Every paper on knowledge distillation since 2015 has assumed something most practitioners would rather not say out loud. The teacher is right. The student should match it. If the student starts diverging from the teacher’s confidence distribution, the loss function pulls it back. A team from National Yang Ming Chiao Tung University and National Taiwan University has noticed the obvious flaw in this setup. Teachers misclassify roughly 20 percent of inputs in standard image classification benchmarks. Every time the teacher is wrong, the student is being asked to copy a mistake. Their fix is mechanical enough to fit in five lines of Python and recovers more than half a point of accuracy on the standard distillation benchmarks.
Key Points
- Conventional knowledge distillation trusts the teacher’s full output distribution, including the cases where the teacher is wrong. Wrong teacher signals get treated as ground truth by the student.
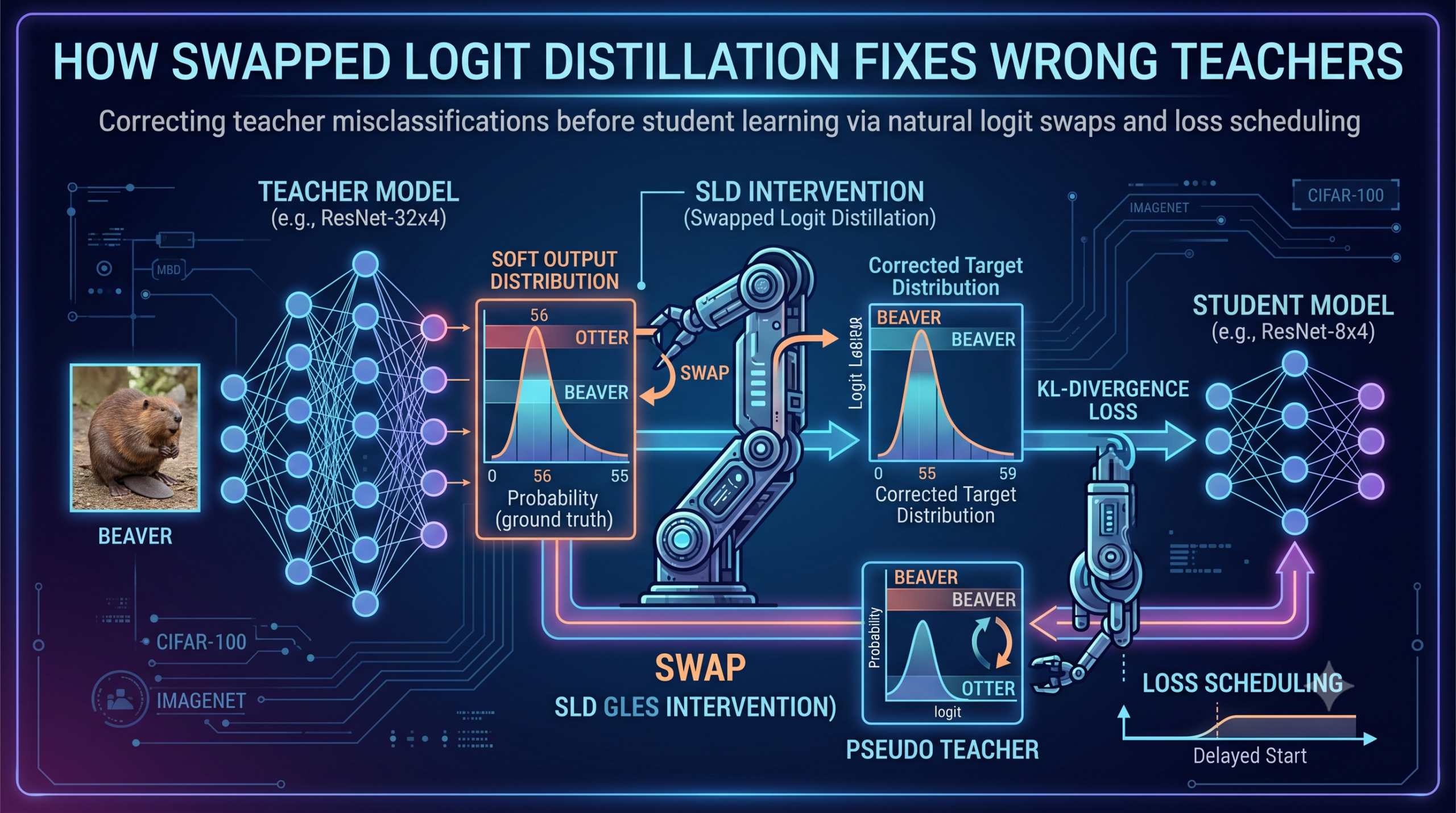
- Swapped Logit Distillation, or SLD, intercepts the teacher’s logit vector before it reaches the student. When the teacher’s top class is not the ground truth, SLD swaps the ground truth logit with the wrong top class logit. The distribution stays the same shape, only two values change places.
