7 Revolutionary Ways FiGKD is Transforming Knowledge Distillation (and 1 Major Drawback)
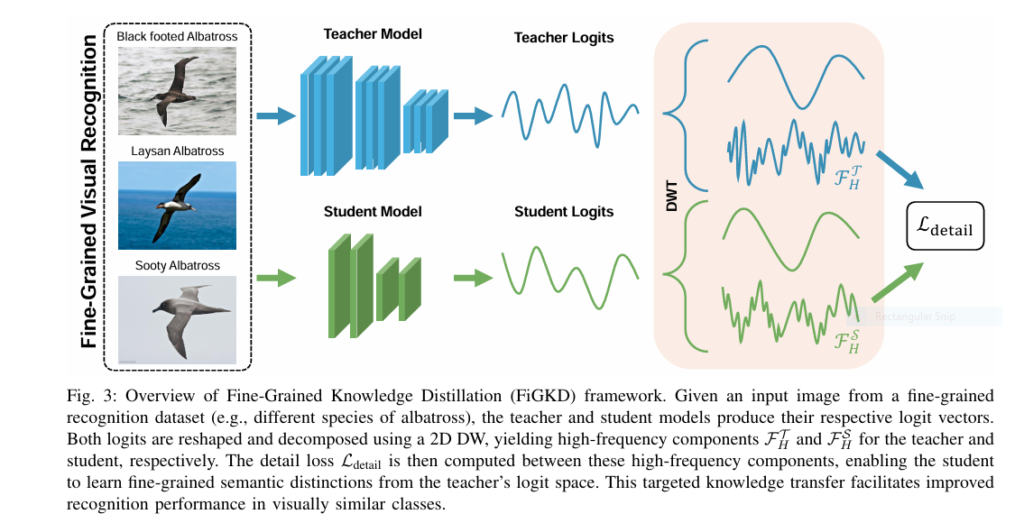
Introduction In the fast-evolving world of artificial intelligence and deep learning, knowledge distillation (KD) has emerged as a cornerstone technique for model compression. The goal? To transfer knowledge from a high-capacity teacher model to a compact student model while maintaining accuracy and efficiency. However, traditional KD methods often fall short when it comes to fine-grained […]
7 Revolutionary Ways FiGKD is Transforming Knowledge Distillation (and 1 Major Drawback) Read More »