (KD loss ratio) was tested across values 0.0 to 1.0.
| KD RATIO (A) | AVG. PERFORMANCE |
|---|---|
| 0.0 (SFT only) | 21.16 |
| 0.25 | 26.62 |
| 0.50 | 29.47 |
| 0.75 | 35.53 |
| 1.0 (KD only) | 33.84 |
✅ Best performance at α = 0.75
➡️ A mix of 75% distillation + 25% direct supervision works best.
Takeaway: Pure distillation (α=1.0) underperforms because the model still needs direct feedback on audio inputs.
Case Study: Real-World Output Comparison
Prompt (Audio): “Describe the color of the dress of the kids.”
- Base Model (Text Query):
“The first child wears a red and white striped sweater, the second a yellow sweater, the third a blue shirt, the fourth a red sweater with a pocket, and the fifth a green and orange striped sweater.” - SFT Model (Audio Query):
“The kids are wearing colorful clothes, mostly sweaters in red, yellow, and blue.” - Self-KD Model (Audio Query):
“One child has a red and white striped sweater, another wears yellow, a third has a blue shirt, one has a red sweater with a pocket, and the last has a multicolored striped sweater.”
🔍 Observation: The Self-KD model’s output is nearly as detailed as the base model, while the SFT model gives only a general summary.
Implications for the Future of Multimodal AI
Self-KD represents a paradigm shift in how we train OLLMs:
- No need for new data — leverages existing vision-text capabilities.
- Improves cross-modal reasoning — aligns behavior across input modalities.
- Scalable and model-agnostic — works across different OLLM architectures.
This approach could be extended to:
- Video-audio integration
- Speech-to-image generation
- Multimodal robotics (e.g., voice-controlled visual navigation)
Limitations and Future Work
While Self-KD is effective, it has two key limitations:
- Higher Training Cost: Requires teacher inference during training.
- Performance Ceiling: Vision-audio performance still lags behind vision-text.
Future research could explore:
- Asymmetric distillation (e.g., image → audio mapping)
- Joint vision-audio pre-training
- Dynamic KD scheduling based on query complexity
Conclusion: Self-KD is a Game-Changer for OLLMs
The paper “Investigating and Enhancing Vision-Audio Capability in Omnimodal Large Language Models” delivers a powerful insight: OLLMs can learn to process audio like text by learning from themselves.
By introducing Self-Knowledge Distillation, the authors provide a simple yet effective method to:
- Reduce the vision-audio performance gap
- Improve attention to visual cues in audio queries
- Enhance modality alignment without new data
As OLLMs move toward true multimodal parity, techniques like Self-KD will be essential for building AI that sees, hears, and understands the world as humans do.
Call to Action: Join the Multimodal AI Revolution
🚀 Want to implement Self-KD in your own OLLM?
👉 Visit our GitHub repo: https://github.com/isruihu/Self-KD
📚 Read the full paper: arXiv:2503.00059v2
💬 Have questions or ideas?
Leave a comment below or connect with us on Twitter @AIResearchBlog. Let’s build the future of multimodal AI — together.
Here is the complete, end-to-end Python code for the Self-Knowledge Distillation (Self-KD) model as proposed in the paper.
# main.py
# -----------------------------------------------------------------------------
# This script provides a complete, end-to-end implementation of the
# Self-Knowledge Distillation (Self-KD) training method for Omnimodal Large
# Language Models (OLLMs), as described in the research paper.
#
# The core idea is to improve the vision-audio capabilities of an OLLM by
# using its stronger vision-text component as a "teacher" to guide the
# training of its vision-audio "student" component.
#
# This implementation includes:
# 1. A mock OLLM architecture.
# 2. The Self-KD loss function using KL divergence.
# 3. A complete training loop demonstrating the proposed method.
# -----------------------------------------------------------------------------
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from transformers import BertModel, BertConfig, WhisperModel, WhisperConfig
# --- 1. Model Architecture ---
# We define a simplified OLLM to demonstrate the Self-KD process.
# In a real-world scenario, these would be pre-trained, state-of-the-art models.
class OLLM(nn.Module):
"""
A simplified Omnimodal Large Language Model (OLLM).
