The HDR Video Revolution: Why Your Camera Can’t See What You Can
Have you ever tried to capture a sunset, only to end up with a black silhouette against a blazing, detail-less sky? Or struggled to see textures in a dimly lit room while the window behind is blown out? This is the frustrating reality of Low Dynamic Range (LDR) imaging — a fundamental limitation of conventional cameras. But what if your videos could see like your eyes, capturing every shadow and highlight with stunning clarity?
Enter High Dynamic Range (HDR) video reconstruction — a cutting-edge technology poised to transform how we capture and experience visual content. Recent research, particularly the groundbreaking work by Guangsha Guo and team in their paper “Recurrent Event-Guided Multimodal Fusion for High Dynamic Range Video Reconstruction,” has unveiled a revolutionary solution that not only solves long-standing problems but also exposes a critical flaw in current methods.
In this deep dive, we’ll explore the 7 most significant breakthroughs in this new era of HDR video — and the one fatal flaw that still needs fixing.
The Problem: Why Your Camera Fails in High-Contrast Scenes
Conventional cameras have a limited dynamic range — typically around 60-80 dB. This means they can’t simultaneously capture the brightest highlights and the darkest shadows in a scene. The result? Overexposed skies and underexposed interiors.
Traditional HDR methods try to fix this by combining multiple photos taken at different exposures. But this approach has major drawbacks:
- Ghosting artifacts from moving objects or camera shake.
- High computational cost and slow processing.
- Inability to work in real-time for video.
This is where event cameras come in — a technology inspired by the human eye.
Breakthrough #1: Event Cameras — The Secret Weapon for HDR
Unlike traditional cameras that capture full frames at fixed intervals, event cameras detect changes in brightness asynchronously. They don’t take pictures — they record events — tiny, timestamped records of brightness changes at individual pixels.
Key advantages of event cameras:
- Ultra-high dynamic range (>120 dB).
- Microsecond-level temporal resolution.
- Low power consumption and no motion blur.
As the paper explains, an event ei(xi, yi, ti, pi) is triggered when the logarithmic intensity change at a pixel exceeds a threshold Cth :
$$E_t(x, y) = \Lambda \big\{ \log L_t – \Delta_t(x, y) + \varepsilon L_t(x, y) + \varepsilon, \; C_{th} \big\} $$This means event cameras can “see” in near-total darkness and blinding sunlight — the perfect guide for HDR reconstruction.
Breakthrough #2: The First Real-World HDR Dataset — RealHDR
One of the biggest roadblocks in AI-driven HDR research has been the lack of real-world, high-resolution training data. Most models are trained on simulated data, which doesn’t reflect real-world noise, motion, or lighting.
Guo et al. solved this by creating RealHDR — the first large-scale, real-world dataset for event-guided HDR reconstruction.
| DATASET FEATURE | REALHDR | PREVIOUS DATASETS |
|---|---|---|
| Resolution | 800 × 600 | ≤ 240 × 180 |
| Data Type | Real captured | Mostly simulated |
| Modality | RGB + Events + HDR GT | Simulated events |
| Sequences | 19 | ≤ 5 |
| Total Images | 5,510 | < 1,000 |
This dataset is a game-changer — enabling models to learn from real-world conditions, not artificial simulations.
Breakthrough #3: End-to-End Fusion — No More Multi-Stage Chaos
Previous event-guided HDR methods used multi-stage pipelines:
- Reconstruct an image from events.
- Fuse it with the LDR image.
- Refine the result.
This approach is complex, slow, and error-prone. Guo et al. introduced REHDR — an end-to-end network that fuses event and image data in a single pass.
This eliminates:
- Training instability from staged optimization.
- Information loss between stages.
- High computational overhead.
The result? Faster, more accurate HDR reconstruction.
