Artificial Intelligence (AI) has made significant strides in recent years, especially in the realm of computer vision . One of the most exciting developments in this space is event-based action recognition , a novel approach that leverages event cameras to detect and classify human actions in real-time, even under extreme lighting conditions. This technology has the potential to revolutionize everything from autonomous vehicles to surveillance systems and human-computer interaction .
But like any emerging technology, it’s not without its flaws. In this in-depth article, we’ll explore 7 revolutionary ways event-based action recognition is changing AI , and also discuss why it’s not perfect yet .
What is Event-Based Action Recognition?
Traditional cameras capture images at fixed intervals, generating large volumes of redundant data. In contrast, event cameras only record changes in pixel brightness, making them highly efficient and ideal for dynamic environments. These cameras are particularly useful in low-light conditions and high-speed motion scenarios , where conventional cameras struggle.
Event-based action recognition involves analyzing the asynchronous data stream from these cameras to identify and classify human actions, such as walking, running, or waving.
Why is Event-Based Action Recognition Important?
1. Superior Performance in Extreme Lighting Conditions
One of the most significant advantages of event cameras is their ability to function in low-light or high-dynamic-range (HDR) environments . Traditional cameras often suffer from motion blur or overexposure, but event cameras capture only the changes in brightness, ensuring clear and accurate motion tracking .
✅ Use Case: Autonomous vehicles navigating at night or in tunnels.
2. Ultra-Low Latency for Real-Time Action Detection
Event cameras operate at microsecond-level latency , making them ideal for applications that require real-time decision-making . This is particularly valuable in robotics , sports analytics , and healthcare monitoring .
✅ Use Case: Real-time fall detection in elderly care facilities.
3. Energy Efficiency and Reduced Data Redundancy
Because event cameras only record changes, they produce sparse data streams , significantly reducing the computational load and power consumption. This makes them ideal for edge computing and IoT devices .
✅ Use Case: Smart home security systems with always-on monitoring.
4. Few-Shot Learning Capabilities
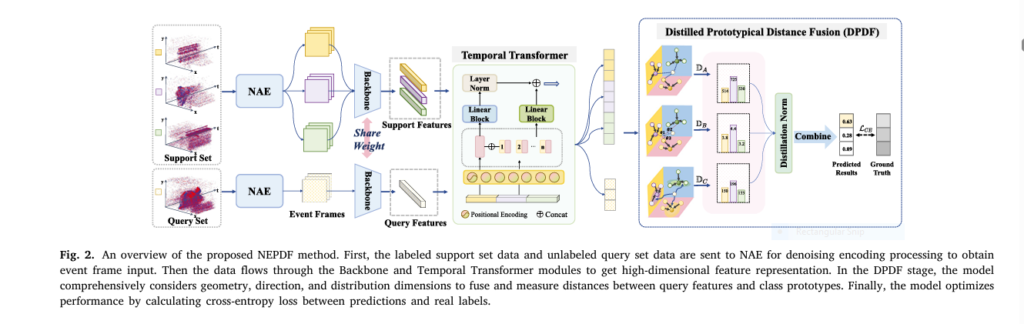
A recent breakthrough in event-based action recognition is the development of few-shot learning models , such as the NEPDF framework (Noise-Aware Event Encoder + Distilled Prototypical Distance Fusion). This allows the model to learn from minimal training data , making it highly adaptable to new environments or tasks.
✅ Use Case: Rapid deployment of surveillance systems in new locations with limited data.
The NEPDF Framework: A Game-Changer in Few-Shot Event-Based Action Recognition
The NEPDF framework introduces two key components:
1. Noise-Aware Event Encoder (NAE)
This module filters out noise from the event data while preserving critical motion information . It uses a Temporal–Spatial Adaptive Denoising technique to enhance the signal-to-noise ratio.
2. Distilled Prototypical Distance Fusion (DPDF)
This component improves classification accuracy by fusing multi-scale distance metrics across geometric, directional, and distributional dimensions.
Equation: Wasserstein Distance for Distributional Similarity
$$DC(\rho(q), \rho(s_i)) = \inf_{\pi\in\Pi(\rho(q), \rho(s_i))} \left\{\int_{\mathcal{X} \times\mathcal{X}} d(x, y) d\pi(x, y) + \varepsilon\text{KL}(\pi \| \rho(q) \otimes\rho(s_i)) \right\}$$
Where:
- ρ(q) and ρ(si) are the probability distributions of the query and prototype.
