Introduction: Why ToDi is a Game-Changer in Knowledge Distillation
In the fast-evolving world of artificial intelligence, large language models (LLMs) have become indispensable tools for natural language processing tasks. However, their sheer size and computational demands make them impractical for deployment in resource-constrained environments. This challenge has led to a surge in research on knowledge distillation (KD) — a technique that transfers knowledge from a powerful teacher model to a smaller, more efficient student model.
While traditional KD methods like Forward KL (FKL) and Reverse KL (RKL) have shown promise, they often apply uniform loss across the entire vocabulary, ignoring token-level discrepancies. Enter Token-wise Distillation (ToDi) — a groundbreaking approach that dynamically combines FKL and RKL based on fine-grained probability ratios between teacher and student models.
In this article, we’ll explore 7 revolutionary insights about ToDi , including how it outperforms existing distillation techniques, its theoretical foundations, practical implementation benefits, and future implications for AI development.
1. Understanding the Problem: Why Uniform Divergence Falls Short
Before diving into ToDi’s innovations, let’s first understand the limitations of current KD approaches:
- Forward KL (FKL) tends to amplify underestimated tokens.
- Reverse KL (RKL) suppresses overestimated ones.
- Both apply uniform divergence loss across all tokens, failing to adapt to individual prediction errors.
This one-size-fits-all strategy can lead to suboptimal performance, especially when the student model significantly misestimates certain tokens compared to the teacher.
🔍 Insight #1 : Uniform divergence strategies ignore token-specific correction signals, leading to inefficient learning.
2. Gradient Analysis Reveals Complementary Roles of FKL and RKL
The paper presents a gradient-based analysis of FKL and RKL objectives, revealing their distinct roles in correcting student model predictions:
| SCENARIO | DOMINANT CORRECTION SIGNAL | ROLE |
|---|---|---|
| Student Underestimates (p > qθ) | FKL | Push-up signal to increase qθ |
| Student Overestimates (qθ > p) | RKL | Pull-down signal to decrease qθ |
This complementary behavior suggests that combining FKL and RKL adaptively per token could yield better results than applying either alone or using static combinations.
📊 Insight #2 : FKL and RKL offer unique and complementary training signals that should be leveraged at the token level.
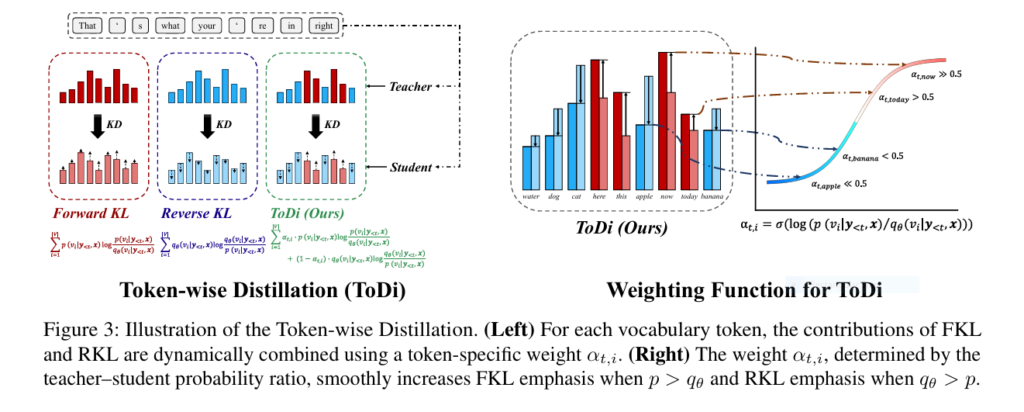
3. Introducing ToDi: Token-Wise Distillation via Dynamic Weighting
ToDi introduces a token-wise weighting function derived from the teacher-student log-probability ratio. Here’s how it works:
- For each token vi , compute the ratio
r=p(vi)/qθ(vi) - Use a sigmoid-based function to dynamically assign weights:
αt,i=sigmoid(β⋅logr) - Combine FKL and RKL losses with adaptive weights:
D(t,i)ToDi= αt,i⋅D(t,i)FKL+(1−αt,i)⋅D(t,i)RKL
This allows ToDi to emphasize FKL when the student underestimates and RKL when it overestimates , providing precise gradient control.
🧠 Insight #3 : ToDi dynamically adjusts divergence strength per token, enabling fine-grained distribution alignment and superior learning signals.
