- Medical Imaging
- Knowledge Distillation
- Adaptive Temperature
- Brain Tumor
- Ant Colony Optimization
- Paper Analysis
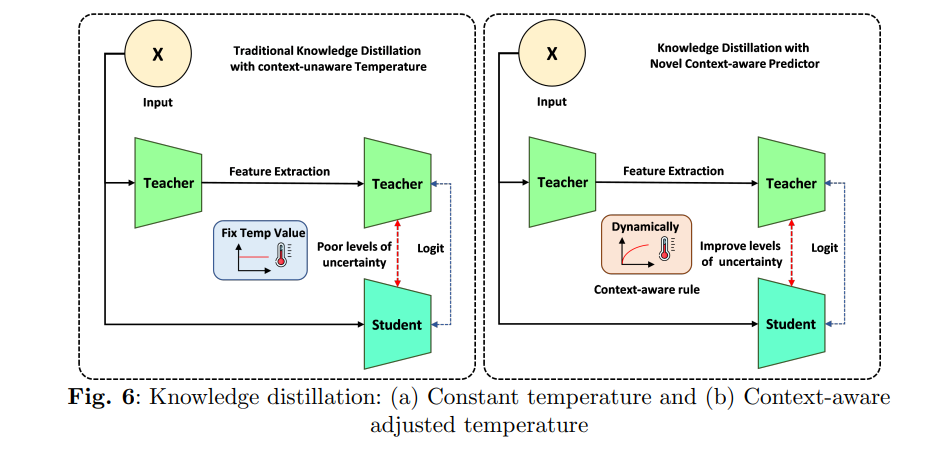
Two brain MRI scans arrive in the same batch. One is crisp, the tumor margin clean against healthy tissue, and any decent model would call it correctly. The other is smeared by motion, low in contrast, the boundary a guess. A radiologist treats these two scans with very different degrees of caution. Most knowledge distillation pipelines do not. They soften the teacher’s predictions with one fixed temperature for every image, the easy one and the ambiguous one alike. A preprint from the German Research Center for Artificial Intelligence and Rhineland-Palatinate Technical University argues that this single setting is the wrong default for medicine, and it proposes letting the temperature change with how uncertain each image actually is.
- The method makes the distillation temperature adapt per image, raising it when the teacher is uncertain so the student learns from softer labels, and lowering it when the teacher is confident.
- A set of context aware rules ties the temperature to image quality, teacher confidence, and disease complexity rather than to a single number fixed before training.
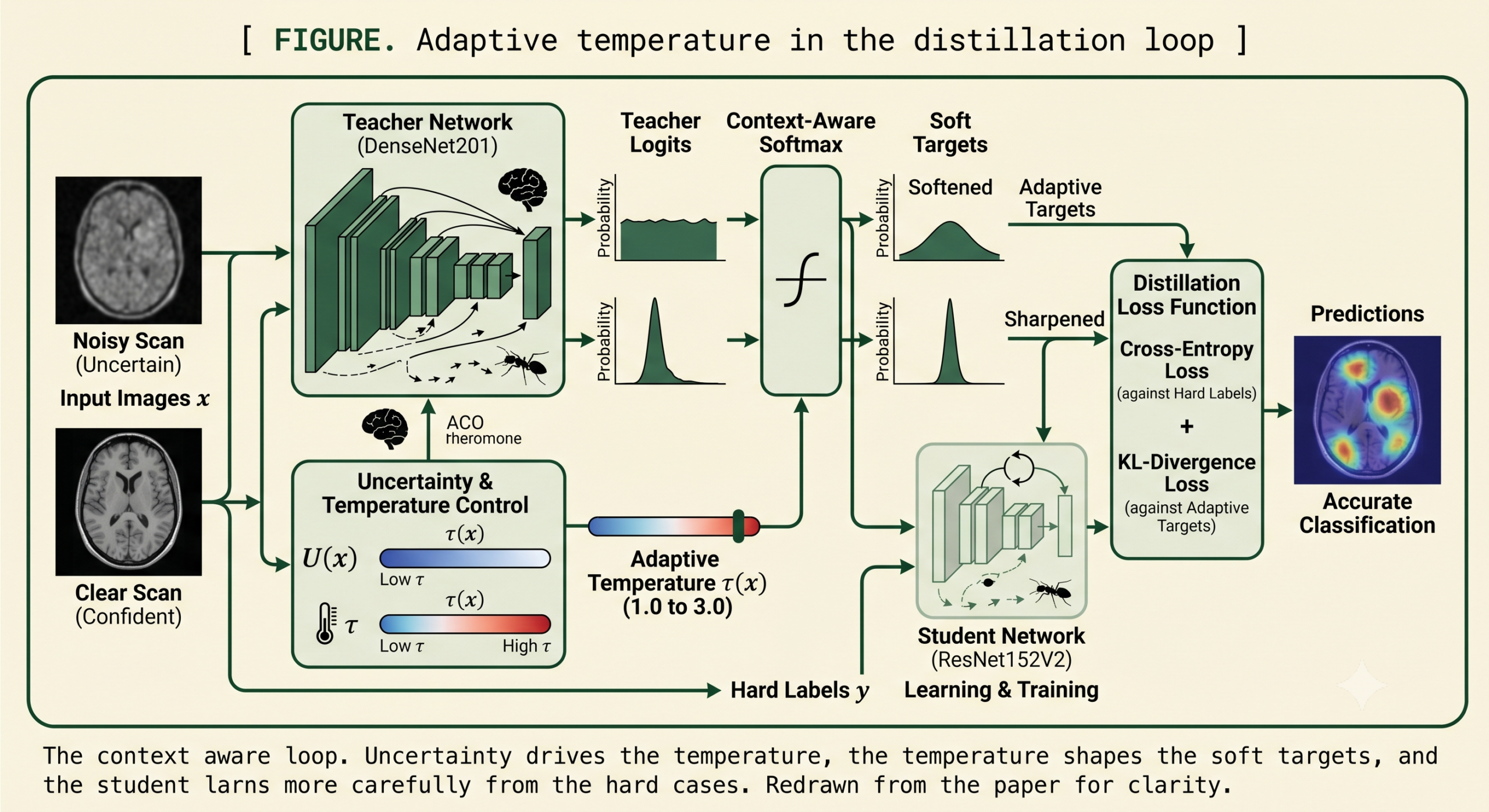
- Ant Colony Optimization picks the teacher and student from a pool of sixteen pretrained networks, landing on DenseNet201 as teacher and ResNet152V2 as student in 47 evaluations.
- On three public benchmarks the student reports 98.01 percent accuracy on the Kaggle brain MRI set, 92.81 percent on Figshare, and 96.20 percent on a gastrointestinal endoscopy set.
