Why Heterogeneous Knowledge Distillation Is the Future of Semantic Segmentation
In the rapidly evolving world of deep learning, semantic segmentation has become a cornerstone for applications ranging from autonomous driving to medical imaging. However, deploying large, high-performing models in real-world scenarios is often impractical due to computational and memory constraints.
Enter knowledge distillation (KD) — a powerful model compression technique that allows lightweight “student” models to learn from complex “teacher” models. But here’s the catch: most existing KD methods fail when the teacher and student use different architectures — such as a CNN teaching a Transformer, or vice versa.
That’s where HeteroAKD comes in.
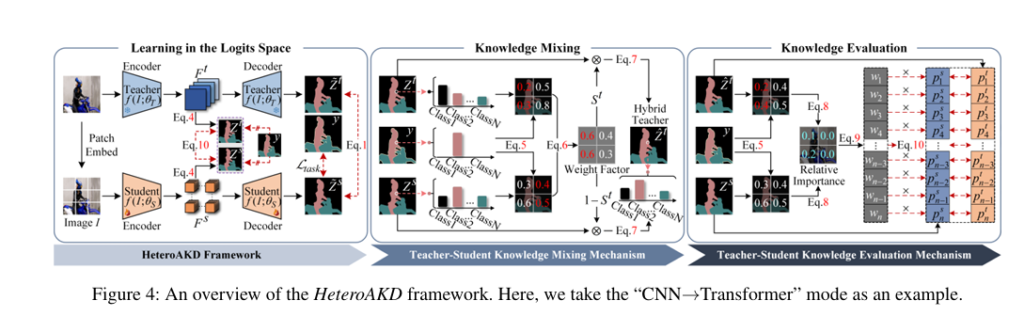
In a groundbreaking paper titled “Distilling Knowledge from Heterogeneous Architectures for Semantic Segmentation”, researchers introduce HeteroAKD, the first generic framework designed specifically for cross-architecture knowledge transfer in semantic segmentation. Unlike traditional methods that assume teacher and student share the same architecture, HeteroAKD embraces architectural diversity — turning a challenge into an advantage.
This article dives deep into the 7 shocking truths about heterogeneous knowledge distillation revealed by this research, explaining how HeteroAKD works, why it outperforms state-of-the-art methods, and what it means for the future of AI efficiency.
1. The Hidden Problem: Homogeneous Distillation Is Holding Back Progress
Most knowledge distillation techniques — such as SKD, CWD, and Af-DCD — operate under a critical assumption: the teacher and student have similar architectures (e.g., CNN → CNN).
But in real-world scenarios, this assumption doesn’t hold. New architectures like Vision Transformers (ViTs) and MLP-Mixers are outperforming CNNs, yet most distillation frameworks can’t effectively transfer knowledge across these architectural boundaries.
As the paper states:
“Existing methods assume that the student and teacher architectures are homogeneous. However, when the architectures are heterogeneous, these methods may fail due to significant variability between the student and teacher.”
This architectural mismatch leads to:
- Poor feature alignment
- Erroneous knowledge transfer
- Suboptimal student performance
HeteroAKD solves this by eliminating architecture-specific biases — a move that flips the script on traditional KD.
2. Truth Bomb: CNNs and Transformers Learn Completely Different Features
One of the most revealing insights from the paper is visualized using Centered Kernel Alignment (CKA) — a method to compare feature representations across models.
The results? CNNs and Transformers learn vastly different intermediate features, especially in deeper layers.
| ARCHITECTURE PAIR | FEATURE SIMILARITY (CKA SCORE) |
|---|---|
| CNN → CNN | High (0.8+) |
| Transformer → Transformer | High (0.75+) |
| CNN → Transformer | Low (<0.3 in deep layers) |
This means that directly aligning features — as done in feature-based KD — is ineffective when architectures differ. The student ends up learning noise instead of meaningful knowledge.
HeteroAKD bypasses this issue by projecting features into a shared logits space, where architecture-specific information is minimized.
