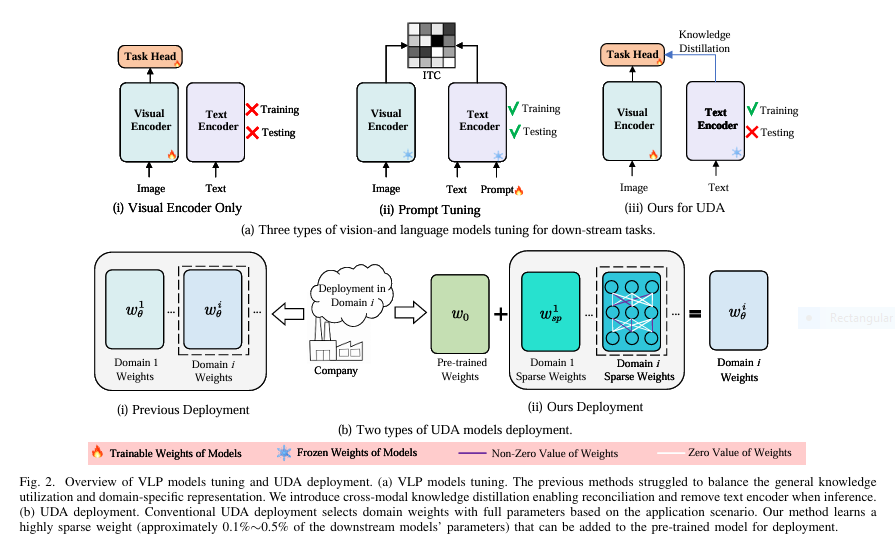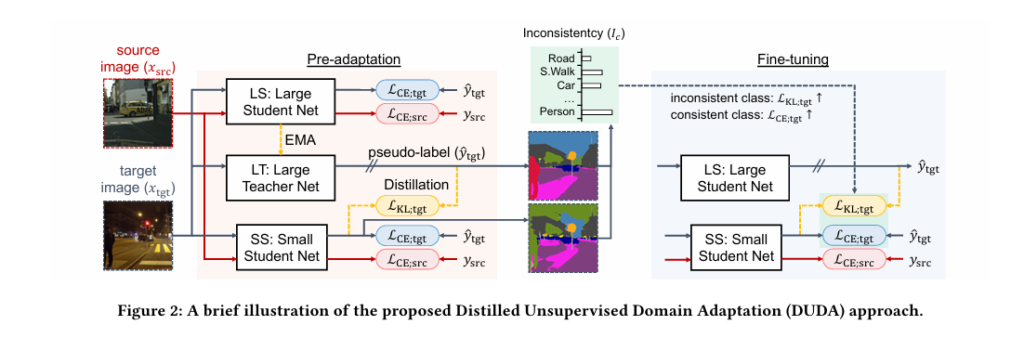
7 Shocking Secrets Behind DUDA: The Ultimate Breakthrough (and Why Most Lightweight Models Fail)
In the fast-evolving world of AI-powered visual understanding, lightweight semantic segmentation is the holy grail for real-time applications like autonomous driving, robotics, and augmented reality. But here’s the harsh truth: most lightweight models fail miserably when deployed in new environments due to domain shift—a phenomenon caused by differences in lighting, weather, camera sensors, and scene […]