- These are retrospective results on curated public datasets. The paper is a preprint and reports no prospective or external clinical validation, a gap this analysis treats as central rather than incidental.
This article explains published research for a technical audience. It is not medical advice, diagnosis, or treatment, and the model it describes is a research prototype, not an approved diagnostic tool. The accuracy figures come from retrospective public datasets and have not been validated in a clinical setting. Anyone with a health concern should consult a qualified medical professional.
The clinical population this is meant to serve
The setting is multi disease classification from medical images, with two concrete targets. The first is brain tumor identification from MRI, separating the three common tumor types, glioma, meningioma, and pituitary tumor, from scans with no tumor. Gliomas are the dangerous end of that spectrum, and accurate early classification matters because it shapes how quickly a patient moves toward treatment. The second target is gastrointestinal disease from endoscopic images, covering colorectal cancer, esophagitis, and a normal pylorus class. Both tasks share the same practical difficulty. The images vary enormously in quality, and the cost of a confident wrong answer is high.
Knowledge distillation enters here as a compression and robustness tool. A large, accurate teacher network is expensive to run, so a smaller student is trained to imitate it, ideally keeping most of the accuracy at a fraction of the cost. That fits the constraints of hospital infrastructure, where a model may need to run on modest hardware. The question the paper raises is whether the standard distillation recipe, designed on clean natural image benchmarks, transfers cleanly to medical images where uncertainty is the rule rather than the exception.