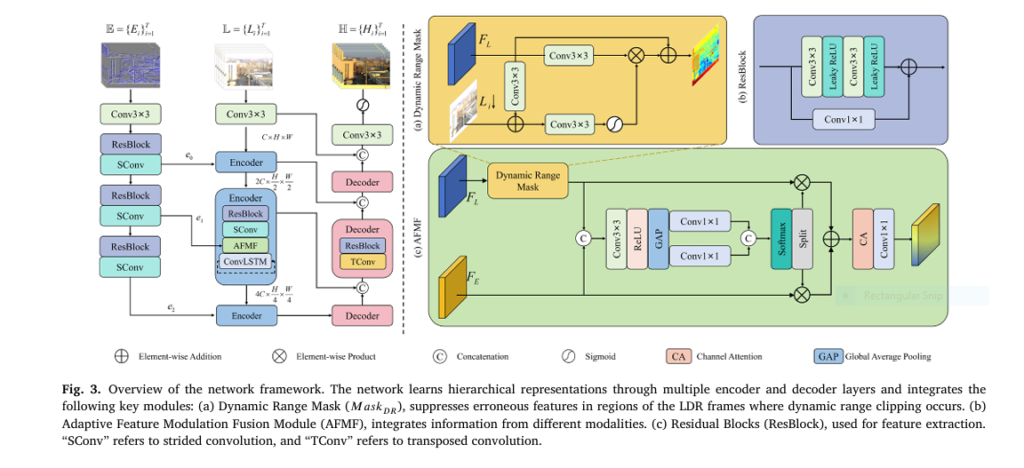
Breakthrough #4: Adaptive Feature Modulation Fusion (AFMF)
One of the hardest challenges in multimodal fusion is modality mismatch:
- Events are sparse, noisy, and asynchronous.
- LDR images are dense but clipped in bright/dark areas.
Simple fusion (like concatenation) fails. So the team designed the Adaptive Feature Modulation Fusion (AFMF) module — a smart fusion engine that learns how to combine the two.
Here’s how it works:
- Dynamic Range Mask (MaskDR): Identifies overexposed regions in the LDR image and suppresses them.
- Attention-Based Fusion: Uses global pooling and Softmax to weight event and image features.
This ensures the network focuses on reliable data and ignores corrupted regions — a brilliant fix for a long-standing problem.
Breakthrough #5: Recurrent Temporal Modeling — Say Goodbye to Flickering
HDR video reconstruction often suffers from flickering — rapid brightness changes between frames. This happens because event streams are non-uniform — more events fire in bright, moving areas.
REHDR solves this with a ConvLSTM-based recurrent encoder. It maintains a hidden state across frames, ensuring temporal consistency.
$$h_t = \text{ConvLSTM}(x_t, h_{t-1}) $$This hidden state carries over visual context, smoothing out flicker and producing stable, cinematic HDR video.
Breakthrough #6: Unified Data Loading — SSASDL
Training video models is hard. Traditional methods load entire sequences into memory — a memory hog that limits scalability.
The team introduced SSASDL (Streaming Sampling and Augmentation Sequential Data Loading) — a smart, memory-efficient loader that:
- Dynamically samples fixed-length sequences.
- Supports random cropping, flipping, and rotation.
- Works for both images and videos.
This flexible framework makes training faster, more efficient, and scalable to large datasets.
Breakthrough #7: State-of-the-Art Performance — The Numbers Don’t Lie
The proof is in the results. On the RealHDR dataset, REHDR outperforms all existing methods:
| METHOD | PSNR (DB) | SSIM | VDP | VQM |
|---|---|---|---|---|
| Li et al. (2020) | 17.80 | 0.706 | – | – |
| AHDRNet (2019) | 12.78 | 0.485 | 63.549 | 0.622 |
| E2VID (2019) | 12.07 | 0.316 | – | – |
| HDRev-Net (2023) | 18.85 | 0.625 | 63.581 | 0.456 |
| NeurImg-HDR+ (2023) | 16.37 | 0.606 | 64.026 | 0.639 |
| REHDR (Ours) | 25.01 | 0.878 | 64.369 | 0.329 |
That’s a 7.21 dB improvement over the best previous method — a massive leap in image quality.