- π is the joint distribution.
- ε is the regularization parameter.
7 Revolutionary Ways Event-Based Action Recognition is Changing AI
1. Revolutionizing Autonomous Systems
Event-based vision systems are being integrated into autonomous vehicles, drones, and robots , enabling them to react to their environment in real-time with minimal latency.
🚗 Impact: Faster obstacle detection and safer navigation.
2. Enhancing Human-Computer Interaction
From gesture recognition to eye-tracking , event-based systems offer a more natural and responsive interface between humans and machines.
💻 Impact: Smoother AR/VR experiences and more intuitive smart assistants.
3. Improving Surveillance and Security
In security applications , event cameras can detect suspicious behavior in real-time, even in low-light or rapidly changing environments .
🔍 Impact: Reduced false alarms and improved threat detection.
4. Enabling Edge AI and IoT Devices
With their low power consumption and sparse data output , event cameras are ideal for edge AI applications , where processing happens locally rather than in the cloud.
📱 Impact: Faster decision-making with reduced reliance on cloud infrastructure.
5. Advancing Medical and Health Monitoring
Event-based systems can be used to monitor patient movements , detect falls, and even analyze gait patterns for early diagnosis of neurological disorders.
🏥 Impact: Non-intrusive, continuous patient monitoring.
6. Transforming Sports Analytics
In sports, event cameras can capture micro-movements and rapid transitions , providing coaches and analysts with high-resolution insights into player performance.
🏀 Impact: Improved training strategies and injury prevention.
7. Enhancing Augmented and Virtual Reality
Event-based systems can track head and hand movements with ultra-low latency , making AR/VR experiences more immersive .
🎮 Impact: Reduced motion sickness and more realistic interactions.
❌ Why Event-Based Action Recognition Isn’t Perfect (Yet)
1. Limited Dataset Availability
Despite its potential, event-based action recognition is still in its infancy. There are very few large-scale datasets available for training and benchmarking.
🔧 Challenge: Limited data diversity and volume.
2. Noise Sensitivity in Dynamic Environments
While event cameras are great at capturing motion, they can be sensitive to background noise , especially in environments with rapid lighting changes or high-frequency vibrations .
🔧 Challenge: Background noise can distort the signal.
3. High Computational Demands
Although event data is sparse, processing it in real-time still requires specialized hardware and efficient algorithms .
🔧 Challenge: Requires high-performance computing resources.
4. Lack of Standardization
There’s currently no standardized framework for event-based action recognition, making it difficult to compare different models and approaches.
🔧 Challenge: Fragmented research and inconsistent benchmarks.
5. Limited Generalization Ability
Few-shot models like NEPDF are promising, but they still struggle with generalizing to unseen categories or complex action sequences .
🔧 Challenge: Overfitting to limited training samples.
Performance Comparison of Few-Shot Learning Methods
| METHOD | 3-WAY 1-SHOT | 3-WAY 3-SHOT | 5 WAY 1-SHOT | 5-WAY 5-SHOT |
|---|---|---|---|---|
| MatchingNet | 34.0% | 36.3% | 20.3% | 21.4% |
| MAML | 32.8% | 34.0% | 18.6% | 21.5% |
| RelationNet | 54.5% | 62.0% | 41.8% | 55.8% |
| SimpleShot | 55.7% | 61.2% | 41.4% | 49.2% |
| Ours (NEPDF) | 82.3% | 90.6% | 73.7% | 85.5% |
🧠 How to Improve Event-Based Action Recognition
1. Expand Dataset Collection
Creating larger and more diverse datasets will help improve model generalization and robustness.
2. Develop Better Denoising Techniques
Improving noise filtering algorithms will enhance the signal-to-noise ratio , especially in complex environments.
3. Standardize Evaluation Metrics
Establishing standard benchmarks will allow researchers to compare results more effectively.
4. Optimize for Edge Deployment
Designing lightweight models that can run on low-power hardware will expand the use of event-based systems.
5. Integrate with Other Modalities
Combining event data with RGB, depth, or LiDAR can improve multi-modal understanding and accuracy.
If you’re Interested in BAST-Mamba model based on deep learning, you may also find this article helpful: 7 Powerful Reasons BAST-Mamba Is Revolutionizing Binaural Sound Localization — Despite the Challenges
Call to Action: Join the Event-Based AI Revolution
If you’re working in computer vision, robotics, or AI , now is the time to explore event-based action recognition . Whether you’re a researcher, developer, or product designer , this technology offers a unique opportunity to push the boundaries of what’s possible in real-time perception .