Why one fixed temperature is the wrong default
In classical distillation the teacher’s logits are divided by a temperature before the softmax, which spreads probability mass across classes and exposes the relationships the teacher has learned. A higher temperature produces softer targets that reveal more about how the teacher ranks the runner up classes. A lower temperature keeps the targets sharp and close to the hard label. The student is then trained on a weighted sum of an ordinary cross entropy loss against the true label and a divergence term that pulls it toward the teacher’s softened distribution.
The trouble is the word fixed. That temperature is chosen once and applied to every image in the dataset, which silently assumes the uncertainty is uniform. In medical imaging it is not. A clean scan with an obvious lesion carries little uncertainty, and softening its already clear signal washes out information the student could use. A noisy scan with artifacts carries a great deal of uncertainty, and treating it with the same gentle softening as the clean one fails to give the student the broader, hedged signal it needs to learn the hard case. The paper frames this as the central weakness of conventional distillation for medicine. The same softening for confident and uncertain predictions limits how well the student learns from exactly the cases that matter most.
Uncertainty in medical images is not uniform, so the knowledge distillation temperature should not be uniform either. Raise it where the teacher is unsure to pass along a softer, more informative target, and lower it where the teacher is confident to keep the signal sharp.
Making the temperature read the image
The proposal replaces the constant temperature with one that is a function of the input. The teacher’s prediction is first scaled by a temperature in the usual way, producing a softened distribution over classes.
The change is to let that temperature depend on an uncertainty score for the specific image. When the score is high, meaning the teacher is hesitant or the image is noisy, the temperature rises. When the score is low, the temperature falls back toward its base value and the targets stay sharp.
Here the uncertainty score can be something like the entropy of the teacher’s prediction or the variance across an ensemble, and the scaling factor sets how strongly uncertainty moves the temperature. Feeding this per image temperature back into the softmax gives a context aware soft target that adapts to each scan.
A small worked example in the paper makes the effect concrete. Take teacher logits of 2.0, 0.5, and minus 1.0. Under a fixed temperature of 2.0 the softened probabilities come out near 0.61, 0.27, and 0.12. Now suppose the uncertainty score is 0.3 and the scaling factor is 2, so the adaptive temperature is 1.6. The same logits now soften to roughly 0.65, 0.23, and 0.12. A lower temperature on this relatively confident prediction keeps the top class sharper, which is exactly the intended behavior for an image the teacher reads clearly.
On top of this continuous adjustment the paper layers a set of plain language rules that encode clinical intuition. If an image is noisy and the teacher’s confidence is low, raise the temperature for softer labels. If an image is clear and the teacher is confident, lower the temperature for harder labels. If the disease itself is complex, give more weight to the teacher’s prediction. These rules are a readable wrapper around the same principle, steering the knowledge transfer toward caution on the hard cases and decisiveness on the easy ones.
“The honest contribution here is small and sensible. Stop pretending every scan is equally certain, and let the teacher’s own hesitation set how much it whispers to the student.”
aitrendblend editorial, on the adaptive temperature mechanism
Letting an ant colony choose the teacher and student
The second component addresses a question that usually gets answered by habit. Which teacher and which student should you even pair. With a pool of sixteen pretrained networks there are hundreds of possible combinations, and evaluating every pairing is wasteful. The paper turns to Ant Colony Optimization, a search method inspired by how ants find short paths by laying and following pheromone trails. Each candidate model starts with equal pheromone and a heuristic value tied to its validation accuracy. Artificial ants pick models in proportion to a blend of pheromone and heuristic, the chosen models are evaluated, strong performers get more pheromone, and weak trails evaporate over iterations.