Visual results confirm this: REHDR recovers fine textures in overexposed windows, natural colors in dark rooms, and zero ghosting artifacts — even in dynamic scenes.
The Fatal Flaw: Color Recovery in Clipped Regions
Despite these breakthroughs, there’s one critical limitation — color recovery in overexposed or underexposed areas.
Event cameras only detect brightness changes, not absolute color. So when a region is clipped (pure white or black), the color information is lost forever.
As the paper notes:
“Since event data only reflects brightness changes… recovering the colors of clipped regions remains a critical challenge.”
This means:
- A red wall blown out to white may be reconstructed as gray or blue.
- Skin tones in bright sunlight may look unnatural.
- No amount of AI can perfectly guess lost color.
This is the Achilles’ heel of current HDR reconstruction — and the next frontier for research.
Future Directions: What’s Next for HDR Video?
The authors suggest several promising paths:
- Time-Aware Recurrent Networks: Current ConvLSTM assumes uniform time steps — but events are asynchronous. Models like Neural ODEs or Mamba could better handle irregular timing.
- Color Recovery Integration: Combine HDR reconstruction with image colorization or inpainting models to restore lost colors.
- Joint Deblurring and HDR: Use events to correct motion blur in LDR frames — a double win for image quality.
- Real-Time Embedded Systems: Optimize REHDR for deployment on drones, AR glasses, or autonomous vehicles.
Why This Matters: Real-World Applications
This technology isn’t just for better vacation videos. It has life-changing applications:
- Autonomous Vehicles: See clearly in tunnels, at night, or in glaring sun.
- Medical Imaging: Reveal subtle tissue contrasts in surgery.
- Security & Surveillance: Monitor high-contrast environments (e.g., entrances with bright sunlight).
- Virtual Reality: Create immersive, lifelike environments.
With REHDR, we’re one step closer to machines that see the world as humans do — in full, vibrant detail.
How to Try It Yourself (Free & Open Source!)
The best part? The authors open-sourced everything.
- GitHub Repository: https://github.com/ice-cream567/REHDR
- Includes: Full code, trained models, and data loading scripts.
- Framework: PyTorch 2.1.1.
Whether you’re a researcher, developer, or HDR enthusiast, you can run, test, and improve this state-of-the-art model today.
Conclusion: A New Era of Visual Fidelity
The REHDR framework represents a quantum leap in HDR video reconstruction. With 7 key breakthroughs — from real-world data to adaptive fusion — it sets a new benchmark for the field.
But it also reminds us that technology isn’t perfect. The fatal flaw of color loss in clipped regions is a humbling reminder that even the most advanced AI has limits.
Yet, this challenge is also an opportunity — a call to researchers, engineers, and visionaries to push the boundaries further.
If you’re Interested in Knowledge Distillation Model, you may also find this article helpful: 5 Shocking Secrets of Skin Cancer Detection: How This SSD-KD AI Method Beats the Competition (And Why Others Fail)
Call to Action: Join the HDR Revolution!
🚀 Want to be part of the future of imaging?
- Download the code and dataset from https://github.com/ice-cream567/REHDR .
- Run experiments on your own data.
- Contribute improvements — fix the color recovery flaw!
- Share your results on social media with #HDRRevolution.
The next breakthrough in visual AI could come from you.
👉 Click here to get started now and transform how the world sees.
👉 Paper Link: Recurrent event-guided multimodal fusion for high dynamic range video reconstruction
Here is the complete, end-to-end PyTorch implementation of the REHDR model, based on the architecture and modules described in the research paper.
import torch
import torch.nn as nn
import torch.nn.functional as F
# ##############################################################################
# # 1. Core Building Blocks
# ##############################################################################
class ResBlock(nn.Module):
"""
Standard Residual Block used for feature extraction.
