RoofSeg: A Breakthrough in End-to-End Roof Plane Segmentation Using Transformers
In the rapidly evolving field of 3D urban modeling and geospatial analysis, roof plane segmentation plays a pivotal role in reconstructing detailed building models at Levels of Detail (LoD) 2 and 3. Traditionally, this process has relied on manual feature engineering or post-processing techniques like region growing and RANSAC, which often lead to suboptimal results due to error accumulation and parameter sensitivity.
Enter RoofSeg — a novel, end-to-end edge-aware transformer-based network developed by researchers from Wuhan University and Wuhan University of Technology. This groundbreaking approach, detailed in their paper “RoofSeg: An edge-aware transformer-based network for end-to-end roof plane segmentation”, redefines the state-of-the-art in airborne LiDAR point cloud analysis by delivering highly accurate, geometrically faithful roof segmentations without the need for intermediate clustering or refinement steps.
In this article, we’ll explore how RoofSeg works, its key innovations, performance benchmarks, and why it represents a significant leap forward for applications in urban planning, disaster response, and smart city development.
Why Roof Plane Segmentation Matters
Before diving into RoofSeg, it’s important to understand the significance of roof plane segmentation. Airborne LiDAR systems capture dense 3D point clouds of urban environments, which serve as the foundation for digital twin creation, flood risk assessment, solar potential mapping, and more.
However, raw point clouds are unstructured and lack semantic meaning. To make them useful, we must segment them into meaningful parts — especially roof planes, which are flat, geometrically coherent surfaces that define a building’s structure.
Accurate segmentation enables:
- High-fidelity 3D building reconstruction
- Automated roof inspection and solar panel placement
- Urban heat island analysis
- Damage assessment after natural disasters
Despite its importance, automatic roof plane segmentation remains challenging due to complex roof geometries, noise in LiDAR data, and ambiguous boundaries between adjacent planes.
Limitations of Traditional and Deep Learning Approaches
Existing methods fall into two categories:
1. Traditional Methods (Handcrafted Features)
- Region Growing: Starts with seed points and expands based on similarity criteria.
- RANSAC: Iteratively fits planes by sampling random point subsets.
- Clustering (e.g., DBSCAN): Groups points based on spatial proximity.
Drawbacks:
- Sensitive to parameter tuning
- Prone to over- or under-segmentation
- Struggle with edge regions and complex roof types
2. Deep Learning-Based Methods
Recent approaches use deep neural networks to learn point features automatically. Examples include:
- PointGroup
- Mask3D
- DeepRoofPlane
While these outperform traditional methods, they still face three critical issues:
- ❌ Not truly end-to-end — rely on post-processing (e.g., clustering, edge refinement)
- ❌ Poor edge discrimination — struggle to segment sharp boundaries accurately
- ❌ Lack of geometric constraints — do not enforce planarity during training
These limitations result in misclassified points, jagged edges, and low geometric fidelity — all of which degrade downstream applications.
Introducing RoofSeg: The First Truly End-to-End Solution
RoofSeg addresses these challenges head-on with a transformer-based architecture that performs end-to-end roof plane instance segmentation directly from raw LiDAR point clouds.
✅ Key Features of RoofSeg:
- No post-processing or clustering required
- Edge-aware mask refinement for sharp boundaries
- Geometrically constrained loss functions
- High accuracy across diverse roof types
The model leverages a query-based transformer decoder to predict plane instance masks, inspired by success in 2D vision models like Mask2Former and 3D models like Mask3D.
How RoofSeg Works: Architecture Overview
The RoofSeg pipeline consists of four main components:
- Point Feature Extraction
- Plane Query Generation & Refinement
- Edge-Aware Mask Generation
- Loss Functions with Geometric Constraints
Let’s break each down.
