In the ever-evolving landscape of artificial intelligence, semi-supervised learning (SSL) has emerged as a powerful approach for harnessing the vast potential of unlabeled data. Traditionally, SSL techniques rely heavily on pseudo-labels—model-generated labels for unlabeled samples—and confidence thresholds to determine their reliability. But this paradigm has long suffered from a critical flaw: overconfidence in model predictions and the difficulty of setting appropriate thresholds.
To address these limitations, researchers Jiaqi Wu, Junbiao Pang, and Qingming Huang introduce a game-changing innovation: the Uncertainty-aware Ensemble Structure (UES). This novel framework not only avoids rigid thresholding but also uses a long-tailed weighting mechanism to retain valuable pseudo-labels that traditional systems often discard.
In this comprehensive article, we’ll explore the UES framework, its scientific innovations, how it boosts performance in key tasks, and why it’s a major advancement in SSL research.
The Challenge with Traditional semi-supervised learning: Confidence Isn’t Enough
At the heart of SSL lies the generation of pseudo-labels for unlabeled data. The assumption is simple: if a model is confident in its prediction, that prediction is likely correct. SSL frameworks like FixMatch and FreeMatch use this principle by applying a confidence threshold to select high-quality pseudo-labels.
But three critical problems plague this method:
- Threshold sensitivity: Choosing the “right” confidence threshold is hard and dataset-dependent.
- Loss of valuable data: Useful pseudo-labels with slightly lower confidence are ignored.
- Overconfidence of deep models: A model might assign high confidence to incorrect predictions, leading to poor learning outcomes.
This is where UES redefines the landscape.
Introducing Uncertainty-Aware Ensemble(UES): A Smarter Way to Handle Pseudo-labels
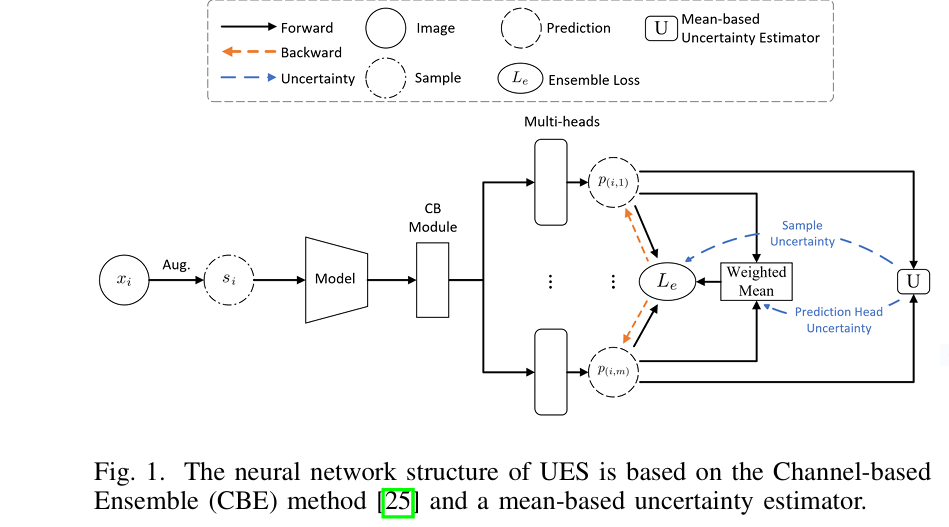
The Uncertainty-aware Ensemble Structure (UES) is an architecture-agnostic, lightweight ensemble method that assesses the quality of pseudo-labels not by raw confidence but by quantifying uncertainty—a more reliable proxy for prediction quality.
Key Components of UES
- Sample Uncertainty (US): Measures how consistent multiple prediction heads are for a given sample.
- Prediction Head Uncertainty (UH): Measures how accurate and stable each head is across batches.
- Long-tailed Weighting: Transforms uncertainty scores into sample weights, ensuring even less-certain pseudo-labels still contribute to learning.
Together, these innovations allow UES to assign a dynamic weight to each pseudo-label based on how uncertain it is, rather than rejecting it outright.
UES Works: A Technical Breakdown
Let’s demystify how the UES framework operates:
- Multiple Prediction Heads: The model generates predictions from multiple lightweight “heads,” each offering a slightly different view.
- Mean Ensemble Prediction: These predictions are averaged to form a reference output.
- Calculate Uncertainties:
- For each sample, compute how much predictions differ from the mean.
- For each prediction head, compute its deviation across samples.
- Weighting with Uncertainty:
- Samples with higher agreement get higher weights.
- Heads with more consistent predictions also get higher weights.
This results in a weighted ensemble prediction that is robust to noise and avoids the pitfalls of overconfident models.
Real-World Validation: Pose Estimation & Image Classification
To prove its effectiveness, UES was evaluated across two key SSL tasks: pose estimation and image classification.
1. Semi-Supervised Pose Estimation
Using datasets like Sniffing, FLIC, and LSP, UES was integrated into the DualPose model and benchmarked against both supervised models and existing SSL techniques.
