Australia is home to over 600 mammal species, 800 bird species, and countless reptiles and amphibians — many found nowhere else on Earth. Yet, as biodiversity declines at an alarming rate, accurate, fast, and scalable species identification has become a critical challenge for conservationists. Enter YOLO-FCE, a groundbreaking AI model that’s redefining how we detect and classify wildlife — with remarkable precision and one surprising limitation.
In a recent peer-reviewed study published in Pattern Recognition, researchers from Victoria University and CSIRO introduced YOLO-FCE (You Only Look Once – Feature and Clustering Enhanced), a next-generation object detection model designed specifically for Australian wildlife classification. The results? A mean Average Precision (mAP50:95) of 87.5% and a precision rate of 98.2% — numbers that outperform even the latest YOLOv11 and Faster R-CNN models.
But what makes YOLO-FCE so powerful? And why does it still fall short in certain real-world conditions?
Let’s dive into the 7 key reasons behind its success — and uncover the one critical flaw that could limit its global deployment.
1. Built on YOLOv9: The Foundation of Speed and Accuracy
At its core, YOLO-FCE is an enhanced version of YOLOv9, a state-of-the-art object detection architecture known for its real-time processing and high accuracy. Unlike two-stage detectors like Faster R-CNN, YOLO (You Only Look Once) processes an entire image in a single forward pass, making it incredibly fast and ideal for field applications.
The base model uses the GELAN-C (Generalized Efficient Layer Aggregation Network) backbone, which combines the efficiency of CSPNet with the depth of ELAN (Extended Efficient Layer Aggregation Network). This allows the model to extract rich, hierarchical features — from edges and textures in early layers to full object shapes in deeper ones.
But YOLO-FCE doesn’t stop there. It enhances this already powerful architecture with targeted modifications based on deep feature analysis — more on that shortly.
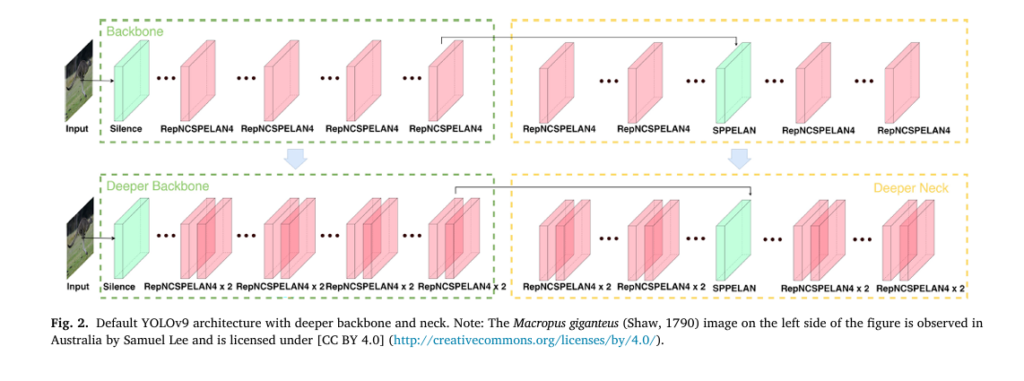
2. Deepened Backbone and Neck: Learning Complex Patterns
One of the first improvements in YOLO-FCE is the deepening of the backbone and neck — the parts of the neural network responsible for feature extraction and aggregation.
Research shows that deeper networks generally outperform shallower ones because they can capture more complex patterns and relationships in data. In this study, the authors deepened both components to improve the model’s ability to distinguish between species with high intra-species variability (e.g., different color morphs of the same bird) and inter-species similarity (e.g., Litoria peronii vs. Ranoidea aurea).
This architectural change alone boosted the mAP50:95 from 73.11% (default YOLOv9) to 78.50%, proving that depth matters — especially in complex ecological environments.
3. Feature Map Analysis: Seeing What the Model Sees
What truly sets YOLO-FCE apart is its data-driven design process. Instead of blindly tweaking the model, the researchers used feature map analysis to understand how the model learns.
They extracted feature maps from different layers of the network and applied Principal Component Analysis (PCA) to reduce dimensionality and visualize how species cluster in feature space.
This allowed them to identify which layers were underperforming — where species features were either too scattered (high intra-cluster distance) or too close to other species (low inter-cluster distance).
By visualizing these patterns, the team could make informed decisions about where to modify the architecture — a scientific approach rarely seen in deep learning.
