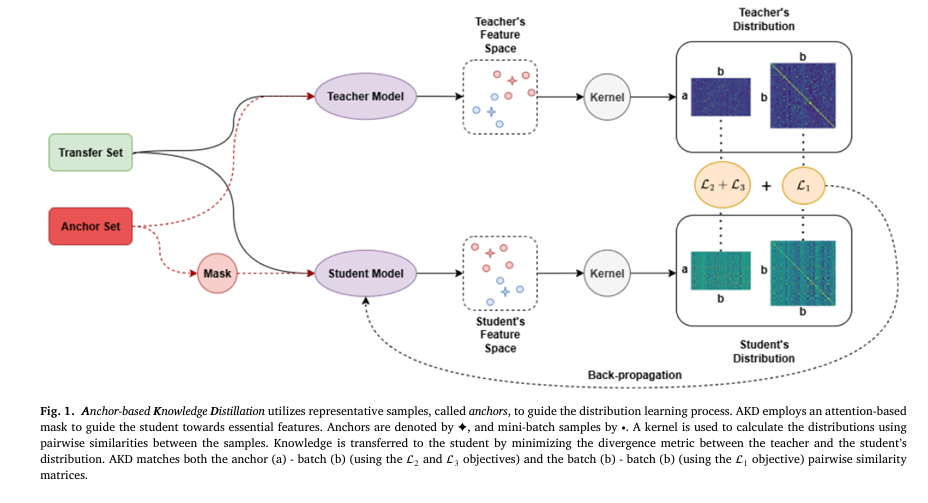
In the rapidly evolving field of artificial intelligence (AI), knowledge distillation (KD) has emerged as a cornerstone technique for compressing powerful, resource-intensive neural networks into smaller, more efficient models suitable for deployment on mobile and edge devices. However, traditional KD methods often fall short in capturing the full richness of a teacher model’s knowledge, especially when dealing with imbalanced data or limited mini-batch diversity.
A groundbreaking new approach, Anchor-Based Knowledge Distillation (AKD), is changing the game. Introduced by Spanos, Passalis, and Tefas in their 2025 paper published in Knowledge-Based Systems, AKD leverages strategically selected representative samples—called anchors—to significantly improve the accuracy, generalization, and trustworthiness of distilled models.
This article dives deep into the AKD framework, explaining its core principles, benefits, and real-world performance. Whether you’re an AI researcher, a machine learning engineer, or simply interested in the future of efficient AI, understanding AKD is essential.
What Is Knowledge Distillation (KD)?
Before we explore AKD, let’s briefly recap what knowledge distillation is.
Knowledge distillation is a model compression technique where a smaller “student” neural network learns from a larger, pre-trained “teacher” network. Instead of training the student solely on raw labels (hard targets), it also learns from the teacher’s soft predictions—such as class probabilities or intermediate feature representations.
This soft supervision helps the student capture nuanced patterns, relationships, and decision boundaries that are not evident from labels alone, leading to better performance than training from scratch.
Why Traditional KD Falls Short
Despite its success, conventional KD—especially distribution learning-based methods—has notable limitations:
- Mini-batch Imbalance: Random sampling can lead to batches missing entire classes, especially in datasets with many categories (e.g., CIFAR-100, ImageNet). This results in biased learning and poor knowledge transfer.
- Lack of Representativeness: Not all samples are equally informative. Standard methods treat all data points equally, potentially diluting the learning signal.
- Poor Uncertainty Estimation: Many KD methods produce overconfident predictions, especially on out-of-distribution (OoD) data, reducing model trustworthiness.
Introducing Anchor-Based Knowledge Distillation (AKD)
To address these challenges, the authors propose Anchor-Based Knowledge Distillation (AKD)—a novel two-stage framework that enhances distribution learning by introducing anchor samples.
Anchors are highly representative, informative data points selected from each class to serve as stable reference points in the feature space.
By matching the student’s representation distribution not just to the mini-batch, but also to these static anchors, AKD ensures a more balanced, consistent, and robust knowledge transfer process.