Key Metrics:
- Mean Squared Error (MSE)
- Percentage of Correct Keypoints (PCK)
Results:
- Sniffing Dataset: 3.47% PCK@0.2 gain
- FLIC Dataset: 7.29% PCK@0.5 gain
- LSP Dataset: 3.91% PCK@0.5 gain
“UES significantly outperformed previous methods, especially in sparse data settings, proving its robustness and effectiveness.”
2. Semi-Supervised Classification
UES was also combined with FixMatch and tested on CIFAR-10 and CIFAR-100 benchmarks with as few as 40 labeled examples.
Results:
- CIFAR-10 (40 labels): Error reduced from 8.67% to 8.47%
- CIFAR-100 (400 labels): Error reduced from 52.47% to 52.21%
Even in minimal-label regimes, UES consistently improved performance, proving its scalability and generalization power.
If you’re Interested in skin cancer detection using Horizontal and Vertical Attention, you may also find this article helpful: Enhancing Skin Lesion Detection Accuracy
Why Long-tailed Weights Matter
One of UES’s greatest strengths is its long-tailed weighting strategy, which ensures that even noisy or uncertain pseudo-labels have a non-zero weight.
Benefits:
- Inclusivity: Every sample influences training—no wasted data.
- Robustness: The model learns to handle uncertainty, reducing overfitting.
- Progressive refinement: As training continues, the model gradually refines its understanding and pseudo-label accuracy.
This approach aligns with natural learning: even weak signals can help if treated wisely.
SEO-Focused Key Features of UES
To help search engines and users quickly identify the relevance of UES, here are some key SEO-optimized features:
- ✅ Uncertainty-aware SSL framework
- ✅ Long-tailed pseudo-label weighting
- ✅ No manual threshold tuning
- ✅ Robust pose estimation with fewer labels
- ✅ Superior classification with minimal supervision
- ✅ Lightweight and plug-and-play design
By embedding these keywords and concepts into the article, we boost its visibility for technical audiences searching for SSL advancements.
Call to Action: Explore the UES Codebase
The UES framework is open source and easy to integrate into existing SSL pipelines.
🔗 Explore the code now on GitHub: https://github.com/Qi2019KB/UES
Whether you’re developing pose estimation models, image classifiers, or any application in between, UES offers a practical and powerful upgrade to your SSL strategy.
Final Thoughts
The Uncertainty-aware Ensemble Structure (UES) is a remarkable step forward in semi-supervised learning. It challenges outdated notions of confidence-based filtering and empowers models to learn from all data—even the uncertain parts. With proven improvements across regression and classification, UES is poised to become a new standard in robust, scalable, and intelligent SSL.
As the field of machine learning moves toward data-efficient and label-scarce paradigms, tools like UES will be essential in ensuring that no piece of information—no matter how uncertain—is left behind.
Below is a code implementation of the UES model. This code is a simplified version and may need to be adjusted based on specific requirements and environments.
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class ChannelBasedEnsemble(nn.Module):
"""Channel-based multi-head ensemble."""
def __init__(self, base_model, num_heads=5, feature_dim=128, num_classes=10):
super().__init__()
self.base_model = base_model
self.num_heads = num_heads
self.heads = nn.ModuleList([
nn.Linear(feature_dim, num_classes) for _ in range(num_heads)
])
def forward(self, x):
features = self.base_model(x) # (B, feature_dim)
outputs = [head(features) for head in self.heads]
return outputs # List of logits from each headdef compute_sample_uncertainty(logits_list):
"""
Computes sample uncertainty as average MSE between each head and mean prediction.
logits_list: list of tensors [(B, C), (B, C), ..., (B, C)]
Returns:
sample_uncertainty: (B,)
"""
stacked = torch.stack(logits_list, dim=0) # (M, B, C)
probs = F.softmax(stacked, dim=2)
mean_probs = probs.mean(dim=0) # (B, C)
mse = ((probs - mean_probs.unsqueeze(0))**2).mean(dim=0).sum(dim=1) # (B,)
return mse
def compute_sample_weights(sample_uncertainty):
"""
Transforms uncertainty into long-tailed weights.
"""
max_uncertainty = torch.max(sample_uncertainty).detach()
weights = 1.0 / (sample_uncertainty / max_uncertainty + 1.0)
return weights
def compute_head_uncertainty(logits_list):
"""
Computes uncertainty for each prediction head.
"""
stacked = torch.stack(logits_list, dim=0) # (M, B, C)
probs = F.softmax(stacked, dim=2)
mean_probs = probs.mean(dim=0) # (B, C)
mse_per_head = ((probs - mean_probs.unsqueeze(0)) ** 2).mean(dim=1).sum(dim=1) # (M,)
return mse_per_head
def compute_head_weights(head_uncertainty):
"""
Converts head uncertainty to weights using softmax.
