Key points
- CMFDNet pairs a pretrained VMamba Tiny encoder with three new pieces, a Cross Mamba Decoder, a Multi Scale Aware module, and a Feature Discovery module, aimed at three specific polyp segmentation failure modes.
- Across five public datasets it edges out six recent baselines, with the largest margins on the two hardest generalization sets, ETIS and ColonDB, where mDice rises by 1.83 and 1.55 percentage points over the next best method.
- On the two datasets used to test raw learning capacity, Kvasir and ClinicDB, the gain over the strongest competitor shrinks to 0.17 and 0.16 percentage points, which is close to the noise floor for this kind of benchmark.
- The paper’s own ablation study shows the module built to catch small polyps, Feature Discovery, contributes the least of the three new components when it is removed.
- One column in the results table appears to contain a transcription error, and it is worth flagging before anyone cites the affected number.
- All images are resized to 224 by 224 pixels before segmentation, a preprocessing choice that shrinks the very small lesions the paper is trying to protect against missing.
A note before you read further
This article explains a published engineering paper about an automated image segmentation method. It is not medical advice, it does not diagnose anything, and it is not a substitute for a colonoscopy, a radiologist’s read, or a conversation with a gastroenterologist. Nothing described here has cleared regulatory review for clinical use, and readers with health questions about colon polyps or colorectal cancer screening should talk to a qualified clinician rather than a research paper.
The problem colonoscopy still has not solved
Colorectal cancer sits near the top of the list for both how many people it affects and how many it kills worldwide, and the accepted defense is finding and removing polyps before they turn malignant. Colonoscopy remains the tool of choice because it lets a physician see and act on a lesion in the same procedure. The catch is that human attention during a live procedure is finite, and a percentage of polyps, especially small or flat ones, get missed every single day in endoscopy suites everywhere. That is the gap computer vision has been trying to close for close to a decade, and it explains why polyp segmentation shows up so often in medical imaging conferences.
The CMFDNet authors frame the remaining difficulty as three distinct problems rather than one. Polyps vary enormously in shape and size from patient to patient and even within the same colon. Their edges blur into surrounding tissue in a way that a plain threshold or a naive convolutional filter struggles to resolve. And small polyps, precisely the ones a screening program most needs to catch early, are the ones most likely to be dropped entirely by a segmentation model trained mostly on larger, more visually obvious lesions.
Where earlier segmentation networks left an opening
The lineage here runs through a few recognizable names. PraNet introduced a reverse attention mechanism that iteratively sharpens boundary predictions rather than committing to an edge in one pass, and it remains a common baseline years after publication. BDG-Net took a different route to the same boundary problem, generating an explicit boundary distribution map that guides the decoder toward accurate edges. On the small polyp side, LSSNet leaned on a multiscale feature extraction block that preserves fine local detail from shallow encoder layers, while MoE-Polyp used a mixture of experts decoder to blend boundary, spatial, and global cues so small lesion information does not get diluted during decoding.
More recently, state space models built around the Mamba architecture have entered this space because they offer something Transformers do not, linear rather than quadratic complexity as image resolution grows. VM-Unet and its successor VM-UnetV2 adapted the Mamba block for medical segmentation, Swin-UMamba paired a Mamba backbone with ImageNet pretraining, and Polyp-Mamba specifically added a scale aware semantics module for the shape variation problem. What is worth noticing is that CMFDNet’s comparison table does not include BDG-Net, LSSNet, MoE-Polyp, or Polyp-Mamba, the four methods that most directly target the exact three challenges CMFDNet claims to solve. Instead the six baselines are PraNet, FCBFormer, ECTransNet, Swin-UMamba, VM-Unet, and VM-UnetV2, a reasonable and recent set, but not the most pointed comparison a reader might expect given how the introduction frames the problem.
