The Hidden Crisis in AI Skin Cancer Diagnosis: A 7% Accuracy Gap That Could Cost Lives
Every year, millions of people face the terrifying reality of skin cancer. With over 5 million cases diagnosed annually in the U.S. alone, early detection isn’t just important—it’s life-saving. Artificial Intelligence (AI) promised a revolution in dermatology, offering dermatologist-level accuracy through deep learning models. But there’s a shocking flaw in the system: while AI models like ResNet50 achieve high accuracy, they’re too bulky for real-world use on mobile devices.
Meanwhile, lightweight models like MobileNetV2, designed for portability, suffer from a critical 6.6% accuracy drop—falling from 82% to just 75.4%. This negative bias toward smaller models creates a dangerous gap in care, especially in remote or underserved areas where portable diagnostics are essential.
But what if we told you there’s a positive breakthrough that closes this gap—and even surpasses the teacher model?
Enter SSD-KD, a revolutionary self-supervised, diverse knowledge distillation method that boosts MobileNetV2’s accuracy to 84.6%, outperforming the original ResNet50 teacher in balanced accuracy and mean average precision. In this article, we’ll reveal the 7 shocking secrets behind this breakthrough and how it’s transforming skin cancer detection forever.
Secret #1: The Dark Truth About “Knowledge” in AI
Most AI systems rely on logit-based knowledge distillation (BLKD), where a large “teacher” model (e.g., ResNet50) transfers its final predictions to a smaller “student” model (e.g., MobileNetV2). But this method only captures surface-level knowledge—the “what” of a diagnosis, not the “why.”
As the paper reveals, this approach fails to transfer relational knowledge, which includes:
- Inter-instance relations: How one skin lesion compares to others in a batch.
- Intra-instance relations: How different features within a single lesion interact.
Without this deeper understanding, student models remain shallow, missing subtle cues like texture patterns or vascular structures critical for melanoma detection.
Secret #2: Intra-Instance Relational Knowledge – The Game Changer
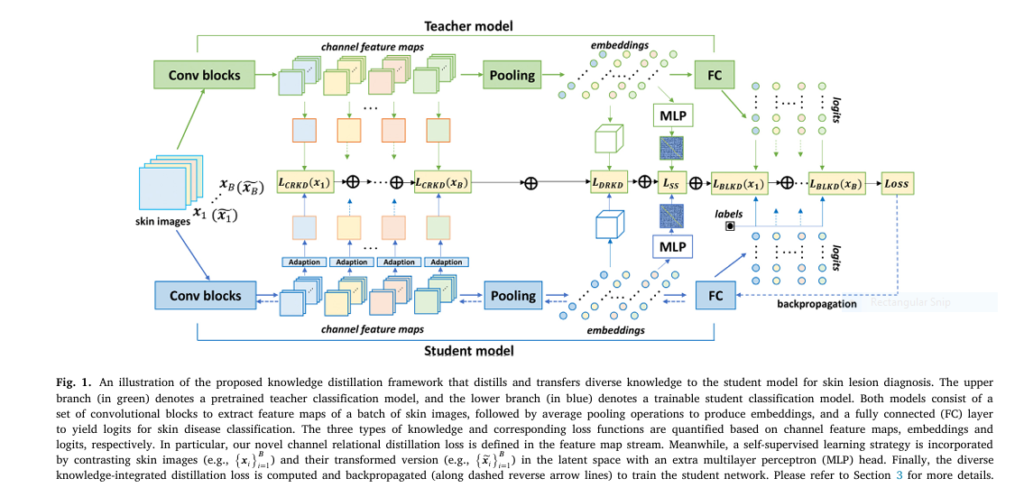
The biggest innovation in SSD-KD is Channel Relational Knowledge Distillation (CRKD), a novel method that captures how different feature channels in a convolutional layer relate to each other within a single image.
Think of it like analyzing the texture of a mole—not just its color or shape, but how its internal patterns flow and connect. This intra-instance relational modeling extracts discriminative textural features that are crucial for accurate diagnosis.