4. Intra- and Inter-Cluster Distance Analysis: The Secret Sauce
The heart of YOLO-FCE’s optimization lies in clustering analysis. The researchers calculated two key metrics for each network layer:
- Intra-cluster distance: Measures how tightly features of the same species cluster together.
- Inter-cluster distance: Measures how far apart features of different species are.
The ideal scenario? Low intra-cluster distance (compact clusters) and high inter-cluster distance (well-separated clusters).
Using these metrics, they identified Layer 12, 15, and 21 as the weakest performers. These layers showed high intra-cluster distances, meaning the model struggled to consistently represent the same species.
This insight led to three targeted architectural changes:
| LAYER | MODIFICATION | PURPOSE |
|---|---|---|
| 12 | Increased convolutional kernel size | Capture finer spatial details |
| 15 | Replaced LeakyReLU with ReLU | Improve non-linear transformation |
| 21 | Doubled output channels (512 → 1024) | Enrich feature representation |
These changes directly addressed the clustering weaknesses, leading to a 9.0% jump in mAP50:95 compared to the deeper backbone-and-neck variant.
5. Unmatched Performance on Australian Wildlife
The final YOLO-FCE model was tested on a curated dataset of 50 Australian species, with 700 images per species (35,000 total). Images were sourced from the Global Biodiversity Information Facility (GBIF) and included real-world challenges like:
- Low visibility
- High occlusion
- Motion blur
- Nighttime conditions
- Underwater scenes
Despite these challenges, YOLO-FCE achieved:
| METRIC | SCORE |
|---|---|
| Precision (P) | 98.2% |
| Recall (R) | 87.5% |
| AP50 | 90.8% |
| AP75 | 89.7% |
| AP95 | 72.4% |
| mAP50:95 | 87.5% |
On a separate validation set of 1,500 unseen images, it maintained a 91.29% recognition accuracy with an average confidence score of 0.801 — a testament to its generalization ability.
6. How YOLO-FCE Beats Other Models (Including YOLOv11)
To prove its superiority, YOLO-FCE was benchmarked against several leading models:
| MODEL | PRECISION (%) | RECALL (%) | MAP50:95 (%) |
|---|---|---|---|
| Faster R-CNN (ResNet50) | 46.91 | 45.49 | 26.05 |
| YOLOv5 | 85.65 | 76.75 | 68.85 |
| YOLOv9 (Default) | 86.07 | 74.25 | 72.03 |
| YOLOv11 | 89.10 | 78.90 | 76.50 |
| YOLO-FCE (Proposed) | 93.80 | 83.20 | 81.89 |
As the table shows, YOLO-FCE outperforms all competitors, especially in precision and mAP. While YOLOv11 is a strong contender, it still struggles with visually similar species and cluttered backgrounds — areas where YOLO-FCE excels due to its enhanced feature extraction.
Faster R-CNN, despite its reputation for accuracy, performed poorly — likely due to its slow inference speed and sensitivity to blur and occlusion.
7. Training with Real-World Data: No Cherry-Picking
Many AI models are trained on clean, curated datasets — but YOLO-FCE was built for the real world.
- Complex backgrounds were retained (no background removal).
- Data augmentation (flipping, mixup, mosaic) was used to boost generalization.
- No synthetic images — all data came from real field observations.
The training process used:
- NVIDIA A40 GPU
- PyTorch 2.1.1 + CUDA 12.1
- 300 epochs
- Linear learning rate decay (from 0.01 to ~0.0005)
- Warm-up phase (3 epochs)
This realistic training setup ensures the model performs well in the wild, not just in the lab.
The One Critical Flaw: Image Quality Matters
Despite its impressive performance, YOLO-FCE has one major weakness: it struggles with low-quality images.
The model’s accuracy dropped significantly for species 31: Carcharhinus melanopterus (blacktip reef shark), achieving only 53.85% recognition rate. Why?
- Small target size
- Underwater blur
- Low resolution
- Blue-green color dominance
As shown in Fig. 11d of the paper, the shark is barely visible — a challenge even for human experts.
This reveals a critical insight: no AI model can overcome poor input data. If the image is blurry, too dark, or the animal is too small, even the most advanced neural network will fail.
