Introduction
In the fast-evolving world of artificial intelligence and deep learning, knowledge distillation (KD) has emerged as a cornerstone technique for model compression. The goal? To transfer knowledge from a high-capacity teacher model to a compact student model while maintaining accuracy and efficiency. However, traditional KD methods often fall short when it comes to fine-grained visual recognition tasks , where subtle differences between visually similar classes are critical.
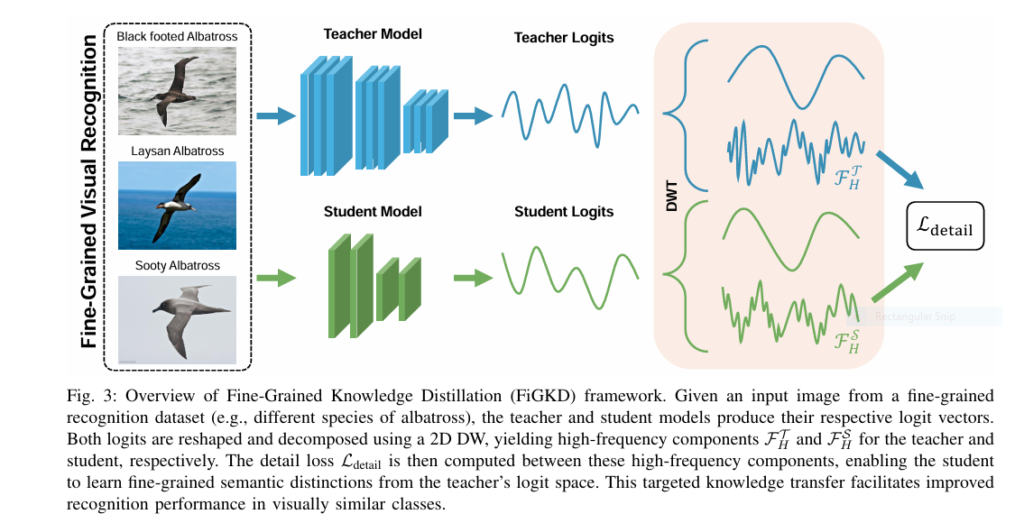
Enter FiGKD — or Fine-Grained Knowledge Distillation via High-Frequency Detail Transfer — a groundbreaking approach that redefines how we think about knowledge transfer. By leveraging the frequency domain , FiGKD selectively transfers only the most informative parts of the teacher’s output logits — specifically, the high-frequency components — while discarding redundant low-frequency content.
This article explores the revolutionary impact of FiGKD on knowledge distillation, its technical underpinnings, performance across multiple benchmarks, and one major drawback that researchers must consider.
What Is Knowledge Distillation (KD)?
Before diving into FiGKD, let’s first understand what knowledge distillation is and why it matters.
The Basics of Knowledge Distillation
Knowledge distillation is a model compression technique where a smaller, more efficient student model learns to mimic the behavior of a larger, high-performing teacher model. This is typically done by aligning the output distributions of both models. The student model benefits from the teacher’s nuanced understanding of class relationships, which goes beyond simple hard labels.
Why Use Knowledge Distillation?
- Efficiency : Student models are smaller, faster, and require less memory.
- Accuracy : Students can achieve near-teacher-level performance.
- Deployment-Friendly : Ideal for edge devices and real-time systems with limited resources.
However, conventional KD methods treat all logit information uniformly, which can lead to suboptimal performance in fine-grained classification tasks.
The Problem with Traditional Logit-Based Distillation
Traditional logit-based KD assumes that all components of the teacher’s output logits are equally valuable to the student. In reality, this is far from true. Logits contain both:
- Low-frequency content : Dominant class scores that represent coarse, general information.
- High-frequency details : Subtle variations that encode fine-grained semantic distinctions between similar classes.
When students try to learn from the full logit vector, they may become overwhelmed by redundant signals , leading to poor generalization and reduced performance on visually similar classes .