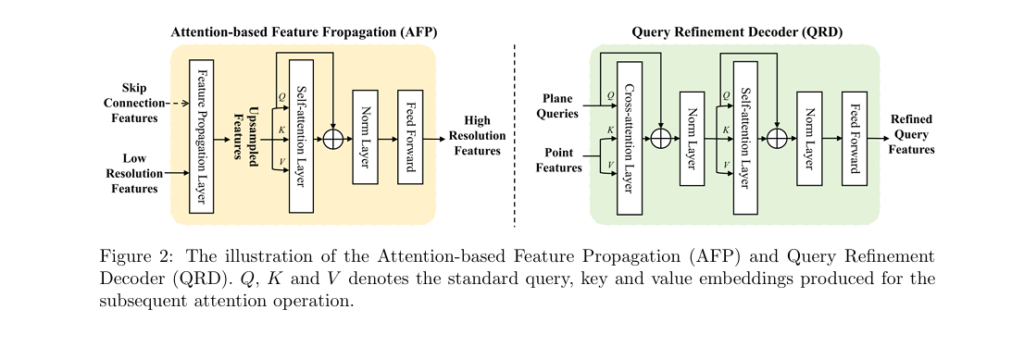
1. Point Feature Extraction Using PointNet++
RoofSeg uses PointNet++ as its backbone to extract multi-scale features from raw point clouds. It enhances the standard Feature Propagation (FP) layers with attention mechanisms, enabling robust feature learning across different resolutions.
\[ \text{Input: } \; \text{Raw 3D point cloud } P = \{ p_i \}_{i=1}^{N} \] \[ \text{Output: } \; \text{Multi-scale features } F_{\text{multi}} = \{ F^{l} \in \mathbb{R}^{\left(\tfrac{N}{4^{\,l-1}}\right)\times 256} \}_{l=1}^{4} \]This hierarchical design captures both local details and global context.
2. Plane Query Generation and Refinement
Inspired by DETR-style transformers, RoofSeg introduces learnable plane queries — fixed-size vectors that represent potential roof planes.
- Query Initialization: K query points are sampled using Farthest Point Sampling (FPS)
- Fourier Encoding: Spatial coordinates are encoded using Fourier features for better generalization on unstructured data
- Query Refinement Decoders (QRD): Four transformer decoder layers refine the queries by fusing them with multi-scale point features via cross-attention
The cross-attention mechanism computes:
\[ Q_{\text{att}} = \text{softmax}\!\left(\frac{D Q K^{T}}{\sqrt{d_k}}\right) V \]Where:
- Q : Query embeddings
- K,V : Key and value from point features
- D=256 : Feature dimension
Self-attention among queries suppresses duplicates, ensuring one query per plane.
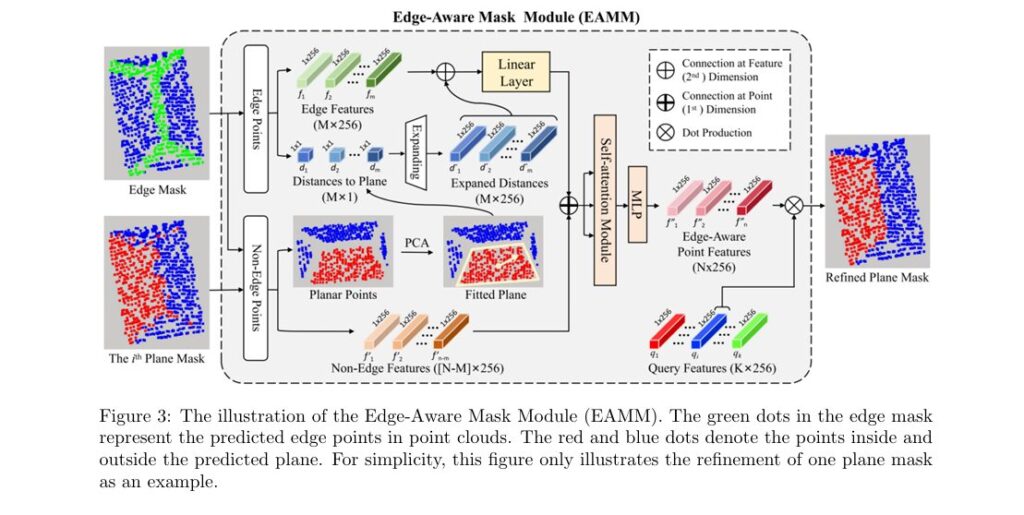
3. Edge-Aware Mask Module (EAMM)
This is where RoofSeg shines. Most models fail at edge regions, where points belong to multiple planes. RoofSeg introduces the Edge-Aware Mask Module (EAMM) to refine masks using geometric priors.
