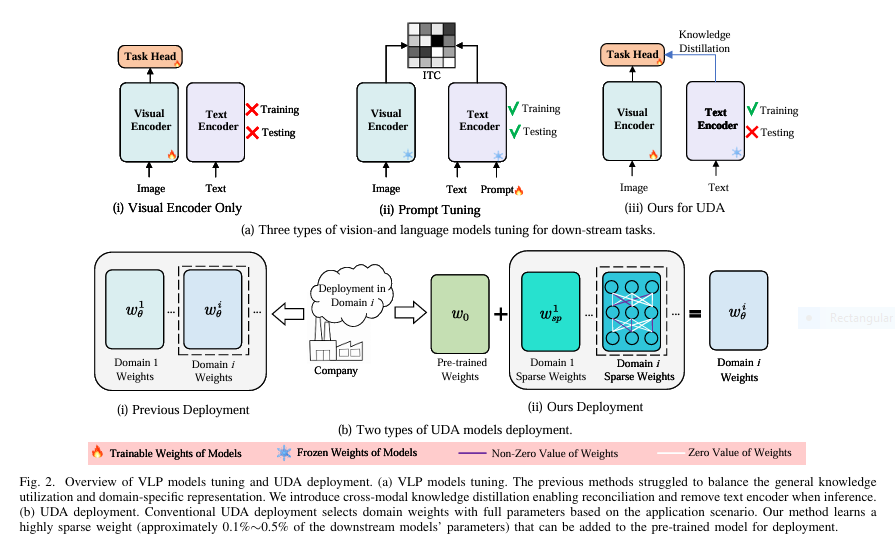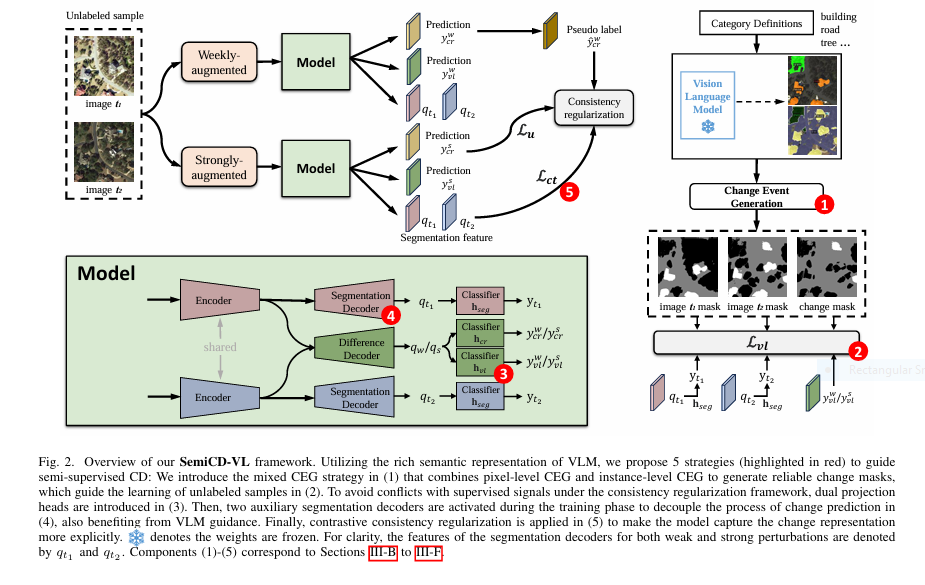
Revolutionize Change Detection: How SemiCD-VL Cuts Labeling Costs 5X While Boosting Accuracy
Change detection—the critical task of identifying meaningful differences between images over time—just got a seismic upgrade. For industries relying on satellite monitoring (urban planning, disaster response, agriculture), pixel-level annotation has long been the costly, time-consuming bottleneck stifling innovation. But a breakthrough AI framework—SemiCD-VL—now slashes labeling needs by 90% while delivering unprecedented accuracy, even outperforming fully supervised models. The Crippling […]