It consists of two 3x3 convolutional layers with LeakyReLU activation.
A 1x1 convolution is used in the skip connection if the number of input
and output channels are different.
"""
def __init__(self, in_channels, out_channels):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.leaky_relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
# Shortcut connection to match dimensions if necessary
if in_channels != out_channels:
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
else:
self.shortcut = nn.Identity()
def forward(self, x):
residual = self.shortcut(x)
out = self.conv1(x)
out = self.leaky_relu(out)
out = self.conv2(out)
out += residual
return out
class ConvLSTMCell(nn.Module):
"""
Convolutional LSTM Cell, the core component of the ConvLSTM layer.
This cell processes one time step of a sequence, updating its internal
cell state and hidden state.
"""
def __init__(self, in_channels, hidden_channels, kernel_size, bias=True):
super(ConvLSTMCell, self).__init__()
self.hidden_channels = hidden_channels
# Convolution for input and hidden states
self.conv = nn.Conv2d(
in_channels=in_channels + hidden_channels,
out_channels=4 * hidden_channels, # 4 gates: input, forget, output, cell
kernel_size=kernel_size,
padding=kernel_size // 2,
bias=bias
)
def forward(self, x_cur, h_prev, c_prev):
# Concatenate current input with previous hidden state
combined = torch.cat([x_cur, h_prev], dim=1)
# Compute all four gates in a single convolution
gates = self.conv(combined)
# Split the gates
i_gate, f_gate, o_gate, g_gate = torch.split(gates, self.hidden_channels, dim=1)
# Apply activations
i_gate = torch.sigmoid(i_gate)
f_gate = torch.sigmoid(f_gate)
o_gate = torch.sigmoid(o_gate)
g_gate = torch.tanh(g_gate)
# Update cell state and hidden state
c_next = f_gate * c_prev + i_gate * g_gate
h_next = o_gate * torch.tanh(c_next)
return h_next, c_next
def init_hidden(self, batch_size, image_size):
height, width = image_size
return (torch.zeros(batch_size, self.hidden_channels, height, width, device=self.conv.weight.device),
torch.zeros(batch_size, self.hidden_channels, height, width, device=self.conv.weight.device))
class ConvLSTM(nn.Module):
"""
Convolutional LSTM layer. This is a wrapper around the ConvLSTMCell that
handles sequence processing.
"""
def __init__(self, in_channels, hidden_channels, kernel_size=3, bias=True):
super(ConvLSTM, self).__init__()
self.cell = ConvLSTMCell(in_channels, hidden_channels, kernel_size, bias)
def forward(self, x, hidden_state=None):
# x is expected to be of shape (b, seq_len, c, h, w)
b, _, _, h, w = x.size()
# Initialize hidden state if not provided
if hidden_state is None:
hidden_state = self.cell.init_hidden(b, (h, w))
h_prev, c_prev = hidden_state
outputs = []
# Process sequence step-by-step
for t in range(x.size(1)):
h_next, c_next = self.cell(x[:, t, :, :, :], h_prev, c_prev)
outputs.append(h_next)
h_prev, c_prev = h_next, c_next
# Stack outputs along the time dimension
return torch.stack(outputs, dim=1), (h_prev, c_prev)
# ##############################################################################
# # 2. Adaptive Feature Modulation Fusion (AFMF) Module
# ##############################################################################
class DynamicRangeMask(nn.Module):
"""
Generates a dynamic range mask to suppress erroneous features in
overexposed/underexposed regions of the LDR frames.
As described in Fig. 3(a) of the paper.
"""
def __init__(self, channels):
super(DynamicRangeMask, self).__init__()
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.sigmoid = nn.Sigmoid()
def forward(self, ldr_features, ldr_input_downscaled):
# ldr_input_downscaled is the original LDR image, downscaled to match
# the feature map size.
# Combine deep features with original image features
combined_features = self.conv1(ldr_features) + ldr_input_downscaled
# Generate pixel-wise attention weights
pixel_attention = self.sigmoid(self.conv2(combined_features))
# Modulate the LDR features
masked_features = pixel_attention * self.conv1(ldr_features) + ldr_features
return masked_features
class ChannelAttention(nn.Module):
"""
Squeeze-and-Excitation style Channel Attention module.
