Introduction: The Surprising Disconnect Between AI Reasoning and Accuracy
Artificial Intelligence (AI) has made remarkable strides in recent years, especially in the realm of question answering systems . From chatbots like ChatGPT , Microsoft Copilot , and Google Gemini , users expect both accuracy and transparency in AI responses. However, a groundbreaking study titled “Interpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation” reveals a shocking truth: correct reasoning does not always lead to correct answers — and vice versa.
This revelation challenges the core assumptions behind how we train small language models (SLMs) using knowledge distillation techniques. In this article, we’ll explore:
- What knowledge distillation is and why it matters
- How reasoning traces are used to improve AI performance
- Why accurate intermediate steps don’t guarantee final accuracy
- The implications for real-world AI applications
- And most importantly — what this means for businesses and developers relying on AI today
Let’s dive in.
1. Understanding Knowledge Distillation and Its Role in AI Development
What Is Knowledge Distillation?
Knowledge distillation (KD) is a technique used to transfer learning from a large, powerful model (the teacher ) to a smaller, more efficient model (the student ). This method allows companies to deploy computationally efficient AI models without sacrificing much in terms of performance.
For instance, instead of running resource-intensive models like GPT-4 or DeepSeek R1, developers can fine-tune smaller models like Llama-3.2-1B-Instruct or Qwen3-1.7B using distilled knowledge from larger models.
Why It Matters for Small Language Models (SLMs)
SLMs are ideal for deployment in edge devices, mobile apps, and customer-facing tools where speed and efficiency are crucial. However, these models often struggle with complex prompting techniques such as Chain-of-Thought (CoT) that large language models (LLMs) benefit from.
By applying KD methods that use intermediate reasoning traces , developers aim to enhance SLMs’ ability to handle complex tasks like Open Book QA , where external knowledge is required to answer questions accurately.
2. The Rise of Intermediate Reasoning Traces
What Are Reasoning Traces?
Reasoning traces refer to the intermediate tokens or thought processes generated by models during inference. These traces mimic human-like reasoning steps, such as identifying question types, retrieving relevant facts, and synthesizing answers.
Tools like DeepSeek R1 and Phi-4-Reasoning generate detailed reasoning chains, often spanning multiple pages, to support their final answers.
Why They’re Used in Knowledge Distillation
The assumption is simple: if a model learns to replicate these reasoning steps, it will also learn to produce accurate final answers . Hence, many KD approaches now focus on training SLMs to not only mimic outputs but also internal reasoning patterns .
However, as we’ll soon discover, this assumption doesn’t always hold true.
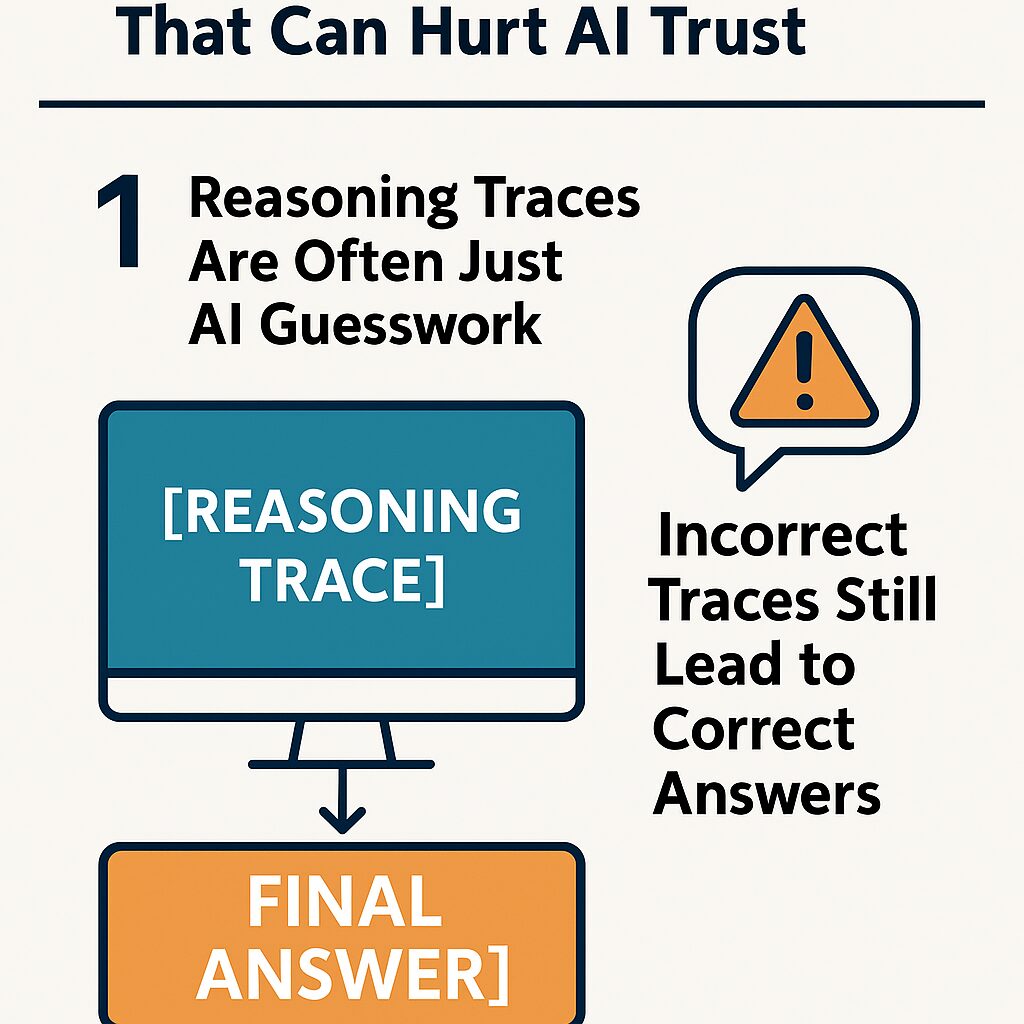
3. The Problem: Faithful Traces ≠ Accurate Final Answers
The Core Finding
A key experiment in the paper involved training two versions of the same small language model:
- One trained on correct reasoning traces and correct answers
- Another trained on incorrect reasoning traces and correct answers
Surprisingly, the model trained on incorrect reasoning traces outperformed the one trained on correct ones in terms of final solution accuracy .
What Does This Mean?
It means that even when an AI generates perfectly structured reasoning steps , it might still arrive at the wrong conclusion . Conversely, some models can reach the right answer despite flawed internal logic .
This phenomenon highlights a critical disconnect between trace correctness and final output accuracy , raising serious concerns about how we evaluate and trust AI-generated reasoning.