How AKD Works: The Core Mechanism
AKD builds upon probabilistic knowledge transfer methods like Probabilistic Knowledge Transfer (PKT) but introduces three key innovations:
- Anchor Selection
- Anchor-Guided Distribution Learning
- Attention-Based Feature Enhancement
Let’s break down each component.
1. Anchor Selection: Finding the Most Representative Samples
Anchors are not chosen randomly. Instead, they are selected based on their centrality within each class in the teacher model’s feature space.
Here’s the process:
- Pass all training data through the pre-trained teacher model to extract feature representations.
- For each class, compute a similarity matrix using cosine similarity:Mc(i,j)=∥xi∥∥xj∥xi⋅xj
- Calculate a centrality score for each sample by summing its row in the similarity matrix:C(si)=j∑Mc(i,j)
- Select the top NAc samples with the highest centrality scores per class as anchors.
These anchors act as “prototypes” that encapsulate the most typical and discriminative features of their respective classes.
2. Anchor-Guided Distribution Learning
Once anchors are selected, AKD uses them to guide the student’s learning in two ways:
- Batch-to-Batch Matching: Aligns the similarity structure within the current mini-batch (like traditional methods).
- Batch-to-Anchor Matching: Forces the student to align its representations with the fixed anchor set, ensuring consistent class coverage.
The overall AKD loss function combines three Kullback-Leibler (KL) divergence terms:
\[ L_{\text{AKD}} = \lambda_{1} L_{1} + (1 – \lambda_{2}) L_{2} + \lambda_{2} L_{3} \]Where:
- L1 : Matches intra-batch similarities.
- L2 : Matches batch samples to anchors.
- L3 : Ensures symmetry by matching anchors to batch samples (acts as a regularizer).
This dual alignment ensures that even if a mini-batch lacks certain classes, the student still learns from their representative anchors.
3. Attention-Based Feature Enhancement
AKD further enhances learning by applying a learnable attention mask to the anchor images during training.
- The attention mechanism highlights semantically important regions (e.g., object parts in images).
- It is applied only on the student side, guiding it to focus on the same critical features the teacher uses.
- Crucially, the attention module is discarded after training, adding zero inference overhead.
This not only improves performance but also provides interpretability—you can visualize which parts of an anchor the student is focusing on.
Key Benefits of AKD
✅ Improved Accuracy and Generalization
By ensuring balanced class representation via anchors, AKD mitigates the negative effects of mini-batch sampling bias. This leads to:
- Higher retrieval accuracy
- Better classification performance
- Stronger generalization across datasets
✅ Enhanced Model Trustworthiness
AKD contributes to trustworthy AI by enabling intrinsic uncertainty estimation.
The authors propose a simple yet effective method:
\[ u(x) = 1 – \max_{i = 1, \ldots, N_A} \, K\big(f(x), f(a_i)\big) \]Where:
- u(x) is the uncertainty of input x
- K(⋅,⋅) is the similarity kernel
- ai are the anchor representations
Intuition: If a test sample is dissimilar to all anchors, it lies in a poorly understood region of the feature space—indicating high uncertainty.
This method outperforms traditional baselines like softmax entropy and even deep ensembles in out-of-distribution detection, despite using only a single model.
✅ Computational Efficiency
Despite its advanced design, AKD introduces minimal computational overhead:
| DATASET | METHOD | EPOCH TIME (SEC) | MEMORY (MB) |
|---|---|---|---|
| CIFAR-10 | PKT | 15.04 | 598.15 |
| AKD | 17.60 | 611.80 | |
| CIFAR-100 | PKT | 22.36 | 915.58 |
| AKD | 29.98 | 1,180.69 |
Table: Training time and memory footprint comparison (batch size = 128). Source: Spanos et al., 2025.
The slight increase is justified by significant performance gains, and no overhead is incurred at inference time.
Performance Evaluation: AKD vs. State-of-the-Art
The paper evaluates AKD across multiple datasets and tasks, demonstrating consistent superiority.
