Unlock 2.5X Better LLMs: How Progressive Overload Training Crushes Catastrophic Forgetting
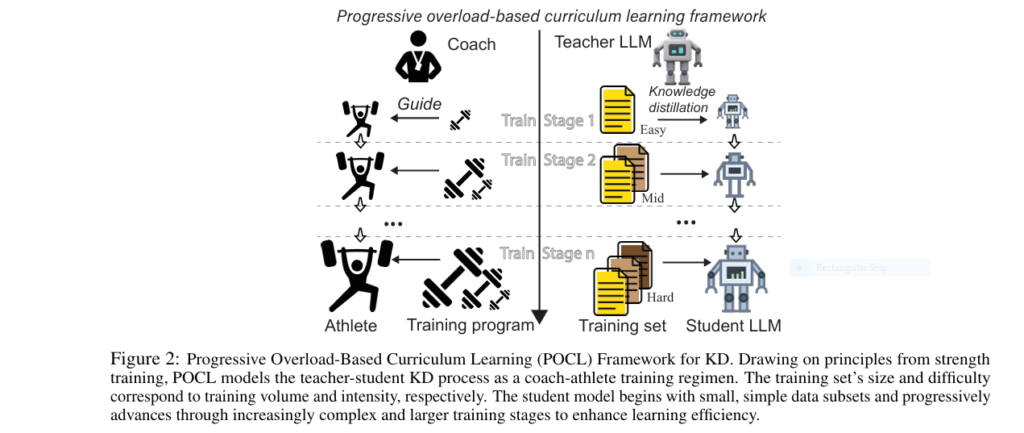
The Painful Reality of Shrinking Giant LLMs Large language models (LLMs) like GPT-4o and Claude 3.5 revolutionized AI—but their massive size makes deployment a nightmare. Imagine slashing compute costs by 90% while retaining 97% of performance. That’s the promise of Knowledge Distillation (KD), where a compact “student” model learns from a “teacher” LLM. Yet traditional KD […]