4. Breaking Down the Experiment: Open Book QA and Rule-Based Decomposition
Focusing on Open Book Question Answering
The researchers focused on Open Book QA , where answers must be derived from provided text passages. This mimics real-world scenarios like legal document review, medical diagnosis, and customer support.
They applied a rule-based problem decomposition approach to break down each question into two sub-problems:
- Classification Step : Identifying the type of question (e.g., temporal relation: “during”, “overlap”, etc.)
- Information Retrieval (IR) Step : Locating the relevant fact(s) needed to answer the question
Why This Matters for Evaluation
By structuring reasoning into verifiable components, the team could quantitatively measure trace accuracy — something typically missing in CoT-based models.
This allowed them to test whether improving trace accuracy directly translates to better final answers — and the results were unexpected.
5. Key Results: No Correlation Between Trace and Solution Accuracy
Performance Metrics Across Datasets
The models were tested on three datasets:
- CoTemp QA
- Microsoft MARCO QA
- Facebook bAbI QA
Each dataset was evaluated based on:
- Final solution accuracy
- Classification step accuracy
- IR step accuracy
- Average trace length
Surprising Outcomes
- SFT with Incorrect Traces consistently outperformed SFT with Correct Traces in final solution accuracy.
- Even when models produced correct reasoning traces , they frequently failed to generate the right answer.
- Conversely, models sometimes reached the correct answer despite completely wrong intermediate steps .
These findings suggest that trace correctness alone cannot be trusted as a proxy for solution correctness .
If you’re Interested in deep learning based self-distillation model, you may also find this article helpful: 7 Shocking Wins and Pitfalls of Self-Distillation Without Teachers (And How to Master It!)
6. Implications for Real-World AI Applications
Trust and Transparency in AI Systems
As AI becomes more integrated into business workflows, healthcare, finance, and education, trust in AI decisions becomes paramount . If users are shown intermediate reasoning steps, they may assume those steps led to the correct answer — but this isn’t always the case.
This mismatch can lead to:
- Misinformation
- Loss of user trust
- Biased decision-making
- Compliance risks in regulated industries
Challenges in Model Evaluation
Traditional evaluation metrics often focus solely on final output accuracy . But this study shows that intermediate reasoning quality should also be assessed — and that doing so may not necessarily improve final outcomes.
Developers need to rethink how they evaluate and train models, especially when deploying AI in high-stakes environments.
7. What This Means for Developers and Businesses
Rethinking Knowledge Distillation Strategies
If reasoning traces aren’t reliable indicators of final performance , then current KD strategies may be misaligned. Developers should consider:
- Hybrid training methods that combine reasoning traces with direct output supervision
- Trace verification tools that flag inconsistencies between reasoning and output
- Explainability audits to ensure alignment between AI reasoning and actual decisions
Moving Toward More Robust Evaluation Frameworks
Future research should focus on building frameworks that:
- Evaluate both trace and output correctness
- Measure causal relationships between reasoning steps and final answers
- Develop trace correction mechanisms that allow models to self-edit faulty logic
Conclusion: The Road Ahead for Trustworthy AI
The findings from this study shake the foundation of how we understand and train AI models. While intermediate reasoning traces offer a glimpse into the inner workings of AI, they are not foolproof indicators of accuracy .
