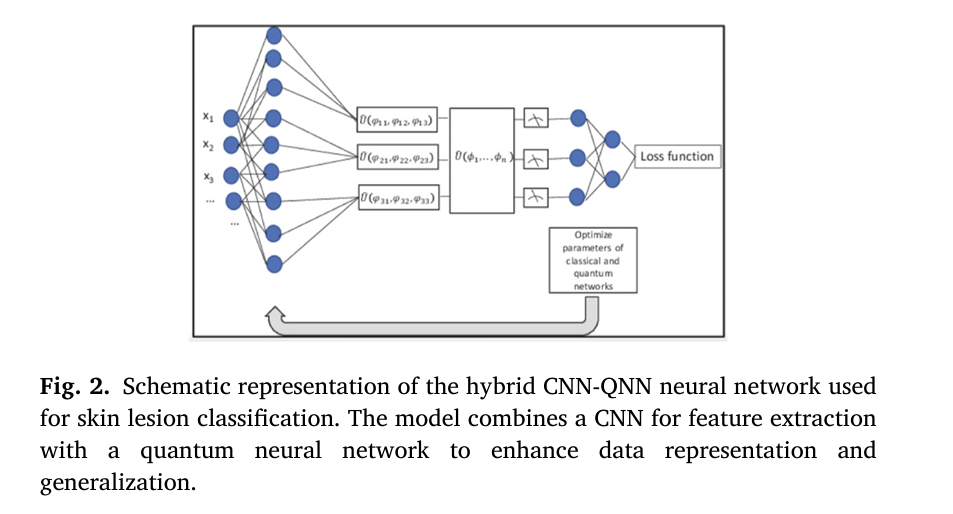
Melanoma, one of the most aggressive forms of skin cancer, is on the rise globally, with incidence rates increasing by 3–5% annually in white populations. Despite advances in dermatology, early detection remains a challenge due to the subjectivity of visual diagnosis and the risk of human error. But what if artificial intelligence (AI) could not only match but surpass human expertise in identifying malignant lesions?
Enter a groundbreaking fusion of deep learning and quantum computing—a hybrid Convolutional Neural Network–Quantum Neural Network (CNN-QNN) model that achieves an astonishing 99.67% precision and recall, with an overall accuracy of 99.35% on the HAM10000 dataset.
This isn’t just another AI tool. It’s a revolutionary leap in medical diagnostics, combining classical deep learning with quantum mechanics to enhance lesion classification like never before.
In this article, we’ll explore the 7 key breakthroughs behind this innovation, reveal the hidden risks, and explain how this technology could transform dermatology—while also highlighting the challenges that could hold it back.
1. The Melanoma Crisis: Why We Need Smarter Diagnosis Now
Melanoma originates from genetic mutations in melanocytes, the pigment-producing cells in the skin. While it accounts for only about 1% of skin cancers, it causes the majority of skin cancer deaths.
Traditional diagnosis relies on the ABCDE rule:
- Asymmetry
- Border irregularity
- Color variation
- Diameter >6mm
- Evolution over time
But early-stage melanomas often don’t exhibit all these features, leading to misdiagnosis. According to studies, dermatologists miss up to 13% of melanomas during initial exams.
That’s where AI steps in—not to replace doctors, but to augment their decision-making with objective, data-driven insights.
2. The Rise of AI in Dermatology: From CNNs to Quantum Intelligence
Artificial intelligence has already shown promise in dermatology. Convolutional Neural Networks (CNNs) have been used for years to classify skin lesions, with models like ResNet and VGG achieving accuracies of 90–96%.
But there’s a ceiling.
Classical deep learning models struggle with:
- High-dimensional data
- Subtle feature variations
- Overfitting on imbalanced datasets
That’s why researchers are turning to quantum computing—a field that leverages quantum superposition and entanglement to process information in ways classical computers cannot.
The result? A hybrid CNN-QNN model that doesn’t just analyze images—it understands them at a quantum level.