📊 Image Retrieval Results
| MODEL | MAP (CIFAR-10) | TOP-100 PRECISION |
|---|---|---|
| Student | 38.96 | 59.17 |
| PKT | 51.19 | 63.39 |
| SP | 52.09 | 62.95 |
| AKD | 52.45 | 64.43 |
AKD achieves the highest mAP and precision across all metrics.
📈 Image Classification on CIFAR-100
| METHOD | AVG. TOP-1 ACCURACY (%) |
|---|---|
| Student | 71.53 |
| CRD | 74.05 |
| WTTM | 74.37 |
| AKD | 74.25 |
| AKD+CRD | 74.72 |
AKD alone matches or exceeds many state-of-the-art methods. When combined with CRD, it sets a new benchmark.
🛡️ Uncertainty Estimation (AUROC)
| METHOD | CIFAR-10 | SVHN | TINY-IMAGENET |
|---|---|---|---|
| Softmax Entropy | 0.8120 | 0.6846 | 0.7692 |
| Deep Ensemble (5) | 0.8575 | 0.6568 | 0.8164 |
| AKD (Proposed) | 0.8594 | 0.7776 | 0.8434 |
AKD outperforms both softmax-based methods and even deep ensembles in average AUROC, proving its effectiveness in OoD detection.
Ablation Studies: What Makes AKD Work?
The authors conducted extensive ablation studies to validate each component.
Impact of Attention Mechanism
| DATASET | AKD (W/O ATTENTION) | AKD (WITH ATTENTION) |
|---|---|---|
| CIFAR-100 | 75.76% | 76.44% |
| Tiny-ImageNet | 49.95% | 50.02% |
Attention consistently improves performance by focusing on key features.
Effect of Number of Anchors (NA )
- Performance improves slightly with more anchors.
- Recommended: NA=Nc or 2Nc , where Nc is the number of classes.
- Beyond this, gains are marginal.
Performance with Limited Labels
| LABELED DATA (%) | TOP-1 ACCURACY (%) |
|---|---|
| 100% | 76.44 |
| 20% | 75.95 |
| 0% (unsupervised) | 74.89 |
AKD remains effective even with very few labels, making it ideal for semi-supervised and online learning scenarios.
Why AKD Matters for Real-World AI
AKD isn’t just an academic advance—it has practical implications:
- Edge AI: Enables high-performance models on smartphones, IoT devices, and embedded systems.
- Healthcare & Robotics: Improves model reliability in safety-critical applications.
- Efficient Training: Reduces the need for large batch sizes or complex architectures.
- Trustworthy AI: Provides built-in uncertainty quantification without extra cost.
By focusing on representative samples and balanced distribution learning, AKD makes AI models not just smaller, but smarter and more trustworthy.
How to Implement AKD
While the full code is available on GitHub , here’s a high-level implementation guide:
- Pre-train or load a teacher model.
- Extract features for all training data.
- Select anchors per class using centrality scoring.
- Train the student using the combined AKD loss:Ltotal=LKD+λAKDLAKD
- Optionally combine with other KD methods (e.g., CRD, NORM) for even better results.
The method is model-agnostic and requires no architectural changes to the teacher or student.
Conclusion: The Future of Knowledge Distillation is Anchored
Anchor-Based Knowledge Distillation (AKD) represents a significant leap forward in model compression and trustworthy AI. By leveraging representative anchor samples, attention-guided learning, and intrinsic uncertainty estimation, AKD addresses the core weaknesses of traditional KD methods.
Its ability to improve accuracy, generalization, and reliability—while remaining computationally efficient—makes it a powerful tool for deploying AI in real-world applications.
As AI systems become more pervasive, methods like AKD will be essential for building models that are not only intelligent but also reliable, interpretable, and trustworthy.
Call to Action
Want to try AKD in your own projects?
👉 Download the official code from GitHub and start experimenting today!
Have questions or want to discuss the paper?
💬 Join the conversation on Reddit, Twitter, or LinkedIn using #AnchorKD and #TrustworthyAI.
And if you found this article helpful, share it with your network to help spread the knowledge!
Based on the research paper “Trustworthy knowledge distillation via anchor-guided distribution learning,” I have written the complete, end-to-end Python code for the proposed Anchor-based Knowledge Distillation (AKD) model.