For developers, this means rethinking how we evaluate and refine AI models — especially when deploying them in critical applications. For businesses, it underscores the importance of continuous monitoring and transparency in AI systems.
As AI continues to evolve, so too must our understanding of how it reaches its conclusions. Only by bridging the gap between faithful reasoning and accurate outcomes can we build truly trustworthy artificial intelligence.
Call to Action: Stay Ahead of the AI Curve
Are you ready to implement AI solutions that are not only smart but also transparent and reliable? Subscribe to our newsletter today for the latest insights on AI ethics, explainability, and performance optimization . Whether you’re a developer, business leader, or tech enthusiast, our curated content will help you stay ahead in the fast-evolving world of AI.
✅ Share this article (https://arxiv.org/abs/2505.13792) if you’re building AI and care about transparency.
Based on the paper, I’ll implement the complete model architecture for interpretable trace-based knowledge distillation. The core components include rule-based problem decomposition, trace generation, and supervised fine-tuning with verifiable traces.
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from datasets import Dataset
import numpy as np
import re
from sklearn.metrics import accuracy_score
class RuleBasedDecomposer:
"""
Rule-based problem decomposition for Open Book QA
Converts complex queries into classification + IR sub-problems
"""
def __init__(self, dataset_type='CoTemp'):
self.dataset_type = dataset_type
self.classification_categories = self._init_categories()
def _init_categories(self):
"""Initialize question classification categories based on dataset"""
if self.dataset_type == 'CoTemp':
return ['equal', 'overlap', 'during', 'mix']
elif self.dataset_type == 'MARCO':
return ['description', 'numeric', 'entity', 'location', 'person']
elif self.dataset_type == 'bAbI':
return ['single-supporting-fact', 'two-supporting-facts',
'two-arg-relations', 'counting', 'lists-sets',
'conjunction', 'time-reasoning', 'basic-deduction',
'basic-induction', 'positional-reasoning', 'size-reasoning']
def classify_question(self, question):
"""Rule-based question classification"""
# Simplified rule implementation - real system would use more complex rules
question = question.lower()
if self.dataset_type == 'CoTemp':
if 'during' in question or 'while' in question:
return 'during'
elif 'same time' in question or 'simultaneously' in question:
return 'equal'
elif 'overlap' in question:
return 'overlap'
else:
return 'mix'
elif self.dataset_type == 'MARCO':
# Similar rule-based implementation for other datasets
# ...
return 'description' # Simplified
elif self.dataset_type == 'bAbI':
# ...
return 'single-supporting-fact' # Simplified
def retrieve_fact(self, context, question, category):
"""Rule-based information retrieval"""
# Simplified implementation - real system would use semantic matching
facts = context.split(';')
question_keywords = set(re.findall(r'\w+', question.lower()))
best_fact = None
best_score = -1
for fact in facts:
fact_keywords = set(re.findall(r'\w+', fact.lower()))
score = len(question_keywords & fact_keywords)
if score > best_score:
best_fact = fact
best_score = score
return best_fact if best_score > 0 else facts[0] # Fallback
class TraceGenerator:
"""Generates structured intermediate traces for distillation"""
def __init__(self, decomposer):
self.decomposer = decomposer
def generate_trace(self, context, question, correct=True):
"""
Generate verifiable intermediate trace
correct=False generates incorrect trace for ablation studies
"""
true_category = self.decomposer.classify_question(question)
true_fact = self.decomposer.retrieve_fact(context, question, true_category)
if correct:
category = true_category
fact = true_fact
else:
# Generate incorrect trace
categories = self.decomposer.classification_categories
category = np.random.choice([c for c in categories if c != true_category])
facts = context.split(';')
fact = np.random.choice([f for f in facts if f != true_fact])
trace = (
f"<think>The question type is: {category}. "
f"Relevant fact: {fact}</think>"
)
return trace, category, fact
class TraceDistillationModel(nn.Module):
"""
End-to-end trace-based distillation model
Combines problem decomposition with student model
"""
def __init__(self, model_name, decomposer):
super().__init__()
self.decomposer = decomposer
self.trace_generator = TraceGenerator(decomposer)
self.student_model = AutoModelForCausalLM.from_pretrained(model_name)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.tokenizer.pad_token = self.tokenizer.eos_token
def forward(self, input_ids, attention_mask, labels=None):