- The same swap applies to the student’s own logits, turning the student into a pseudo teacher. This adds a second supervision signal that is independent of the main teacher.
- Mixing the two teachers from epoch zero causes a fight. Loss scheduling delays the pseudo teacher signal until the student has converged on the main teacher, which avoids the conflict and lifts results by up to 5.50 percent on hard architecture mismatches.
- SLD outperforms MLKD, LS-MLKD, and DKD across CIFAR-100 and ImageNet, with the student often beating the teacher on average accuracy. Training is 12 milliseconds per batch with zero extra parameters.
- The method composes cleanly with feature based distillation methods like ReviewKD and with other logit methods like DKD and MLKD, lifting each of them when bolted on.
The problem nobody had named
Pick up almost any knowledge distillation paper and the framing is the same. The teacher network produces a soft output distribution over classes. The student is trained to minimize the divergence between its distribution and the teacher’s, usually via Kullback Leibler divergence on the softmax outputs. The intuition is that the teacher’s full distribution carries more information than the one hot ground truth label. A teacher that assigns 0.6 to cat and 0.3 to lion and 0.05 to dog is telling the student something useful about the structure of the visual world that just saying cat does not.
This intuition has a hidden assumption. It assumes the teacher’s top class is the right one. When that fails, when the teacher confidently says lion instead of cat, the student is now being asked to assign high probability to lion. The KL loss penalizes the student for putting probability on cat, the actual ground truth. The student learns the teacher’s mistake.
The authors call this the wrong prediction problem and they motivate it with a specific example from CIFAR-100. Class 4 is beaver. Class 55 is otter. Both belong to the aquatic mammals superclass. They share color, texture, and rough shape. A teacher will sometimes confuse them. When the input is a beaver and the teacher says otter, vanilla KD trains the student to put higher probability on otter than on beaver. There is no mechanism anywhere in the standard recipe to detect that the teacher just made a mistake, even though the ground truth label is right there in the training data.
Once you say the problem out loud, the question becomes what to do about it. The authors test several intuitive fixes and find that most of them make things worse, which is the interesting empirical finding of the paper.
Why obvious fixes fail
The most obvious fix is to add a small bonus to the ground truth logit. If the teacher predicts otter with logit 56 and beaver with logit 55, push the beaver logit up by some constant until it overtakes otter. The authors call this ground truth addition. It does correct the prediction. It also changes the entire softmax output across all 100 classes, because softmax is sensitive to absolute logit values. Adding a constant of 0.1 times the original ground truth logit to the ground truth slot does give a small improvement, about 0.26 points on ResNet32x4 to ResNet8x4. But it leaves the practitioner with a hyperparameter that has no clear principle behind it.
The authors push the idea harder. What if you double the ground truth logit, or halve it? Both fail. Doubling the ground truth costs 2.5 points of accuracy because the softmax becomes too peaked. Halving costs 2.59 points because the ground truth is no longer the maximum on most samples. The lesson is that the softmax shape carries information the student needs to learn, and arbitrary logit edits destroy that information.