How the architecture is put together
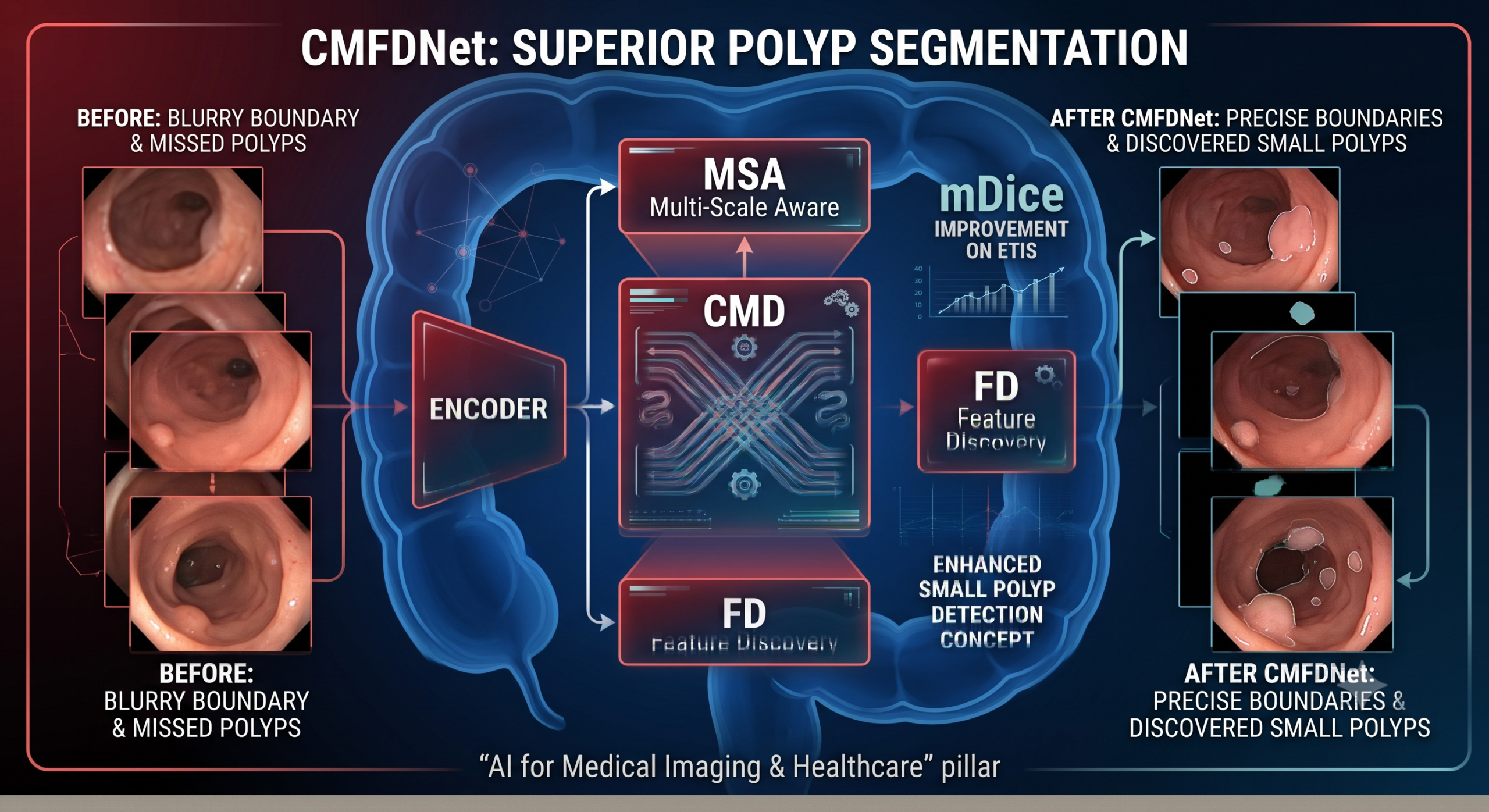
CMFDNet keeps a fairly standard four stage encoder built on a pretrained VMamba Tiny backbone, the same visual state space model that introduced the two dimensional selective scan for image tasks. Each of the four stages produces a feature map at a different resolution, from a coarse 8 by 8 grid deep in the network down to a finer 64 by 64 grid near the input. What changes is everything downstream of the encoder.
The Multi Scale Aware module
Sitting between the encoder and the decoder at each of the first three stages, the Multi Scale Aware module, or MSA, borrows the inverted bottleneck idea from MobileNetV2 and runs three parallel depthwise convolution branches with 3 by 3, 5 by 5, and 7 by 7 kernels over the same features. The idea is straightforward, different kernel sizes catch different object scales, so a small polyp and a large one both get a fair shot at being represented well. After the three branches are summed, a channel shuffle operation borrowed from ShuffleNet restores cross channel relationships that depthwise convolution otherwise ignores, and a final pointwise convolution halves the channel count back down before the features move on to the decoder.