This model includes components for processing vision, audio, and text inputs.
- Vision Encoder: A placeholder for an image processing model (e.g., ViT).
- Audio Encoder: A mock Whisper model to process audio features.
- Text Embedding: Standard text embeddings.
- LLM: A mock BERT model as the core language processing unit.
"""
def __init__(self, num_labels=50):
super(OLLM, self).__init__()
# Vision Encoder (Placeholder)
# In a real implementation, this would be a pre-trained vision transformer.
# For this example, we use a simple linear layer to simulate its output.
self.vision_encoder = nn.Linear(256, 768) # Input feature size 256 -> BERT hidden size 768
# Audio Encoder
# Using a small, randomly initialized Whisper model configuration for demonstration.
whisper_config = WhisperConfig(
vocab_size=51865,
num_mel_bins=80,
encoder_layers=2,
encoder_attention_heads=4,
decoder_layers=2,
decoder_attention_heads=4,
d_model=768,
)
self.audio_encoder = WhisperModel(whisper_config)
# Large Language Model (LLM)
# Using a small, randomly initialized BERT model configuration.
llm_config = BertConfig(
vocab_size=30522,
hidden_size=768,
num_hidden_layers=4,
num_attention_heads=4,
intermediate_size=1024
)
self.llm = BertModel(llm_config)
# Output Classifier
# A linear layer to map the LLM's output to the desired number of labels.
self.classifier = nn.Linear(768, num_labels)
def forward(self, image_input=None, text_input=None, audio_input=None, attention_mask=None):
"""
Forward pass for the OLLM.
It can process either vision-text or vision-audio pairs.
"""
# 1. Process Vision Input
# The image input is always present.
vision_embeds = self.vision_encoder(image_input)
# Add a sequence dimension for concatenation with text/audio embeds.
vision_embeds = vision_embeds.unsqueeze(1)
# 2. Process Text or Audio Input
if text_input is not None:
# Get text embeddings from the LLM's embedding layer.
text_embeds = self.llm.embeddings(input_ids=text_input)
# Combine vision and text embeddings.
combined_embeds = torch.cat((vision_embeds, text_embeds), dim=1)
elif audio_input is not None:
# Get audio embeddings from the audio encoder.
# The Whisper encoder expects a specific input format, which we simulate here.
audio_embeds = self.audio_encoder.encoder(audio_input).last_hidden_state
# Combine vision and audio embeddings.
combined_embeds = torch.cat((vision_embeds, audio_embeds), dim=1)
else:
raise ValueError("Either text_input or audio_input must be provided.")
# 3. Pass through LLM
# The combined embeddings are processed by the core language model.
outputs = self.llm(inputs_embeds=combined_embeds, attention_mask=attention_mask)
# We take the output of the [CLS] token (first token) for classification.
pooled_output = outputs.pooler_output
# 4. Get Final Logits
logits = self.classifier(pooled_output)
return logits
# --- 2. Self-Knowledge Distillation (Self-KD) Loss ---
def self_kd_loss(teacher_logits, student_logits, temperature=2.0):
"""
Calculates the Self-Knowledge Distillation loss.
Args:
teacher_logits: The output logits from the teacher model (vision-text).
student_logits: The output logits from the student model (vision-audio).
temperature: A softening parameter for the probability distributions.
Returns:
The KL divergence loss.
"""
# Soften the probability distributions using the temperature parameter.
soft_teacher_probs = F.softmax(teacher_logits / temperature, dim=-1)
soft_student_log_probs = F.log_softmax(student_logits / temperature, dim=-1)
# Calculate the KL divergence loss.
# The `batchmean` reduction averages the loss over the batch.
loss = F.kl_div(soft_student_log_probs, soft_teacher_probs, reduction='batchmean')
return loss * (temperature ** 2) # Scale the loss as suggested in Hinton's paper.
