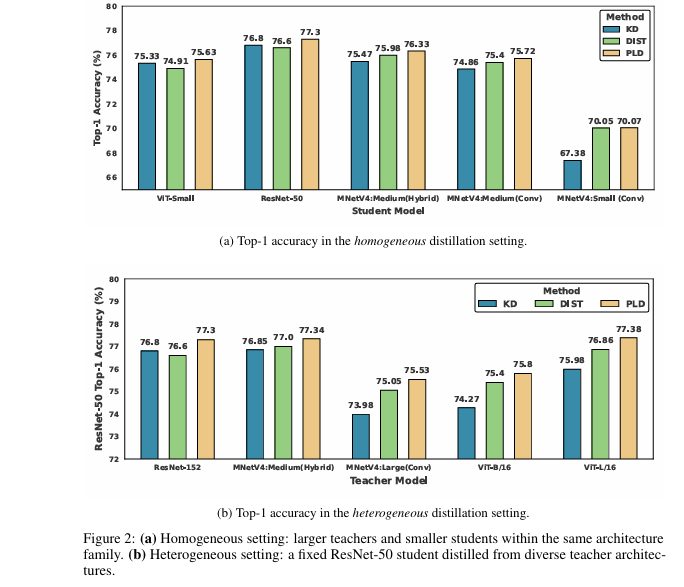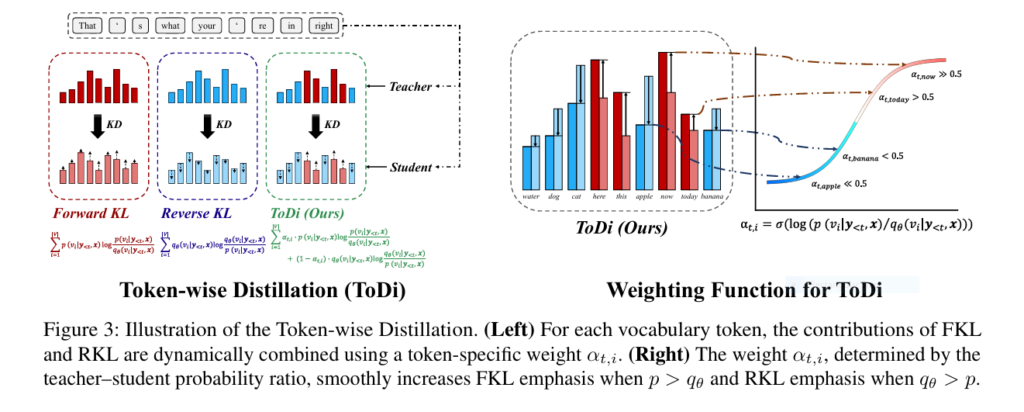
7 Revolutionary Insights About ToDi (Token-wise Distillation): The Future of Language Model Efficiency
Introduction: Why ToDi is a Game-Changer in Knowledge Distillation In the fast-evolving world of artificial intelligence, large language models (LLMs) have become indispensable tools for natural language processing tasks. However, their sheer size and computational demands make them impractical for deployment in resource-constrained environments. This challenge has led to a surge in research on knowledge […]