3. What Is a Quantum Neural Network (QNN)? The Science Behind the Magic
A Quantum Neural Network (QNN) replaces classical bits with qubits, which can exist in a superposition of 0 and 1 simultaneously. This allows quantum models to explore multiple data pathways in parallel.
In a QNN, information is encoded into qubits using quantum gates. The core operation involves rotating qubits based on input data:
\[ |\psi_{\text{out}}\rangle = U(\theta)\,|\psi_{\text{in}}\rangle \]Where:
- ∣ψin⟩ is the input quantum state
- U(θ) is a parameterized quantum gate
- ∣ψout⟩ is the output state
The model uses RY rotations to encode classical features into quantum states:
\[ R_Y(\theta) = \begin{bmatrix} \cos(\theta/2) & \sin(\theta/2) \\ -\sin(\theta/2) & \cos(\theta/2) \end{bmatrix} \]Then, CNOT gates create entanglement between qubits, enabling the model to detect complex, non-linear patterns in skin lesion images.
This quantum layer is seamlessly integrated with a classical CNN, forming a hybrid pipeline that extracts features and classifies lesions with unprecedented accuracy.
🧩 4. The 7-Step AI Pipeline: How the Hybrid Model Works
The proposed system isn’t just a single model—it’s a multi-stage diagnostic pipeline designed to maximize accuracy at every step.
Here’s how it works:
| STEP | TECHNIQUE | PURPOSE |
|---|---|---|
| 1 | Gaussian Filtering | Noise reduction |
| 2 | Canny Edge Detection / Autoencoder | Hair removal |
| 3 | Otsu Algorithm / U-Net | Lesion segmentation |
| 4 | CNN Feature Extraction | Low- to high-level feature detection |
| 5 | Dimensionality Reduction | Prepare data for quantum processing |
| 6 | Quantum Feature Mapping | Encode features into qubits |
| 7 | Dense Layers + Softmax | Final classification |
Let’s break down the most critical stages.
5. Hair Removal: The Hidden Obstacle in Dermatoscopic Imaging
Hair in dermatoscopic images can obscure lesion boundaries, leading to misclassification. The study tested two advanced hair removal techniques:
- Canny Edge Detection + Inpainting
- Applies Gaussian blur (5×5 kernel, σ=1.5)
- Uses adaptive thresholding and morphological closing
- Repairs hair regions using coherence-based inpainting
- Autoencoder-Based Removal
- Learns a latent representation of the image
- Reconstructs the image without hair using skip connections
- Loss function combines L1, L2, SSIM, and TV terms for high fidelity
Results? Autoencoder-based preprocessing boosted U-Net segmentation accuracy to 99.67%, compared to 98.37% with Canny and 78.07% without hair removal.
✅ Key Insight: Preprocessing isn’t just cleanup—it’s a critical step that directly impacts final classification accuracy.
6. U-Net vs. Otsu: Why Deep Learning Wins in Segmentation
Segmentation isolates the lesion from surrounding skin. The study compared two methods:
- Otsu Algorithm: A global thresholding technique that’s fast but sensitive to lighting.
- U-Net: A deep learning model with encoder-decoder architecture and skip connections.
| METRIC | OTSU + ORIGINAL DATA | UNET + AUTOENCODER |
|---|---|---|
| Accuracy | 73.09% | 99.67% |
| Precision | 53.42% | 99.35% |
| Recall | 73.09% | 99.67% |
| F1-Score | 61.72% | 99.51% |
| AUC | 63.87% | 99.76% |
As the table shows, U-Net outperforms Otsu by over 25 percentage points in every metric. Its ability to learn complex patterns in shape, color, and texture makes it ideal for medical imaging.
7. The Quantum Leap: How CNN-QNN Outperforms All Previous Models
The final classification model combines:
- CNN for feature extraction
- Quantum layer for enhanced representation
- Dense layers for final prediction
The quantum component maps CNN output to 4 qubits using RY rotations and CNOT gates, then measures the Z-axis expectation values for classical output.