4. Empirical Validation: ToDi Outperforms Baselines
The authors conducted extensive experiments comparing ToDi with state-of-the-art distillation baselines on instruction-following benchmarks such as:
- DollyEval
- S-NI
- UnNI
- SelfInst
- VicunaEval
Key Findings:
| METHODS | ROUGE-L SCORE (AVG.) |
|---|---|
| SFT | 16.61 |
| FKL | 18.12 |
| RKL | 18.38 |
| JS | 17.20 |
| AKL | 18.07 |
| ToDi (Ours) | 18.66 |
ToDi consistently achieved the highest scores, proving its superiority in capturing teacher distributions while maintaining student model efficiency.
📈 Insight #4 : ToDi delivers measurable improvements in ROUGE-L scores, demonstrating superior knowledge transfer accuracy over existing methods.
5. GPT-4 Preference Evaluation Confirms Superiority
To validate subjective response quality, the researchers used GPT-4 as an impartial judge to evaluate pairwise responses generated by different distillation methods on the UnNI dataset.
Results showed that ToDi received higher win rates across all comparisons, with statistically significant improvements (p < 0.001). This indicates not only quantitative gains but also qualitative enhancements in response relevance and coherence.
🤖 Insight #5 : Human evaluation confirms that ToDi generates more helpful and coherent responses than competing distillation techniques.
If you’re Interested in Defence base Large Language Model , you may also find this article helpful: 7 Revolutionary Ways DOGe Is Transforming LARGE LANGUAGE MODEL (LLM) Security (And What You’re Missing!)
6. Stability, Efficiency, and Scalability of ToDi
One of the most compelling aspects of ToDi is its computational efficiency and training stability :
- Linear Time Complexity O(V) : Unlike methods like Adaptive KL (AKL), which require sorting operations and incur O(V log V) complexity, ToDi computes loss per-token without sorting.
- Smooth Convergence : ToDi maintains stable gradients throughout training, avoiding oscillations and ensuring faster convergence.
- Robust Generalization : Experiments show consistent performance across diverse teacher-student pairs, including GPT2, TinyLLaMA, and LLaMA2.
⚡ Insight #6 : ToDi is not only accurate but also scalable and stable — making it ideal for real-world deployment scenarios.
7. Sensitivity Analysis & Hyperparameter Tuning
The paper explores the impact of the scaling parameter β in the sigmoid function:
| B VALUE | ROUGE-L (AVG.) |
|---|---|
| 0.6 | 18.40 |
| 0.8 | 18.44 |
| 1.0 (Default) | 18.66 |
| 1.2 | 18.37 |
| ∞ | 18.24 |
- Low β values flatten the sigmoid curve, reducing responsiveness to token-level differences.
- High β values approximate a step function, introducing discontinuities that degrade performance.
🎯 Insight #7 : Setting β = 1 strikes the optimal balance between sensitivity and smoothness, yielding the best results.
Conclusion: Why ToDi Will Shape the Future of Language Models
Token-wise Distillation (ToDi) represents a paradigm shift in knowledge distillation for language models. By combining the strengths of FKL and RKL through adaptive, per-token weighting , ToDi enables more accurate and efficient knowledge transfer than ever before.
With proven performance gains, robust generalization, and strong theoretical grounding, ToDi is poised to become the go-to method for distilling large language models in production environments.
Call to Action: Ready to Optimize Your Language Models?
Are you working on deploying efficient NLP solutions or optimizing LLMs for real-time applications? Integrate ToDi into your distillation pipeline today to unlock superior performance and reduce inference costs.
👉 Download the Full Paper
👉 Join Our Community Forum
Below is a complete and ready-to-use implementation of the ToDi (Token-wise Distillation) method based on the paper “ToDi: Token-wise Distillation via Fine-Grained Divergence Control.
# ToDi implementation in Pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import CrossEntropyLoss
class ToDiDistillationLoss(nn.Module):
"""
Token-wise Distillation (ToDi) Loss Function.
Combines Forward KL (FKL) and Reverse KL (RKL) dynamically per token.