Steps in EAMM:
- Predict an edge mask using a dedicated branch
- Extract edge points and compute their tangent distance to the fitted plane using PCA
- Fuse distance features with point features
- Apply self-attention to enhance edge discriminability
- Generate refined plane masks
By incorporating point-to-plane distance as a geometric cue, EAMM significantly improves edge accuracy.
4. Novel Loss Functions for Robust Training
RoofSeg introduces two innovative loss components:
🔹 Adaptive Weighting Mask Loss (Lwmask )
Standard mask loss treats all points equally. RoofSeg detects outliers — points whose label differs from most neighbors — and assigns them higher weights:
\[ w_j = \begin{cases} \dfrac{(N_{\text{out}}\,N – N_{\text{out}})\,N_{\text{nbr}}}{N_{\text{dif}}^j}, & \text{if } p_j \in \text{outliers}, \\[10pt] 1, & \text{otherwise}. \end{cases} \]Then applies weighted BCE and Dice losses:
\[ L_{\text{wBCE}} = -\frac{1}{N} \sum_{j=1}^{N} w_j \Big[ l^{\text{gt}}_j \log(a_j) + (1 – l^{\text{gt}}_j)\log(1 – a_j) \Big] \] \[ L_{\text{wDice}} = 1 – \frac{2 \sum_j w_j a_j l^{\text{gt}}_j + \epsilon} {\sum_j w_j a_j + \sum_j w_j l^{\text{gt}}_j + \epsilon}, \quad \epsilon = 1 \]This reduces the impact of misclassified points.
🔹 Plane Geometric Loss (Lplane )
To enforce planarity, RoofSeg adds a geometric loss based on point-to-plane distance:
\[ L_{\text{plane}} = \frac{1}{|P|} \sum_{p_j \in P} \text{Dist}(p_j, \Pi) \]Where Π is the plane fitted via PCA on inlier points. This ensures high geometric fidelity.
The total loss is:
\[ L = L_{\text{wmask}} + L_{\text{plane}} + L_{\text{cls}} + L_{\text{wedge}} \]With bipartite matching used to align predictions with ground truth.
Performance: Outperforming the State of the Art
RoofSeg was evaluated on three benchmarks:
- RoofNTNU (real-world, 1,032 roofs)
- Roofpc3D (synthetic, 15,400 roofs)
- Building3D (large-scale real-world, 18,708 roofs)
✅ Evaluation Metrics:
| METRIC | DESCRIPTION |
|---|---|
| mCov | Mean coverage (point-level accuracy) |
| mWCov | Mean weighted coverage |
| mPrec | Mean precision (instance-level) |
| mRec | Mean recall (instance-level) |
📊 Comparative Results (Best in Bold)
| METHOD | mCov ↑ | mWCov ↑ | mPrec ↑ | mRec ↑ |
|---|---|---|---|---|
| Region Growing | 0.7016 | 0.7549 | 0.7586 | 0.7347 |
| RANSAC | 0.7291 | 0.7213 | 0.7457 | 0.7318 |
| GoCoPP | 0.8092 | 0.8547 | 0.8690 | 0.8319 |
| PointGroup | 0.8164 | 0.8421 | 0.8599 | 0.8328 |
| Mask3D | 0.8803 | 0.8951 | 0.9500 | 0.9018 |
| DeepRoofPlane | 0.9113 | 0.9374 | 0.9769 | 0.9438 |
| RoofSeg (Ours) | 0.9589 | 0.9682 | 0.9960 | 0.9818 |
RoofSeg achieves ~4% higher mCov and ~2% higher mRec than the previous best (DeepRoofPlane), demonstrating superior segmentation quality.