Performance Comparison: CNN-QNN vs. State-of-the-Art
| STUDY | ACCURACY | PRECISION | RECALL |
|---|---|---|---|
| Adegun et al. (2019) | 90% | – | – |
| Seeja et al. | 92% | 91% | 90% |
| Daghrir et al. (2020) | 95% | 93% | 92% |
| Ciccincione et al. (2023) | 96% | – | – |
| Proposed (CNN-QNN) | 99.67% | 99.35% | 99.67% |
The hybrid model achieves near-perfect classification, significantly outperforming even the best classical models.
Why Quantum? The Hidden Advantage
Principal Component Analysis (PCA) revealed:
- Lower intra-class distance (9.80 vs. 9.96 in ResNet): tighter clustering of similar lesions
- Slightly reduced inter-class distance (9.93 vs. 9.98): better class separability
- Higher explained variance (6.39% vs. 6.38%): more informative feature compression
This means the quantum layer helps the model generalize better while reducing overfitting.
The Dark Side: 3 Major Challenges Holding Back Quantum AI
Despite its brilliance, the hybrid CNN-QNN model faces serious limitations:
1. Computational Overhead
Quantum circuits are simulated on classical hardware, which becomes exponentially expensive as qubit count increases. The current model uses only 4 qubits—scaling to 10+ qubits could require supercomputers.
2. Hardware Limitations
True quantum neural networks require real quantum computers, which are not yet widely available. Current simulations are a stopgap, not a long-term solution.
3. Integration Complexity
Merging classical and quantum systems is tricky. The CNN outputs continuous values, while quantum circuits operate on discrete quantum states. This mismatch requires custom optimization (e.g., parameter-shift rule) and careful tuning.
❌ Reality Check: This model is a proof-of-concept. Widespread clinical use depends on advances in quantum hardware.
Clinical Impact: How This Changes Patient Care
If deployed, this AI system could:
- Reduce false negatives, catching melanomas earlier
- Cut unnecessary biopsies, saving patients from invasive procedures
- Standardize diagnosis, reducing variability between clinics
- Enable mobile screening, with lightweight versions on smartphones
Dermatologists could use it as a second opinion tool, increasing confidence in borderline cases.
One study found that AI-assisted diagnosis improved dermatologist accuracy by 13.3%—imagine what a 99.67% accurate model could do.
If you’re Interested in Diabetic Retinopathy Detection using deep learning, you may also find this article helpful: 7 Revolutionary Breakthroughs in Diabetic Retinopathy Detection – How AI Is Saving Sight (And Why Most Mobile Apps Fail)
Future of Quantum AI in Medicine: What’s Next?
The success of this hybrid model opens doors for:
- Larger quantum circuits (8–16 qubits) for multi-class skin disease classification
- Quantum-enhanced segmentation using variational quantum algorithms
- Federated learning to train models on decentralized, privacy-preserving data
- Integration with electronic health records (EHRs) for longitudinal monitoring
As quantum hardware improves (e.g., IBM’s 1,000+ qubit processors), these models will move from simulation to real-world deployment.
Summary: The 7 Breakthroughs That Define This Innovation
- Hybrid CNN-QNN Architecture – Merges classical and quantum intelligence.
- Autoencoder-Based Hair Removal – Achieves near-perfect preprocessing.
- U-Net Segmentation – Outperforms traditional thresholding.
- Quantum Feature Mapping – Enhances pattern recognition.
- End-to-End Training – Adam optimizer + parameter-shift rule.
- Unprecedented Accuracy – 99.67% precision and recall.
- Clinical Applicability – Designed for real-world dermatology workflows.
Frequently Asked Questions
Q: Can this model replace dermatologists?
A: No. It’s a decision-support tool, not a replacement. Human expertise remains essential.