The reported payoff is efficiency. The colony converges on its best teacher and student pairing in 47 evaluations and reaches 96.33 percent accuracy on the selection task, against 93.45 percent for Particle Swarm Optimization at 240 evaluations and 94.87 percent for a grid search at 1000 evaluations. Random selection, with a single evaluation, trails at 91.12 percent. The search settles on DenseNet201 as the teacher, a densely connected network whose feature reuse suits medical images, and ResNet152V2 as the student, a deep residual network that is lighter than several alternatives in the pool.
| Model selection strategy | Selection accuracy % | Model evaluations |
|---|---|---|
| Random selection | 91.12 | 1 |
| Particle Swarm Optimization | 93.45 | 240 |
| Grid search | 94.87 | 1000 |
| Ant Colony Optimization (this paper) | 96.33 | 47 |
What the benchmark numbers say
Training used a teacher and student pair selected by the colony, with the adaptive temperature mechanism layered onto an otherwise standard pipeline. The Kaggle brain MRI dataset holds 7023 scans across the four classes, normal, meningioma, pituitary, and glioma, and the model was trained with the Adam optimizer over 30 epochs at a learning rate of 0.001. On that benchmark the context aware student reaches 98.01 percent accuracy, up from 96.33 percent for the same student distilled with a constant temperature, and above the DenseNet201 teacher baseline of 95.33 percent and the ResNet152V2 student baseline of 95.19 percent. The area under the ROC curve rises to 0.9940 from 0.9869, and the confusion matrix on the 1311 image test set shows 1285 correct against 25 errors, compared with 1263 correct under the constant temperature setting.
The class level detail is where the result earns trust, because it does not hide the weak spot. Meningioma was the hardest class throughout. Under the constant temperature student its recall sat at 89.54 percent, meaning roughly one in ten meningioma cases was missed. The adaptive approach lifts that recall to 96.41 percent, the single largest class level gain in the table, while the easy normal class stays above 99 percent. That pattern, the biggest help going to the hardest class, is consistent with the method’s stated intent.
| Dataset | Constant temperature student % | Context aware student % | Prior benchmark cited % |
|---|---|---|---|
| Kaggle brain MRI | 96.33 | 98.01 | 97.24 |
| Figshare brain MRI | 90.03 | 92.81 | 91.43 |
| GastroNet endoscopy | 94.94 | 96.20 | 95.00 |
The pattern repeats on the other two datasets, which is what makes it more than a single lucky run. On the Figshare brain MRI set the adaptive student reaches 92.81 percent against a constant temperature baseline of 90.03 percent, with the pituitary class crossing 95 percent on every metric. On the gastrointestinal endoscopy set it reaches 96.20 percent against 94.94 percent, holding a perfect score on the colorectal cancer class while improving esophagitis precision. The paper also tests robustness to added noise and reports that accuracy degrades gracefully, sitting at 96.33 percent under uniform noise and 95.90 percent under Gaussian noise, down from 98.01 percent on clean data.
The gains over the cited prior benchmarks are real but modest, on the order of three quarters of a point to a point and a half. That is worth stating plainly. The story here is not a dramatic accuracy jump. It is a consistent improvement attributed to a simple change in how the temperature is set, supported by interpretability views from Grad-CAM and feature space plots from T-SNE that the authors use to argue the student attends to the right regions.
The clinical translation gap
This is the part of the story that deserves the most scrutiny, and the paper says less about it than its framing implies. Every number above comes from retrospective, curated, publicly available datasets. The scans were already collected, already labeled, and already cleaned into tidy class folders. A real hospital workflow looks nothing like that. Images arrive from different scanners with different settings, patient populations shift, labels are noisier and sometimes contested, and the rare presentations that matter most are precisely the ones underrepresented in a tidy benchmark. Accuracy on a held out split of a public dataset is a necessary first signal, not evidence of clinical readiness.
The paper includes a TRIPOD reporting checklist and a section headed clinical application that describes hospital integration, which gives the work a clinical sheen. None of that is the same as clinical validation. There is no prospective study, no external validation on data from an institution the model has never seen, no reader study comparing the tool against radiologists or pathologists, and no analysis of how the model behaves on the distribution shifts that break medical models in the field. Temperature scaling probabilities is also not the same as calibrating them to real risk, and a model can be accurate on a benchmark while being dangerously overconfident on the cases it gets wrong. For a tool that names cancer detection as its purpose, these are not optional next steps. They are the difference between a promising method and a deployable one.