"""
def __init__(self, channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class AFMF(nn.Module):
"""
Adaptive Feature Modulation Fusion Module.
This module integrates LDR and event features effectively.
As described in Fig. 3(c) of the paper.
"""
def __init__(self, channels):
super(AFMF, self).__init__()
self.dynamic_mask = DynamicRangeMask(channels)
# Fusion part
self.fusion_conv = nn.Sequential(
nn.Conv2d(channels * 2, channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# Attention to weigh the two modalities
self.gap = nn.AdaptiveAvgPool2d(1)
self.attention_conv = nn.Conv2d(channels, channels * 2, kernel_size=1)
# Final refinement
self.ca = ChannelAttention(channels)
self.out_conv = nn.Conv2d(channels, channels, kernel_size=1)
def forward(self, ldr_features, event_features, ldr_input_downscaled):
# 1. Apply Dynamic Range Mask to LDR features
ldr_features_masked = self.dynamic_mask(ldr_features, ldr_input_downscaled)
# 2. Initial concatenation and fusion
concatenated_features = torch.cat([ldr_features_masked, event_features], dim=1)
f_in = self.fusion_conv(concatenated_features)
# 3. Generate attention weights for each modality
attention_weights = self.attention_conv(self.gap(f_in))
w1, w2 = torch.softmax(attention_weights.view(attention_weights.size(0), 2, -1), dim=1).chunk(2, dim=1)
w1 = w1.squeeze(1).unsqueeze(2).unsqueeze(3) # Reshape to (b, c, 1, 1)
w2 = w2.squeeze(1).unsqueeze(2).unsqueeze(3)
# 4. Weighted fusion
fused_features = w1 * ldr_features_masked + w2 * event_features
# 5. Apply Channel Attention and final convolution
f_out = self.out_conv(self.ca(fused_features))
return f_out
# ##############################################################################
# # 3. Main REHDR Network
# ##############################################################################
class Encoder(nn.Module):
"""
The dual-encoder part of the U-Net architecture.
"""
def __init__(self, in_channels, base_c=32):
super(Encoder, self).__init__()
self.init_conv_ldr = ResBlock(in_channels, base_c)
self.init_conv_evt = ResBlock(in_channels, base_c)
# Downsampling layers
self.enc1_ldr = nn.Sequential(ResBlock(base_c, base_c), nn.Conv2d(base_c, base_c*2, 4, 2, 1))
self.enc1_evt = nn.Sequential(ResBlock(base_c, base_c), nn.Conv2d(base_c, base_c*2, 4, 2, 1))
self.enc2_ldr = nn.Sequential(ResBlock(base_c*2, base_c*2), nn.Conv2d(base_c*2, base_c*4, 4, 2, 1))
self.enc2_evt = nn.Sequential(ResBlock(base_c*2, base_c*2), nn.Conv2d(base_c*2, base_c*4, 4, 2, 1))
# Fusion modules
self.afmf1 = AFMF(base_c * 2)
self.afmf2 = AFMF(base_c * 4)
# Recurrent block
self.conv_lstm = ConvLSTM(base_c * 4, base_c * 4)
def forward(self, ldr, event, ldr_orig, hidden_state):
# Initial feature extraction
ldr_feat_init = self.init_conv_ldr(ldr)
evt_feat_init = self.init_conv_evt(event)
# Level 1
ldr_feat1 = self.enc1_ldr(ldr_feat_init)
evt_feat1 = self.enc1_evt(evt_feat_init)
ldr_down1 = F.interpolate(ldr_orig, scale_factor=0.5, mode='bilinear', align_corners=False)
fused1 = self.afmf1(ldr_feat1, evt_feat1, ldr_down1)
# Level 2
ldr_feat2 = self.enc2_ldr(ldr_feat1)
evt_feat2 = self.enc2_evt(evt_feat1)
ldr_down2 = F.interpolate(ldr_orig, scale_factor=0.25, mode='bilinear', align_corners=False)
fused2 = self.afmf2(ldr_feat2, evt_feat2, ldr_down2)
# Recurrent processing
# ConvLSTM expects (b, seq, c, h, w), so we unsqueeze dim 1
recurrent_out, next_hidden_state = self.conv_lstm(fused2.unsqueeze(1), hidden_state)
recurrent_out = recurrent_out.squeeze(1) # Back to (b, c, h, w)
# Return features for skip connections and the final encoded feature
return recurrent_out, fused1, evt_feat_init, next_hidden_state
class Decoder(nn.Module):
"""
The decoder part of the U-Net architecture.