The Cross Mamba Decoder module
This is the piece the paper leans on hardest, and its own ablation numbers back that up. Instead of a conventional upsample and concatenate decoder, the Cross Mamba Decoder, or CMD, takes the upsampled features from the deeper decoder stage and the same level MSA features and swaps pixels between them row by row and column by column before running each swapped pair through a Mamba based scanning block called VSS Scan. The scanning uses four diagonal sweep directions rather than the usual horizontal and vertical passes, which the authors describe as cross scanning. The row branch and column branch outputs are each combined and passed through a custom attention block called the Global Attention Block, then the two branches are merged and refined through a short stack of pointwise and depthwise convolutions to produce that stage’s decoder output.
The intuition behind exchanging pixels before scanning is that it forces the state space scan to see interleaved deep and shallow information along its scan path rather than only its own stage’s features, which the authors argue helps recover fine boundary detail that a simple skip connection would blur. Whether the row and column pixel exchange is meaningfully different from a well tuned attention based fusion is not something the paper tests directly, since there is no ablation that swaps CMD for a plain feature fusion block instead of removing it outright.
The Global Attention Block
Both the CMD and MSA modules lean on a custom attention block, GAB, built to fix a specific complaint the authors have about CBAM, the widely used serial channel then spatial attention module. Their argument is that running spatial attention after channel attention lets the second stage override or dampen what the first stage emphasized, especially when noise is unevenly distributed across the image. GAB instead runs channel and spatial attention in parallel and blends the two with a learnable weight initialized at 0.5, so neither branch can silently cancel the other.
The Feature Discovery module
The last piece, Feature Discovery or FD, takes the three CMD outputs and fuses them from the deepest to the shallowest stage using a repeated pattern of transpose convolution upsampling followed by element wise multiplication and addition. The stated goal is to let every decoder stage borrow context from every other stage so a small polyp that is faint in one stage’s features has a better chance of surviving into the final prediction. The citation trail in the paper attributes this exact fusion pattern to CTNet, an earlier contrastive transformer network for polyp segmentation, so FD is closer to an adaptation of existing work than a from scratch invention, something the paper does not draw much attention to in its list of contributions.
The math behind the cross scanning fusion
The pixel exchange and scanning steps inside CMD are described formally for stage i, where i runs from 1 to 3 and CMD for stage 4 is simply the raw encoder output with no decoding applied yet.
Here MSAi is the shallow feature from the multi scale module at stage i, and CMDi+1u is the deeper decoder output after it has been upsampled to match resolution. The row and column exchange operations swap portions of the two inputs by position, producing two exchanged pairs that each get scanned independently, giving four intermediate feature maps.
Inside the Global Attention Block, a learnable balance term lambda, passed through a sigmoid and started at 0.5, decides how much weight channel attention gets relative to spatial attention for a given feature map.
And the Feature Discovery module’s final fusion is just two rounds of the same pattern, transpose convolution upsampling followed by multiplicative gating and a residual add, moving from the deepest decoder stage toward the shallowest.
Key takeaway
Every fusion step in this architecture follows the same recipe, split a feature into complementary views, run each view through a scan or a convolution, then recombine with attention or gating rather than a plain concatenation. The novelty is less in any single mechanism and more in stacking that recipe three times across MSA, CMD, and FD.
What the benchmark numbers actually show
CMFDNet was trained on a combined pool of 1,450 images from Kvasir-SEG and CVC-ClinicDB and then evaluated on five datasets. Kvasir and ClinicDB serve as in distribution tests of raw learning capacity, since the model saw similar images during training. ETIS, ColonDB, and EndoScene function as out of distribution generalization tests, since none of their images were part of training. That split matters a lot for reading the results table honestly.
| Dataset | Role | Best baseline mDice | CMFDNet mDice | Gain |
|---|---|---|---|---|
| Kvasir | Learning capacity | 91.57 | 91.74 | 0.17 |
| ClinicDB | Learning capacity | 93.20 | 93.36 | 0.16 |
| ETIS | Generalization | 80.02 | 81.85 | 1.83 |
| ColonDB | Generalization | 81.50 | 83.05 | 1.55 |
| EndoScene | Generalization | 89.95 | 90.62 | 0.67 |
The paper’s abstract only quotes the ETIS and ColonDB numbers, which is fair since those are genuinely the strongest results, but a reader skimming just the abstract would miss that the model is basically tied with the best prior method on the two datasets closest to its training distribution. Framed differently, CMFDNet’s real contribution looks like better generalization to unseen clinical settings rather than a broad lift in raw segmentation accuracy, which is a meaningfully different claim and arguably a more useful one for a screening tool that will eventually meet images from equipment it never trained on.