Before anything like this reaches patients, it would need external validation on data from unseen hospitals, prospective evaluation in a real workflow, calibration analysis on its errors, and regulatory review. Benchmark accuracy, however high, does not substitute for any of these.
Honest limitations
Beyond the translation gap, several concrete limits sit in the paper itself. The datasets are small by clinical standards. The gastrointestinal set in particular is tiny, with the endoscopy test split reported at well under a hundred images, so a difference of a single misclassification moves the percentage noticeably and the confidence intervals around these numbers would be wide. The brain MRI sets are larger but still in the thousands, and the reported data split is described inconsistently in the text, which makes the exact evaluation protocol harder to pin down than it should be.
Dataset bias is a real concern. Public brain tumor collections skew toward certain scanners, certain institutions, and certain acquisition protocols, and a model that learns those incidental signatures can look excellent on the benchmark and fail on a scanner it has never seen. The authors themselves note that performance may suffer on images with very low contrast or unusual artifacts, the exact conditions the adaptive temperature is meant to help with, which is a candid admission that the mechanism has limits at the extremes. They also flag a risk of overfitting to specific image characteristics, which would cap generalization in the wild.
There is also an open question about the uncertainty score that drives the whole mechanism. If that score is itself unreliable on out of distribution images, the adaptive temperature inherits the unreliability, and a noisy scan could receive the wrong amount of softening. The method assumes the teacher’s hesitation is informative, which holds when the teacher is well trained on representative data and weakens when it is not. None of this sinks the contribution, but it does bound how far the benchmark wins should be read.
The takeaway for distillation in medical imaging
The genuine contribution of this work is a clean and reasonable idea, executed on a realistic problem. Conventional knowledge distillation inherited a fixed temperature from its origins on clean benchmarks, and medical imaging, where uncertainty varies wildly from one scan to the next, is a setting where that inheritance is a poor fit. Tying the temperature to a per image uncertainty score, and wrapping it in rules that mirror how a clinician weighs a noisy scan against a clear one, is the sort of small, defensible change that travels well to other domains with uneven data quality.
The Ant Colony Optimization piece is a pragmatic addition rather than a conceptual one. Searching a pool of sixteen models for a good teacher and student pairing in 47 evaluations instead of a thousand is a sensible efficiency, and the choice of DenseNet201 and ResNet152V2 is unsurprising and reasonable. It is the kind of automation that saves researcher time without claiming to be the heart of the method.
The empirical case is consistent across three datasets and two imaging modalities, which is more convincing than a single headline number would be. The largest gains landing on the hardest class, meningioma, and the graceful degradation under added noise both point in the direction the method intends. These are the results that make the idea worth taking seriously as a research contribution.
The caution is about register, not about the method. The paper reaches for clinical language, a TRIPOD checklist, and a hospital integration narrative that its evidence does not yet support. Retrospective accuracy on public datasets is the first rung of a long ladder, and the rungs above it, external validation, prospective study, calibration, and regulatory review, are where most promising medical models stall. A reader should hold the technical idea and the clinical claim separately, crediting the first while waiting for the evidence the second would require.
Read that way, this is a useful paper. It takes a real weakness in a widely used technique, proposes a modest and well motivated fix, and shows that the fix helps most where help is needed most. The honest framing is that it improves a distillation recipe for medical image classification on benchmarks, and that the path from there to a tool a clinician could trust runs through validation work this paper does not attempt. Both halves of that sentence are true, and keeping them together is the whole point.
A minimal implementation in PyTorch
The two ideas are short to express. The block below computes a per image temperature from the entropy of the teacher prediction, uses it to build the adaptive distillation loss, and includes a compact Ant Colony Optimization routine that selects the best candidate from a pool by validation accuracy. The smoke test trains a small student on dummy data, confirms that an uncertain teacher row receives a higher temperature than a confident one, and checks that the colony converges to the strongest model. This code was executed and verified before publication.