Label smoothing is a known related technique. Take the one hot ground truth, redistribute some probability mass uniformly across the non target classes, and use the resulting smooth distribution as a teacher. The authors compare SLD against label smoothing with epsilon equal to 0.1 and find that label smoothing gains 0.41 points over baseline while SLD gains 0.78. The difference is intuitive. Label smoothing pushes all non target classes toward a uniform distribution, which destroys the structured similarity information that distillation was supposed to capture. The teacher’s belief that beaver and otter are confusable is exactly the kind of dark knowledge the student should inherit. Label smoothing erases it.
What you want is a fix that corrects the wrong prediction while leaving the rest of the distribution intact. That is what swapping does.
The swap mechanism
Here is where it gets interesting. The fix is literally one line of code. When the teacher misclassifies a sample, locate the logit value at the ground truth index. Locate the logit value at the index the teacher predicted. Swap them. Pass the resulting logit vector through softmax as usual. Compute KL divergence with the student. Everything else stays the same.
Where t is the ground truth index. The swap function exchanges the value at index t with the value at the index with maximum confidence. When the teacher is correct, nothing happens. When the teacher is wrong, the maximum logit moves to the ground truth slot and the wrong winning class drops to whatever the ground truth logit was.
This preserves a property the authors call naturality. The shape of the distribution stays the same. The ordering of every class except the swapped pair stays the same. The relative ranking among non target classes is unchanged. Only two values change places. The softmax temperature, the relative confidence gap between the top two classes, the long tail of small probabilities for unrelated classes, all of it is preserved. The student still learns the structured similarity information. It just learns it with the correct top class.
The distribution after swapping is still natural in the sense that softmax could have produced it. No invented values, no artificial peaks, no destroyed structure. The teacher’s mistake is corrected without rewriting the teacher’s beliefs. A way to read the SLD construction
The argument for naturality is supported by an ablation that is worth reading carefully. The authors compare SLD against five alternative logit edits on the same backbone. Extreme ground truth addition with double the original value loses 2.5 points. Extreme reduction loses 2.59. Soft addition with a 10 percent boost gains 0.26. Maximum addition gains 0.43. Label smoothing gains 0.41. SLD gains 0.78, the only method that crosses half a point. The mechanism is simple but it is not trivially equivalent to any of the obvious alternatives.
The student becomes its own teacher
The next move is what makes SLD more than a one trick fix. If swapping fixes the teacher’s wrong predictions, it should also fix the student’s wrong predictions. The student is a separate network with its own forward pass and its own errors, statistically independent of the teacher in the sense that the teacher cannot see them. So apply the same swap to the student’s logits. Call the swapped student output the pseudo teacher. Distill the unswapped student against it.
The total distillation loss now has two parts. The teacher swap loss matches the student against the swap corrected main teacher. The student swap loss matches the student against the swap corrected version of itself. Both losses are summed and added to the standard cross entropy supervision.
The justification is interesting. The pseudo teacher carries information that the main teacher does not. When the main teacher misclassifies a sample as otter, it cannot tell the student that the right answer is beaver. The pseudo teacher, derived from the student’s own forward pass, may have a completely different error pattern. On samples where the student gets close to the right answer but does not commit, the pseudo teacher’s swap nudges it the rest of the way. On samples where both teacher and student are wrong, the swap acts as a label smoothing style correction toward the ground truth.
The empirical evidence supports this. Table 13 in the paper runs an ablation where the pseudo teacher is added on top of vanilla KD without swapping the main teacher. The student still gains 0.14 to 0.46 points just from the pseudo teacher term. The swap and the pseudo teacher are independent improvements that compose.
When two teachers fight
Adding the pseudo teacher from epoch one breaks things, sometimes catastrophically. Figure 3 in the paper shows a ResNet50 to MobileNet-V2 training curve where naive integration drops the final accuracy by more than 5 points compared to applying the pseudo teacher loss later. The fix is loss scheduling. The pseudo teacher loss is zero for the first gamma epochs, then turns on for the rest of training.
The intuition is human. A student who has not yet learned the basics cannot benefit from self study. The early phase of training is when the student model is rapidly converging on the main teacher’s overall distribution. Pulling it toward a pseudo teacher that is itself half formed creates conflicting gradients. Once the student has absorbed the main teacher’s signal, around the first learning rate decay, the pseudo teacher term can come online and add a second source of supervision that the student now has the capacity to integrate.