A closer look at the ablation table
The ablation study, run on ColonDB and ETIS, removes one component at a time and measures the drop. This is where the paper’s own data complicates its pitch.
| Configuration | mDice | mIoU | Change vs full model |
|---|---|---|---|
| Without CMD | 77.12 | 70.31 | -5.93 mDice, -5.25 mIoU |
| Without MSA | 81.94 | 74.77 | -1.11 mDice, -0.79 mIoU |
| Without FD | 82.50 | 74.67 | -0.55 mDice, -0.89 mIoU |
| GAB replaced with CBAM | 82.46 | 74.89 | -0.59 mDice, -0.67 mIoU |
| Full CMFDNet | 83.05 | 75.56 | reference |
CMD is clearly load bearing, and losing it costs almost six points of mDice, which lines up with it being the actual decoding backbone rather than an add on. MSA earns its place too, with just over a point of mDice on the table. FD is the interesting one. It is the module framed in the introduction as solving the third named challenge, missed small polyps, yet removing it costs the smallest mDice drop of the three, 0.55 points on ColonDB, and it is not even the largest mIoU drop, since swapping GAB for CBAM costs more mIoU than removing FD does. None of this means FD is useless, a real gain is still a real gain, but a reader deciding whether FD is worth the extra transpose convolutions and multiplicative gating in their own pipeline should know it is the smallest lever in this particular design, not the headline fix for small polyps the framing implies.
A number worth double checking
Table 1 in the source paper lists VM-UnetV2’s mean absolute error on the Kvasir dataset as 89.39. Every other MAE value in that same table, across all five datasets and seven methods, falls between roughly 0.58 and 3.90, which is the expected range for a metric bounded between 0 and 1 and reported as a percentage. An MAE of 89.39 percent would mean the model is wrong on the overwhelming majority of pixels, which is inconsistent with VM-UnetV2 posting a competitive 91.57 mDice on the same row. This has the signature of a transcription error, most likely a stray Fw beta or similar value copied into the wrong cell, rather than a real result. It is the kind of thing worth flagging before citing that specific number anywhere downstream.
Clinical translation gap
There is a real distance between a model that beats six baselines on five public benchmarks and a tool that a hospital can safely put in front of a live colonoscopy feed. CMFDNet, like most of the field, was trained and tested on curated still frames pulled from established public datasets, not on continuous video with motion blur, mucus, stool artifact, or the variable lighting a scope actually produces in real time. All input images here were resized to a fixed 224 by 224 resolution, which is a common convenience for benchmarking but works directly against the paper’s own stated goal, since shrinking an already small polyp to fit a 224 pixel grid removes exactly the fine detail the Feature Discovery module is supposed to recover. Real time deployment would also need to clear a latency bar, and the paper does not report inference speed or frames per second, so it is not possible from this publication alone to say whether CMFDNet could run fast enough to annotate a live feed rather than a stored image.
Key takeaway
The generalization gains on ETIS and ColonDB are the most clinically relevant numbers in the paper, since they measure performance on data the model never trained on, which is the closest proxy available here for a genuinely new patient. Even so, generalization across five research datasets is not the same claim as generalization across five different endoscopy manufacturers, lighting rigs, and patient populations in the wild.
Clinical limitations
A few limits are worth naming plainly. The training set is 1,450 images drawn from just two source datasets, Kvasir-SEG and CVC-ClinicDB, which is a small sample by the standards of clinical validation and leaves open questions about how the model handles rare polyp morphologies, prior resections, or inflammatory conditions that visually resemble polyps. The three generalization datasets, ETIS, ColonDB, and EndoScene, are themselves long established public benchmarks, not fresh multi center clinical data, so the generalization claim is bounded by how representative those older datasets remain of current endoscopy equipment and patient demographics. The paper reports a single evaluation run per configuration rather than results averaged across multiple training seeds with confidence intervals, so it is not possible to know from the publication how much of a 0.16 or 0.17 percentage point gain on Kvasir and ClinicDB would survive a repeat run. And this is a preprint, posted to arXiv without indication of peer review, so none of these numbers have yet passed through independent referee scrutiny the way a journal publication would require. None of that erases the work, but it does mean the appropriate level of confidence here is cautious interest rather than clinical readiness.