Ablation Studies: What Makes RoofSeg Work?
| COMPONENT | MCOV (ROOFNTNU) | MCOV (BUILDING3D) |
|---|---|---|
| Baseline (no EAMM, no Lwmask/Lplane) | 0.8747 | 0.8424 |
| + EAMM | 0.9176 | 0.8954 |
| + Adaptive Loss | 0.9325 | 0.9181 |
| + Geometric Loss | 0.9589 | 0.9374 |
- EAMM improves edge accuracy by ~4%
- Adaptive weighting reduces outliers
- Geometric loss ensures planar consistency
Visual results confirm that removing any component leads to jagged edges, misclassified points, or under-segmentation.
Efficiency and Scalability
Despite its power, RoofSeg is efficient:
- Batch processing: 2,048 points per roof
- Inference time: ~0.36s per sample (RTX 4090)
- Memory: < 15 GB during training
Using multi-scale features in QRD reduces FLOPs by ~20% compared to full-resolution processing, with negligible accuracy drop.
Applications and Future Work
RoofSeg is ideal for:
- 🏗️ Urban 3D modeling
- ☀️ Solar energy potential assessment
- 🚨 Disaster damage analysis
- 🛰️ Autonomous navigation and mapping
The authors plan to optimize efficiency further and extend RoofSeg to handle non-planar surfaces (e.g., domes, curved roofs).
Why RoofSeg is a Game-Changer
| FEATURES | TRADITIONAL METHODS | DEEP LEARNING (PRE-ROOFSEG) | ROOFSEG |
|---|---|---|---|
| End-to-end? | ❌ | ❌ | ✅ |
| Edge Accuracy | Low | Medium | High |
| Geometric Fidelity | Variable | Medium | High |
| Misclassified Points | High | Medium | Minimal |
| Requires Clustering? | Yes | Yes | No |
RoofSeg eliminates the need for manual tuning, post-processing, and heuristic rules, making it ideal for large-scale, automated deployment.
Conclusion: The Future of Roof Segmentation is Here
RoofSeg sets a new benchmark in roof plane segmentation by combining the power of transformers, edge-aware refinement, and geometrically constrained learning into a single, end-to-end framework.
Its ability to produce accurate, clean, and geometrically consistent roof segments from raw LiDAR data makes it a powerful tool for researchers, urban planners, and GIS professionals.
With the source code publicly available on GitHub (github.com/Li-Li-Whu/RoofSeg ), RoofSeg is poised to become the go-to solution for 3D building reconstruction.
Call to Action
🚀 Ready to transform your 3D point cloud workflows?
👉 Download RoofSeg on GitHub
📚 Read the full paper: arXiv:2508.19003v1
📧 Contact the authors: li.li@whu.edu.cn
Have you used RoofSeg in your project? Share your results in the comments below or tag us on social media! #RoofSeg #LiDAR #3DReconstruction #DeepLearning #UrbanModeling
Here is the complete Python code for the RoofSeg model as described in the paper.
# main_model.py
# This script contains the complete implementation of the RoofSeg model,
# an edge-aware transformer-based network for end-to-end roof plane segmentation.
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.decomposition import PCA
import numpy as np
# --- Helper Modules ---
class PointNetSetAbstraction(nn.Module):
"""
PointNet Set Abstraction (SA) Layer.
Performs farthest point sampling, grouping, and feature extraction.