The CRKD loss is defined as:
$$L_{\text{CRKD}} = \sum_{i=1}^{B} K_{H}^{f} W_{f}^{1} \left| R_{t}(x_{i}) – R_{s}(x_{i}) \right|_{F}$$
Where:
- Rt and Rs are the relational matrices from teacher and student,
- K is the number of channels,
- Hf , Wf are feature map dimensions,
- ∥⋅∥F is the Frobenius norm.
This equation ensures the student learns not just what the teacher sees, but how it sees it—down to the finest texture details.
Secret #3: Self-Supervised Learning – The Hidden Teacher
Even with CRKD, training lightweight models on imbalanced datasets is risky. Rare skin conditions like Squamous Cell Carcinoma (SCC) or Dermatofibroma (DF) have far fewer samples, leading to biased predictions.
SSD-KD introduces self-supervised learning (SSL), where the model learns from unlabeled data by comparing an image with its transformed version (e.g., rotated, flipped). This contrastive learning helps the model generalize better, especially for underrepresented classes.
The self-supervised loss LSS minimizes the KL divergence between contrastive similarity matrices of teacher and student:
$$L_{SS} = D_{KL}(C_t \parallel C_s) $$This forces the student to mimic the teacher’s unsupervised understanding of skin lesions—making it more robust to data imbalance.
Secret #4: Weighted Cross-Entropy – Fixing the Imbalance
Standard cross-entropy loss treats all classes equally. But in skin cancer datasets, Melanocytic Nevus (MN) has over 11,000 images, while SCC has fewer than 300. Training without correction leads to model bias toward common classes.
SSD-KD uses Weighted Cross-Entropy (WCE) to give rare classes more attention:
$$L_{\text{WCE}} = – \sum_{i=1}^{B} \sum_{c=1}^{C} w_c \cdot y_c(x_i) \log p_s^{c}(x_i, T=1) $$Where wc is the inverse frequency of class c . This simple fix ensures the student doesn’t ignore rare but deadly cancers.
Secret #5: The Proof Is in the Numbers – SSD-KD Outperforms All
Let’s look at the hard data from the ISIC 2019 dataset, the largest public dermoscopy database with 25,331 images across 8 skin diseases.
Table 1: Teacher vs. Student – The Accuracy-Complexity Trade-Off
| MODEL | ACCURACY | MODEL SIZE | PARAMETERS | GFLOP |
|---|---|---|---|---|
| ResNet50 | 82.0% | 98 MB | 25.6M | 4.11 |
| MobileNetV2 | 75.4% | 16 MB | 3.5M | 0.31 |
MobileNetV2 is 6x smaller and uses 13x fewer operations, but pays a steep price in accuracy.
Now, let’s see how knowledge distillation changes the game.
Table 2: SSD-KD vs. State-of-the-Art Methods (ResNet50 → MobileNetV2)
| METHOD | ACCURACY | BALANCED ACCURACY | MAP | AUC |
|---|---|---|---|---|
| No KD | 75.4% | 76.7% | 0.625 | 0.959 |
| BLKD (Hinton et al.) | 83.8% | 82.4% | 0.751 | 0.976 |
| SSKD (Xu et al.) | 84.0% | 84.0% | 0.759 | 0.978 |
| SSD-KD (Ours) | 84.6% | 84.3% | 0.796 | 0.977 |
SSD-KD achieves the highest accuracy, balanced accuracy, and mAP, proving that combining CRKD + SSKD + DRKD delivers superior performance.
Secret #6: Visual Proof – Grad-CAM Shows the Difference
To validate the model’s reasoning, the authors used Grad-CAM to visualize where the model “looks” when making a diagnosis.