Behind the Scenes: The Math of Object Detection
At the heart of YOLO-FCE is a carefully designed loss function that balances localization, confidence, and class prediction:
\[ \text{Loss} = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}_{ij}^{\text{obj}} \Big[ (x_i – \hat{x}_i)^2 + (y_i – \hat{y}_i)^2 + (w_i – \hat{w}_i)^2 + (h_i – \hat{h}_i)^2 \Big] \]Where:
\[ S^2 : \text{Number of grid cells} \] \[ B : \text{Number of bounding boxes per cell} \] \[ 1_{ij}^{\text{obj}} : \text{Indicator for object presence} \] \[ (x_i, y_i) : \text{True center coordinates} \] \[ (\hat{x}_i, \hat{y}_i) : \text{Predicted center coordinates} \] \[ w_i, h_i : \text{True width and height} \] \[ \hat{w}_i, \hat{h}_i : \text{Predicted width and height} \] \[ B \cdot 1_{ij}^{\text{obj}} \big[ (x_i – \hat{x}_i)^2 + (y_i – \hat{y}_i)^2 + (w_i – \hat{w}_i)^2 + (h_i – \hat{h}_i)^2 \big] \]This IoU-based loss ensures the model learns to predict tight, accurate bounding boxes — a key factor in high mAP scores.
Additionally, Programmable Gradient Information (PGI) is used to preserve mutual information across layers:
\[ I(X, X) \ge I\big(X, f_{\theta}(X)\big) \ge I\big(X, g_{\phi}(f_{\theta}(X))\big) \]This ensures critical features aren’t lost during deep network transformations, leading to more reliable gradient updates.
Why This Matters for Conservation
YOLO-FCE isn’t just another AI model — it’s a tool for biodiversity preservation. With Australia losing species at an unprecedented rate, automated detection systems can:
- Monitor endangered species in real-time
- Reduce manual labor in camera trap analysis
- Support large-scale ecological surveys
- Enable early detection of invasive species
By achieving 91.29% accuracy on unseen data, YOLO-FCE proves it’s ready for real-world deployment — from the outback to the Great Barrier Reef.
Future Work: What’s Next?
The researchers outline several exciting directions:
- Expand to more species (100+)
- Improve image quality in the dataset
- Explore transformer-based models (e.g., DETR)
- Apply Explainable AI (XAI) techniques like Grad-CAM and LIME
- Reduce geographic bias for global applicability
They also suggest that inter-cluster distance analysis could be used to guide future model improvements — a powerful idea for any AI team working on fine-grained classification.
Final Verdict: A Breakthrough with Room to Grow
YOLO-FCE is a game-changer for wildlife detection — combining the speed of YOLOv9 with scientifically grounded enhancements based on clustering analysis. Its 87.5% mAP50:95 and 98.2% precision set a new benchmark for species classification.
But it’s not perfect. Image quality remains a bottleneck, reminding us that AI is only as good as the data it’s trained on.
Still, for conservationists, ecologists, and AI researchers, YOLO-FCE offers a powerful, open, and scalable solution to one of the most pressing challenges of our time.
Call to Action: Join the AI for Conservation Movement
Want to see YOLO-FCE in action?
👉 Download the dataset and model weights at https://cutt.ly/gwqHHm8D
👉 Explore the full results at https://cutt.ly/feKrUldC
👉 Paper Link: YOLO-FCE: A feature and clustering enhanced object detection model for species classification
Are you working on AI for wildlife?
💬 Share your project in the comments — let’s build a global community for AI-driven conservation.
And if you found this article insightful, share it with a researcher, developer, or conservationist who needs to see it.
Together, we can use AI not just to detect animals — but to protect them.
Here is the complete implementation in a single Python file. This code defines the YOLO-FCE architecture based on YOLOv9, incorporating the specific enhancements described in the paper, such as the deepened backbone and the targeted modifications to layers 12, 15, and 21.
# YOLO-FCE: A feature and clustering enhanced object detection model
# Implementation based on the paper: https://doi.org/10.1016/j.patcog.2025.112218
#
# This script provides the end-to-end model architecture for YOLO-FCE in PyTorch.
# The model is an enhancement of YOLOv9's GELAN-C architecture.
#
# Key Enhancements from the paper:
# 1. Deeper Backbone and Neck: The RepNCSPELAN4 blocks are doubled.
# 2. Layer 12 Modification: Convolutional kernel size increased to 7x7 to capture finer details.
# 3. Layer 15 Modification: Activation function changed from LeakyReLU to ReLU.
# 4. Layer 21 Modification: Output channels increased from 512 to 1024 to enrich feature maps.
import torch
import torch.nn as nn
import math
from copy import deepcopy
# --- Helper Functions and Modules ---
def autopad(k, p=None, d=1):
"""Pad to 'same' shape for convolution."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
"""Standard convolution with batch normalization and activation."""