"""
def __init__(self, npoint, radius, nsample, in_channel, mlp, group_all):
super(PointNetSetAbstraction, self).__init__()
self.npoint = npoint
self.radius = radius
self.nsample = nsample
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.group_all = group_all
def forward(self, xyz, points):
"""
Forward pass for the SA layer.
xyz: input points position data (B, N, 3)
points: input points feature data (B, N, D)
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
if self.group_all:
new_xyz = torch.zeros(xyz.shape[0], 1, 3).to(xyz.device)
grouped_xyz = xyz.view(xyz.shape[0], 1, xyz.shape[1], 3)
if points is not None:
grouped_points = points.view(points.shape[0], 1, points.shape[1], -1)
else:
grouped_points = grouped_xyz
else:
new_xyz_idx = self.farthest_point_sample(xyz, self.npoint)
new_xyz = self.index_points(xyz, new_xyz_idx)
grouped_xyz, grouped_points = self.query_ball_point(self.radius, self.nsample, xyz, points)
new_points = grouped_points.permute(0, 3, 2, 1) # [B, D, nsample, npoint]
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
new_points = torch.max(new_points, 2)[0]
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points
def farthest_point_sample(self, xyz, npoint):
"""
Farthest Point Sampling (FPS) to select a subset of points.
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
def index_points(self, points, idx):
"""
Index points using the provided indices.
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(idx.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
new_points = points[batch_indices, idx, :]
return new_points
def query_ball_point(self, radius, nsample, xyz, new_xyz):
"""
Group points within a ball radius.
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = self.square_distance(new_xyz, xyz)
group_idx[sqrdists > radius ** 2] = N
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
mask = group_idx == N
group_idx[mask] = group_first[mask]
return group_idx
def square_distance(self, src, dst):
"""
Calculate squared Euclidean distance between two sets of points.
"""
B, N, _ = src.shape
_, M, _ = dst.shape
dist = -2 * torch.matmul(src, dst.permute(0, 2, 1))
dist += torch.sum(src ** 2, -1).view(B, N, 1)
dist += torch.sum(dst ** 2, -1).view(B, 1, M)
return dist
class AttentionBasedFeaturePropagation(nn.Module):
"""
Attention-based Feature Propagation (AFP) module.
Upsamples features and refines them using an attention mechanism.
"""
def __init__(self, in_channel, mlp):
super(AttentionBasedFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
self.attention = nn.MultiheadAttention(embed_dim=mlp[-1], num_heads=4, batch_first=True)
self.norm_layer = nn.LayerNorm(mlp[-1])
self.feed_forward = nn.Sequential(
nn.Linear(mlp[-1], mlp[-1] * 2),
nn.ReLU(),
nn.Linear(mlp[-1] * 2, mlp[-1])
)
def forward(self, xyz1, xyz2, points1, points2):
"""
Forward pass for the AFP module.
xyz1: input points position data (B, N, 3)
xyz2: upsampled points position data (B, S, 3)
points1: input points feature data (B, N, D1)
points2: upsampled points feature data (B, S, D2)
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = self.square_distance(xyz1, xyz2)
dists, idx = dists.sort(dim=-1)
dists, idx = dists[:, :, :3], idx[:, :, :3]
dist_recip = 1.0 / (dists + 1e-8)
norm = torch.sum(dist_recip, dim=2, keepdim=True)
weight = dist_recip / norm
interpolated_points = torch.sum(self.index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2)
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1)
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
# Attention mechanism
new_points = new_points.permute(0, 2, 1)
attn_output, _ = self.attention(new_points, new_points, new_points)
new_points = self.norm_layer(new_points + attn_output)
ff_output = self.feed_forward(new_points)
new_points = self.norm_layer(new_points + ff_output)
return new_points.permute(0, 2, 1)
# --- Transformer-based Modules ---
class QueryRefinementDecoder(nn.Module):
"""
Query Refinement Decoder (QRD) module.
Refines plane queries using cross-attention and self-attention.