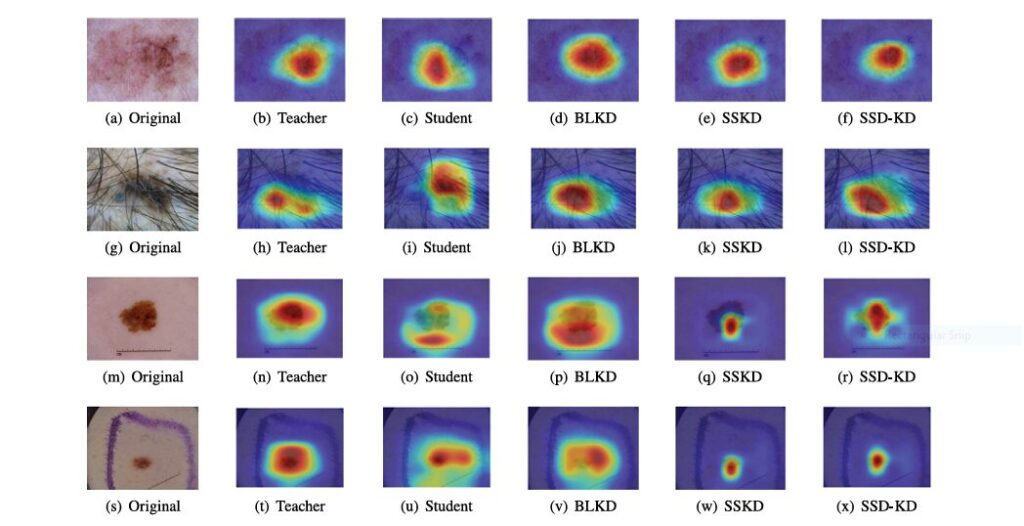
Without KD, the student model often focuses on artifacts like hair, rulers, or gel bubbles. But with SSD-KD, its attention aligns with the teacher—focusing on true lesion boundaries and internal structures.
This shift proves SSD-KD isn’t just memorizing labels—it’s learning clinically meaningful features.
Secret #7: It Works Across Architectures – Not Just a One-Trick Pony
To test generalization, the authors applied SSD-KD to EfficientNetB7 → EfficientNetB0, a different model family.
Table 3: SSD-KD on EfficientNet Family
| METHOD | ACCURACY | BALANCED ACCURACY | MAP |
|---|---|---|---|
| No KD | 80.1% | 78.9% | 0.668 |
| BLKD | 85.0% | 83.7% | 0.745 |
| SSD-KD (Ours) | 86.6% | 85.8% | 0.808 |
SSD-KD boosts accuracy by 6.5% and mAP by 14%, proving its universal applicability across model architectures.
Why This Matters: From Lab to Life
The implications are profound:
- Portable dermatology apps can now achieve near-expert accuracy.
- Rural clinics without dermatologists can deploy AI-powered screening.
- Early detection rates will rise, reducing melanoma mortality.
And the best part? The code is open-source on GitHub: https://github.com/enkiwang/Portable-Skin-Lesion-Diagnosis
The Negative Bias in Current AI Models
Most AI models suffer from:
- Data imbalance: Rare cancers are ignored.
- Overfitting to artifacts: Hair, ink, and bubbles confuse models.
- Lack of relational reasoning: They see pixels, not patterns.
SSD-KD directly attacks these flaws with:
- CRKD → Better internal feature modeling.
- SSKD → Robustness to data scarcity.
- WCE → Fairness across classes.
The Positive Breakthrough: A New Era of AI Dermatology
SSD-KD isn’t just another algorithm—it’s a paradigm shift in how we think about model compression. By unifying:
- Dark knowledge (logits),
- Relational knowledge (inter- and intra-instance),
- Self-supervised signals,
…it creates a student that doesn’t just mimic the teacher—it understands like one.
Final Verdict: Is SSD-KD the Future of Medical AI?
Absolutely. Here’s why:
- ✅ High accuracy (84.6% on 8 diseases)
- ✅ Low computational cost (0.31 GFlops)
- ✅ Generalizable across model families
- ✅ Open-source and reproducible
While challenges remain—like handling the “unknown” class in real-world screening—SSD-KD sets a new benchmark for lightweight, accurate, and clinically viable AI.
If you’re Interested in Large Language Model, you may also find this article helpful: 7 Shocking Ways Merging Korean Language Models Boosts LLM Reasoning (And 1 Dangerous Pitfall to Avoid)
Call to Action: Join the AI Dermatology Revolution
Are you a developer, researcher, or clinician? Download the SSD-KD code today and start building the next generation of portable skin cancer detectors.