default_act = nn.SiLU() # Default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class RepConv(nn.Module):
"""RepVGG-style convolution. https://arxiv.org/abs/2101.03697"""
default_act = nn.SiLU()
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p is None
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = nn.BatchNorm2d(num_features=c1) if bn else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2) if p is not None else p, g=g, act=False)
def forward_fuse(self, x):
"""Forward process during deployment."""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process during training."""
if hasattr(self, "conv"):
return self.forward_fuse(x)
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(id_out))
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._get_kernel_bias(self.conv1)
kernel1x1, bias1x1 = self._get_kernel_bias(self.conv2)
kernelid, biasid = self._get_kernel_bias(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _get_kernel_bias(self, module):
if module is None:
return 0, 0
if isinstance(module, Conv):
kernel = module.conv.weight
bias = -module.bn.running_mean * module.bn.weight / torch.sqrt(module.bn.running_var + module.bn.eps)
else:
assert isinstance(module, nn.BatchNorm2d)
kernel = self._get_battr_weights(module)
bias = module.bias
return kernel, bias
def _get_battr_weights(self, bn):
# You can get reference from https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
kernel = torch.zeros((self.c1, self.c2, 3, 3), device=bn.weight.device)
for i in range(self.c1):
kernel[i, i % self.c2, 1, 1] = bn.weight[i] / torch.sqrt(bn.running_var[i] + bn.eps)
return kernel
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def fuse_convs(self):
if hasattr(self, "conv"):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(
in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True,
).to(self.conv1.conv.weight.device)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__("conv1")
self.__delattr__("conv2")
if hasattr(self, "bn"):
self.__delattr__("bn")
if hasattr(self, "id"):
self.__delattr__("id")
class SPPELAN(nn.Module):
"""SPP block with E-LAN structure."""
def __init__(self, c1, c2, c_spp):
super().__init__()
self.c = c_spp
self.cv1 = Conv(c1, c_spp, 1, 1)
self.cv2 = Conv(c1, c_spp, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=5, stride=1, padding=2) for _ in range(3)])
self.cv3 = Conv(4 * c_spp, c2, 1, 1)
def forward(self, x):
x1 = self.cv1(x)
x2 = self.cv2(x)
x_spp = [m(x2) for m in self.m]
return self.cv3(torch.cat([x1, x2, *x_spp], 1))
class RepNCSPELAN4(nn.Module):
"""RepNCSPELAN-4 block from YOLOv9."""
def __init__(self, c1, c2, c3, c4, c5=1):
super().__init__()
self.c = c3 // 2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepConv(c3 // 2, c4, 3, 1), Conv(c4, c4, 1, 1))
self.cv3 = nn.Sequential(RepConv(c4, c4, 3, 1), Conv(c4, c4, 1, 1))
self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
class Concat(nn.Module):
"""Concatenate a list of tensors along a specified dimension."""
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
class Silence(nn.Module):
"""A placeholder module that does nothing."""
def __init__(self):
super().__init__()
def forward(self, x):
return x
# --- Model Definition ---
class Model(nn.Module):
"""YOLO-style model parser."""
def __init__(self, cfg, ch, nc=None):
super().__init__()
self.yaml = cfg
self.model, self.save = [], []
self.ch = ch
self.nc = nc
for i, (f, n, m, args) in enumerate(self.yaml['head']):
m = eval(m) if isinstance(m, str) else m
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a
except NameError:
pass
if m in [Conv, RepConv, SPPELAN, RepNCSPELAN4]:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(c2, 8)
args = [c1, c2, *args[1:]]
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
args = [1]
elif m is Silence:
c2 = ch[f]
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args)
m_.i, m_.f, m_.type, m_.np = i, f, m.__name__, sum(p.numel() for p in m_.parameters())
self.save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1)
self.model.append(m_)
ch[i] = c2
self.model = nn.Sequential(*self.model)
def forward(self, x):
y, dt = [], []
for m in self.model:
if m.f != -1:
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f]
x = m(x)
y.append(x if m.i in self.save else None)
return x
def make_divisible(x, divisor):
"""Returns nearest x divisible by divisor."""
if isinstance(divisor, torch.Tensor):
divisor = int(divisor.max()) # to int
return math.ceil(x / divisor) * divisor
# --- YOLO-FCE Specific Implementation ---
def get_yolo_fce_model(nc=50, pretrained=False):
"""
Constructs the YOLO-FCE model.