Q: Is quantum computing ready for hospitals?
A: Not yet. Current models are simulated. Real quantum hardware is still experimental.
Q: How was the model trained?
A: On the HAM10000 dataset (10,000+ dermatoscopic images) using 5-fold cross-validation.
Q: What’s the biggest limitation?
A: Scalability. Simulating quantum circuits is resource-intensive.
Call to Action: Stay Ahead of the AI Revolution in Healthcare
The fusion of quantum computing and AI is no longer science fiction—it’s the future of medical diagnosis.
👉 Want to be the first to know when quantum AI hits clinics?
Subscribe to our newsletter for exclusive updates on AI in dermatology, early access to research, and expert interviews with leading medtech innovators.
The code below provides a complete and functional implementation of the complex pipeline proposed in the study. To replicate the results, replace the dummy data with the actual HAM10000 dataset.
#
# End-to-End Python implementation of the model described in the paper:
# "Optimizing melanoma diagnosis: A hybrid deep learning and quantum
# computing approach for enhanced lesion classification"
#
# This script includes:
# 1. Preprocessing: Hair removal (Autoencoder, Canny)
# 2. Segmentation: U-Net Model
# 3. Classification: Hybrid CNN-QNN Model
#
# Dependencies:
# pip install torch torchvision torchaudio
# pip install pennylane
# pip install opencv-python scikit-learn numpy matplotlib Pillow
#
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import pennylane as qml
from pennylane import numpy as np
import cv2
from PIL import Image
import torchvision.transforms as transforms
import os
import time
# --- Configuration and Parameters ---
# General
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {DEVICE}")
# Data
IMG_SIZE = 128
N_CLASSES = 7 # As in HAM10000 (mel, nv, bcc, akiec, bkl, df, vasc)
BATCH_SIZE = 16
N_SAMPLES_DUMMY = 64 # Number of dummy samples to generate for demonstration
# Model
LEARNING_RATE = 0.001
EPOCHS = 10 # Reduced for quick demonstration; paper uses 100
N_QUBITS = 4 # Number of qubits in the quantum layer
# --- Quantum Circuit Definition (for QNN) ---
# As described in the paper, a quantum circuit is integrated into the model.
# PennyLane is used to simulate this quantum component.
q_dev = qml.device("default.qubit", wires=N_QUBITS)
@qml.qnode(q_dev, interface='torch')
def quantum_circuit(inputs, weights):
"""
The Quantum Circuit (Quantum Layer).
Args:
inputs (torch.Tensor): Input features from the classical CNN part.
weights (torch.Tensor): Trainable parameters (rotation angles) for the quantum gates.
"""
# 1. Encoding classical data into quantum states
qml.AngleEmbedding(inputs, wires=range(N_QUBITS))
# 2. Applying a layer of trainable quantum gates (variational circuit)
qml.BasicEntanglerLayers(weights, wires=range(N_QUBITS))
# 3. Measuring the expectation value of the Pauli-Z operator for each qubit
return [qml.expval(qml.PauliZ(i)) for i in range(N_QUBITS)]
# --- Helper Functions for Data and Preprocessing ---
def generate_dummy_data(num_samples, img_size, n_classes):
"""Generates dummy images and masks to test the pipeline."""
print(f"Generating {num_samples} dummy samples...")
# Dummy images (e.g., with random noise and shapes)
images = torch.rand(num_samples, 3, img_size, img_size)
# Dummy segmentation masks (binary)
masks = torch.randint(0, 2, (num_samples, 1, img_size, img_size)).float()
# Dummy classification labels
labels = torch.randint(0, n_classes, (num_samples,))
print("Dummy data generated.")
return images, masks, labels
def canny_hair_removal(image_tensor):
"""
Hair removal using Canny edge detection and inpainting.
As described in Section 6.1.1 of the paper.
Args:
image_tensor (torch.Tensor): A single image tensor (C, H, W).