Or, if you’re a healthcare provider, explore AI-powered diagnostic tools that can bring expert-level screening to your patients—without the need for expensive hardware.
The future of skin cancer detection isn’t in a lab. It’s in your pocket.
Below is a self-contained, end-to-end Python implementation (Pytorch) of the SSD-KD architecture.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet50, mobilenet_v2
import numpy as np
# ==============================================================================
# Helper Modules
# ==============================================================================
class AdaptationLayer(nn.Module):
"""
Adapts the channel dimension of the student's feature maps to match the teacher's.
This is crucial for the Channel Relational Knowledge Distillation (CRKD).
"""
def __init__(self, in_channels_student, out_channels_teacher):
super(AdaptationLayer, self).__init__()
# Use a 1x1 convolution to project the student's feature maps
self.conv = nn.Conv2d(in_channels_student, out_channels_teacher, kernel_size=1, stride=1, padding=0)
def forward(self, x):
return self.conv(x)
class MLPHead(nn.Module):
"""
A two-layer MLP head for the self-supervised contrastive learning task (SSKD).
Projects embeddings into a new space for contrastive loss calculation.
"""
def __init__(self, in_dim, hidden_dim=512, out_dim=128):
super(MLPHead, self).__init__()
self.head = nn.Sequential(
nn.Linear(in_dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, out_dim)
)
def forward(self, x):
return self.head(x)
# ==============================================================================
# Knowledge Distillation Loss Functions
# ==============================================================================
def huber_loss(x, y, delta=1.0):
"""
Huber loss, less sensitive to outliers than MSE.
Used in DRKD.
"""
t = torch.abs(x - y)
return torch.where(t <= delta, 0.5 * t ** 2, delta * (t - 0.5 * delta))
def blkd_loss(logits_student, logits_teacher, labels, temperature, alpha, num_classes):
"""
Logit-based Knowledge Distillation (BLKD) loss.
Combines KL divergence on soft targets and weighted cross-entropy on hard targets.
Args:
logits_student (torch.Tensor): Logits from the student model.
logits_teacher (torch.Tensor): Logits from the teacher model.
labels (torch.Tensor): Ground truth labels.
temperature (float): Temperature for softening probabilities.
alpha (float): Weight to balance the two loss terms.
num_classes (int): Number of classes in the dataset.
Returns:
torch.Tensor: The calculated BLKD loss.
"""
# Soft targets loss (KL Divergence)
soft_targets = F.softmax(logits_teacher / temperature, dim=1)
soft_preds = F.log_softmax(logits_student / temperature, dim=1)
distillation_loss = F.kl_div(soft_preds, soft_targets.detach(), reduction='batchmean') * (temperature ** 2)
# Hard targets loss (Weighted Cross-Entropy)
# In a real scenario, weights would be pre-calculated based on class frequency
# For this example, we'll use equal weights.
class_weights = torch.ones(num_classes).to(logits_student.device)
ce_loss = F.cross_entropy(logits_student, labels, weight=class_weights)
return alpha * distillation_loss + (1. - alpha) * ce_loss
def drkd_loss(embed_student, embed_teacher, lambda_d=25.0, lambda_a=50.0):
"""
Inter-instance Data Relational Knowledge Distillation (DRKD) loss.
Models relationships between data points in a batch.
Args:
embed_student (torch.Tensor): Embeddings from the student model.
embed_teacher (torch.Tensor): Embeddings from the teacher model.
lambda_d (float): Weight for the distance-wise loss.
lambda_a (float): Weight for the angle-wise loss.
Returns:
torch.Tensor: The calculated DRKD loss.