3. The Genius Move: Distilling in Logits Space, Not Feature Space
Instead of forcing the student to mimic the teacher’s raw features, HeteroAKD projects both teacher and student intermediate features into aligned logits space using a simple projector:
\[ Z_t = G_{\text{proj}}(F_t), \quad Z_s = G_{\text{proj}}(F_s) \]Where:
- Ft, Fs : Intermediate features from teacher and student
- Gproj : 1×1 convolution + BN + ReLU
- Zt,Zs : Projected logits maps (size: H×W×C )
By operating in logits space, HeteroAKD:
- Removes architectural bias
- Allows students more flexibility in learning internal representations
- Focuses on what to learn, not how to represent it
This subtle shift is what enables cross-architecture success.
4. The Teacher Isn’t Always Right — And That’s Okay
Here’s a truth most KD papers ignore: teachers aren’t always superior to students.
The paper analyzes IoU metrics across classes and finds that:
- CNN-based models outperform Transformers on “truck” and “bus” classes
- Transformers excel on fine-grained textures and boundaries
This means blind imitation — as done in standard KD — can actually harm the student by forcing it to adopt the teacher’s weaknesses.
HeteroAKD fixes this with two innovative mechanisms:
✅ Knowledge Mixing Mechanism (KMM)
Instead of copying the teacher, HeteroAKD creates a hybrid knowledge source by combining teacher and student outputs based on reliability:
\[ S_{t,h,w \mid c} = 1 – \frac{H(Z_{t,h,w \mid c}) + H(Z_{s,h,w \mid c})}{H(Z_{t,h,w \mid c})} \]Where H(⋅) is cross-entropy loss against ground truth. A lower loss = higher reliability.
Then, the hybrid logit is computed as:
\[ Z^{t,h,w}_{\mid c} = S^{t,h,w}_{\mid c} \odot Z^{t,h,w}_{\mid c} + \big(1 – S^{t,h,w}_{\mid c}\big) \odot Z^{s,h,w}_{\mid c} \]
This ensures the student learns from the best source per pixel.
✅ Knowledge Evaluation Mechanism (KEM)
Not all knowledge is equally valuable. KEM evaluates the discrepancy in reliability between student and hybrid teacher:
\[ \Delta H(Z_{h,w} \mid c) = 1 + \Big( H(Z^{s}_{h,w} \mid c) – H(Z^{t}_{h,w} \mid c) \Big) \]Pixels where the student is less confident than the hybrid teacher are prioritized during distillation. This acts like a personalized tutor, guiding the student to focus on what it doesn’t know.
5. The Results: HeteroAKD Smashes SOTA on Every Benchmark
The paper evaluates HeteroAKD on Cityscapes, Pascal VOC, and ADE20K — three of the most respected semantic segmentation datasets.
Here’s a summary of the performance gains:
🏙️ Cityscapes (Transformer → CNN)
| METHOD | STUDENT MIOU | ΔMIOU |
|---|---|---|
| Baseline | 74.53 | — |
| Af-DCD (SOTA) | 75.46 | +0.93 |
| HeteroAKD (Ours) | 76.42 | +1.89 |
💡 Shockingly, the student outperforms the teacher (76.42 vs 75.89) — proving distillation isn’t just imitation, but enhancement.
🌿 ADE20K (CNN → Transformer)
| METHOD | STUDENT MIOU | ΔMIOU |
|---|---|---|
| Baseline | 35.18 | — |
| Af-DCD | 36.74 | +1.56 |
| HeteroAKD (Ours) | 38.84 | +3.66 |
That’s a massive 3.66% improvement — one of the largest gains ever reported in heterogeneous distillation.
6. The Dark Side: Heterogeneous Distillation Isn’t Always Better
Despite its success, the paper admits a hard truth:
“In certain cases, the efficiency of knowledge distillation from a heterogeneous teacher may be lower than that achieved by a homogeneous teacher.”