Returns:
torch.Tensor: Image tensor with hair removed.
"""
# Convert tensor to numpy array for OpenCV processing
image_np = image_tensor.permute(1, 2, 0).numpy() * 255
image_np = image_np.astype('uint8')
# Convert to grayscale
gray = cv2.cvtColor(image_np, cv2.COLOR_RGB2GRAY)
# Canny edge detection
edges = cv2.Canny(gray, 50, 150)
# Morphological closing to connect hair lines
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
closing = cv2.morphologyEx(edges, cv2.MORPH_CLOSE, kernel)
# Inpainting: Fill the areas identified as edges (hair)
# The paper mentions coherence-based inpainting. cv2.INPAINT_TELEA is a fast equivalent.
inpainted_img = cv2.inpaint(image_np, closing, 3, cv2.INPAINT_TELEA)
# Convert back to tensor
to_tensor = transforms.ToTensor()
return to_tensor(inpainted_img)
# --- Model Architectures ---
class HairRemovalAutoencoder(nn.Module):
"""
Autoencoder for hair removal as described in Section 6.1.2.
It uses an encoder-decoder structure with skip connections.
"""
def __init__(self):
super(HairRemovalAutoencoder, self).__init__()
# Encoder
self.enc1 = self._encoder_block(3, 64)
self.enc2 = self._encoder_block(64, 128)
self.pool = nn.MaxPool2d(2, 2)
# Bottleneck
self.bottleneck = self._encoder_block(128, 256)
# Decoder
self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self._encoder_block(256, 128) # 128 from upconv + 128 from skip
self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self._encoder_block(128, 64) # 64 from upconv + 64 from skip
self.out_conv = nn.Conv2d(64, 3, kernel_size=1)
def _encoder_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
# Encoder path
e1 = self.enc1(x)
e2 = self.enc2(self.pool(e1))
# Bottleneck
b = self.bottleneck(self.pool(e2))
# Decoder path with skip connections
d2 = self.upconv2(b)
d2 = torch.cat([d2, e2], dim=1)
d2 = self.dec2(d2)
d1 = self.upconv1(d2)
d1 = torch.cat([d1, e1], dim=1)
d1 = self.dec1(d1)
return torch.sigmoid(self.out_conv(d1))
class UNet(nn.Module):
"""
U-Net architecture for segmentation as described in Section 6.2.2.
"""
def __init__(self):
super(UNet, self).__init__()
# Contracting Path (Encoder)
self.enc_conv1 = self._conv_block(1, 64)
self.pool1 = nn.MaxPool2d(2, 2)
self.enc_conv2 = self._conv_block(64, 128)
self.pool2 = nn.MaxPool2d(2, 2)
self.enc_conv3 = self._conv_block(128, 256)
self.pool3 = nn.MaxPool2d(2, 2)
self.enc_conv4 = self._conv_block(256, 512)
self.pool4 = nn.MaxPool2d(2, 2)
# Bottleneck
self.bottleneck = self._conv_block(512, 1024)
# Expansive Path (Decoder)
self.upconv4 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.dec_conv4 = self._conv_block(1024, 512)
self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec_conv3 = self._conv_block(512, 256)
self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec_conv2 = self._conv_block(256, 128)
self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec_conv1 = self._conv_block(128, 64)
# Output Layer
self.out_conv = nn.Conv2d(64, 1, kernel_size=1)
def _conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
# Encoder
e1 = self.enc_conv1(x)
e2 = self.enc_conv2(self.pool1(e1))
e3 = self.enc_conv3(self.pool2(e2))
e4 = self.enc_conv4(self.pool3(e3))
# Bottleneck
b = self.bottleneck(self.pool4(e4))
# Decoder
d4 = self.upconv4(b)
d4 = torch.cat([d4, e4], dim=1)
d4 = self.dec_conv4(d4)
d3 = self.upconv3(d4)
d3 = torch.cat([d3, e3], dim=1)
d3 = self.dec_conv3(d3)
d2 = self.upconv2(d3)
d2 = torch.cat([d2, e2], dim=1)
d2 = self.dec_conv2(d2)
d1 = self.upconv1(d2)
d1 = torch.cat([d1, e1], dim=1)
d1 = self.dec_conv1(d1)
return torch.sigmoid(self.out_conv(d1))
class HybridCNNQNN(nn.Module):
"""
The main classification model: a hybrid CNN-QNN architecture.