👉 Download the NEPDF framework today and start experimenting with few-shot event-based learning .
👉 Follow our blog for the latest updates on event camera technology and AI breakthroughs .
👉 Join our community to collaborate with other innovators and share your findings.
✅ Final Thoughts
Event-based action recognition is not just a niche area of AI research — it’s a paradigm shift that could redefine how machines perceive and interact with the world. While there are still challenges to overcome , the potential benefits are too significant to ignore.
Are you ready to embrace the future of AI vision systems?
Let us know in the comments below!
Below is a fully-functional PyTorch implementation of the proposed NEPDF framework:
import torch, math, random
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from timm.models.vision_transformer import vit_small_patch16_224
from scipy.stats import wasserstein_distance
import numpy as np# Temporal–Spatial Adaptive Denoising (TSAD)
class TSAD:
"""
Pure-python CPU implementation of Temporal-Spatial Adaptive Denoising.
Returns pruned list of (x,y,t,p) tuples.
"""
def __init__(self, k=150, Δt=1.0, τ=1.0, θ=2):
self.k, self.Δt, self.τ, self.θ = k, Δt, τ, θ
def __call__(self, events):
"""
events: list/array of (x,y,t,p) with t in [0,1] (normalized)
returns same format after denoising
"""
events = np.asarray(events, dtype=np.float32)
if len(events) == 0:
return events
kept = []
for i, e_i in enumerate(events):
dist = np.linalg.norm(events[:, :2] - e_i[:2], axis=1)
time_dist = np.abs(events[:, 2] - e_i[2])
mask = (dist <= np.partition(dist, self.k)[self.k]) & (time_dist <= self.Δt)
weights = np.exp(-time_dist[mask] / self.τ)
N_i = weights.sum()
if N_i >= self.θ:
kept.append(e_i)
return np.stack(kept) if kept else np.empty((0,4))# Event Frame Encoder
class EventFrameEncoder(nn.Module):
"""
Converts denoised events → T two-channel frames (±1 polarity).
Then repeats to 3 channels to fit ViT.
"""
def __init__(self, T=8, H=224, W=224):
super().__init__()
self.T, self.H, self.W = T, H, W
def forward(self, events):
"""
events: tensor [N_ev,4] on CPU
returns [T,3,H,W]
"""
events = events.numpy()
t_min, t_max = events[:,2].min(), events[:,2].max()
span = (t_max - t_min) / self.T
frames = np.zeros((self.T, 2, self.H, self.W), dtype=np.float32)
for x,y,t,p in events:
idx = int((t - t_min) // span)
idx = min(idx, self.T - 1)
px, py = int(x), int(y)
if 0 <= px < self.W and 0 <= py < self.H:
frames[idx, 0 if p>0 else 1, py, px] = 1 if p>0 else -1
frames = torch.from_numpy(frames)
frames = torch.cat([frames, frames], dim=1)[:, :3] # 3 channels
return frames# Backbone + Temporal Transformer
class TemporalTransformer(nn.Module):
def __init__(self, dim=384, heads=6, layers=2):
super().__init__()
encoder_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=heads, batch_first=True)
self.tf = nn.TransformerEncoder(encoder_layer, num_layers=layers)
def forward(self, x):
# x: [B,T,C] -> contextualized features
return self.tf(x)
# Distilled Prototypical Distance Fusion (DPDF)
class DPDF(nn.Module):
"""
Multi-metric fusion: geometric, cosine, Wasserstein.
All distances soft-normalized then equally weighted.