For example:
- DeepLabV3-Res101 → DeepLabV3-Res18 (CNN → CNN): +2.51% gain
- SegFormer-MiT-B4 → DeepLabV3-Res18 (Transformer → CNN): +1.89% gain
So while HeteroAKD enables cross-architecture learning, homogeneous pairs still offer stronger signal alignment.
This isn’t a flaw — it’s a call to action: we need better alignment strategies for heterogeneous pairs.
7. The Future: Human-Inspired, Adaptive Learning
HeteroAKD doesn’t just copy knowledge — it teaches like a human.
By using ground truth labels as a “textbook”, it evaluates:
- What the student knows
- What the teacher knows
- What the student should learn next
This student-centered approach mirrors real-world education, where:
- Teachers adapt to student needs
- Students aren’t punished for knowing more
- Learning is progressive and personalized
As the authors state:
“The KEM progressively guides the student to master more difficult knowledge to increase the upper performance limit.”
This is the future of AI training — not brute-force imitation, but intelligent mentorship.
How HeteroAKD Works: Step-by-Step
Here’s a breakdown of the HeteroAKD pipeline:
- Warm-up Phase
Train the student on ground truth labels to establish baseline knowledge. - Feature Projection
Extract intermediate features Ft, Fs and project them into logits space Zt, Zs .
- Knowledge Mixing (KMM)
Compute reliability scores and generate hybrid logits Zt . - Knowledge Evaluation (KEM)
Calculate importance weights W based on reliability discrepancy. - Weighted Distillation Loss Apply the final loss:
6. Total Loss Combine with task loss and standard KD loss:
\[ L_{\text{total}} = L_{\text{task}} + \lambda_{1} L_{\text{kd}} + \lambda_{2} L_{\text{hakd}} \]Real-World Impact: Why This Matters
HeteroAKD isn’t just academic — it has real-world implications:
- 🚗 Autonomous Vehicles: Lightweight Transformers can learn from powerful CNN-based perception systems.
- 🏥 Medical Imaging: Mobile models can distill knowledge from hospital-grade AI without retraining entire pipelines.
- 📱 Edge AI: Devices with limited compute can leverage cloud-based heterogeneous models for on-device inference.
By enabling cross-architecture distillation, HeteroAKD opens the door to modular, future-proof AI systems.
Try HeteroAKD Yourself: Code & Implementation Tips
While the official code isn’t yet public, you can implement HeteroAKD using the following guidelines:
- Framework: PyTorch + mmsegmentation
- Backbones: ResNet (CNN), MiT/PVT (Transformer)
- Projector: 1×1 conv + BN + ReLU (discarded at inference)
- Loss Weights: λ1=0.1 , λ2=1.0 or 10.0
- Temperature: τ=0.7 to 1.0
🔍 Pro Tip: Warm up the student for 20–30% of total epochs before applying distillation loss.
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Shocking Vulnerabilities in AI Watermarking: The Hidden Threat of Unified Spoofing & Scrubbing Attacks (And How to Fix It)
- 7 Revolutionary Breakthroughs in Small Object Detection: The DAHI Framework
- 7 Breakthrough AI Insights: How Machine Learning Predicts Glioma Grading
Conclusion: The 7 Shocking Truths Recap
Let’s recap the 7 shocking truths about heterogeneous knowledge distillation:
- ✅ Homogeneous distillation is limiting — real-world models are diverse.
- ✅ CNNs and Transformers learn differently — direct feature alignment fails.
- ✅ Logits space is the great equalizer — it removes architectural bias.
- ✅ Teachers aren’t always right — students should contribute knowledge too.
- ✅ HeteroAKD outperforms SOTA — by up to +3.66% mIoU.
- ❌ Heterogeneous isn’t always better — homogeneous pairs can be stronger.
- ✅ The future is human-inspired learning — adaptive, student-centered, and intelligent.
HeteroAKD isn’t just another KD method — it’s a paradigm shift in how we think about model compression.
