7 Shocking Wins and Pitfalls of Self-Distillation Without Teachers (And How to Master It!)
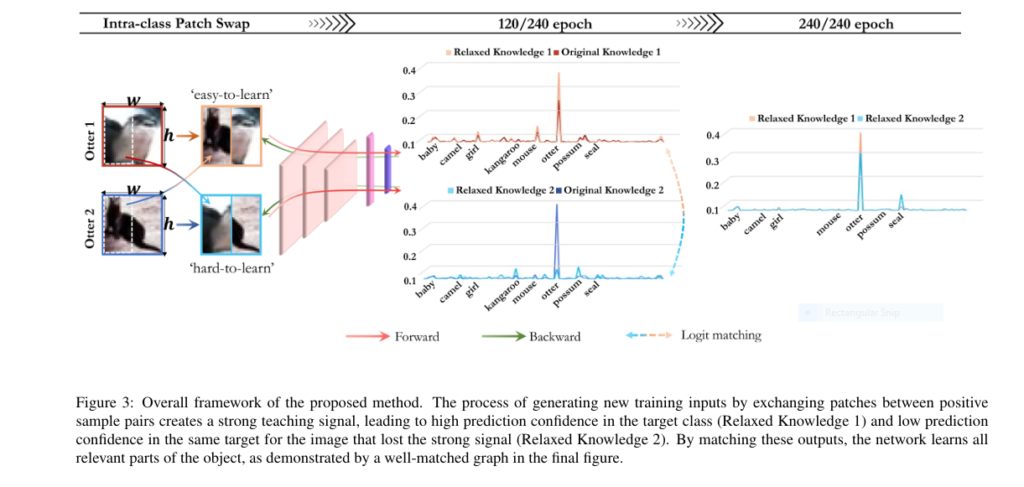
Introduction In the world of deep learning, especially in computer vision, knowledge distillation (KD) has been a go-to method to compress large models and improve performance. But the classic approach heavily relies on teacher-student architectures, which come with high memory, computational costs, and training complexity. The new research paper “Intra-class Patch Swap for Self-Distillation” proposes […]