# --- 3. Training Setup ---
def train(model, data_loader, optimizer, alpha=0.75, num_epochs=5):
"""
The main training loop implementing the Self-KD methodology.
"""
model.train()
sft_criterion = nn.CrossEntropyLoss() # Standard SFT loss
print("--- Starting Training ---")
for epoch in range(num_epochs):
total_sft_loss = 0
total_kd_loss = 0
total_combined_loss = 0
for batch_idx, (image_input, text_input, audio_input, labels) in enumerate(data_loader):
optimizer.zero_grad()
# --- Teacher Forward Pass (Vision-Text) ---
# The teacher component processes the image and text query.
# We detach its output to prevent gradients from flowing back to it.
with torch.no_grad():
teacher_logits = model(image_input=image_input, text_input=text_input)
# --- Student Forward Pass (Vision-Audio) ---
# The student component processes the image and audio query.
student_logits = model(image_input=image_input, audio_input=audio_input)
# --- Loss Calculation ---
# 1. Standard Supervised Fine-Tuning (SFT) Loss
# This is the conventional loss for the vision-audio task.
sft_loss = sft_criterion(student_logits, labels)
# 2. Self-Knowledge Distillation (Self-KD) Loss
# This loss encourages the student to mimic the teacher's output distribution.
kd_loss = self_kd_loss(teacher_logits, student_logits)
# 3. Combined Loss
# The final loss is a weighted sum of the SFT and Self-KD losses.
# The hyperparameter 'alpha' controls the balance between them.
combined_loss = (alpha * kd_loss) + ((1 - alpha) * sft_loss)
# --- Backpropagation ---
combined_loss.backward()
optimizer.step()
total_sft_loss += sft_loss.item()
total_kd_loss += kd_loss.item()
total_combined_loss += combined_loss.item()
# --- Logging ---
avg_sft_loss = total_sft_loss / len(data_loader)
avg_kd_loss = total_kd_loss / len(data_loader)
avg_combined_loss = total_combined_loss / len(data_loader)
print(f"Epoch {epoch+1}/{num_epochs} | "
f"SFT Loss: {avg_sft_loss:.4f} | "
f"KD Loss: {avg_kd_loss:.4f} | "
f"Combined Loss: {avg_combined_loss:.4f}")
print("--- Training Finished ---")
# --- 4. Main Execution Block ---
if __name__ == '__main__':
# --- Hyperparameters ---
BATCH_SIZE = 8
NUM_EPOCHS = 5
LEARNING_RATE = 5e-5
ALPHA = 0.75 # As suggested by the paper for best performance
NUM_LABELS = 50 # Example number of output classes
# --- Model Initialization ---
ollm_model = OLLM(num_labels=NUM_LABELS)
optimizer = optim.Adam(ollm_model.parameters(), lr=LEARNING_RATE)
# --- Dummy Data Generation ---
# Create mock data to simulate the training process.
# In a real application, this data would be loaded from a pre-processed dataset.
num_samples = 128
image_dim = 256
text_seq_len = 10
audio_seq_len = 15
vocab_size = 30522
# Generate random tensors for each modality.
dummy_images = torch.randn(num_samples, image_dim)
dummy_texts = torch.randint(0, vocab_size, (num_samples, text_seq_len))
# For Whisper encoder, input is (batch_size, num_mel_bins, sequence_length)
dummy_audios = torch.randn(num_samples, 80, audio_seq_len)
dummy_labels = torch.randint(0, NUM_LABELS, (num_samples,))
# Create a PyTorch DataLoader.
dataset = TensorDataset(dummy_images, dummy_texts, dummy_audios, dummy_labels)
data_loader = DataLoader(dataset, batch_size=BATCH_SIZE)
# --- Start Training ---
train(ollm_model, data_loader, optimizer, alpha=ALPHA, num_epochs=NUM_EPOCHS)
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
Pingback: Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging - aitrendblend.com