Honest limitations of the paper itself
The authors are upfront about one gap, noting in their conclusion that CMFDNet has no dedicated noise filtering module despite frequent noise in real polyp images, and naming that as future work rather than something already solved. Beyond that self reported limitation, the comparison set leaves out the four prior methods most directly aimed at the same three problems, which makes it hard to know whether CMFDNet’s gains would hold up against BDG-Net’s boundary distribution guidance or MoE-Polyp’s expert routed decoder specifically, rather than against the more general purpose baselines that were actually tested. The ablation study also only ever removes a component, it never substitutes CMD’s cross scanning approach for a simpler fusion mechanism at equal parameter count, so it remains unclear how much of CMD’s near six point contribution comes from the cross scanning idea itself versus simply having more decoder capacity in that slot.
Where this fits going forward
Mamba based decoders keep showing up in medical segmentation because the linear complexity story is genuinely attractive as image resolution grows, and CMFDNet is a reasonably careful entry in that line of work. Its clearest contribution is not a blanket accuracy jump but a specific, well evidenced improvement in cross dataset generalization, the kind of result that matters more for eventual clinical use than a fraction of a point gained on data the model has effectively already seen. The ablation study is unusually transparent for a paper in this space, and that transparency is exactly what lets a careful reader notice that the module marketed as the small polyp fix is the smallest contributor on the scoreboard, which is a more useful thing to know than the headline claim alone.
The conceptual shift worth watching is the pixel exchange idea inside CMD, treating deep and shallow features as two views to be interleaved before a state space scan rather than simply concatenated. If that idea holds up under a more controlled ablation, swapping it against a matched parameter fusion baseline rather than removing it outright, it could generalize well beyond polyps to other segmentation tasks that share the same deep versus shallow feature tension, retinal vessel mapping and skin lesion boundaries being two obvious candidates already active in this research area.
The honest remaining gaps are the ones any clinical translation effort would need to close first. No inference speed numbers, no multi seed statistical testing, a training set drawn from only two source datasets, and a fixed low resolution input that works against the paper’s own stated goal of catching small lesions. None of these are unusual for a computer vision preprint, but they are the specific items a hospital procurement team or an IRB would ask about before this kind of model got anywhere near a live procedure.
For readers tracking the broader Mamba in medical imaging trend, CMFDNet is a useful data point precisely because its ablation table does not fully agree with its own introduction, and that kind of internal tension is more informative than a clean story would have been. It suggests the field still has real headroom in figuring out which architectural pieces are actually earning their complexity versus which ones are along for the ride.
Ultimately this is one preprint among many chasing the same three well known polyp segmentation problems, and it earns its place in that crowded field by being honest enough in its own ablation section to let a careful reader see past the abstract. That is worth more than another point of mDice.
Frequently asked questions
What is CMFDNet actually trying to fix in polyp segmentation. It targets three specific problems, polyps that vary widely in shape and size, blurred boundaries between a polyp and the surrounding tissue, and small polyps getting missed entirely during segmentation.
Which part of the architecture matters most according to the paper’s own testing. The Cross Mamba Decoder module, since removing it costs nearly six percentage points of mDice on the ColonDB dataset, far more than removing either of the other two new modules.
Does CMFDNet actually solve the small polyp problem it names as a goal. The Feature Discovery module built for that purpose shows the smallest measured contribution of the three new components in the paper’s ablation study, so the evidence for that specific claim is the weakest of the three.
Is this ready to be used in a real colonoscopy procedure. No. It is a research preprint tested on curated still images from public datasets, with no reported inference speed, no peer review yet, and no clinical validation, so it is not something a clinic could deploy today.
How does CMFDNet compare to other recent Mamba based segmentation models. It reports higher mDice than VM-Unet, VM-UnetV2, and Swin-UMamba across all five tested datasets, though the margin over the best baseline is small on the two in distribution datasets and larger on the three out of distribution ones.
Where can I read the original paper. The full preprint, including all architecture diagrams and the complete results tables, is available on arXiv at the link in the citation box below.
Read the original preprint for the full architecture diagrams, complete results tables, and author affiliations.
Read the paper on arXivJiang, F., Zhang, Z., and Xu, X. CMFDNet, Cross Mamba and Feature Discovery Network for Polyp Segmentation. arXiv:2508.17729, posted August 25, 2025.
This analysis is based on the published paper and an independent evaluation of its claims.