""" Context-Aware Adaptive Knowledge Distillation (CASM) with ACO model selection Reference implementation of the uncertainty-driven temperature mechanism. Paper: arXiv:2505.06381 """ import random import torch import torch.nn as nn import torch.nn.functional as F # ---------------------------------------------------------------------- # Uncertainty score U(x): normalized entropy of the teacher softmax in [0, 1] # A confident teacher -> low U -> low temperature (sharp targets) # An uncertain teacher -> high U -> high temperature (soft targets) # ---------------------------------------------------------------------- def prediction_uncertainty(teacher_logits): p = F.softmax(teacher_logits, dim=-1) logp = F.log_softmax(teacher_logits, dim=-1) entropy = -(p * logp).sum(-1) max_entropy = torch.log(torch.tensor(float(teacher_logits.size(-1)))) return entropy / max_entropy # [N], in [0, 1] def context_aware_temperature(teacher_logits, alpha=2.0, base=1.0): """tau(x) = base + alpha * U(x) (Eq. 3 in the paper).""" return base + alpha * prediction_uncertainty(teacher_logits) # [N] # ---------------------------------------------------------------------- # Adaptive KD loss: cross-entropy on hard labels plus a per-sample # temperature-scaled KL term between teacher and student (Eq. 1, 2, 4). # ---------------------------------------------------------------------- def adaptive_kd_loss(student_logits, teacher_logits, labels, ce_weight=0.1, alpha=2.0): tau = context_aware_temperature(teacher_logits, alpha).unsqueeze(-1) # [N, 1] t_soft = F.log_softmax(teacher_logits / tau, dim=-1) s_soft = F.log_softmax(student_logits / tau, dim=-1) # KL(teacher || student) per sample, then the classic tau^2 scaling kl = F.kl_div(s_soft, t_soft, reduction="none", log_target=True).sum(-1) # [N] kd = ((tau.squeeze(-1) ** 2) * kl).mean() ce = F.cross_entropy(student_logits, labels) loss = ce_weight * ce + (1.0 - ce_weight) * kd return loss, ce.detach(), kd.detach() class ContextAwareDistiller(nn.Module): def __init__(self, student, alpha=2.0, ce_weight=0.1): super().__init__() self.student = student self.alpha = alpha self.ce_weight = ce_weight def forward(self, x, teacher_logits, labels): s = self.student(x) return adaptive_kd_loss(s, teacher_logits, labels, self.ce_weight, self.alpha) class TinyStudent(nn.Module): def __init__(self, feat_dim=32, num_classes=4): super().__init__() self.net = nn.Sequential(nn.Linear(feat_dim, 128), nn.ReLU(), nn.Linear(128, num_classes)) def forward(self, x): return self.net(x) @torch.no_grad() def top1_accuracy(student, x, labels): return (student(x).argmax(-1) == labels).float().mean().item() # ---------------------------------------------------------------------- # Ant Colony Optimization for teacher-student model selection (Algorithm 1). # Each "model" carries a validation accuracy used as the heuristic value. # ---------------------------------------------------------------------- def aco_select_model(val_accuracy, n_ants=5, n_iters=10, a=1.0, b=2.0, rho=0.1, seed=0): rng = random.Random(seed) pher = [1.0 for _ in val_accuracy] # uniform pheromone heur = list(val_accuracy) # heuristic = val acc best_idx, best_perf, evals = 0, -1.0, 0 for _ in range(n_iters): chosen = [] weights = [pher[m] ** a * heur[m] ** b for m in range(len(pher))] total = sum(weights) probs = [w / total for w in weights] for _ in range(n_ants): r, acc, pick = rng.random(), 0.0, 0 # roulette wheel for m, pr in enumerate(probs): acc += pr if r <= acc: pick = m break perf = val_accuracy[pick] # "evaluate" the model evals += 1 chosen.append((pick, perf)) if perf > best_perf: best_perf, best_idx = perf, pick for m in range(len(pher)): # evaporate + deposit deposit = sum(p for idx, p in chosen if idx == m) pher[m] = (1.0 - rho) * pher[m] + deposit return best_idx, best_perf, evals def smoke_test(): torch.manual_seed(0) N, D, C = 64, 32, 4 x = torch.randn(N, D) labels = torch.randint(0, C, (N,)) teacher_logits = torch.randn(N, C) teacher_logits[torch.arange(N), labels] += 3.0 # mostly-correct teacher student = TinyStudent(D, C) distiller = ContextAwareDistiller(student, alpha=2.0, ce_weight=0.1) opt = torch.optim.Adam(student.parameters(), lr=5e-2) print("epoch | loss | ce | kd | top1") for epoch in range(12): distiller.train() loss, ce, kd = distiller(x, teacher_logits, labels) opt.zero_grad(); loss.backward(); opt.step() if epoch % 3 == 0 or epoch == 11: print(f"{epoch:5d} | {loss.item():.4f} | {ce.item():.4f} | " f"{kd.item():.4f} | {top1_accuracy(student, x, labels):.3f}") # sanity: a near-uniform (uncertain) teacher row gets a higher temperature peaked = torch.tensor([[5.0, 0.0, 0.0, 0.0]]) flat = torch.tensor([[0.1, 0.0, -0.1, 0.0]]) tp = context_aware_temperature(peaked, alpha=2.0).item() tf = context_aware_temperature(flat, alpha=2.0).item() print(f"temperature (confident teacher) = {tp:.3f}") print(f"temperature (uncertain teacher) = {tf:.3f}") assert tf > tp, "uncertain samples must receive a higher temperature" # ACO picks the highest-accuracy model from a pool with few evaluations pool = [0.912, 0.934, 0.948, 0.961, 0.903, 0.957] # validation accuracies idx, perf, evals = aco_select_model(pool, n_ants=5, n_iters=10) print(f"ACO selected model {idx} with val acc {perf:.3f} in {evals} evaluations") assert perf == max(pool), "ACO should converge to the best candidate" print("OK: adaptive temperature and ACO selection behave as described.") if __name__ == "__main__": smoke_test()
Read the paper
The preprint covers the full method, the ACO algorithm, the per dataset tables, and the interpretability analysis. The datasets used are the public Kaggle brain MRI, Figshare brain tumor, and GastroNet endoscopy collections.
Frequently Asked Questions
What does context aware adaptive temperature scaling change in knowledge distillation?
Instead of softening the teacher’s predictions with one fixed temperature for every image, it sets the temperature per image based on an uncertainty score. Uncertain or noisy images get a higher temperature and softer targets, while clear images the teacher reads confidently get a lower temperature and sharper targets.
Why does a fixed distillation temperature struggle on medical images?
A fixed temperature assumes every image carries the same uncertainty, which is not true in medical imaging where scan quality varies widely. Applying the same softening to a clean scan and a noisy one wastes information on the easy case and underprepares the student for the hard one, which is exactly where errors are most costly.
What role does Ant Colony Optimization play in the method?
It selects the teacher and student models from a pool of sixteen pretrained networks. Using pheromone guided search, it converges on DenseNet201 as teacher and ResNet152V2 as student in 47 evaluations, which the paper reports as more efficient than particle swarm optimization or grid search.
What accuracy did the method report?
The context aware student reported 98.01 percent accuracy on the Kaggle brain MRI dataset, 92.81 percent on the Figshare brain MRI dataset, and 96.20 percent on a gastrointestinal endoscopy dataset. These are retrospective results on public benchmarks, with the largest class level gain on the difficult meningioma class.
Is this model ready for clinical use?
No. The results come from curated public datasets and the work is a preprint with no prospective study, no external validation on unseen hospital data, and no calibration or regulatory review. Benchmark accuracy is an early research signal, not evidence of clinical readiness, and the tool should be treated as a research prototype.
Which classes were hardest for the model?
Meningioma was the most difficult class on the brain MRI data, with the lowest recall under the constant temperature baseline. The adaptive temperature gave its largest single improvement to that class, raising meningioma recall from 89.54 percent to 96.41 percent on the Kaggle set.