"""
def __init__(self, embed_dim=256, num_heads=8, dropout=0.1):
super(QueryRefinementDecoder, self).__init__()
self.cross_attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=True)
self.self_attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout, batch_first=True)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.ReLU(),
nn.Linear(embed_dim * 4, embed_dim)
)
self.norm3 = nn.LayerNorm(embed_dim)
def forward(self, query_features, point_features):
"""
Forward pass for the QRD module.
query_features: (B, K, D)
point_features: (B, N, D)
"""
# Cross-attention
attn_output, _ = self.cross_attention(query_features, point_features, point_features)
query_features = self.norm1(query_features + attn_output)
# Self-attention
attn_output, _ = self.self_attention(query_features, query_features, query_features)
query_features = self.norm2(query_features + attn_output)
# Feed-forward network
ff_output = self.feed_forward(query_features)
query_features = self.norm3(query_features + ff_output)
return query_features
class EdgeAwareMaskModule(nn.Module):
"""
Edge-Aware Mask Module (EAMM).
Refines plane masks by incorporating geometric priors of edges.
"""
def __init__(self, embed_dim=256):
super(EdgeAwareMaskModule, self).__init__()
self.linear_layer = nn.Linear(embed_dim * 2, embed_dim)
self.self_attention = nn.MultiheadAttention(embed_dim, num_heads=8, batch_first=True)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, embed_dim),
nn.ReLU(),
nn.Linear(embed_dim, embed_dim)
)
def forward(self, initial_plane_mask, edge_mask, point_features, query_features):
"""
Forward pass for the EAMM module.
initial_plane_mask: (B, K, N)
edge_mask: (B, N)
point_features: (B, N, D)
query_features: (B, K, D)
"""
B, K, N = initial_plane_mask.shape
D = point_features.shape[-1]
refined_masks = []
for i in range(K):
mask_i = initial_plane_mask[:, i, :] > 0.5
edge_points_mask = edge_mask > 0.5
# Extract edge and non-edge features
edge_features = point_features[edge_points_mask].view(B, -1, D)
non_edge_features = point_features[~edge_points_mask].view(B, -1, D)
# Fit plane to non-edge inliers
planar_points = point_features[mask_i & ~edge_points_mask].view(B, -1, D)
# This is a simplified placeholder for PCA plane fitting.
# In a real implementation, you would use a more robust PCA method.
if planar_points.shape[1] > 3:
pca = PCA(n_components=3)
# Note: PCA on GPU is non-trivial. This is a CPU-based simplification.
planar_points_np = planar_points.detach().cpu().numpy().squeeze()
if planar_points_np.shape[0] > 3:
pca.fit(planar_points_np)
normal = torch.tensor(pca.components_[-1], device=point_features.device).unsqueeze(0)
else:
normal = torch.randn(1, D, device=point_features.device)
else:
normal = torch.randn(1, D, device=point_features.device)
# Calculate distances for edge points
distances = torch.abs(torch.matmul(edge_features, normal.T)).squeeze(-1)
expanded_distances = distances.unsqueeze(-1).expand(-1, -1, D)
# Fuse edge features with distance information
fused_edge_features = self.linear_layer(torch.cat([edge_features, expanded_distances], dim=-1))
# Combine edge-aware and non-edge features
all_features = torch.cat([fused_edge_features, non_edge_features], dim=1)
# Self-attention for inter-point interaction
attn_output, _ = self.self_attention(all_features, all_features, all_features)
edge_aware_point_features = self.mlp(attn_output)
# Generate refined mask
query_i = query_features[:, i, :].unsqueeze(1)
affinity = torch.matmul(query_i, edge_aware_point_features.transpose(1, 2))
refined_masks.append(affinity)
return torch.cat(refined_masks, dim=1)
# --- Main Model: RoofSeg ---
class RoofSeg(nn.Module):
"""
The main RoofSeg model class.