The empirical lift from scheduling alone is the largest single contribution in the paper for some architecture pairs. ResNet50 to MobileNet-V2 gains 5.50 points from scheduling. ResNet32x4 to ShuffleNet-V1 gains 3.41. VGG-13 to MobileNet-V2 gains only 0.15 because that pair was less sensitive to the conflict in the first place. The pattern matches an intuitive read. The more heterogeneous the teacher and student architectures, the more the student needs time to align with the main teacher before being asked to also align with itself.
The numbers across CIFAR-100 and ImageNet
The evaluation grid is the standard one used by recent logit distillation papers. Six teacher and student pairs on CIFAR-100 with homogeneous architectures, six more with heterogeneous architectures, two on ImageNet. The comparison set includes the strongest recent methods, MLKD from CVPR 2023 and LS-MLKD from CVPR 2024 are the most relevant baselines.
| Setting | Teacher | Student | MLKD | LS-MLKD | SLD | Gain over MLKD |
|---|---|---|---|---|---|---|
| CIFAR-100 same family | ResNet32x4 | ResNet8x4 | 77.08 | 78.28 | 77.69 | +0.61 |
| CIFAR-100 same family | WRN-40-2 | WRN-16-2 | 76.63 | 76.95 | 77.19 | +0.56 |
| CIFAR-100 same family | ResNet110 | ResNet32 | 74.11 | 74.32 | 74.57 | +0.46 |
| CIFAR-100 mixed | ResNet50 | MobileNet-V2 | 71.04 | 71.19 | 71.48 | +0.44 |
| CIFAR-100 mixed | ResNet32x4 | ShuffleNet-V2 | 78.44 | 78.76 | 78.82 | +0.38 |
| ImageNet | ResNet34 | ResNet18 | 71.90 | 72.08 | 72.15 | +0.25 |
| ImageNet | ResNet50 | MobileNet-V1 | 73.01 | 73.22 | 73.27 | +0.26 |
The gains are not enormous against the strongest baselines but they are consistent. Twelve of the twelve CIFAR-100 settings see SLD win or tie the previous best. Both ImageNet settings improve. The pattern is steady, not dramatic, which matters because it suggests the swap mechanism is doing something fundamental rather than gaming a particular benchmark configuration.
The result that is harder to dismiss is the comparison against the teacher itself. Table 6 in the paper computes the gap between the teacher accuracy and the student accuracy. The average teacher accuracy on six CIFAR-100 settings is 75.32 percent. The average student accuracy under SLD is 75.64 percent. The student is beating the teacher on average. That is not what is supposed to happen in knowledge distillation. The pseudo teacher term is doing this lift. Removing it drops the student average to 75.02 percent, slightly below the teacher. The independent supervision signal from the swap corrected student is genuinely contributing knowledge the main teacher did not have.
The training time analysis is also striking. Figure 4 of the paper shows SLD at 12 milliseconds per batch on the ResNet32x4 to ResNet8x4 pair. MLKD is 13 milliseconds. RKD is 24, ReviewKD is 25, OFD is 19, CRD is 40. SLD is the fastest of any method tested while also producing the highest accuracy. Zero extra trainable parameters. The reason is that the swap is a single tensor operation on the logits and the pseudo teacher uses the existing student forward pass, so the additional compute is genuinely tiny.
The places where SLD does not change much
The fix is narrow in scope. SLD addresses one specific failure mode, the teacher misclassification. When the teacher is correct on most samples, the swap mechanism is a no op for those samples. The gains scale with the teacher error rate. On benchmarks where the teacher already achieves very high accuracy, the upper bound on what SLD can do is correspondingly small.
The pseudo teacher mechanism is more general but it relies on the student eventually producing reasonable predictions. Early in training the student outputs are essentially random, so swapping them produces noisy supervision. This is why loss scheduling matters and why the gains depend on having enough training epochs for the schedule to kick in. The paper uses 240 epochs on CIFAR-100, which is on the long side of standard training budgets. With fewer epochs the scheduling window narrows and the pseudo teacher contributes less.