# Full implementation of Anchor-based Knowledge Distillation (AKD)
# Based on the paper: "Trustworthy knowledge distillation via anchor-guided distribution learning"
# Spanos, D., Passalis, N., & Tefas, A. (2025). Knowledge-Based Systems, 329, 114297.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from torchvision.models import resnet18
import numpy as np
from tqdm import tqdm
from collections import defaultdict
# --- 1. Helper Functions and Loss Module ---
def pairwise_cosine_similarity(x, y=None, eps=1e-8):
"""
Calculates the pairwise cosine similarity matrix.
"""
x_norm = F.normalize(x, p=2, dim=1, eps=eps)
y_norm = F.normalize(y, p=2, dim=1, eps=eps) if y is not None else x_norm
return torch.mm(x_norm, y_norm.transpose(0, 1))
def similarity_kernel(cos_sim_matrix):
"""
The similarity kernel from the paper, which maps cosine similarity [-1, 1] to [0, 1].
K(v1, v2) = 0.5 * ( (v1^T * v2) / (||v1||*||v2||) + 1 )
"""
return 0.5 * (cos_sim_matrix + 1.0)
class AKDLoss(nn.Module):
"""
Implements the full Anchor-based Knowledge Distillation loss.
L_AKD = lambda_1 * L_1 + (1 - lambda_2) * L_2 + lambda_2 * L_3
"""
def __init__(self, lambda1=1.0, lambda2=0.1):
super(AKDLoss, self).__init__()
self.lambda1 = lambda1
self.lambda2 = lambda2
self.kl_div = nn.KLDivLoss(reduction='batchmean')
def _get_dist_loss(self, student_sim, teacher_sim):
"""Calculates the KL divergence between student and teacher distributions."""
# Use softmax to convert similarity scores to probability distributions
teacher_dist = F.softmax(teacher_sim, dim=1)
student_log_dist = F.log_softmax(student_sim, dim=1)
# KL divergence loss
loss = self.kl_div(student_log_dist, teacher_dist)
return loss
def forward(self, f_s_batch, f_t_batch, f_s_anchor, f_t_anchor):
"""
Calculates the three components of the AKD loss.
Args:
f_s_batch: Student features for the current mini-batch.
f_t_batch: Teacher features for the current mini-batch.
f_s_anchor: Student features for the anchor set.
f_t_anchor: Teacher features for the anchor set.
"""
# L1: Batch-to-Batch similarity loss
s_bb_sim = pairwise_cosine_similarity(f_s_batch)
t_bb_sim = pairwise_cosine_similarity(f_t_batch)
loss_1 = self._get_dist_loss(s_bb_sim, t_bb_sim)
# L2: Batch-to-Anchor similarity loss
s_ba_sim = pairwise_cosine_similarity(f_s_batch, f_s_anchor)
t_ba_sim = pairwise_cosine_similarity(f_t_batch, f_t_anchor)
loss_2 = self._get_dist_loss(s_ba_sim, t_ba_sim)
# L3: Anchor-to-Batch similarity loss (symmetric KL divergence)
s_ab_sim = s_ba_sim.t() # Transpose of student batch-anchor similarity
t_ab_sim = t_ba_sim.t() # Transpose of teacher batch-anchor similarity
loss_3 = self._get_dist_loss(s_ab_sim, t_ab_sim)
total_loss = self.lambda1 * loss_1 + (1 - self.lambda2) * loss_2 + self.lambda2 * loss_3