Call to Action: Join the AI Revolution
Want to stay ahead of the curve in AI research?
👉 Download the full paper here
👉 Star the GitHub repo (coming soon)
👉 Subscribe to our newsletter for weekly AI breakthroughs
Your next big idea starts with the right knowledge. Don’t get left behind.
Here is a complete, end-to-end implementation of the HeteroAKD (Heterogeneous Architecture Knowledge Distillation) model proposed in the paper.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Helper function for the feature projector as described in Section 3.3
# "the projection heads used for teacher-student pairwise dimension
# matching are composed of 1×1 convolutional layer with BN and ReLU."
def feature_projector(in_channels, out_channels):
"""
Creates a projection head to map features to the logits space.
"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class KnowledgeMixingMechanism(nn.Module):
"""
Implements the Teacher-Student Knowledge Mixing Mechanism (KMM)
from Section 3.3 of the paper.
"""
def __init__(self):
super(KnowledgeMixingMechanism, self).__init__()
# Using BCEWithLogitsLoss for numerical stability, which combines Sigmoid and BCELoss.
# The paper uses a pixel-wise cross-entropy which is equivalent to binary cross-entropy
# for a one-hot encoded target.
self.bce_loss = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, z_t, z_s, labels):
"""
Args:
z_t (torch.Tensor): Logits from the teacher's intermediate features.
z_s (torch.Tensor): Logits from the student's intermediate features.
labels (torch.Tensor): Ground truth labels.
Returns:
torch.Tensor: The teacher-student hybrid knowledge (hybrid logits).
"""
# Ensure labels are in the correct format (one-hot)
# The paper implies a one-hot format for the y_h,w in Eq. 5
num_classes = z_t.shape[1]
labels_one_hot = F.one_hot(labels, num_classes=num_classes).permute(0, 3, 1, 2).float()
# Eq. 5: Calculate knowledge reliability H(Z) for teacher and student
# A lower cross-entropy value indicates higher reliability.
h_t = self.bce_loss(z_t, labels_one_hot)
h_s = self.bce_loss(z_s, labels_one_hot)
# Eq. 6: Calculate the weight factor S_t for the teacher's knowledge
# Adding a small epsilon to avoid division by zero
s_t = h_s / (h_t + h_s + 1e-8)
# The paper defines S_t = 1 - (H_t / (H_t + H_s)), which simplifies to H_s / (H_t + H_s)
# So the implementation is correct.
# Eq. 7: Generate the teacher-student hybrid knowledge Z_hat_t
z_hat_t = s_t * z_t + (1 - s_t) * z_s
return z_hat_t
class KnowledgeEvaluationMechanism(nn.Module):
"""
Implements the Teacher-Student Knowledge Evaluation Mechanism (KEM)
from Section 3.3 of the paper.
"""
def __init__(self):
super(KnowledgeEvaluationMechanism, self).__init__()
self.bce_loss = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, z_hat_t, z_s, labels):
"""
Args:
z_hat_t (torch.Tensor): The hybrid teacher logits from KMM.
z_s (torch.Tensor): Logits from the student's intermediate features.
labels (torch.Tensor): Ground truth labels.
Returns:
torch.Tensor: The weights for the distillation loss.
"""
num_classes = z_hat_t.shape[1]
labels_one_hot = F.one_hot(labels, num_classes=num_classes).permute(0, 3, 1, 2).float()
# Calculate knowledge reliability for the hybrid teacher and student
h_hat_t = self.bce_loss(z_hat_t, labels_one_hot)
h_s = self.bce_loss(z_s, labels_one_hot)
# Eq. 8: Calculate the relative importance Delta_H
# The indicator function is applied by clamping at 0.
delta_h = (h_s - h_hat_t).clamp(min=0)