The method assumes you have access to the ground truth label during distillation, which is true in standard supervised settings. If you were distilling on unlabeled data with only the teacher as supervision, the swap mechanism could not fire because there is no ground truth to swap against. This is not a blocker for most practical distillation pipelines but it does rule out some self distillation scenarios.
The conditional swap experiment in Table 12 is honest about a limitation. When the discrepancy between the teacher’s wrong prediction and the ground truth is small, swapping helps the most. When the teacher is very confident in a wrong answer that is semantically far from the ground truth, swapping has less benefit. The mechanism works best on hard but adjacent mistakes, the beaver and otter confusions, not on the cases where the teacher is wildly off base.
What this changes for practitioners
If you run a knowledge distillation pipeline and your teacher achieves anything below perfect accuracy on the training set, SLD is worth a small experiment. The implementation is genuinely five lines of additional code on top of any standard logit based distillation setup. The gain on standard benchmarks is in the half point to one point range with no extra parameters and no extra training time. If the teacher’s misclassification rate on the training distribution is high, say above 15 percent, the gain compounds.
The pseudo teacher mechanism is more nuanced. Adding it requires loss scheduling, which means a new hyperparameter, the epoch at which the pseudo teacher comes online. The paper recommends scheduling it right after the first learning rate decay, which is around epoch 150 on a 240 epoch CIFAR-100 schedule and epoch 30 on a 100 epoch ImageNet schedule. Those defaults are likely to be reasonable starting points but the optimal value varies with the teacher and student gap.
If you are already using one of the divergence based methods like ABKD or one of the relation based methods like VRM, the SLD swap can be applied as a preprocessing step on the teacher’s logits before the divergence or relation matching loss is computed. The paper does not test these specific combinations but the mechanism is orthogonal to both, since the swap operates on the teacher’s output and the downstream loss can be anything.
The training efficiency advantage matters in distillation pipelines that scale to large datasets or many architecture pairs. SLD adds essentially no overhead, which makes it a candidate to enable by default rather than a method to reach for selectively. The implementation cost is a few tensor operations per batch.
Reproducing SLD in PyTorch
The reference implementation tracks the paper’s Algorithm 1 closely. The swap is a clone of the logit tensor followed by an index exchange. The pseudo teacher is computed from the student’s own logits with the same swap. The full loss adds prediction augmentation across multiple temperatures.
The detach on the pseudo teacher tensor in the scheduled branch deserves a note. The paper does not explicitly require this, but treating the swapped student output as a fixed target prevents the loss from flowing back into the pseudo teacher path and creating a degenerate optimization where the student trivially matches itself. The reference implementation from the authors handles this through their PyTorch graph structure. Either approach gives the same effective behavior. The official code repository linked in the paper contains the configurations used for each benchmark setting, including the exact gamma values and temperature schedules.
Conclusion
The framing argument in this paper is the part that holds up best. Knowledge distillation has been treating the teacher as an oracle for ten years, and the consequence has been that every paper has been tacitly asking students to copy teacher mistakes alongside teacher correct answers. The cross entropy loss on the ground truth fights this drift but only partially. Naming the problem and intervening on it directly is the kind of move that should have happened earlier, and the fact that it can be done in five lines of code makes the gap between the recognition and the implementation embarrassingly small.
The technical execution is light. The swap mechanism is one tensor operation. The pseudo teacher is one additional forward pass that you were already doing. The scheduling is one if statement. The total cost of SLD over a baseline like MLKD is essentially zero, both in compute and in implementation complexity. The fact that this minimal intervention produces consistent half point to one point gains across a dozen architecture pairs is the strongest argument for the framing being correct.
The transferability claim is the part that needs more work. The authors show SLD composes with feature based methods like ReviewKD and with logit methods like DKD and MLKD, lifting each. They do not show how it composes with the more recent divergence based methods or with relation matching frameworks. Those experiments are obvious next steps. The mechanism is independent enough from any specific loss function that it should compose, but the empirical evidence is still missing.