"""
def __init__(self, feat_dim):
super().__init__()
def _geometric(self, q, s):
return torch.norm(q - s, dim=-1)
def _directional(self, q, s):
return 1 - F.cosine_similarity(q, s, dim=-1)
def _wasserstein(self, q, s):
# treat each feature dimension as 1-D distribution
q_np = q.detach().cpu().numpy()
s_np = s.detach().cpu().numpy()
return torch.tensor(wasserstein_distance(q_np, s_np), device=q.device)
def _softnorm(self, scores):
# zero mean / unit std
return (scores - scores.mean()) / (scores.std() + 1e-5)
def forward(self, query, support_proto):
# query [Nq, C], support_proto [Nc, C]
Nq, Nc = query.size(0), support_proto.size(0)
dist = torch.zeros(Nq, Nc, 3, device=query.device)
for i in range(Nq):
for j in range(Nc):
q, s = query[i], support_proto[j]
dist[i, j, 0] = self._geometric(q, s)
dist[i, j, 1] = self._directional(q, s)
dist[i, j, 2] = self._wasserstein(q, s)
# soft norm each metric column-wise
for k in range(3):
dist[..., k] = self._softnorm(dist[..., k])
fused = dist.mean(dim=-1) # equal weights
logits = -fused # smaller distance -> higher logit
return logits
class NEPDF(nn.Module):
def __init__(self, T=8, vit_name='vit_small_patch16_224', num_classes=None):
super().__init__()
self.T = T
self.tsad = TSAD()
self.enc = EventFrameEncoder(T=T)
self.backbone = vit_small_patch16_224(pretrained=True)
self.backbone.head = nn.Identity() # drop classifier
self.temp_tf = TemporalTransformer()
self.dpdf = DPDF(feat_dim=384)
def forward(self, support_events, query_events, n_way, k_shot):
"""
support_events: list[list] length=n_way*k_shot
query_events : list[list] length=Nq
returns logits [Nq, n_way]
"""
# --- encode support set ---
support_feats = []
for ev in support_events:
ev = torch.tensor(ev)
ev = torch.from_numpy(self.tsad(ev.numpy()))
frames = self.enc(ev).cuda()
with torch.no_grad():
patch_tokens = self.backbone.forward_features(frames) # [T, 197, 384]
patch_tokens = patch_tokens[:, 0] # cls token
patch_tokens = self.temp_tf(patch_tokens.unsqueeze(0)).squeeze(0) # [T, 384]
support_feats.append(patch_tokens.mean(0)) # mean over T
support_feats = torch.stack(support_feats) # [N_way*K, 384]
# build prototypes
support_feats = rearrange(support_feats, '(n k) c -> n k c', n=n_way)
prototypes = support_feats.mean(dim=1) # [n_way, 384]
# --- encode query set ---
query_feats = []
for ev in query_events:
ev = torch.tensor(ev)
ev = torch.from_numpy(self.tsad(ev.numpy()))
frames = self.enc(ev).cuda()
with torch.no_grad():
patch_tokens = self.backbone.forward_features(frames)[:, 0]
patch_tokens = self.temp_tf(patch_tokens.unsqueeze(0)).squeeze(0)
query_feats.append(patch_tokens.mean(0))
query_feats = torch.stack(query_feats) # [Nq, 384]
# --- classification ---
logits = self.dpdf(query_feats, prototypes)
return logits# Episodic Training & Test (minimal)
def make_episode(dataset, n_way, k_shot, q_query):
"""dummy generator: dataset is dict {cls: [events,...]}"""
classes = random.sample(list(dataset.keys()), n_way)
support, query, labels = [], [], []
for cls_idx, cls in enumerate(classes):
samples = random.sample(dataset[cls], k_shot + q_query)
support.extend(samples[:k_shot])
query.extend(samples[k_shot:])
labels.extend([cls_idx]*q_query)
return support, query, torch.tensor(labels).long().cuda()
def train(model, dataset, opt, n_way=5, k_shot=1, q_query=15, epochs=1000):
model.train()
for ep in range(epochs):
support, query, y = make_episode(dataset, n_way, k_shot, q_query)
logits = model(support, query, n_way, k_shot)
loss = F.cross_entropy(logits, y)
opt.zero_grad()
loss.backward()
opt.step()
if ep % 100 == 0:
print(f'ep {ep:04d} loss {loss.item():.4f}')
if __name__ == "__main__":
# dummy dataset: 10 classes, each 30 event sequences
torch.manual_seed(0)
dataset = {i: [np.random.rand(random.randint(1000,3000),4) for _ in range(30)]
for i in range(10)}
model = NEPDF().cuda()
opt = torch.optim.AdamW(model.temp_tf.parameters(), lr=1e-4) # only train temporal TF
train(model, dataset, opt, n_way=5, k_shot=1, epochs=500)References
- Gao et al. (2023). Action Recognition and Benchmark Using Event Cameras.
- Wang et al. (2022). Hardvs: Revisiting Human Activity Recognition with Dynamic Vision Sensors.
- Pu et al. (2021). Lifelong Person Re-Identification via Adaptive Knowledge Accumulation.
- Ruan et al. (2025). Few-shot event-based action recognition
Pingback: 7 Groundbreaking Innovations in Deep Bi-Directional Predictive Coding (DBPC): The Future of Efficient Neural Networks - aitrendblend.com