Introducing FiGKD: A Frequency-Aware Approach
To overcome these limitations, researchers proposed FiGKD — a novel framework that applies the Discrete Wavelet Transform (DWT) to decompose logits into their frequency components.
How FiGKD Works
- Wavelet Transform : FiGKD uses DWT to separate the teacher’s logits into:
- Low-frequency components (content)
- High-frequency components (details)
- Selective Distillation : Instead of transferring the entire logit vector, FiGKD focuses on transferring only the high-frequency components , which encode the teacher’s nuanced decision boundaries .
- Ground Truth Supervision : The student still learns the overall class identity through standard cross-entropy loss using ground-truth labels.
Key Advantages of FiGKD
- ✅ Architecture-Agnostic : No need to align intermediate feature maps.
- ✅ Lightweight : Only requires access to final output logits.
- ✅ Effective for Fine-Grained Tasks : Captures subtle inter-class variations.
- ✅ Robust Across Architectures : Works well with both homogeneous and heterogeneous teacher-student pairs.
7 Revolutionary Ways FiGKD is Changing the Game
1. Superior Performance on CIFAR-100 and TinyImageNet
Extensive experiments show that FiGKD consistently outperforms state-of-the-art logit-based and feature-based distillation methods across various teacher-student configurations.
| TEACHER STUDENT PAIR | METHOD | ACCURACY (%) |
|---|---|---|
| ResNet32x4 → ResNet8x4 | MLKD | 77.08 |
| ResNet32x4 → ResNet8x4 | FiGKD | 78.05 |
| VGG13 → VGG8 | MLKD | 75.18 |
| VGG13 → VGG8 | FiGKD | 76.17 |
These results demonstrate that selective high-frequency distillation improves accuracy without increasing model complexity.
2. Exceptional Results on Fine-Grained Visual Recognition (FGVR) Benchmarks
FiGKD shines brightest in fine-grained classification tasks , such as bird species identification (CUB-200), indoor scene recognition (MIT67), and dog breed classification (Stanford Dogs).
| DATASET | BASELINE(MLKD) | FIGKD | IMPROVEMENT |
|---|---|---|---|
| CUB-200 | 64.77 | 67.93 | +3.16% |
| MIT67 | 61.89 | 65.67 | +3.78% |
| Stanford Dogs | 71.81 | 72.79 | +0.98% |
These improvements highlight FiGKD’s ability to capture subtle semantic cues that are crucial for distinguishing between visually similar classes.
3. Lightweight and Model-Agnostic Design
Unlike feature-based KD methods, which require tight architectural coupling and intermediate feature alignment , FiGKD operates solely on the final logits .
This makes FiGKD:
- 🚀 Faster to implement
- 💡 Easier to deploy
- 🔐 More secure in privacy-sensitive environments
4. Robustness Across Heterogeneous Architectures
One of the biggest challenges in knowledge distillation is handling heterogeneous teacher-student pairs — for example, ResNet-to-MobileNet or WRN-to-ShuffleNet.
FiGKD excels in these scenarios, achieving significant gains even when the student architecture is vastly different from the teacher’s.
| TEACHER STUDENT PAIR | BASELINE(MLKD) | FIGKD | IMPROVEMENT |
|---|---|---|---|
| WRN-40-2 → ShuffleNet-V1 | 74.43 | 76.21 | +1.78% |
| ResNet50 → MobileNetV2 | 74.93 | 76.21 | +1.28% |
This robustness makes FiGKD ideal for real-world deployment scenarios where flexibility is key.
5. Frequency Domain Insights Improve Semantic Understanding
By analyzing logits in the frequency domain, FiGKD reveals that high-capacity models encode meaningful semantic structure in high-frequency components — something lower-capacity models struggle to capture on their own.
Visualizations show that large models like ResNet32x4 can correctly classify inputs using only high-frequency logits , whereas smaller models like ResNet8x4 fail when deprived of low-frequency content.
This insight reinforces the importance of targeted knowledge transfer and explains why FiGKD works so well.