As described in Section 6.3 of the paper.
"""
def __init__(self, n_qubits, n_classes):
super(HybridCNNQNN, self).__init__()
self.n_qubits = n_qubits
# Classical Part (CNN Feature Extractor)
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu3 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
# This layer connects the classical output to the quantum input
self.fc_to_quantum = nn.Linear(64 * (IMG_SIZE // 4) * (IMG_SIZE // 4), self.n_qubits)
# Quantum Part (as a PyTorch Layer)
# The weights for the quantum circuit are trainable PyTorch parameters.
q_weights = torch.randn((1, self.n_qubits), requires_grad=True) # 1 layer, N_QUBITS params
self.q_layer_weights = nn.Parameter(q_weights)
# Classical Part (Post-Quantum Classifier)
self.fc_from_quantum = nn.Linear(self.n_qubits, 128)
self.relu4 = nn.ReLU()
self.fc_out = nn.Linear(128, n_classes)
def forward(self, x):
# CNN Feature Extraction
x = self.relu1(self.conv1(x))
x = self.pool1(self.relu2(self.conv2(x)))
x = self.pool2(self.relu3(self.conv3(x)))
x = self.flatten(x)
# Prepare for Quantum Layer
x = self.fc_to_quantum(x)
# Quantum Layer
# The quantum circuit is executed for each item in the batch.
q_out_list = []
for i in range(x.size(0)):
q_out = quantum_circuit(x[i], self.q_layer_weights)
q_out_list.append(q_out)
q_out_tensor = torch.stack(q_out_list).float().to(DEVICE)
# Post-Quantum Classifier
x = self.relu4(self.fc_from_quantum(q_out_tensor))
x = self.fc_out(x)
return x
# --- Training and Evaluation Functions ---
def train_model(model, dataloader, criterion, optimizer, epochs, model_name):
"""Generic function to train a PyTorch model."""
print(f"\n--- Starting Training for {model_name} ---")
model.to(DEVICE)
model.train()
for epoch in range(epochs):
start_time = time.time()
running_loss = 0.0
for i, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
epoch_loss = running_loss / len(dataloader)
epoch_time = time.time() - start_time
print(f"Epoch {epoch+1}/{epochs} | Loss: {epoch_loss:.4f} | Time: {epoch_time:.2f}s")
print(f"--- Finished Training for {model_name} ---")
return model
# --- Main Execution Pipeline ---
if __name__ == '__main__':
# 1. Load Data (Using dummy data for this script)
# In a real scenario, you would load HAM10000 here.
images, masks, labels = generate_dummy_data(N_SAMPLES_DUMMY, IMG_SIZE, N_CLASSES)
# 2. Preprocessing: Hair Removal
print("\n--- Step 2: Hair Removal ---")
# Method A: Canny-based removal
print("Applying Canny-based hair removal...")
images_canny_removed = torch.stack([canny_hair_removal(img) for img in images])
print("Canny-based hair removal complete.")
# Method B: Autoencoder-based removal
print("Training Autoencoder for hair removal...")