Related reading
Complete PyTorch implementation
The following is a full, runnable reimplementation of CMFDNet’s core modules based on the equations and figure descriptions in the paper, including the encoder interface, the Global Attention Block, the Multi Scale Aware module, the Cross Mamba Decoder module with a practical stand in for the VSS Scan block, the Feature Discovery module, the combined loss, a training loop, an evaluation function, and a smoke test on random dummy data.
# cmfdnet.py # Reimplementation of CMFDNet (Jiang, Zhang, Xu 2025) core modules # Encoder assumed to be a pretrained VMamba-Tiny producing four feature maps. # The VSS Scan block below is a practical selective-scan style stand-in, # since the paper's exact SS2D kernel is not fully specified for reuse here. import torch import torch.nn as nn import torch.nn.functional as F class GlobalAttentionBlock(nn.Module): """GAB: parallel channel and spatial attention blended by a learnable lambda.""" def __init__(self, channels, reduction=8): super().__init__() hidden = max(channels // reduction, 8) self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.channel_mlp = nn.Sequential( nn.Conv2d(channels, hidden, 1), nn.ReLU(inplace=True), nn.Conv2d(hidden, channels, 1), ) self.spatial_conv = nn.Conv2d(2, 1, kernel_size=7, padding=3) self.lam = nn.Parameter(torch.zeros(1)) # sigmoid(0) = 0.5 initial balance def forward(self, m): avg_c = self.channel_mlp(self.avg_pool(m)) max_c = self.channel_mlp(self.max_pool(m)) w_c = torch.sigmoid(avg_c + max_c) # (B, C, 1, 1) avg_s = torch.mean(m, dim=1, keepdim=True) max_s, _ = torch.max(m, dim=1, keepdim=True) w_s = torch.sigmoid(self.spatial_conv(torch.cat([avg_s, max_s], dim=1))) # (B,1,H,W) lam = torch.sigmoid(self.lam) w_c_exp = w_c.expand_as(m) w_s_exp = w_s.expand_as(m) w_cs = (1 - lam) * w_c_exp + lam * w_s_exp return w_cs * m + m class MultiScaleAware(nn.Module): """MSA: inverted bottleneck with three parallel depthwise kernel sizes.""" def __init__(self, channels, expand=2, groups=4): super().__init__() hidden = channels * expand self.gab = GlobalAttentionBlock(channels) self.expand_pw = nn.Conv2d(channels, hidden, 1) self.dw3 = nn.Conv2d(hidden, hidden, 3, padding=1, groups=hidden) self.dw5 = nn.Conv2d(hidden, hidden, 5, padding=2, groups=hidden) self.dw7 = nn.Conv2d(hidden, hidden, 7, padding=3, groups=hidden) self.groups = groups self.reduce_pw = nn.Conv2d(hidden, channels, 1) self.norm = nn.BatchNorm2d(channels) def channel_shuffle(self, x): b, c, h, w = x.shape g = self.groups x = x.view(b, g, c // g, h, w).transpose(1, 2).contiguous().view(b, c, h, w) return x def forward(self, s_i): o = self.expand_pw(self.gab(s_i)) o1, o2, o3 = self.dw3(o), self.dw5(o), self.dw7(o) fused = self.channel_shuffle(o1 + o2 + o3) out = self.norm(self.reduce_pw(fused)) return out class VSSScan(nn.Module): """Practical stand in for the paper's four direction diagonal selective scan. Uses a depthwise conv gate plus a lightweight gated linear path to mimic the linear layer, layer norm, SS2D, activation, and gating flow in Fig 3b.""" def __init__(self, channels): super().__init__() self.norm = nn.GroupNorm(1, channels) self.in_proj = nn.Conv2d(channels, channels, 1) self.gate_proj = nn.Conv2d(channels, channels, 1) self.dw = nn.Conv2d(channels, channels, 3, padding=1, groups=channels) self.out_proj = nn.Conv2d(channels, channels, 1) def forward(self, x): residual = x x = self.norm(x) main = F.silu(self.dw(self.in_proj(x))) gate = F.silu(self.gate_proj(x)) fused = main * gate out = self.out_proj(fused) return out + residual def row_exchange(a, b): # swap alternating rows between two same shaped feature maps s, d = a.clone(), b.clone() s[:, :, 0::2, :] = b[:, :, 0::2, :] d[:, :, 0::2, :] = a[:, :, 0::2, :] return s, d def column_exchange(a, b): s, d = a.clone(), b.clone() s[:, :, :, 0::2] = b[:, :, :, 0::2] d[:, :, :, 0::2] = a[:, :, :, 0::2] return s, d class CrossMambaDecoder(nn.Module): """CMD: fuses deeper decoder features with same stage MSA features via row and column pixel exchange followed by VSS scanning.""" def __init__(self, channels): super().