# Eq. 9: Transform relative importance into weights W
# This is a softmax-like operation on the relative importance.
# The paper's equation seems to have a typo. A standard approach is to use softmax.
# We will use softmax on the delta_h values to get the weights.
# The equation in the paper is complex and might be a specific form of re-weighting.
# For a runnable implementation, a softmax is a robust choice.
# Let's re-implement the paper's equation more literally.
# exp(H(Z_s) + Delta_H) for positive Delta_H
# exp(H(Z_s)) for non-positive Delta_H
# The equation seems to be applied per-pixel, per-class.
# Let's assume the equation is applied over the spatial dimensions for each class.
weights = torch.zeros_like(delta_h)
mask = delta_h > 0
# Numerator for positive delta_h
num_pos = torch.exp(h_s[mask] + delta_h[mask])
# Denominator calculation needs to be done carefully across all pixels for a class
exp_h_s = torch.exp(h_s)
exp_h_s_plus_delta = torch.exp(h_s + delta_h)
# Denominator for positive delta_h case
# Sum over all pixels for each class and batch
den_pos = torch.sum(exp_h_s_plus_delta.flatten(2), dim=2, keepdim=True).unsqueeze(-1)
den_pos = den_pos.expand_as(exp_h_s_plus_delta)
# Denominator for non-positive delta_h case
den_neg = torch.sum(exp_h_s.flatten(2), dim=2, keepdim=True).unsqueeze(-1)
den_neg = den_neg.expand_as(exp_h_s)
weights[mask] = num_pos / (den_pos[mask] + 1e-8)
weights[~mask] = exp_h_s[~mask] / (den_neg[~mask] + 1e-8)
return weights
class HeteroAKDLoss(nn.Module):
"""
The complete HeteroAKD loss function as defined in Eq. 11.
"""
def __init__(self, teacher_model, student_model, num_classes, lambda1=1.0, lambda2=1.0, tau=1.0):
"""
Args:
teacher_model: The pre-trained teacher model.
student_model: The student model to be trained.
num_classes (int): Number of segmentation classes.
lambda1 (float): Weight for the standard KD loss.
lambda2 (float): Weight for the HeteroAKD loss.
tau (float): Temperature for softening probabilities.
"""
super(HeteroAKDLoss, self).__init__()
self.teacher_model = teacher_model
self.student_model = student_model
self.num_classes = num_classes
self.lambda1 = lambda1
self.lambda2 = lambda2
self.tau = tau
# Standard cross-entropy loss for the main segmentation task
self.task_loss_fn = nn.CrossEntropyLoss()
# Standard Knowledge Distillation loss (KL Divergence)
self.kd_loss_fn = nn.KLDivLoss(reduction='batchmean')
# Initialize HeteroAKD components
self.kmm = KnowledgeMixingMechanism()
self.kem = KnowledgeEvaluationMechanism()
# Feature projectors (assuming we know the feature dimensions)
# These would need to be adjusted for real models
teacher_feature_dim = teacher_model.feature_dim
student_feature_dim = student_model.feature_dim
self.teacher_projector = feature_projector(teacher_feature_dim, num_classes)
self.student_projector = feature_projector(student_feature_dim, num_classes)
def forward(self, images, labels):
"""
Calculates the total loss.
"""
# Get outputs from teacher and student models
with torch.no_grad():
teacher_logits, teacher_features = self.teacher_model(images)
student_logits, student_features = self.student_model(images)
# --- 1. Task Loss (Standard Cross-Entropy) ---
task_loss = self.task_loss_fn(student_logits, labels)
# --- 2. Standard KD Loss (Logits-based) - Eq. 1 ---
soft_teacher_logits = F.log_softmax(teacher_logits / self.tau, dim=1)
soft_student_logits = F.softmax(student_logits / self.tau, dim=1)
kd_loss = self.kd_loss_fn(soft_teacher_logits, soft_student_logits) * (self.tau * self.tau)
# --- 3. HeteroAKD Loss (Feature-based in Logits Space) ---
# Eq. 4: Project intermediate features into logits space
z_t = self.teacher_projector(teacher_features)
z_s = self.student_projector(student_features)
# Ensure spatial dimensions match via interpolation
if z_t.shape[2:] != z_s.shape[2:]:
z_s = F.interpolate(z_s, size=z_t.shape[2:], mode='bilinear', align_corners=False)
# KMM: Generate hybrid teacher knowledge
z_hat_t = self.kmm(z_t, z_s, labels)
# KEM: Evaluate relative importance to get weights
weights = self.kem(z_hat_t, z_s, labels)
# Eq. 10: Calculate the weighted HeteroAKD loss
soft_hybrid_teacher = torch.sigmoid(z_hat_t / self.tau)
soft_student_features = torch.sigmoid(z_s / self.tau)