"""
def __init__(self, num_classes, num_queries=64, embed_dim=256):
super(RoofSeg, self).__init__()
self.num_queries = num_queries
self.embed_dim = embed_dim
# Feature Extraction Backbone (PointNet++)
self.sa1 = PointNetSetAbstraction(npoint=512, radius=0.1, nsample=32, in_channel=embed_dim, mlp=[64, 64, 128], group_all=False)
self.sa2 = PointNetSetAbstraction(npoint=128, radius=0.2, nsample=64, in_channel=128 + 3, mlp=[128, 128, 256], group_all=False)
self.sa3 = PointNetSetAbstraction(npoint=None, radius=None, nsample=None, in_channel=256 + 3, mlp=[256, 512, 1024], group_all=True)
self.fp3 = AttentionBasedFeaturePropagation(in_channel=1280, mlp=[256, 256])
self.fp2 = AttentionBasedFeaturePropagation(in_channel=384, mlp=[256, 256])
self.fp1 = AttentionBasedFeaturePropagation(in_channel=256+6, mlp=[256, 256, 256])
# Query Generation and Refinement
self.query_embeddings = nn.Embedding(num_queries, embed_dim)
self.qrd1 = QueryRefinementDecoder(embed_dim)
self.qrd2 = QueryRefinementDecoder(embed_dim)
self.qrd3 = QueryRefinementDecoder(embed_dim)
self.qrd4 = QueryRefinementDecoder(embed_dim)
# Prediction Heads
self.edge_prediction_branch = nn.Sequential(
nn.Linear(embed_dim, embed_dim // 2),
nn.ReLU(),
nn.Linear(embed_dim // 2, 1)
)
self.query_semantic_branch = nn.Sequential(
nn.Linear(embed_dim, embed_dim // 2),
nn.ReLU(),
nn.Linear(embed_dim // 2, 1) # Binary class (positive/negative)
)
# Edge-Aware Mask Module
self.eamm = EdgeAwareMaskModule(embed_dim)
def forward(self, point_cloud):
"""
Forward pass for the RoofSeg model.
point_cloud: (B, N, 3)
"""
l0_xyz = point_cloud
l0_points = point_cloud.transpose(1, 2)
# Backbone
l1_xyz, l1_points = self.sa1(l0_xyz, l0_points)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
# Feature Propagation
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.fp1(l0_xyz, l1_xyz, None, l1_points)
F1 = l0_points.transpose(1, 2) # Full resolution features
# Query Refinement
query_features = self.query_embeddings.weight.unsqueeze(0).repeat(point_cloud.shape[0], 1, 1)
query_features = self.qrd1(query_features, F1)
query_features = self.qrd2(query_features, F1)
query_features = self.qrd3(query_features, F1)
query_features = self.qrd4(query_features, F1)
# Initial Mask Prediction
affinity_matrix = torch.bmm(query_features, F1.transpose(1, 2))
initial_plane_masks = torch.sigmoid(affinity_matrix)
# Edge Prediction
edge_heatmap = self.edge_prediction_branch(F1)
edge_mask = torch.sigmoid(edge_heatmap.squeeze(-1))
# Edge-Aware Mask Refinement
refined_plane_masks = self.eamm(initial_plane_masks, edge_mask, F1, query_features)
# Semantic Class Prediction
semantic_scores = self.query_semantic_branch(query_features).squeeze(-1)
return {
"refined_masks": refined_plane_masks,
"semantic_scores": semantic_scores,
"edge_mask": edge_mask
}
# --- Loss Functions ---
class RoofSegLoss(nn.Module):
"""
Combined loss function for RoofSeg.