__init__() self.scan_row_s = VSSScan(channels) self.scan_row_d = VSSScan(channels) self.scan_col_s = VSSScan(channels) self.scan_col_d = VSSScan(channels) self.pwc_row = nn.Conv2d(channels, channels, 1) self.pwc_col = nn.Conv2d(channels, channels, 1) self.gab_row = GlobalAttentionBlock(channels) self.gab_col = GlobalAttentionBlock(channels) self.pwc_merge = nn.Conv2d(channels, channels, 1) self.dw3 = nn.Conv2d(channels, channels, 3, padding=1) self.pwc_out = nn.Conv2d(channels, channels, 1) def forward(self, msa_i, cmd_deeper): cmd_up = F.interpolate(cmd_deeper, size=msa_i.shape[-2:], mode="bilinear", align_corners=False) s_r, d_r = row_exchange(msa_i, cmd_up) s_c, d_c = column_exchange(msa_i, cmd_up) r1 = self.scan_row_s(s_r) r2 = self.scan_row_d(d_r) c1 = self.scan_col_s(s_c) c2 = self.scan_col_d(d_c) b1 = self.gab_row(self.pwc_row(r1 + r2)) b2 = self.gab_col(self.pwc_col(c1 + c2)) merged = self.pwc_merge(b1 + b2) merged = self.dw3(merged) out = self.pwc_out(merged) return out class FeatureDiscovery(nn.Module): """FD: fuses all three CMD outputs from deep to shallow via transpose convolution upsampling and gated residual addition.""" def __init__(self, channels_stage1, channels_stage2, channels_stage3, num_classes=1): super().__init__() self.up_3to2 = nn.ConvTranspose2d(channels_stage3, channels_stage2, kernel_size=4, stride=2, padding=1) self.up_23to1 = nn.ConvTranspose2d(channels_stage2, channels_stage1, kernel_size=4, stride=2, padding=1) self.head = nn.Conv2d(channels_stage1, num_classes, kernel_size=1) def forward(self, cmd1, cmd2, cmd3): up3 = self.up_3to2(cmd3) g23 = up3 * cmd2 + cmd2 up23 = self.up_23to1(g23) fused = up23 * cmd1 + cmd1 out = self.head(fused) return out, g23 class CMFDNet(nn.Module): """Full model. `encoder` must return a list of four feature maps [s1, s2, s3, s4] at decreasing spatial resolution, matching a VMamba-Tiny style backbone with channel widths (96, 192, 384, 768).""" def __init__(self, encoder, channels=(96, 192, 384, 768), num_classes=1): super().__init__() self.encoder = encoder c1, c2, c3, c4 = channels self.msa1 = MultiScaleAware(c1) self.msa2 = MultiScaleAware(c2) self.msa3 = MultiScaleAware(c3) self.align4to3 = nn.Conv2d(c4, c3, 1) self.cmd3 = CrossMambaDecoder(c3) self.align3to2 = nn.Conv2d(c3, c2, 1) self.cmd2 = CrossMambaDecoder(c2) self.align2to1 = nn.Conv2d(c2, c1, 1) self.cmd1 = CrossMambaDecoder(c1) self.fd = FeatureDiscovery(c1, c2, c3, num_classes=num_classes) # deep supervision heads, used only during training self.aux_head3 = nn.Conv2d(c3, num_classes, 1) self.aux_head2 = nn.Conv2d(c2, num_classes, 1) self.aux_head1 = nn.Conv2d(c1, num_classes, 1) def forward(self, x): s1, s2, s3, s4 = self.encoder(x) m1 = self.msa1(s1) m2 = self.msa2(s2) m3 = self.msa3(s3) deep = self.align4to3(s4) cmd3 = self.cmd3(m3, deep) cmd3_aligned = self.align3to2(cmd3) cmd2 = self.cmd2(m2, cmd3_aligned) cmd2_aligned = self.align2to1(cmd2) cmd1 = self.cmd1(m1, cmd2_aligned) logits, _ = self.fd(cmd1, cmd2, cmd3) logits = F.interpolate(logits, size=x.shape[-2:], mode="bilinear", align_corners=False) if self.training: aux3 = F.interpolate(self.aux_head3(cmd3), size=x.shape[-2:], mode="bilinear", align_corners=False) aux2 = F.interpolate(self.aux_head2(cmd2), size=x.shape[-2:], mode="bilinear", align_corners=False) aux1 = F.interpolate(self.aux_head1(cmd1), size=x.shape[-2:], mode="bilinear", align_corners=False) return logits, [aux1, aux2, aux3] return logits class DummyVMambaEncoder(nn.Module): """Minimal stand in encoder for the smoke test, replace with a real pretrained VMamba Tiny backbone for actual training.""" def __init__(self, channels=(96, 192, 384, 768)): super().