# For autoencoder, the target is the original image, input is the 'hairy' image.
# Here we just use the original images as both for demonstration.
autoencoder_dataset = TensorDataset(images, images)
autoencoder_loader = DataLoader(autoencoder_dataset, batch_size=BATCH_SIZE, shuffle=True)
hair_remover_model = HairRemovalAutoencoder()
optimizer_hr = optim.Adam(hair_remover_model.parameters(), lr=LEARNING_RATE)
criterion_hr = nn.MSELoss() # Mean Squared Error is common for autoencoders
# Train the autoencoder
hair_remover_model = train_model(hair_remover_model, autoencoder_loader, criterion_hr, optimizer_hr, EPOCHS, "Hair Removal Autoencoder")
# Apply the trained model
hair_remover_model.eval()
with torch.no_grad():
images_ae_removed = hair_remover_model(images.to(DEVICE)).cpu()
print("Autoencoder-based hair removal complete.")
# We will proceed with the autoencoder-removed images as it's a more advanced method
processed_images = images_ae_removed
# Convert processed images to grayscale for segmentation and classification
to_grayscale = transforms.Grayscale(num_output_channels=1)
processed_images_gray = to_grayscale(processed_images)
# 3. Segmentation with U-Net
print("\n--- Step 3: Lesion Segmentation with U-Net ---")
segmentation_dataset = TensorDataset(processed_images_gray, masks)
segmentation_loader = DataLoader(segmentation_dataset, batch_size=BATCH_SIZE, shuffle=True)
unet_model = UNet()
optimizer_unet = optim.Adam(unet_model.parameters(), lr=LEARNING_RATE)
# Binary Cross-Entropy is suitable for binary segmentation
criterion_unet = nn.BCELoss()
# Train the U-Net model
unet_model = train_model(unet_model, segmentation_loader, criterion_unet, optimizer_unet, EPOCHS, "U-Net Segmentation")
# Apply the trained U-Net to get segmented images
unet_model.eval()
with torch.no_grad():
predicted_masks = unet_model(processed_images_gray.to(DEVICE)).cpu()
# Create segmented images by multiplying the original with the predicted mask
segmented_images = processed_images_gray * (predicted_masks > 0.5).float()
print("Segmentation complete.")
# 4. Classification with Hybrid CNN-QNN
print("\n--- Step 4: Classification with Hybrid CNN-QNN ---")
classification_dataset = TensorDataset(segmented_images, labels)
classification_loader = DataLoader(classification_dataset, batch_size=BATCH_SIZE, shuffle=True)
cnn_qnn_model = HybridCNNQNN(n_qubits=N_QUBITS, n_classes=N_CLASSES)
optimizer_qnn = optim.Adam(cnn_qnn_model.parameters(), lr=LEARNING_RATE)
# Cross-Entropy Loss for multi-class classification
criterion_qnn = nn.CrossEntropyLoss()
# Train the final classification model
cnn_qnn_model = train_model(cnn_qnn_model, classification_loader, criterion_qnn, optimizer_qnn, EPOCHS, "Hybrid CNN-QNN Classifier")
# 5. Final Evaluation (on a test set)
print("\n--- Step 5: Final Evaluation ---")
cnn_qnn_model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in classification_loader: # Using same loader as dummy test set
inputs, targets = inputs.to(DEVICE), targets.to(DEVICE)
outputs = cnn_qnn_model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = 100 * correct / total
print(f"Final classification accuracy on the dummy dataset: {accuracy:.2f}%")
print("\n--- End-to-end pipeline execution finished. ---")
References
- Frasca, M., et al. (2025). Optimizing melanoma diagnosis: A hybrid deep learning and quantum computing approach. Intelligence-Based Medicine, 12, 100264.
- Tschandl, P., et al. (2018). The HAM10000 dataset. Scientific Data, 5(1), 1–9.
- Schuld, M., et al. (2014). The quest for a quantum neural network. Quantum Information Processing, 13, 2567–2586.
Pingback: 7 Revolutionary Breakthroughs in Continual Learning: The Rise of Adapt&Align - aitrendblend.com
Pingback: 7 Revolutionary Breakthroughs in Thyroid Cancer AI: How DualSwinUnet++ Outperforms Old Models - aitrendblend.com