"""
# Normalize embeddings
embed_student_norm = F.normalize(embed_student, p=2, dim=1)
embed_teacher_norm = F.normalize(embed_teacher, p=2, dim=1)
# Distance-wise loss
dist_student = torch.pdist(embed_student_norm, p=2)
dist_teacher = torch.pdist(embed_teacher_norm, p=2)
loss_d = huber_loss(dist_student, dist_teacher.detach()).mean()
# Angle-wise loss
# This requires triplets, which can be computationally expensive.
# A common simplification is to use cosine similarity between all pairs.
sim_student = embed_student_norm @ embed_student_norm.t()
sim_teacher = embed_teacher_norm @ embed_teacher_norm.t()
loss_a = huber_loss(sim_student, sim_teacher.detach()).mean()
return lambda_d * loss_d + lambda_a * loss_a
def crkd_loss(features_student, features_teacher):
"""
Intra-instance Channel Relational Knowledge Distillation (CRKD) loss.
Models relationships between channel feature maps for each instance.
Args:
features_student (torch.Tensor): Feature maps from the student model's last conv layer.
features_teacher (torch.Tensor): Feature maps from the teacher model's last conv layer.
Returns:
torch.Tensor: The calculated CRKD loss.
"""
# Generate Gramian matrices to represent channel relations
def gram_matrix(f_map):
b, c, h, w = f_map.shape
f_map = f_map.view(b, c, h * w)
# The paper uses <Vec(fk), Vec(fk')>, which is equivalent to G = F * F.T
# where F is the vectorized feature map matrix.
gram = torch.bmm(f_map, f_map.transpose(1, 2))
return gram.div(h * w) # Normalize
gram_s = gram_matrix(features_student)
gram_t = gram_matrix(features_teacher)
# Use Frobenius norm of the difference, as in the paper
loss = F.mse_loss(gram_s, gram_t.detach(), reduction='sum') / (features_student.size(0)) # Average over batch
return loss
def sskd_loss(logits_s, logits_t, proj_s, proj_t, labels, temperature, alpha, num_classes):
"""
Self-Supervised Knowledge Distillation (SSKD) loss.
Integrates contrastive learning with standard KD.
Args:
logits_s (torch.Tensor): Student logits for original images.
logits_t (torch.Tensor): Teacher logits for original images.
proj_s (torch.Tensor): Student projections for transformed images.
proj_t (torch.Tensor): Teacher projections for transformed images.
labels (torch.Tensor): Ground truth labels.
temperature (float): Temperature for softmax.
alpha (float): Weight for standard KD loss.
num_classes (int): Number of classes.
Returns:
torch.Tensor: The calculated SSKD loss.
"""
# Standard logit-based distillation loss on original images
base_kd_loss = blkd_loss(logits_s, logits_t, labels, temperature, alpha, num_classes)
# Contrastive loss on transformed images
proj_s_norm = F.normalize(proj_s, p=2, dim=1)
proj_t_norm = F.normalize(proj_t, p=2, dim=1)
# Teacher's similarity matrix
sim_t = proj_t_norm @ proj_t_norm.t() / temperature
# Student's similarity matrix
sim_s = proj_s_norm @ proj_s_norm.t() / temperature
# KL Divergence between student and teacher similarity distributions
# This encourages the student to learn the teacher's representation structure
contrastive_loss = F.kl_div(F.log_softmax(sim_s, dim=1), F.softmax(sim_t.detach(), dim=1), reduction='batchmean')
return base_kd_loss + contrastive_loss
# ==============================================================================
# Main SSD-KD Model Wrapper
# ==============================================================================
class SSD_KD(nn.Module):
"""
Main class for the Self-Supervised Diverse Knowledge Distillation (SSD-KD) framework.