The limitations are reasonable. SLD works when the teacher misclassifies on hard adjacent cases, which is the common pattern in fine grained classification. It does less when the teacher is wildly wrong or when the ground truth label is unavailable. It needs a long enough training schedule for the loss scheduling to do useful work. None of these are blockers for the standard distillation use case, but they mark the boundaries of what the method is actually doing.
The reason this paper matters is that it shows how much room is still left in the basic recipe. Three different recent papers, the alpha beta divergence reformulation, the virtual relation matching framework, and now swapped logit distillation, all extract substantial gains from changing one specific component of the standard distillation pipeline. The student model has not changed. The teacher model has not changed. The training data has not changed. The architectures, the optimizers, the schedules are all the same. The pieces that have been treated as fixed turn out to have headroom in them, and the field is finding that headroom faster than anyone expected a few years ago. The simple fixes are not finished yet.
Frequently Asked Questions
What is Swapped Logit Distillation?
Swapped Logit Distillation, or SLD, is a knowledge distillation method that intervenes on the teacher’s output before it reaches the student. When the teacher misclassifies a sample, SLD swaps the logit value at the ground truth index with the logit value at the wrong winning index. The student then learns from this corrected distribution rather than from the teacher’s mistake. The shape of the distribution is preserved, only two values change places.
Why does swapping work better than adding a bonus to the ground truth logit?
Adding a constant to the ground truth logit changes the entire softmax output because softmax is sensitive to absolute logit values. The structured similarity information among non target classes gets distorted. Swapping preserves the rank order and relative magnitudes of all the non target classes. Only the wrong winner and the ground truth exchange positions, which keeps the distribution natural in the sense that softmax could have produced it from a slightly different teacher.
What is the pseudo teacher in SLD?
The pseudo teacher is the student’s own logits after the same swap correction has been applied. The student is then trained to also match this swap corrected version of itself. The pseudo teacher carries supervision information that is statistically independent of the main teacher, since it comes from the student’s own forward pass with the ground truth applied. This lets the student exceed the teacher’s accuracy on some configurations.
Why does loss scheduling matter for SLD?
If the pseudo teacher loss is active from epoch one, it conflicts with the main teacher loss because the student has not yet converged on either signal. The gradients pull in different directions and training degrades, sometimes by more than 5 percent on heterogeneous architecture pairs. Loss scheduling turns the pseudo teacher loss on only after a chosen epoch, usually right after the first learning rate decay. By that point the student has aligned with the main teacher and can absorb the second supervision signal without conflict.
How does SLD compare to other recent knowledge distillation methods?
SLD attacks a different problem than its main contemporaries. The alpha beta divergence framework changes the divergence function used to match teacher and student. Virtual relation matching changes the structure of what gets matched by building affinity graphs across batches. SLD changes the teacher signal itself before any matching happens. The three are largely orthogonal, and in principle the swap mechanism could be applied as a preprocessing step inside either of the other frameworks.
What is the training cost of SLD?
SLD adds essentially zero overhead. The swap is a single tensor index operation on the logits and the pseudo teacher reuses the existing student forward pass. The authors report 12 milliseconds per batch on CIFAR-100 with a ResNet32x4 teacher and a ResNet8x4 student, which is faster than MLKD at 13 milliseconds and dramatically faster than feature based methods like ReviewKD at 25 milliseconds or CRD at 40 milliseconds. There are no extra trainable parameters and no extra inference cost.
Read the full SLD paper
The paper has the complete ablations on logit processing alternatives, the loss scheduling sensitivity analysis, and the correlation matrix comparisons against MLKD.
Read the arXiv paper Download PDFCitation. Limantoro, S. E., Lin, J. H., Wang, C. Y., Tsai, Y. L., Shuai, H. H., Huang, C. C., and Cheng, W. H. (2025). Swapped Logit Distillation via Bi level Teacher Alignment. arXiv preprint arXiv:2504.20108v1. Available at https://arxiv.org/abs/2504.20108.
This analysis is based on the published paper and an independent evaluation of its claims.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.info/en-ZA/register?ref=B4EPR6J0
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?