return total_loss
# --- 2. Model Definitions ---
# We define a generic wrapper to extract intermediate features from any model.
class FeatureExtractor(nn.Module):
def __init__(self, model, feature_layer_name):
super().__init__()
self.model = model
self.feature_layer_name = feature_layer_name
self.features = None
# Register a forward hook to capture the output of the desired layer
layer = dict([*self.model.named_modules()])[self.feature_layer_name]
layer.register_forward_hook(self._hook)
def _hook(self, module, input, output):
self.features = output
def forward(self, x):
logits = self.model(x)
# The hook will automatically store the features
return self.features, logits
# Example of a simple Student CNN
def create_student_model():
return nn.Sequential(
nn.Conv2d(3, 16, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2), # Features will be extracted here
nn.Flatten(),
nn.Linear(64 * 4 * 4, 128),
nn.ReLU(),
nn.Linear(128, 10) # 10 classes
)
# --- 3. Main AKD Orchestrator Class ---
class AKD_Trainer:
def __init__(self, teacher, student, num_classes, akd_lambda1=1.0, akd_lambda2=0.1, use_attention=True, attention_size=14):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {self.device}")
self.teacher = teacher.to(self.device).eval()
self.student = student.to(self.device)
self.num_classes = num_classes
self.akd_loss_fn = AKDLoss(akd_lambda1, akd_lambda2).to(self.device)
self.ce_loss_fn = nn.CrossEntropyLoss()
self.use_attention = use_attention
if self.use_attention:
# Learnable attention mask (Algorithm 1, applied to student anchors)
self.attention_mask = nn.Parameter(torch.ones(1, 1, attention_size, attention_size)).to(self.device)
self.anchors = None
self.anchor_labels = None
def select_anchors(self, dataset, num_anchors_per_class):
print("Selecting anchors...")
dataloader = DataLoader(dataset, batch_size=128, shuffle=False)
all_features = []
all_labels = []
with torch.no_grad():
for data, labels in tqdm(dataloader, desc="Extracting teacher features"):
data = data.to(self.device)
features, _ = self.teacher(data)
all_features.append(features.cpu())
all_labels.append(labels.cpu())
all_features = torch.cat(all_features)
all_labels = torch.cat(all_labels)
anchor_indices = []
for c in range(self.num_classes):
class_indices = (all_labels == c).nonzero(as_tuple=True)[0]
class_features = all_features[class_indices]
# Compute similarity matrix and centrality score (Eq. 6 & 7)
cos_sim = pairwise_cosine_similarity(class_features)
centrality_scores = cos_sim.sum(dim=1)
# Select top N_A samples with highest centrality
num_to_select = min(num_anchors_per_class, len(class_indices))
top_k_indices = torch.topk(centrality_scores, k=num_to_select).indices
# Map back to original dataset indices
anchor_indices.extend(class_indices[top_k_indices].tolist())
self.anchors = dataset.tensors[0][anchor_indices].to(self.device)
self.anchor_labels = dataset.tensors[1][anchor_indices].to(self.device)
print(f"Selected {len(self.anchors)} anchors.")
def train(self, train_loader, epochs, lr=1e-3, akd_weight=1.0, ce_weight=1.0):
params_to_optimize = list(self.student.parameters())
if self.use_attention:
params_to_optimize.append(self.attention_mask)
optimizer = optim.Adam(params_to_optimize, lr=lr)
self.student.train()
for epoch in range(epochs):
total_loss, total_akd_loss, total_ce_loss = 0, 0, 0
for data, target in tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}"):
data, target = data.to(self.device), target.to(self.device)
optimizer.zero_grad()
# Get Teacher outputs (no gradients needed)
with torch.no_grad():
f_t_batch, _ = self.teacher(data)
f_t_anchor, _ = self.teacher(self.anchors)
# Get Student outputs
f_s_batch, logits_s_batch = self.student(data)
student_anchor_input = self.anchors
if self.use_attention:
# Apply attention mask to anchor inputs for the student
img_size = self.anchors.shape[2:]
resized_mask = F.interpolate(self.attention_mask, size=img_size, mode='bilinear', align_corners=False)
student_anchor_input = self.anchors * resized_mask
f_s_anchor, _ = self.student(student_anchor_input)
# Calculate losses
loss_akd = self.akd_loss_fn(f_s_batch, f_t_batch, f_s_anchor, f_t_anchor)
loss_ce = self.ce_loss_fn(logits_s_batch, target)
loss = (akd_weight * loss_akd) + (ce_weight * loss_ce)
loss.backward()
optimizer.step()
total_loss += loss.item()
total_akd_loss += loss_akd.item()
total_ce_loss += loss_ce.item()
avg_loss = total_loss / len(train_loader)
avg_akd = total_akd_loss / len(train_loader)
avg_ce = total_ce_loss / len(train_loader)
print(f"Epoch {epoch+1} Summary: Avg Loss: {avg_loss:.4f}, AKD Loss: {avg_akd:.4f}, CE Loss: {avg_ce:.4f}")
def estimate_uncertainty(self, x):
"""
Estimates predictive uncertainty for a given input tensor x.