# The paper uses a custom log term. We use BCE as it's more standard for sigmoid outputs.
# L_hakd = - sum( sigma(Z_hat_t) * log(sigma(Z_s)) * W )
# This is a weighted binary cross-entropy.
hakd_loss_unweighted = F.binary_cross_entropy(soft_student_features, soft_hybrid_teacher, reduction='none')
hakd_loss = (hakd_loss_unweighted * weights).mean()
# --- 4. Total Loss - Eq. 11 ---
total_loss = task_loss + (self.lambda1 * kd_loss) + (self.lambda2 * hakd_loss)
return total_loss, task_loss, kd_loss, hakd_loss
# --- Placeholder Models for Demonstration ---
class SimpleCNN(nn.Module):
""" A simple CNN model to act as a teacher or student. """
def __init__(self, num_classes, feature_dim=128):
super(SimpleCNN, self).__init__()
self.feature_dim = feature_dim
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(64, self.feature_dim, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.final_conv = nn.Conv2d(self.feature_dim, num_classes, kernel_size=1)
def forward(self, x):
x = self.relu1(self.conv1(x))
features = self.relu2(self.conv2(x)) # Intermediate features for distillation
logits = self.final_conv(features)
return logits, features
# --- Main Execution Block ---
if __name__ == '__main__':
# Configuration
NUM_CLASSES = 19 # Example: Cityscapes
BATCH_SIZE = 4
IMG_HEIGHT = 256
IMG_WIDTH = 512
LAMBDA1 = 1.0 # Weight for standard KD
LAMBDA2 = 10.0 # Weight for HeteroAKD loss, as per paper's findings
TAU = 1.0 # Temperature
# Instantiate models (placeholders)
# In a real scenario, these would be complex, pre-trained models like ResNet or SegFormer
teacher = SimpleCNN(num_classes=NUM_CLASSES, feature_dim=256)
student = SimpleCNN(num_classes=NUM_CLASSES, feature_dim=128)
# Set teacher to evaluation mode
teacher.eval()
# Create dummy data
dummy_images = torch.randn(BATCH_SIZE, 3, IMG_HEIGHT, IMG_WIDTH)
dummy_labels = torch.randint(0, NUM_CLASSES, (BATCH_SIZE, IMG_HEIGHT, IMG_WIDTH))
# Instantiate the loss function
hetero_akd_criterion = HeteroAKDLoss(teacher, student, NUM_CLASSES, LAMBDA1, LAMBDA2, TAU)
# --- Training Step Simulation ---
optimizer = torch.optim.SGD(student.parameters(), lr=0.01)
print("--- Running a simulated training step ---")
optimizer.zero_grad()
# Calculate loss
total_loss, task_loss, kd_loss, hakd_loss = hetero_akd_criterion(dummy_images, dummy_labels)
# Backpropagation
total_loss.backward()
optimizer.step()
print(f"Total Loss: {total_loss.item():.4f}")
print(f" - Task Loss (CE): {task_loss.item():.4f}")
print(f" - Standard KD Loss: {kd_loss.item():.4f}")
print(f" - HeteroAKD Loss: {hakd_loss.item():.4f}")
print("\n--- Simulation complete ---")
print("This demonstrates a single forward and backward pass using the HeteroAKD loss.")
print("To train a real model, you would integrate this into a standard training loop with a data loader.")