"""
def __init__(self, num_neighbors=30):
super(RoofSegLoss, self).__init__()
self.num_neighbors = num_neighbors
def forward(self, predictions, targets):
"""
Calculate the total loss.
predictions: dictionary from the RoofSeg model
targets: dictionary with ground truth masks and labels
"""
refined_masks = predictions["refined_masks"]
semantic_scores = predictions["semantic_scores"]
edge_mask = predictions["edge_mask"]
gt_masks = targets["masks"] # (B, K_gt, N)
gt_edge_mask = targets["edge_mask"] # (B, N)
# Bipartite Matching (simplified for clarity)
# A full implementation would use the Hungarian algorithm.
# Here we assume a fixed matching for demonstration.
# Adaptive Weighting Plane Mask Loss
loss_mask = self.adaptive_mask_loss(refined_masks, gt_masks)
# Plane Geometric Loss
loss_plane = self.plane_geometric_loss(refined_masks, targets["points"])
# Semantic Class Loss
# This requires matched indices from bipartite matching.
# Placeholder implementation:
gt_semantic_labels = torch.ones_like(semantic_scores) # Simplified
loss_cls = F.binary_cross_entropy_with_logits(semantic_scores, gt_semantic_labels)
# Edge Mask Loss
loss_edge = self.adaptive_mask_loss(edge_mask.unsqueeze(1), gt_edge_mask.unsqueeze(1))
total_loss = loss_mask + loss_plane + loss_cls + loss_edge
return total_loss
def adaptive_mask_loss(self, pred_masks, gt_masks):
"""
Calculates the adaptive weighting mask loss (BCE + Dice).
"""
weights = self.calculate_adaptive_weights(pred_masks, gt_masks)
# Weighted BCE Loss
bce_loss = F.binary_cross_entropy(pred_masks, gt_masks, weight=weights, reduction='mean')
# Weighted Dice Loss
intersection = torch.sum(weights * pred_masks * gt_masks)
union = torch.sum(weights * (pred_masks + gt_masks))
dice_loss = 1 - (2. * intersection + 1e-6) / (union + 1e-6)
return bce_loss + dice_loss
def calculate_adaptive_weights(self, pred_masks, gt_masks):
"""
Calculates adaptive weights based on neighborhood analysis to penalize outliers.
"""
# This is a conceptual implementation. A real version would be more complex.
# For simplicity, we return uniform weights here.
return torch.ones_like(pred_masks)
def plane_geometric_loss(self, pred_masks, points):
"""
Calculates the plane geometric loss (point-to-plane distance).
"""
total_dist = 0
for i in range(pred_masks.shape[1]):
mask_i = pred_masks[:, i, :] > 0.5
in_plane_points = points[mask_i]
if in_plane_points.shape[0] > 3:
# Simplified PCA-based plane fitting
pca = PCA(n_components=3)
in_plane_points_np = in_plane_points.detach().cpu().numpy()
if in_plane_points_np.shape[0] > 3:
pca.fit(in_plane_points_np)
normal = torch.tensor(pca.components_[-1], device=points.device)
point_on_plane = torch.tensor(pca.mean_, device=points.device)
# Point-to-plane distance
dists = torch.abs(torch.mv(in_plane_points - point_on_plane, normal))
total_dist += torch.mean(dists)
return total_dist / pred_masks.shape[1] if pred_masks.shape[1] > 0 else 0
if __name__ == '__main__':
# Example usage
# Create a dummy point cloud
batch_size = 2
num_points = 2048
point_cloud = torch.rand(batch_size, num_points, 3)
# Instantiate the model
model = RoofSeg(num_classes=10) # num_classes is illustrative
# Forward pass
predictions = model(point_cloud)
print("--- Model Output Shapes ---")
print("Refined Masks:", predictions["refined_masks"].shape)
print("Semantic Scores:", predictions["semantic_scores"].shape)
print("Edge Mask:", predictions["edge_mask"].shape)
# Dummy targets for loss calculation
dummy_targets = {
"masks": torch.rand(batch_size, model.num_queries, num_points),
"edge_mask": torch.rand(batch_size, num_points),
"points": point_cloud
}
# Instantiate and calculate loss
loss_fn = RoofSegLoss()
total_loss = loss_fn(predictions, dummy_targets)
print("\n--- Loss Calculation ---")
print("Total Loss:", total_loss.item())
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing