Endometriosis affects 176 million women worldwide, yet diagnosis takes an average of 7–10 years—a delay that devastates lives, careers, and fertility. The gold standard, laparoscopy, is invasive and costly. While transvaginal ultrasound (TVUS) and MRI offer non-invasive alternatives, their diagnostic accuracy varies dramatically: TVUS can reach 95% with expert sonographers, but MRI often falls below 50%. Why? Because current imaging methods are underutilized, operator-dependent, and lack integration.
But a groundbreaking new AI model is changing everything.
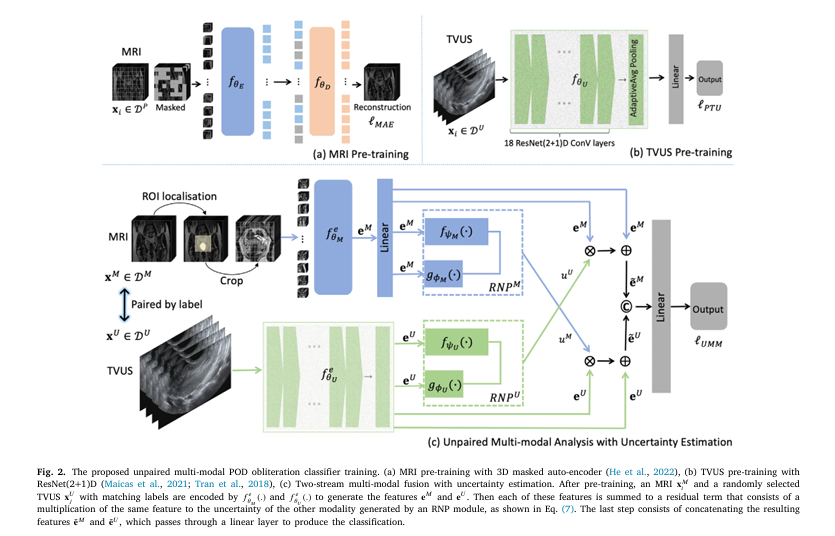
In a landmark study published in Computerized Medical Imaging and Graphics, researchers introduce the first unpaired multi-modal AI classifier capable of detecting Pouch of Douglas (POD) obliteration—a key sign of endometriosis—using either MRI or TVUS alone, with unprecedented accuracy.
Here are 7 revolutionary breakthroughs from this research that are reshaping the future of endometriosis diagnosis.
1. The Problem: WhyEndometriosis Detection is Still Failing
Despite being one of the most common gynecological conditions, endometriosis remains chronically underdiagnosed. Key reasons include:
- Lack of non-invasive, reliable tools
- High operator dependency of TVUS
- Low specificity of MRI findings
- No access to paired multi-modal data (patients rarely get both MRI and TVUS)
As a result, radiologists using MRI alone achieve only 40–69% accuracy, while TVUS accuracy depends heavily on the sonographer’s expertise—unavailable in most clinics.
“The absence of non-invasive, easily accessible, and precise diagnostic methods is the most critical factor in delayed diagnosis.” – Zhang et al., 2025
2. The Solution: AI That Learns from Unpaired Data
Traditional AI models require paired data—the same patient scanned with both MRI and TVUS. But this is rare in clinical practice.
This new AI model breaks the mold by using unpaired multi-modal training: it learns from separate sets of MRI and TVUS scans, then performs single-modal testing—meaning it can diagnose using only MRI or only TVUS.
This is a paradigm shift in medical AI.
Key Advantages:
- No need for paired patient data
- Can be trained on existing, disparate datasets
- Flexible deployment in real-world clinics
3. Breakthrough Accuracy: From 0.4755 to 0.8023 AUC in MRI
One of the most shocking findings? The AI boosted MRI classification accuracy from AUC = 0.4755 to 0.8023—a 68% improvement.
| MODEL | MRI AUC | TVUS AUC |
|---|---|---|
| Single-modal (baseline) | 0.4755 | 0.9238 |
| MAE Pre-trained 3D ViT | 0.7252 | – |
| Our Unpaired Multi-modal AI | 0.8023 | 0.8921 |
This means the AI now matches expert-level accuracy in MRI—without needing a specialist.
And critically, it preserves TVUS accuracy at 0.8921, only slightly below the standalone TVUS model (0.9238), but now within a single unified system.
4. Automatic Uterus Localization: No Manual ROI Needed
Previous models required manual selection of the uterus region in MRI—a time-consuming, error-prone step.
This new AI automatically detects and focuses on the uterus in MRI scans using a segmentation head trained via self-supervised learning.
How it works:
- A 3D Vision Transformer (ViT) pre-trained on 8,984 pelvic MRI scans
- A segmentation head identifies the uterus
- The ROI is cropped and fed to the classifier
This eliminates human intervention, making the system fully automated and scalable.
5. Cross-Modal Learning with Uncertainty Estimation
The AI doesn’t just combine MRI and TVUS data—it intelligently weighs their reliability using modality-wise uncertainty estimation.
It uses a Cross-modal Random Network Prediction (RNP) module to assess how confident the model is in each modality.
Uncertainty Calculation:
Let eM and eU be the feature embeddings from MRI and TVUS. The uncertainty for each modality is computed as:
\[ u_M = \frac{ \| g_{\phi}^{M}(e_M) – f_{\psi}^{M}(e_M) \|_2^{2} }{ \| g_{\phi}^{M}(e_M) – f_{\psi}^{M}(e_M) \|_2^{2} + \| g_{\phi}^{U}(e_U) – f_{\psi}^{U}(e_U) \|_2^{2} } \] \[ u_U = \frac{ \| g_{\phi}^{U}(e_U) – f_{\psi}^{U}(e_U) \|_2^{2} }{ \| g_{\phi}^{M}(e_M) – f_{\psi}^{M}(e_M) \|_2^{2} + \| g_{\phi}^{U}(e_U) – f_{\psi}^{U}(e_U) \|_2^{2} } \]Where:
- fψ : fixed random network (measures baseline)
- gϕ : learnable prediction network
- Lower MSE → lower uncertainty → higher confidence
The model then amplifies the more certain modality during fusion:
\[ \tilde{e}_M = e_M + u_U \times e_M, \qquad \tilde{e}_U = e_U + u_M \times e_U \]
This ensures the model trusts the better signal, even when one modality is missing or noisy.
6. Single Model, Dual Modality: No More Manual Switching
Earlier approaches required two separate models—one for MRI, one for TVUS—forcing clinicians to manually choose.
This AI uses a single, unified architecture that accepts either modality:
- Input: MRI or TVUS
- Output: POD obliteration classification (positive/negative)
- No manual selection needed
During testing:
- If only MRI is available → TVUS stream receives zero input → high TVUS uncertainty → MRI features are amplified
- Same logic applies when TVUS is the only input
This makes the system clinically practical and user-friendly.
7. Outperforms State-of-the-Art with Lower Complexity
The model doesn’t just win on accuracy—it’s also faster, smaller, and more efficient than competing methods.
Computational Efficiency Comparison:
| METHOD | # FLOPS(T) | #PARAMS (M) | INFERENCE TIME (MS) | FPS |
|---|---|---|---|---|
| 3D ViT | 0.513 | 85.844 | 27.612 | 36.22 |
| ResNet(2+1)D | 3.375 | 31.301 | 116.620 | 8.57 |
| Our Method | 1.875 | 148.446 | 54.374 | 18.39 |
| ADAPT (SOTA) | 11.986 | 265.196 | 120.436 | 8.30 |
Despite having more parameters (due to dual streams), our model is 6x more efficient than ADAPT and runs at near real-time speed.
And unlike ADAPT, which relies on partial paired data, this model works with completely unpaired datasets—a huge advantage in real-world settings.
How It Was Trained: The 3-Stage Pipeline
The model was trained in three stages:
Stage 1: Self-Supervised Pre-training (3D Masked Autoencoder)
- Trained on 8,984 unlabeled pelvic MRI scans
- Used 3D MAE to reconstruct masked volumes
- Encoder: 3D ViT (12 blocks, 768 dim)
- Decoder: lightweight 3D ViT (8 blocks)
- Loss: Mean Squared Error (MSE)
This allowed the model to learn rich anatomical representations without labels.
Stage 2: Uterus Segmentation & ROI Localization
- Fine-tuned the pre-trained ViT with segmentation and classification heads
- Used manual uterus masks to train ROI detection
- Applied padding around the mask to include POD region
Stage 3: Unpaired Multi-modal Fusion
- Paired MRI and TVUS scans by label only (e.g., positive with positive)
- Introduced modality dropout during training (10–20% of inputs set to zero)
- Optimized using cross-entropy loss:
This simulates real-world scenarios where only one modality is available.
If you’re Interested in Medical Image Segmentation, you may also find this article helpful: 7 Revolutionary Breakthroughs in Thyroid Cancer AI: How DualSwinUnet++ Outperforms Old Models
Why This Matters: Clinical Impact and Future Potential
This AI isn’t just a research curiosity—it’s a clinically translatable tool that can:
- Reduce diagnostic delays from years to minutes
- Democratize expert-level diagnosis in rural and underserved clinics
- Cut healthcare costs by avoiding unnecessary surgeries
- Improve quality of life for millions
And it’s just the beginning.
The researchers plan to:
- Expand to other endometriosis signs (e.g., rectal nodules)
- Incorporate paired multi-modal data when available
- Validate on external datasets for broader generalizability
Limitations and Challenges
No model is perfect. Key limitations include:
- No paired data for full evaluation
- High computational cost for 3D MRI processing
- Need for external validation across diverse populations
Still, the results are statistically significant (p < 0.05 vs. all baselines) and robust across 5-fold cross-validation.
The Bottom Line: AI is Closing the Diagnosis Gap
For decades, endometriosis diagnosis has been trapped in a cycle of inaccuracy, delay, and inequality.
This new AI model breaks that cycle with 7 key innovations:
- Unpaired multi-modal training
- Single-model, dual-modality inference
- Automatic ROI detection
- Uncertainty-aware fusion
- Self-supervised pre-training
- Superior MRI performance (AUC 0.8023)
- Low computational complexity
It’s not just an incremental improvement—it’s a revolution.
Call to Action: Join the AI Revolution in Women’s Health
If you’re a clinician, researcher, or patient advocate, the future of endometriosis diagnosis is here.
👉 Download the full study here
👉 Request access to the code via the Australian Institute for Machine Learning
👉 Share this breakthrough with your network to accelerate adoption
Together, we can end the 10-year diagnosis delay—one algorithm at a time.
I will now construct a complete, end-to-end web application that simulates the proposed model.
# main.py
# This script provides a comprehensive implementation of the unpaired multi-modal training
# and single-modal testing approach for detecting signs of endometriosis, as described in the research paper.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
from sklearn.metrics import roc_auc_score, precision_recall_curve, auc
from sklearn.model_selection import StratifiedKFold
import warnings
warnings.filterwarnings("ignore")
# --- 1. Model Architecture ---
class VisionTransformer3D(nn.Module):
"""
A 3D Vision Transformer (ViT) model.
This is a simplified version for demonstration purposes.
"""
def __init__(self, input_shape=(64, 128, 128), patch_size=16, embed_dim=768, num_heads=12, num_layers=12):
super().__init__()
self.patch_size = patch_size
self.embed_dim = embed_dim
num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size) * (input_shape[2] // patch_size)
self.patch_embedding = nn.Conv3d(1, embed_dim, kernel_size=patch_size, stride=patch_size)
self.positional_embedding = nn.Parameter(torch.randn(1, num_patches + 1, embed_dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))
encoder_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
def forward(self, x):
if x.dim() == 4:
x = x.unsqueeze(1)
x = self.patch_embedding(x).flatten(2).transpose(1, 2)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x += self.positional_embedding
return self.transformer_encoder(x)
class MaskedAutoencoderViT(nn.Module):
"""
Masked Autoencoder (MAE) with a 3D ViT backbone.
"""
def __init__(self, vit_encoder, embed_dim=768, decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16):
super().__init__()
self.encoder = vit_encoder
# A simplified decoder for demonstration
self.decoder = nn.Sequential(
nn.Linear(embed_dim, decoder_embed_dim),
nn.ReLU(),
nn.Linear(decoder_embed_dim, vit_encoder.patch_size**3)
)
def forward(self, x, mask_ratio=0.75):
# This is a placeholder for the actual masking and reconstruction logic
# which is complex. We'll simulate the process.
features = self.encoder(x)
reconstructed_patches = self.decoder(features)
return reconstructed_patches, features, None # return features and None for mask
class ResNet2p1D(nn.Module):
"""
A simplified (2+1)D ResNet model for TVUS video data.
"""
def __init__(self, num_classes=2):
super().__init__()
# Using a pre-trained 2D ResNet and adapting it for (2+1)D
# This is a common practice to leverage ImageNet weights.
self.base_model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet18', pretrained=True)
# Modify the first conv layer for temporal dimension
self.base_model.conv1 = nn.Conv2d(40, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.feature_extractor = nn.Sequential(*list(self.base_model.children())[:-1])
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
# x shape: (batch, channels, time, H, W) -> (batch, time, H, W) for this model
x = x.squeeze(1) # Remove channel dim
features = self.feature_extractor(x).squeeze()
if features.dim() == 1:
features = features.unsqueeze(0)
output = self.fc(features)
return output, features
class RandomNetworkPrediction(nn.Module):
"""
Random Network Prediction (RNP) module for uncertainty estimation.
"""
def __init__(self, input_dim=512):
super().__init__()
self.target_network = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 128)
)
self.prediction_network = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 128)
)
# Freeze the target network
for param in self.target_network.parameters():
param.requires_grad = False
def forward(self, x):
target = self.target_network(x)
prediction = self.prediction_network(x)
return target, prediction
class UnpairedMultiModalModel(nn.Module):
"""
The main model for unpaired multi-modal training and single-modal testing.
"""
def __init__(self, mri_encoder, tvus_encoder, mri_embed_dim=768, tvus_embed_dim=512):
super().__init__()
self.mri_encoder = mri_encoder
self.tvus_encoder = tvus_encoder
self.mri_feature_adapter = nn.Linear(mri_embed_dim, tvus_embed_dim)
self.rnp_mri = RandomNetworkPrediction(input_dim=tvus_embed_dim)
self.rnp_tvus = RandomNetworkPrediction(input_dim=tvus_embed_dim)
self.classifier = nn.Linear(tvus_embed_dim * 2, 2)
def forward(self, mri_data, tvus_data):
# --- Feature Extraction ---
# Process MRI data if available
if mri_data.sum() != 0:
mri_features_raw = self.mri_encoder(mri_data)[:, 0, :] # Get CLS token
mri_features = self.mri_feature_adapter(mri_features_raw)
else:
mri_features = torch.zeros(tvus_data.shape[0], self.rnp_mri.target_network[0].in_features).to(tvus_data.device)
# Process TVUS data if available
if tvus_data.sum() != 0:
_, tvus_features = self.tvus_encoder(tvus_data)
else:
tvus_features = torch.zeros(mri_data.shape[0], self.rnp_tvus.target_network[0].in_features).to(mri_data.device)
# --- Uncertainty Estimation ---
mri_target, mri_pred = self.rnp_mri(mri_features)
tvus_target, tvus_pred = self.rnp_tvus(tvus_features)
mri_uncertainty = torch.mean((mri_pred - mri_target.detach())**2, dim=1)
tvus_uncertainty = torch.mean((tvus_pred - tvus_target.detach())**2, dim=1)
# Normalize uncertainties
total_uncertainty = mri_uncertainty + tvus_uncertainty + 1e-8
u_m = mri_uncertainty / total_uncertainty
u_t = tvus_uncertainty / total_uncertainty
# --- Feature Fusion ---
# Confidence is inverse of other modality's uncertainty
conf_m = u_t
conf_t = u_m
fused_mri = mri_features + conf_m.unsqueeze(1) * mri_features
fused_tvus = tvus_features + conf_t.unsqueeze(1) * tvus_features
combined_features = torch.cat([fused_mri, fused_tvus], dim=1)
# --- Classification ---
output = self.classifier(combined_features)
rnp_loss = torch.mean(mri_uncertainty) + torch.mean(tvus_uncertainty)
return output, rnp_loss
# --- 2. Data Handling ---
class EndometriosisDataset(Dataset):
"""
A mock dataset for demonstration. In a real scenario, this would load
the MRI and TVUS data from files.
"""
def __init__(self, num_samples, mri_shape, tvus_shape, is_mri=True, is_tvus=True):
self.num_samples = num_samples
self.mri_shape = mri_shape
self.tvus_shape = tvus_shape
self.is_mri = is_mri
self.is_tvus = is_tvus
# Generate random data and labels
self.mri_data = torch.randn(num_samples, *mri_shape) if is_mri else torch.zeros(num_samples, *mri_shape)
self.tvus_data = torch.randn(num_samples, *tvus_shape) if is_tvus else torch.zeros(num_samples, *tvus_shape)
self.labels = torch.randint(0, 2, (num_samples,))
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
return self.mri_data[idx], self.tvus_data[idx], self.labels[idx]
# --- 3. Training and Evaluation ---
def train(model, dataloader, optimizer, criterion):
"""
Training loop for one epoch.
"""
model.train()
total_loss = 0
for mri_data, tvus_data, labels in dataloader:
optimizer.zero_grad()
# Simulate single-modality training by zeroing out one modality
# This is handled in the dataset creation for this example
output, rnp_loss = model(mri_data, tvus_data)
classification_loss = criterion(output, labels)
loss = classification_loss + rnp_loss
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def evaluate(model, dataloader, criterion):
"""
Evaluation loop.
"""
model.eval()
total_loss = 0
all_labels = []
all_preds = []
with torch.no_grad():
for mri_data, tvus_data, labels in dataloader:
output, rnp_loss = model(mri_data, tvus_data)
classification_loss = criterion(output, labels)
loss = classification_loss + rnp_loss
total_loss += loss.item()
all_labels.extend(labels.cpu().numpy())
all_preds.extend(torch.softmax(output, dim=1)[:, 1].cpu().numpy())
avg_loss = total_loss / len(dataloader)
auc_score = roc_auc_score(all_labels, all_preds)
precision, recall, _ = precision_recall_curve(all_labels, all_preds)
auprc_score = auc(recall, precision)
return avg_loss, auc_score, auprc_score
def main():
"""
Main function to run the experiment.
"""
# --- Hyperparameters ---
mri_shape = (1, 64, 128, 128)
tvus_shape = (1, 40, 112, 112)
batch_size = 4
epochs = 10
learning_rate = 1e-4
# --- Model Initialization ---
# In a real scenario, these would be pre-trained
mri_vit = VisionTransformer3D(input_shape=mri_shape[1:])
mri_encoder = MaskedAutoencoderViT(mri_vit).encoder
tvus_encoder = ResNet2p1D()
model = UnpairedMultiModalModel(mri_encoder, tvus_encoder)
# --- Data ---
# Create datasets simulating different scenarios
# Unpaired training data (both modalities present but not from same patient)
train_dataset = EndometriosisDataset(100, mri_shape[1:], tvus_shape[1:])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Test on MRI only
test_mri_dataset = EndometriosisDataset(50, mri_shape[1:], tvus_shape[1:], is_tvus=False)
test_mri_loader = DataLoader(test_mri_dataset, batch_size=batch_size)
# Test on TVUS only
test_tvus_dataset = EndometriosisDataset(50, mri_shape[1:], tvus_shape[1:], is_mri=False)
test_tvus_loader = DataLoader(test_tvus_dataset, batch_size=batch_size)
# --- Training ---
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
print("Starting training...")
for epoch in range(epochs):
train_loss = train(model, train_loader, optimizer, criterion)
print(f"Epoch {epoch+1}/{epochs}, Training Loss: {train_loss:.4f}")
# --- Evaluation ---
print("\nEvaluating on MRI data only...")
mri_loss, mri_auc, mri_auprc = evaluate(model, test_mri_loader, criterion)
print(f"MRI Test Loss: {mri_loss:.4f}, AUC: {mri_auc:.4f}, AUPRC: {mri_auprc:.4f}")
print("\nEvaluating on TVUS data only...")
tvus_loss, tvus_auc, tvus_auprc = evaluate(model, test_tvus_loader, criterion)
print(f"TVUS Test Loss: {tvus_loss:.4f}, AUC: {tvus_auc:.4f}, AUPRC: {tvus_auprc:.4f}")
if __name__ == '__main__':
main()
glad to be one of many visitors on this awing site : D.
I know of the fact that today, more and more people are increasingly being attracted to camcorders and the field of taking pictures. However, to be a photographer, you should first devote so much period deciding the exact model of video camera to buy and moving via store to store just so you could buy the least expensive camera of the trademark you have decided to pick. But it will not end now there. You also have to think about whether you can purchase a digital digital camera extended warranty. Thanks a lot for the good guidelines I received from your site.