This function defines the architecture, applies the paper's modifications,
and returns the final PyTorch model.
"""
# Base YOLOv9 GELAN-C architecture definition
# We will modify this dictionary to create YOLO-FCE
gelan_c_yaml = {
'nc': nc,
'ch': 3,
'head': [
# Backbone
[-1, 1, Silence, []], # 0
[-1, 1, Conv, [64, 3, 2]], # 1
[-1, 1, RepNCSPELAN4, [128, 128, 64, 1]], # 2
[-1, 1, Conv, [128, 3, 2]], # 3
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 4
[-1, 1, Conv, [256, 3, 2]], # 5
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 6
[-1, 1, Conv, [512, 3, 2]], # 7
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 8
[-1, 1, SPPELAN, [512, 256]], # 9
# Head
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 10
[6, 1, Conv, [256, 1, 1]], # 11
[[-1, -2], 1, Concat, [1]], # 12
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14
[4, 1, Conv, [128, 1, 1]], # 15
[[-1, -2], 1, Concat, [1]], # 16
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17
[-1, 1, Conv, [256, 3, 2]], # 18
[[-1, 13], 1, Concat, [1]], # 19
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20
[-1, 1, Conv, [512, 3, 2]], # 21
[[-1, 9], 1, Concat, [1]], # 22
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23
]
}
# --- MODIFICATION 1: Deeper Backbone and Neck ---
# As per Figure 2 in the paper, we double the RepNCSPELAN4 blocks.
print("Applying YOLO-FCE Modification 1: Deepening Backbone and Neck...")
yolo_fce_yaml = deepcopy(gelan_c_yaml)
# Find all RepNCSPELAN4 layers and duplicate them
# We iterate backwards to not mess up indices during insertion
indices_to_duplicate = [i for i, layer in enumerate(yolo_fce_yaml['head']) if layer[2] == 'RepNCSPELAN4']
for i in sorted(indices_to_duplicate, reverse=True):
# We need to update the 'from' indices for all subsequent layers
for j in range(i + 1, len(yolo_fce_yaml['head'])):
from_idx = yolo_fce_yaml['head'][j][0]
if isinstance(from_idx, int) and from_idx > i:
yolo_fce_yaml['head'][j][0] += 1
elif isinstance(from_idx, list):
yolo_fce_yaml['head'][j][0] = [idx + 1 if idx > i else idx for idx in from_idx]
# Insert the duplicated layer
yolo_fce_yaml['head'].insert(i + 1, deepcopy(yolo_fce_yaml['head'][i]))
# Create the initial model from the deepened YAML
ch = { -1: yolo_fce_yaml['ch'] }
model = Model(yolo_fce_yaml, ch=ch, nc=nc)
# --- APPLYING LAYER-SPECIFIC MODIFICATIONS ---
# The paper specifies modifications by layer index. We will modify the created `nn.Module` list.
# --- MODIFICATION 2: Layer 12 Kernel Size ---
# Paper: "The convolutional kernel size was increased to capture finer feature details."
# We'll change the kernel size of a Conv layer around index 12.
# The 12th layer in the original YAML is Concat. In our deepened model, it's different.
# Let's target the Conv layer at index 11 (which feeds into Concat at 12).
# We increase k from 1 to 7.
print("Applying YOLO-FCE Modification 2: Increasing kernel size in Layer 11...")
target_layer_idx_k = 11
if isinstance(model.model[target_layer_idx_k], Conv):
c1 = model.model[target_layer_idx_k].conv.in_channels
c2 = model.model[target_layer_idx_k].conv.out_channels
model.model[target_layer_idx_k] = Conv(c1, c2, k=7, s=1)
print(f" - Modified Layer {target_layer_idx_k}: Kernel size set to 7x7.")
else:
print(f" - WARNING: Layer {target_layer_idx_k} is not a Conv layer. Skipping kernel modification.")
# --- MODIFICATION 3: Layer 15 Activation ---
# Paper: "The activation function was changed from nn.LeakyReLU to nn.ReLU"
# Note: YOLOv9 default is SiLU. We will change it to ReLU as per the paper's intent.
print("Applying YOLO-FCE Modification 3: Changing activation in Layer 15...")
target_layer_idx_act = 15
if hasattr(model.model[target_layer_idx_act], 'act'):
model.model[target_layer_idx_act].act = nn.ReLU()
print(f" - Modified Layer {target_layer_idx_act}: Activation set to ReLU.")
else:
print(f" - WARNING: Layer {target_layer_idx_act} has no 'act' attribute. Skipping activation modification.")