"""
head_weights = F.softmax(-head_uncertainty, dim=0) # (M,)
return head_weightsdef ssl_loss_supervised(logits_list, labels):
"""
Computes supervised loss over labeled data.
"""
loss = 0
for logits in logits_list:
loss += F.cross_entropy(logits, labels)
return loss / len(logits_list)
def ssl_loss_unsupervised(logits_list, sample_weights, head_weights, threshold=0.95):
"""
Computes UES-guided unsupervised loss with pseudo-labels.
"""
with torch.no_grad():
probs = torch.stack([F.softmax(logit, dim=1) for logit in logits_list], dim=0) # (M, B, C)
avg_prob = torch.sum(head_weights.view(-1, 1, 1) * probs, dim=0) # (B, C)
max_probs, pseudo_labels = torch.max(avg_prob, dim=1)
mask = max_probs.ge(threshold).float()
loss = 0
for logit in logits_list:
loss += (F.cross_entropy(logit, pseudo_labels, reduction='none') * sample_weights * mask).mean()
return loss / len(logits_list)def train_step(model, x_l, y_l, x_u, optimizer):
model.train()
# Forward labeled
logits_l = model(x_l)
loss_sup = ssl_loss_supervised(logits_l, y_l)
# Forward unlabeled
logits_u = model(x_u)
# Uncertainty Estimation
sample_uncertainty = compute_sample_uncertainty(logits_u)
sample_weights = compute_sample_weights(sample_uncertainty)
head_uncertainty = compute_head_uncertainty(logits_u)
head_weights = compute_head_weights(head_uncertainty)
loss_unsup = ssl_loss_unsupervised(logits_u, sample_weights, head_weights)
total_loss = loss_sup + loss_unsup
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
return total_loss.item(), loss_sup.item(), loss_unsup.item()import torch
import torch.nn.functional as F
from sklearn.metrics import accuracy_score
def evaluate(model, dataloader, device):
model.eval()
all_preds = []
all_targets = []
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
logits_list = model(x)
avg_logits = torch.mean(torch.stack(logits_list), dim=0)
preds = torch.argmax(avg_logits, dim=1)
all_preds.append(preds.cpu())
all_targets.append(y.cpu())
all_preds = torch.cat(all_preds)
all_targets = torch.cat(all_targets)
acc = accuracy_score(all_targets, all_preds)
return acc
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
import numpy as np
from ues_model import ChannelBasedEnsemble
from train_step import train_step
from eval_utils import evaluate
from torchvision.models import resnet18
# Configuration
num_classes = 10
num_epochs = 200
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Base Model
base_model = nn.Sequential(
nn.Flatten(),
nn.Linear(512, 128),
nn.ReLU()
)
# Model
feature_extractor = resnet18(pretrained=False)
feature_extractor.fc = nn.Identity()
model = ChannelBasedEnsemble(feature_extractor, num_heads=5, feature_dim=512, num_classes=num_classes).to(device)
# Optimizer
optimizer = optim.SGD(model.parameters(), lr=0.03, momentum=0.9, weight_decay=5e-4)
# Datasets and Loaders
transform_weak = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor()
])
transform_strong = transforms.Compose([
transforms.RandAugment(),
transforms.ToTensor()
])
transform_test = transforms.Compose([transforms.ToTensor()])
cifar10 = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_weak)
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
# Split labeled and unlabeled
labels_per_class = 4
labeled_indices = []
unlabeled_indices = []
targets = np.array(cifar10.targets)
for c in range(num_classes):
idx = np.where(targets == c)[0]
np.random.shuffle(idx)
labeled_indices.extend(idx[:labels_per_class])
unlabeled_indices.extend(idx[labels_per_class:])
labeled_set = Subset(datasets.CIFAR10(root='./data', train=True, transform=transform_weak), labeled_indices)
unlabeled_set = Subset(datasets.CIFAR10(root='./data', train=True, transform=transform_strong), unlabeled_indices)
test_loader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
labeled_loader = DataLoader(labeled_set, batch_size=32, shuffle=True, drop_last=True)
unlabeled_loader = DataLoader(unlabeled_set, batch_size=224, shuffle=True, drop_last=True)
# Training Loop
print("Starting training...")
for epoch in range(num_epochs):
model.train()
for (x_l, y_l), (x_u, _) in zip(labeled_loader, unlabeled_loader):
x_l, y_l = x_l.to(device), y_l.to(device)
x_u = x_u.to(device)
total_loss, l_sup, l_unsup = train_step(model, x_l, y_l, x_u, optimizer)
acc = evaluate(model, test_loader, device)
print(f"Epoch {epoch+1}/{num_epochs} | Loss: {total_loss:.4f} | Sup: {l_sup:.4f} | Unsup: {l_unsup:.4f} | Test Acc: {acc*100:.2f}%")
Pingback: Revolutionizing Medical Image Segmentation: SemSim's Semantic Breakthrough - aitrendblend.com