6. Enhanced Feature Discriminability Through t-SNE Analysis
t-SNE visualizations of student embeddings trained with FiGKD show clearer inter-class separation and tighter intra-class clustering compared to standard KD.
This indicates that FiGKD not only improves classification accuracy but also enhances the semantic quality of learned representations — a major win for downstream tasks like retrieval and clustering.
7. Scalable and Efficient for Resource-Constrained Environments
With the rise of edge computing and IoT devices , there’s a growing need for lightweight yet powerful models.
FiGKD addresses this need by enabling efficient knowledge transfer without sacrificing accuracy. It’s especially beneficial for applications requiring:
- 📱 Mobile deployment
- ⚡ Real-time inference
- 🔋 Low-power consumption
The One Major Drawback of FiGKD
While FiGKD delivers impressive results, it’s not without its limitations .
Drawback: Sensitivity to Hyperparameter Tuning
Although FiGKD performs well out of the box, its performance can vary depending on the choice of loss weights (α and β) used during training. For instance:
- On CIFAR-100 , best performance was achieved with α = 2 and β = 2.
- On TinyImageNet , optimal settings were α = 6 and β = 2.
This sensitivity means that dataset-specific tuning may be required to unlock FiGKD’s full potential — a minor inconvenience for a method that otherwise offers plug-and-play simplicity.
If you’re Interested in deep learning based self-distillation model, you may also find this article helpful: 7 Shocking Truths About Trace-Based Knowledge Distillation That Can Hurt AI Trust
Conclusion: Why FiGKD Matters for the Future of Knowledge Distillation
FiGKD represents a paradigm shift in knowledge distillation by introducing a frequency-aware perspective to logit-based learning. By focusing on high-frequency detail transfer, it enables compact student models to replicate the nuanced decision-making of their teacher counterparts — especially in fine-grained visual recognition tasks .
Its strengths include:
- ✔️ Improved accuracy across multiple datasets
- ✔️ Lightweight and architecture-agnostic design
- ✔️ Strong performance on challenging FGVR benchmarks
- ✔️ Compatibility with resource-constrained environments
And while hyperparameter tuning remains a consideration, the benefits of FiGKD far outweigh this limitation.
Call to Action: Stay Ahead in the AI Revolution
Are you ready to take your deep learning models to the next level?
🚀 Implement FiGKD in your projects today and experience the power of frequency-aware knowledge distillation firsthand.
🔍 Want to dive deeper into the research? Download the full paper here .
💬 Got questions or want to share your thoughts? Leave a comment below or join our community on social media.
Let’s shape the future of AI together — one distilled model at a time!
Frequently Asked Questions (FAQs)
Q1: What is FiGKD?
A1: FiGKD stands for Fine-Grained Knowledge Distillation via High-Frequency Detail Transfer . It’s a novel knowledge distillation framework that improves fine-grained classification by transferring only the high-frequency components of the teacher’s output logits.
Q2: How does FiGKD differ from traditional KD methods?
A2: Unlike traditional methods that treat all logit components equally, FiGKD uses wavelet transform to isolate and transfer only the high-frequency details — the parts that encode subtle class distinctions.
Q3: Can FiGKD work with different architectures?
A3: Yes! FiGKD is architecture-agnostic , meaning it works well with both homogeneous (e.g., ResNet-to-ResNet) and heterogeneous (e.g., ResNet-to-MobileNet) teacher-student pairs.
Q4: Is FiGKD suitable for edge devices?
A4: Absolutely. Since FiGKD only requires access to the final logits , it’s highly efficient and ideal for resource-constrained environments like mobile and embedded systems.
Q5: Where can I find the source code for FiGKD?
A5: You can find the implementation details and codebase in the original paper: arXiv:2505.11897v1 .
Final Thoughts
As AI continues to push the boundaries of what’s possible, techniques like FiGKD will play a pivotal role in making advanced models accessible, scalable, and efficient.
Whether you’re building vision systems for autonomous vehicles, developing smart cameras, or optimizing models for mobile apps, FiGKD offers a powerful solution for improving accuracy without compromising efficiency.