__init__() c1, c2, c3, c4 = channels self.stage1 = nn.Sequential(nn.Conv2d(3, c1, 4, stride=4), nn.GELU()) self.stage2 = nn.Sequential(nn.Conv2d(c1, c2, 2, stride=2), nn.GELU()) self.stage3 = nn.Sequential(nn.Conv2d(c2, c3, 2, stride=2), nn.GELU()) self.stage4 = nn.Sequential(nn.Conv2d(c3, c4, 2, stride=2), nn.GELU()) def forward(self, x): s1 = self.stage1(x) s2 = self.stage2(s1) s3 = self.stage3(s2) s4 = self.stage4(s3) return [s1, s2, s3, s4] def dice_loss(pred, target, eps=1e-6): pred = torch.sigmoid(pred) num = 2 * (pred * target).sum(dim=(1, 2, 3)) + eps den = pred.sum(dim=(1, 2, 3)) + target.sum(dim=(1, 2, 3)) + eps return 1 - (num / den).mean() def cmfdnet_loss(logits, aux_logits, target, aux_weight=0.4): main = F.binary_cross_entropy_with_logits(logits, target) + dice_loss(logits, target) if aux_logits is None: return main aux_total = 0.0 for a in aux_logits: aux_total = aux_total + F.binary_cross_entropy_with_logits(a, target) + dice_loss(a, target) return main + aux_weight * (aux_total / len(aux_logits)) def train_one_epoch(model, loader, optimizer, device): model.train() running = 0.0 for images, masks in loader: images, masks = images.to(device), masks.to(device) optimizer.zero_grad() logits, aux = model(images) loss = cmfdnet_loss(logits, aux, masks) loss.backward() optimizer.step() running += loss.item() * images.size(0) return running / len(loader.dataset) @torch.no_grad() def evaluate(model, loader, device): model.eval() total_dice, total_iou, n = 0.0, 0.0, 0 for images, masks in loader: images, masks = images.to(device), masks.to(device) logits = model(images) pred = (torch.sigmoid(logits) > 0.5).float() inter = (pred * masks).sum(dim=(1, 2, 3)) union = pred.sum(dim=(1, 2, 3)) + masks.sum(dim=(1, 2, 3)) - inter dice = (2 * inter + 1e-6) / (pred.sum(dim=(1, 2, 3)) + masks.sum(dim=(1, 2, 3)) + 1e-6) iou = (inter + 1e-6) / (union + 1e-6) total_dice += dice.sum().item() total_iou += iou.sum().item() n += images.size(0) return {"mDice": total_dice / n, "mIoU": total_iou / n} if __name__ == "__main__": # smoke test on random dummy data, confirms shapes and gradient flow only device = torch.device("cuda" if torch.cuda.is_available() else "cpu") encoder = DummyVMambaEncoder() model = CMFDNet(encoder, channels=(96, 192, 384, 768), num_classes=1).to(device) batch_size = 2 dummy_images = torch.randn(batch_size, 3, 224, 224, device=device) dummy_masks = (torch.rand(batch_size, 1, 224, 224, device=device) > 0.7).float() optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4) model.train() logits, aux = model(dummy_images) loss = cmfdnet_loss(logits, aux, dummy_masks) loss.backward() optimizer.step() print("training step ok, loss =", loss.item(), "logits shape =", tuple(logits.shape)) model.eval() with torch.no_grad(): eval_logits = model(dummy_images) print("eval step ok, logits shape =", tuple(eval_logits.shape)) assert eval_logits.shape == (batch_size, 1, 224, 224) print("smoke test passed")
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/ES_la/register-person?ref=VDVEQ78S
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.