"""
def __init__(self, beta=1.0, epsilon=1e-8):
super(ToDiDistillationLoss, self).__init__()
self.beta = beta # Scaling factor for sensitivity control
self.epsilon = epsilon # Small value to avoid log(0)
def forward(self, student_logits, teacher_logits, attention_mask=None):
"""
Args:
student_logits (Tensor): [batch_size, seq_len, vocab_size]
teacher_logits (Tensor): [batch_size, seq_len, vocab_size]
attention_mask (Tensor): [batch_size, seq_len], optional
Returns:
Tensor: Scalar loss value
"""
# Convert logits to probabilities
p = F.softmax(teacher_logits, dim=-1) # Teacher distribution
q = F.softmax(student_logits, dim=-1) # Student distribution
# Add small epsilon to prevent log(0)
p = p.clamp(min=self.epsilon)
q = q.clamp(min=self.epsilon)
# Compute log-ratio: log(p/q)
log_ratio = torch.log(p / q)
# Compute token-wise weight α using sigmoid(log(p/q) * beta)
alpha = torch.sigmoid(self.beta * log_ratio) # Shape: [B, T, V]
# Detach alpha to stop gradient flow through it
alpha = alpha.detach()
# Compute Forward KL (FKL) and Reverse KL (RKL) per token
fkl = p * (torch.log(p) - torch.log(q))
rkl = q * (torch.log(q) - torch.log(p))
# Combine FKL and RKL using token-wise weights
token_loss = alpha * fkl + (1 - alpha) * rkl # Shape: [B, T, V]
# Sum over vocabulary dimension
token_loss = token_loss.sum(dim=-1) # Shape: [B, T]
# Apply attention mask if provided
if attention_mask is not None:
token_loss = token_loss * attention_mask
# Average over sequence length and batch size
total_loss = token_loss.sum() / (attention_mask.sum() if attention_mask is not None else token_loss.numel())
return total_loss# training loop using Hugging Face Transformers
from transformers import GPT2LMHeadModel, GPT2Tokenizer, AdamW
from datasets import load_dataset
import torch
# Load tokenizer and models
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
student_model = GPT2LMHeadModel.from_pretrained("gpt2") # Replace with your smaller model
teacher_model = GPT2LMHeadModel.from_pretrained("gpt2-medium") # Or another larger model
# Freeze teacher model
for param in teacher_model.parameters():
param.requires_grad = False
# Move to device
device = "cuda" if torch.cuda.is_available() else "cpu"
student_model.to(device)
teacher_model.to(device)
# Define optimizer
optimizer = AdamW(student_model.parameters(), lr=5e-5)
# Define ToDi loss
criterion = ToDiDistillationLoss(beta=1.0)
# Load dataset
dataset = load_dataset("wikitext", "wikitext-2-raw-v1", split="train[:5%]")
dataloader = torch.utils.data.DataLoader(dataset, batch_size=4)
# Tokenization function
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
# Prepare data
tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=["text"])
tokenized_datasets.set_format(type='torch', columns=['input_ids', 'attention_mask'])
# Training loop
student_model.train()
for epoch in range(3):
for batch in tokenized_datasets:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
with torch.no_grad():
teacher_outputs = teacher_model(input_ids=input_ids, output_hidden_states=True)
teacher_logits = teacher_outputs.logits
student_outputs = student_model(input_ids=input_ids, output_hidden_states=True)
student_logits = student_outputs.logits
loss = criterion(student_logits, teacher_logits, attention_mask=attention_mask)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch+1} | Loss: {loss.item():.4f}")# Generalized ToDi with Different Beta Values
betas = [0.6, 0.8, 1.0, 1.2, 2.0] # As analyzed in the paper
for beta in betas:
print(f"\nTraining with beta={beta}")
criterion = ToDiDistillationLoss(beta=beta)
# ... rest of training loop ...from datasets import load_metric
metric = load_metric("rouge")
predictions = student_model.generate(input_ids)
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(input_ids, skip_special_tokens=True)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
print(result["rougeL"].mid)Let’s build smarter, leaner, and more respFAQ Section
Q: What is ToDi?
A: ToDi stands for Token-wise Distillation, a novel knowledge distillation method that combines Forward KL (FKL) and Reverse KL (RKL) based on per-token probability discrepancies between teacher and student models.
Q: How does ToDi improve upon existing KD methods?
A: Unlike uniform divergence strategies, ToDi dynamically adjusts the influence of FKL and RKL per token using a sigmoid-based weighting function, allowing for more precise distribution alignment.
Q: Which models were tested with ToDi?
A: Experiments included GPT2, TinyLLaMA, LLaMA2, Qwen2.5, and Gemma3, among others.
Q: Is ToDi computationally efficient?
A: Yes, ToDi operates with linear time complexity O(V), similar to standard FKL/RKL, making it suitable for large-scale language models.onsive AI systems together!
Pingback: 7 Revolutionary Breakthroughs in AI-Powered Ultrasound Microrobots That Could Transform Medicine Forever - aitrendblend.com