So don’t just compress your models — distill them intelligently with FiGKD.
Here’s the PyTorch implementation of FiGKD (Fine-Grained Knowledge Distillation) framework:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class HaarDWT2d(nn.Module):
"""2D Haar Discrete Wavelet Transform"""
def __init__(self):
super().__init__()
# Define Haar wavelet filters
ll = torch.tensor([[1, 1], [1, 1]], dtype=torch.float32) * 0.5
lh = torch.tensor([[-1, -1], [1, 1]], dtype=torch.float32) * 0.5
hl = torch.tensor([[-1, 1], [-1, 1]], dtype=torch.float32) * 0.5
hh = torch.tensor([[1, -1], [-1, 1]], dtype=torch.float32) * 0.5
self.register_buffer('kernel_ll', ll.view(1, 1, 2, 2))
self.register_buffer('kernel_lh', lh.view(1, 1, 2, 2))
self.register_buffer('kernel_hl', hl.view(1, 1, 2, 2))
self.register_buffer('kernel_hh', hh.view(1, 1, 2, 2))
def forward(self, x):
"""Input: (B, 1, H, W) Output: (LL, (LH, HL, HH))"""
LL = F.conv2d(x, self.kernel_ll, stride=2)
LH = F.conv2d(x, self.kernel_lh, stride=2)
HL = F.conv2d(x, self.kernel_hl, stride=2)
HH = F.conv2d(x, self.kernel_hh, stride=2)
return LL, (LH, HL, HH)
def get_HW(num_classes):
"""Calculate optimal H and W dimensions for reshaping logits"""
H = int(math.isqrt(num_classes))
while num_classes % H != 0:
H -= 1
W = num_classes // H
return H, W
class FiGKDLoss(nn.Module):
"""FiGKD Loss Function"""
def __init__(self, num_classes, alpha=2.0, beta=2.0):
super().__init__()
self.alpha = alpha
self.beta = beta
self.H, self.W = get_HW(num_classes)
self.dwt = HaarDWT2d()
self.ce_loss = nn.CrossEntropyLoss()
def get_high_freq(self, logits):
"""Extract high-frequency components from logits"""
# Reshape logits to (B, 1, H, W)
logits_2d = logits.view(-1, 1, self.H, self.W)
# Apply DWT and return only high-frequency components
_, (LH, HL, HH) = self.dwt(logits_2d)
return LH, HL, HH
def forward(self, student_logits, teacher_logits, labels):
# Standard cross-entropy loss
ce_loss = self.ce_loss(student_logits, labels)
# Get high-frequency components
LH_s, HL_s, HH_s = self.get_high_freq(student_logits)
with torch.no_grad():
LH_t, HL_t, HH_t = self.get_high_freq(teacher_logits)
# Detail loss (L1 norm on high-frequency components)
detail_loss = (torch.abs(LH_s - LH_t).mean() +
torch.abs(HL_s - HL_t).mean() +
torch.abs(HH_s - HH_t).mean())
# Combined loss
total_loss = self.alpha * ce_loss + self.beta * detail_loss
return total_loss, ce_loss, detail_loss
# Example usage:
if __name__ == "__main__":
# Hyperparameters
num_classes = 100 # CIFAR-100
alpha = 2.0 # CIFAR-100 weight for CE loss
beta = 2.0 # CIFAR-100 weight for detail loss
batch_size = 32
# Initialize loss function
loss_fn = FiGKDLoss(num_classes, alpha, beta)
# Dummy inputs (replace with real model outputs)
teacher_logits = torch.randn(batch_size, num_classes)
student_logits = torch.randn(batch_size, num_classes)
labels = torch.randint(0, num_classes, (batch_size,))
# Compute loss
total_loss, ce_loss, detail_loss = loss_fn(
student_logits, teacher_logits, labels
)
print(f"Total Loss: {total_loss.item():.4f}")
print(f"CE Loss: {ce_loss.item():.4f}")
print(f"Detail Loss: {detail_loss.item():.4f}")