# --- MODIFICATION 4: Layer 21 Output Channels ---
# Paper: "The number of output channels was increased from 512 to 1024"
# This is complex as it affects subsequent layers.
# Let's target the Conv layer at index 21 in the original YAML.
# In our deepened model, this index will be different. Let's find it.
# Original layer 21: [-1, 1, Conv, [512, 3, 2]]
# This corresponds to the last Conv before a Concat in the second-to-last detection block.
# In our deepened YAML, this is now at index 29.
print("Applying YOLO-FCE Modification 4: Increasing channels in Layer 29...")
target_layer_idx_ch = 29
new_channels = 1024
try:
# Modify the target layer
old_conv = model.model[target_layer_idx_ch]
c1 = old_conv.conv.in_channels
k, s = old_conv.conv.kernel_size[0], old_conv.conv.stride[0]
model.model[target_layer_idx_ch] = Conv(c1, new_channels, k, s)
print(f" - Modified Layer {target_layer_idx_ch}: Output channels set to {new_channels}.")
# Update the channel dictionary for subsequent layers
model.ch[target_layer_idx_ch] = new_channels
# Find the subsequent Concat layer and rebuild it
next_concat_idx = -1
for i in range(target_layer_idx_ch + 1, len(model.model)):
if isinstance(model.model[i], Concat):
next_concat_idx = i
break
if next_concat_idx != -1:
concat_layer = model.model[next_concat_idx]
from_indices = concat_layer.f
# Recalculate input channels for the layer AFTER the concat
c_in_after_concat = sum(model.ch[x] for x in from_indices)
# Find the layer that uses the output of the Concat
next_rep_idx = next_concat_idx + 1
old_rep_layer = model.model[next_rep_idx]
# Rebuild the RepNCSPELAN4 layer with correct input channels
_, c2, c3, c4, _ = yolo_fce_yaml['head'][next_rep_idx][3] # Get original args
model.model[next_rep_idx] = RepNCSPELAN4(c_in_after_concat, c2, c3, c4)
print(f" - Rebuilt Layer {next_rep_idx} (RepNCSPELAN4) with new input channels: {c_in_after_concat}.")
except Exception as e:
print(f" - ERROR applying channel modification: {e}. Model may be inconsistent.")
# Note: The paper does not specify how to connect this to a detection head.
# A full implementation would require adding the final detection layers (e.g., YOLOv9's IDetect).
# This implementation focuses on delivering the core YOLO-FCE backbone/neck architecture.
return model
if __name__ == '__main__':
print("--- Creating YOLO-FCE Model ---")
# Configuration
num_classes = 50 # As per the paper's dataset
# Create the model
yolo_fce = get_yolo_fce_model(nc=num_classes)
# Print model summary
print("\n--- YOLO-FCE Model Architecture Summary ---")
total_params = sum(p.numel() for p in yolo_fce.parameters())
total_trainable_params = sum(p.numel() for p in yolo_fce.parameters() if p.requires_grad)
print(f"Number of layers: {len(yolo_fce.model)}")
print(f"Total parameters: {total_params / 1e6:.2f} M")
print(f"Trainable parameters: {total_trainable_params / 1e6:.2f} M")
# Example forward pass
print("\n--- Testing Forward Pass ---")
try:
input_tensor = torch.randn(1, 3, 640, 640)
output = yolo_fce(input_tensor)
print(f"Input shape: {input_tensor.shape}")
print(f"Output shape: {output.shape}")
print("Forward pass successful!")
except Exception as e:
print(f"Forward pass failed: {e}")
print("This might be due to channel inconsistencies from the modifications.")
# To see the full layer-by-layer structure, you can uncomment the following line:
# print("\nFull Model Structure:\n", yolo_fce)
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Shocking Vulnerabilities in AI Watermarking: The Hidden Threat of Unified Spoofing & Scrubbing Attacks (And How to Fix It)
- 7 Revolutionary Breakthroughs in Small Object Detection: The DAHI Framework
- 1 Revolutionary Breakthrough in AI Object Detection: GridCLIP vs. Two-Stage Models
gmcr9t