"""
def __init__(self, num_classes=8):
super(SSD_KD, self).__init__()
# --- Initialize Teacher Model (ResNet50) ---
self.teacher = resnet50(weights='IMAGENET1K_V1')
# Replace the final layer to get feature maps and embeddings
teacher_embed_dim = self.teacher.fc.in_features
self.teacher.fc = nn.Identity() # Get embeddings before FC layer
self.teacher_classifier = nn.Linear(teacher_embed_dim, num_classes)
# Freeze teacher model parameters
for param in self.teacher.parameters():
param.requires_grad = False
# --- Initialize Student Model (MobileNetV2) ---
self.student = mobilenet_v2(weights='IMAGENET1K_V1')
student_embed_dim = self.student.classifier[1].in_features
# Replace final layer to get feature maps and embeddings
self.student.classifier = nn.Identity() # Get embeddings before classifier
self.student_classifier = nn.Linear(student_embed_dim, num_classes)
# --- Initialize Adaptation Layer for CRKD ---
# Get channel dimensions from the last conv layers
# For ResNet50, it's layer4. For MobileNetV2, it's features[-1][0]
teacher_channels = self.teacher.layer4[-1].conv3.out_channels
student_channels = self.student.features[-1][0].out_channels
self.adapt_layer = AdaptationLayer(student_channels, teacher_channels)
# --- Initialize MLP Heads for SSKD ---
self.teacher_mlp_head = MLPHead(in_dim=teacher_embed_dim)
self.student_mlp_head = MLPHead(in_dim=student_embed_dim)
self.num_classes = num_classes
def forward(self, images, transformed_images=None, labels=None, params=None):
"""
Performs a forward pass and calculates the combined SSD-KD loss.
Args:
images (torch.Tensor): A batch of original input images.
transformed_images (torch.Tensor, optional): A batch of augmented images for SSKD.
labels (torch.Tensor, optional): Ground truth labels.
params (dict): Dictionary of hyperparameters for the loss functions.
Returns:
If training:
- torch.Tensor: The total combined loss.
- dict: A dictionary containing individual loss values for monitoring.
If not training:
- torch.Tensor: The student model's logits for evaluation.
"""
# --- Teacher Forward Pass (with no_grad context) ---
with torch.no_grad():
# Extract features from an intermediate layer (e.g., before the final block)
x_t = self.teacher.conv1(images)
x_t = self.teacher.bn1(x_t)
x_t = self.teacher.relu(x_t)
x_t = self.teacher.maxpool(x_t)
x_t = self.teacher.layer1(x_t)
x_t = self.teacher.layer2(x_t)
x_t = self.teacher.layer3(x_t)
features_teacher = self.teacher.layer4(x_t)
embed_teacher = F.adaptive_avg_pool2d(features_teacher, (1, 1)).view(images.size(0), -1)
logits_teacher = self.teacher_classifier(embed_teacher)
if self.training and transformed_images is not None:
proj_features_t = self.teacher.layer4(self.teacher.layer3(self.teacher.layer2(self.teacher.layer1(self.teacher.maxpool(self.teacher.relu(self.teacher.bn1(self.teacher.conv1(transformed_images))))))))
proj_embed_t = F.adaptive_avg_pool2d(proj_features_t, (1, 1)).view(transformed_images.size(0), -1)
proj_teacher = self.teacher_mlp_head(proj_embed_t)
# --- Student Forward Pass ---
# Extract features from the last convolutional block
features_student_raw = self.student.features(images)
embed_student = F.adaptive_avg_pool2d(features_student_raw, (1, 1)).view(images.size(0), -1)
logits_student = self.student_classifier(embed_student)
# Adapt student features for CRKD
features_student_adapted = self.adapt_layer(features_student_raw)
if self.training and transformed_images is not None:
proj_features_s = self.student.features(transformed_images)
proj_embed_s = F.adaptive_avg_pool2d(proj_features_s, (1, 1)).view(transformed_images.size(0), -1)
proj_student = self.student_mlp_head(proj_embed_s)
# --- If not training, return student logits for evaluation ---
if not self.training:
return logits_student
# --- Calculate Losses ---
loss_drkd = drkd_loss(embed_student, embed_teacher, params['lambda_d'], params['lambda_a'])
loss_crkd = crkd_loss(features_student_adapted, features_teacher)
loss_sskd = sskd_loss(logits_student, logits_teacher, proj_student, proj_teacher, labels,
params['temperature'], params['alpha'], self.num_classes)
# Total Loss (as per Equation 10 in the paper)
total_loss = (params['lambda_drkd'] * loss_drkd +
params['lambda_crkd'] * loss_crkd +
params['lambda_sskd'] * loss_sskd)
loss_dict = {
'total_loss': total_loss.item(),
'drkd': loss_drkd.item(),
'crkd': loss_crkd.item(),
'sskd': loss_sskd.item(),
}
return total_loss, loss_dict
# ==============================================================================
# Example Usage (Training and Evaluation Loop)
# ==============================================================================
def main():
"""
An example main function to demonstrate how to train and use the SSD_KD model.