"""
def __init__(self, out_channels, base_c=32):
super(Decoder, self).__init__()
# Upsampling layers
self.dec1 = nn.Sequential(
ResBlock(base_c*4, base_c*4),
nn.ConvTranspose2d(base_c*4, base_c*2, kernel_size=5, stride=2, padding=2, output_padding=1)
)
self.dec2 = nn.Sequential(
ResBlock(base_c*2, base_c*2),
nn.ConvTranspose2d(base_c*2, base_c, kernel_size=5, stride=2, padding=2, output_padding=1)
)
# Final output convolution
self.out_conv = nn.Conv2d(base_c, out_channels, kernel_size=3, padding=1)
def forward(self, x, skip1, skip2):
# x is the output from the encoder's recurrent block
up1 = self.dec1(x)
# Combine with skip connection 1
cat1 = up1 + skip1
up2 = self.dec2(cat1)
# Combine with skip connection 2
cat2 = up2 + skip2
# Final output
out = self.out_conv(cat2)
return out
class REHDR(nn.Module):
"""
The complete Recurrent Event-Guided HDR Reconstruction Network.
This model takes a sequence of LDR frames and event tensors and outputs
a sequence of reconstructed HDR frames.
"""
def __init__(self, in_channels=3, out_channels=3, base_c=32):
super(REHDR, self).__init__()
self.encoder = Encoder(in_channels, base_c)
self.decoder = Decoder(out_channels, base_c)
# Intermediate residual blocks connecting encoder and decoder
self.intermediate1 = ResBlock(base_c*4, base_c*4)
self.intermediate2 = ResBlock(base_c*4, base_c*4)
def forward(self, ldr_sequence, event_sequence):
"""
Processes a sequence of LDR images and event tensors.
Args:
ldr_sequence (Tensor): Shape (B, T, C_in, H, W)
event_sequence (Tensor): Shape (B, T, C_in, H, W)
Returns:
Tensor: Reconstructed HDR sequence, shape (B, T, C_out, H, W)
"""
batch_size, seq_len, _, h, w = ldr_sequence.size()
# Initialize hidden state for the ConvLSTM
hidden_state = self.encoder.conv_lstm.cell.init_hidden(batch_size, (h // 4, w // 4))
output_sequence = []
# Iterate over the time dimension of the sequence
for t in range(seq_len):
ldr_frame = ldr_sequence[:, t, ...]
event_frame = event_sequence[:, t, ...]
# Encoder pass
encoded_feat, skip1, skip2, hidden_state = self.encoder(ldr_frame, event_frame, ldr_frame, hidden_state)
# Intermediate blocks
intermediate_feat = self.intermediate1(encoded_feat)
intermediate_feat = self.intermediate2(intermediate_feat)
# Decoder pass
decoded_frame = self.decoder(intermediate_feat, skip1, skip2)
# Add the residual from the input LDR frame
hdr_frame = decoded_frame + ldr_frame
output_sequence.append(hdr_frame)
return torch.stack(output_sequence, dim=1)