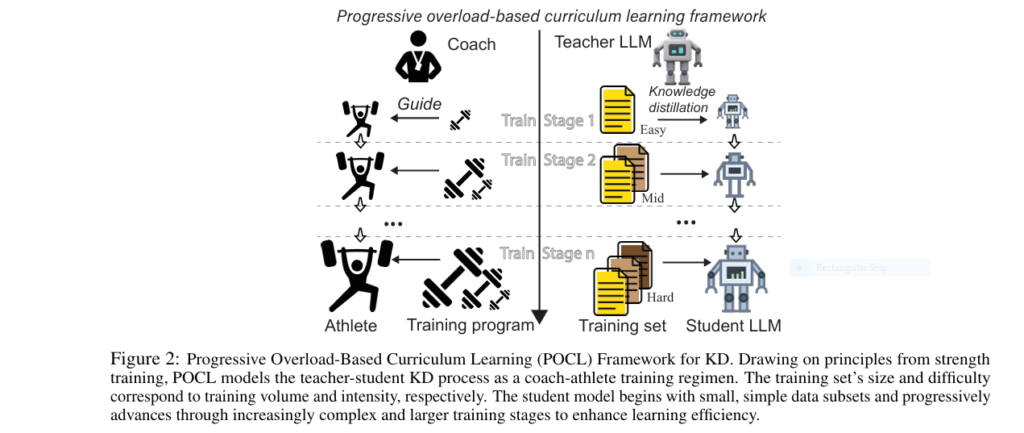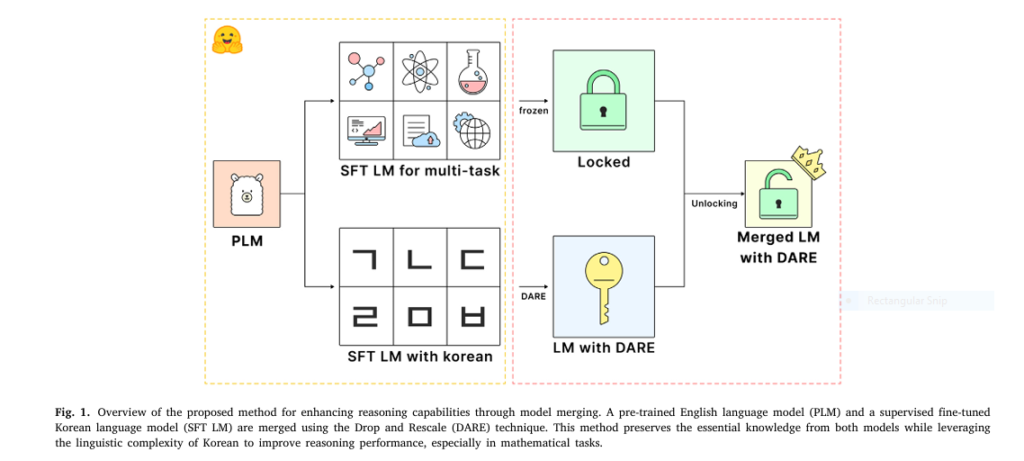
7 Shocking Ways Merging Korean Language Models Boosts LLM Reasoning (And 1 Dangerous Pitfall to Avoid)
In the rapidly evolving world of artificial intelligence, Large Language Models (LLMs) are hitting performance ceilings—especially when it comes to complex reasoning tasks like math and logic. But what if the key to unlocking their next-level intelligence lies not in bigger data or more compute, but in a surprisingly specific language? A groundbreaking 2025 study […]