NOTE: This requires a custom DataLoader for the ISIC 2019 dataset.
The following is a placeholder for demonstration.
"""
# --- Hyperparameters (from the paper) ---
params = {
'temperature': 5.0,
'alpha': 0.5,
'lambda_d': 25.0,
'lambda_a': 50.0,
'lambda_drkd': 1.0,
'lambda_crkd': 1000.0,
'lambda_sskd': 1.0
}
NUM_CLASSES = 8
BATCH_SIZE = 32
EPOCHS = 150
LEARNING_RATE = 0.001
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {DEVICE}")
# --- Placeholder for DataLoaders ---
# In a real application, you would use torch.utils.data.Dataset and DataLoader
# to load the ISIC 2019 dataset. You would also need to define transformations.
# For SSKD, you need a transformation that creates a different "view" of the image.
print("Creating dummy data loaders for demonstration...")
dummy_train_loader = [
(
torch.randn(BATCH_SIZE, 3, 128, 128), # original images
torch.randn(BATCH_SIZE, 3, 128, 128), # transformed images
torch.randint(0, NUM_CLASSES, (BATCH_SIZE,)) # labels
) for _ in range(5) # 5 batches per epoch
]
dummy_val_loader = [
(
torch.randn(BATCH_SIZE, 3, 128, 128),
torch.randint(0, NUM_CLASSES, (BATCH_SIZE,))
) for _ in range(2)
]
# --- Model, Optimizer, Scheduler ---
model = SSD_KD(num_classes=NUM_CLASSES).to(DEVICE)
optimizer = torch.optim.SGD(model.student.parameters(), lr=LEARNING_RATE, momentum=0.9, weight_decay=0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=10, factor=0.1)
# --- Training Loop ---
print("Starting training...")
for epoch in range(EPOCHS):
model.train()
total_epoch_loss = 0
for images, transformed_images, labels in dummy_train_loader:
images, transformed_images, labels = images.to(DEVICE), transformed_images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
loss, loss_dict = model(images, transformed_images, labels, params)
loss.backward()
optimizer.step()
total_epoch_loss += loss.item()
avg_epoch_loss = total_epoch_loss / len(dummy_train_loader)
print(f"Epoch {epoch+1}/{EPOCHS} | Avg Loss: {avg_epoch_loss:.4f} | LR: {optimizer.param_groups[0]['lr']:.6f}")
print(f" -> Last batch losses: {loss_dict}")
# --- Validation Loop ---
model.eval()
total_correct = 0
total_samples = 0
val_loss = 0
with torch.no_grad():
for val_images, val_labels in dummy_val_loader:
val_images, val_labels = val_images.to(DEVICE), val_labels.to(DEVICE)
logits = model(val_images)
# Simple CE loss for validation metric
val_loss += F.cross_entropy(logits, val_labels).item()
_, predicted = torch.max(logits.data, 1)
total_samples += val_labels.size(0)
total_correct += (predicted == val_labels).sum().item()
accuracy = 100 * total_correct / total_samples
avg_val_loss = val_loss / len(dummy_val_loader)
print(f"Validation | Avg Loss: {avg_val_loss:.4f} | Accuracy: {accuracy:.2f}%")
# Update learning rate scheduler
scheduler.step(avg_val_loss)
print("Training finished.")
if __name__ == '__main__':
main()
Pingback: 7 Revolutionary Breakthroughs in HDR Video (and the 1 Fatal Flaw Holding It Back) - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in MR Spectroscopic Imaging: How a Powerful New Method Beats Old, Inaccurate Techniques - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in MRI Super-Resolution – The Good, the Bad, and the Future of HFMT - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Skin Lesion Segmentation — The Dark Truth About Traditional Methods vs. ESC-UNET’s AI Power - aitrendblend.com