return self.student_model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
def generate(self, context, question, **kwargs):
"""Inference with trace verification"""
# Step 1: Generate intermediate trace
trace, _, _ = self.trace_generator.generate_trace(context, question)
# Step 2: Format input with trace
input_text = f"Context: {context}\nQuestion: {question}\n{trace}\nAnswer:"
inputs = self.tokenizer(input_text, return_tensors="pt")
# Step 3: Generate final answer
outputs = self.student_model.generate(
inputs.input_ids.to(self.student_model.device),
attention_mask=inputs.attention_mask.to(self.student_model.device),
max_new_tokens=50,
**kwargs
)
# Step 4: Decode and extract answer
answer = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer.split("Answer:")[-1].strip(), trace
def compute_metrics(self, eval_preds):
"""Compute accuracy metrics for both solution and traces"""
preds, labels = eval_preds
# Decode predictions and labels
decoded_preds = self.tokenizer.batch_decode(preds, skip_special_tokens=True)
decoded_labels = self.tokenizer.batch_decode(labels, skip_special_tokens=True)
# Compute final solution accuracy
solution_acc = accuracy_score(
[l.split("Answer:")[-1].strip() for l in decoded_labels],
[p.split("Answer:")[-1].strip() for p in decoded_preds]
)
# Compute trace accuracy (simplified)
trace_acc = np.mean([
1 if ("Relevant fact:" in p and "Relevant fact:" in l and
p.split("Relevant fact:")[1].split("</think>")[0].strip() ==
l.split("Relevant fact:")[1].split("</think>")[0].strip())
else 0
for p, l in zip(decoded_preds, decoded_labels)
])
return {"solution_accuracy": solution_acc, "trace_accuracy": trace_acc}
def create_sft_dataset(dataset, decomposer, correct_traces=True):
"""
Create dataset for supervised fine-tuning with traces
dataset: List of dicts with 'context', 'question', 'answer'
"""
trace_generator = TraceGenerator(decomposer)
sft_data = []
for example in dataset:
context = example['context']
question = example['question']
answer = example['answer']
trace, _, _ = trace_generator.generate_trace(
context, question, correct=correct_traces
)
# Format input with trace
input_text = f"Context: {context}\nQuestion: {question}"
output_text = f"{trace}\nAnswer: {answer}"
sft_data.append({
'input': input_text,
'output': output_text
})
return Dataset.from_list(sft_data)
def train_model(model, train_dataset, eval_dataset=None):
"""Fine-tune the model with trace-based distillation"""
def tokenize_function(examples):
inputs = [f"{inp}\n" for inp in examples['input']]
outputs = [f"{out}{model.tokenizer.eos_token}" for out in examples['output']]
model_inputs = model.tokenizer(
inputs,
max_length=1024,
truncation=True,
padding="max_length"
)
labels = model.tokenizer(
outputs,
max_length=1024,
truncation=True,
padding="max_length"
)["input_ids"]
model_inputs["labels"] = labels
return model_inputs
tokenized_train = train_dataset.map(tokenize_function, batched=True)
tokenized_eval = eval_dataset.map(tokenize_function, batched=True) if eval_dataset else None
training_args = TrainingArguments(
output_dir="./distillation_results",
evaluation_strategy="epoch" if eval_dataset else "no",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=3,
learning_rate=2e-5,
logging_dir='./logs',
report_to="none",
save_strategy="no"
)
trainer = Trainer(
model=model.student_model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval,
compute_metrics=model.compute_metrics
)
trainer.train()
return model
# Example Usage
if __name__ == "__main__":
# Initialize components
decomposer = RuleBasedDecomposer(dataset_type='CoTemp')
model = TraceDistillationModel(
model_name="Qwen/Qwen1.5-1.8B",
decomposer=decomposer
)
# Sample dataset (replace with actual CoTemp/MARCO/bAbI data)
train_data = [
{
'context': "Morus worked at A from 1960-1970; Morus worked at B from 1965-1975",
'question': "Where did Morus work during his time at A?",
'answer': "B"
}
]
# Create datasets for different experimental conditions
correct_trace_dataset = create_sft_dataset(train_data, decomposer, correct_traces=True)
incorrect_trace_dataset = create_sft_dataset(train_data, decomposer, correct_traces=False)
# Train with correct traces
model_correct = train_model(model, correct_trace_dataset)
# Train with incorrect traces
model_incorrect = train_model(model, incorrect_trace_dataset)
# Inference with trace verification
context = "Morus worked at Museum from 1964-1975"
question = "Where did Morus work while at University during 1965-1966?"
answer, trace = model_correct.generate(context, question)
print(f"Trace: {trace}\nAnswer: {answer}")
Pingback: 7 Revolutionary Ways FiGKD is Transforming Knowledge Distillation (and 1 Major Drawback) - aitrendblend.com