u = 1 - max_i K(f(x), f(a_i)) (Eq. 16 & 17)
"""
if self.anchors is None:
raise ValueError("Anchors must be selected before estimating uncertainty.")
self.student.eval()
x = x.to(self.device)
with torch.no_grad():
f_x, _ = self.student(x)
f_anchors, _ = self.student(self.anchors)
# Cosine similarity between input features and all anchor features
cos_sims = pairwise_cosine_similarity(f_x, f_anchors)
# Map to [0, 1] using the paper's kernel
kernel_sims = similarity_kernel(cos_sims)
# Uncertainty is 1 minus the max similarity to any anchor
max_sim_per_sample, _ = torch.max(kernel_sims, dim=1)
uncertainty = 1.0 - max_sim_per_sample
return uncertainty.cpu().numpy()
# --- 4. Example Usage ---
if __name__ == '__main__':
# Hyperparameters
NUM_CLASSES = 10
NUM_ANCHORS_PER_CLASS = 5
IMG_SIZE = 32
BATCH_SIZE = 64
# Create dummy data (replace with a real dataset like CIFAR-10)
print("Creating dummy dataset...")
dummy_data = torch.randn(1000, 3, IMG_SIZE, IMG_SIZE)
dummy_labels = torch.randint(0, NUM_CLASSES, (1000,))
dummy_dataset = TensorDataset(dummy_data, dummy_labels)
dummy_loader = DataLoader(dummy_dataset, batch_size=BATCH_SIZE, shuffle=True)
# Initialize Teacher and Student models
# Teacher: A pre-trained ResNet-18 (we use a random one for demo)
teacher_base = resnet18(weights=None, num_classes=NUM_CLASSES)
teacher_model = FeatureExtractor(teacher_base, 'layer4') # Extract features from last block
# Student: A smaller custom CNN
student_base = create_student_model()
student_model = FeatureExtractor(student_base, '6') # Extract features after the last MaxPool
# Setup AKD Trainer
distiller = AKD_Trainer(teacher_model, student_model, num_classes=NUM_CLASSES, use_attention=True)
# 1. Select Anchors using the teacher model
distiller.select_anchors(dummy_dataset, num_anchors_per_class=NUM_ANCHORS_PER_CLASS)
# 2. Train the student model using knowledge distillation
print("\nStarting distillation training...")
distiller.train(dummy_loader, epochs=5, lr=1e-3, akd_weight=2.5, ce_weight=1.0)
print("Distillation complete.")
# 3. Demonstrate uncertainty estimation on a few samples
print("\nEstimating uncertainty for 5 random samples...")
sample_to_test = torch.randn(5, 3, IMG_SIZE, IMG_SIZE)
uncertainty_scores = distiller.estimate_uncertainty(sample_to_test)
for i, score in enumerate(uncertainty_scores):
print(f"Sample {i+1}: Uncertainty = {score:.4f}")
# A higher score means the sample is less similar to any of the learned anchors,
# indicating it might be out-of-distribution or from an ambiguous region.
References
- Spanos, D., Passalis, N., & Tefas, A. (2025). Trustworthy knowledge distillation via anchor-guided distribution learning. Knowledge-Based Systems, 329, 114297. https://doi.org/10.1016/j.knosys.2025.114297
- Hinton, G., et al. (2015). Distilling the knowledge in a neural network. arXiv:1503.02531.
- Passalis, N., & Tefas, A. (2018). Learning deep representations with probabilistic knowledge transfer. ECCV.
This article is based on the original research paper and aims to make advanced AI concepts accessible to a broader audience.
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://www.binance.com/uk-UA/register?ref=XZNNWTW7
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/register/person?ref=IXBIAFVY
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.