Revolutionizing Construction Management: How Ontology-Guided LLMs Decode Site Images for Smarter Decisions
In the fast-paced world of construction, real-time insights into on-site activities are crucial. Understanding what workers are doing, how equipment is being used, and whether tasks align with schedules can make or break a project’s success. Traditionally, this has relied on manual reporting or rigid AI models that struggle to adapt to the chaotic, ever-changing nature of construction sites.
Now, a groundbreaking approach is emerging: ontology-based prompting with Large Language Models (LLMs). This innovative method combines structured domain knowledge with the reasoning power of generative AI to infer complex construction activities directly from images—without needing thousands of labeled training examples.
In this comprehensive guide, we’ll explore how researchers have successfully applied this technique to achieve 73.68% accuracy in construction activity recognition, examine the role of ontologies like ConSE, and reveal why this hybrid strategy represents the future of intelligent site monitoring.
What Is Ontology-Based LLM Prompting in Construction AI?
At its core, ontology-based LLM prompting transforms raw visual data into semantically rich, structured inputs that large language models can understand and reason over. Unlike traditional image captioning—which often lacks precision—this method uses a formal construction-domain ontology to represent scene elements such as workers, equipment, materials, spatial relationships, and actions using standardized concepts.
An ontology, in this context, acts as a shared vocabulary and logical framework. It defines:
- Classes (e.g.,
Worker,Excavator,ConcretePouring) - Attributes (e.g., posture, tool usage)
- Relationships (e.g., “operating”, “monitoring”, “near”)
This structure allows AI systems to move beyond simple object detection and toward context-aware semantic interpretation—a critical leap for practical applications in construction management.
Key Takeaway: Ontology-based LLM prompting bridges the gap between computer vision outputs and high-level reasoning by grounding visual features in formal domain semantics.
Why Traditional Methods Fall Short
Before diving into the solution, it’s essential to understand the limitations of current approaches:
| METHOD | KEY LIMITATIONS |
|---|---|
| Supervised Learning | Requires massive annotated datasets; poor generalization to unseen scenarios; lacks interpretability |
| Knowledge-Based Rules | Static logic fails in dynamic environments; hard to scale across diverse projects |
| Standard Image Captioning + LLMs | Loses fine-grained visual detail; ambiguous descriptions reduce accuracy |
These shortcomings hinder scalability and reliability—especially when dealing with rare or complex activities like safety monitoring or multi-agent coordination.
The Proposed Framework: A Step-by-Step Breakdown
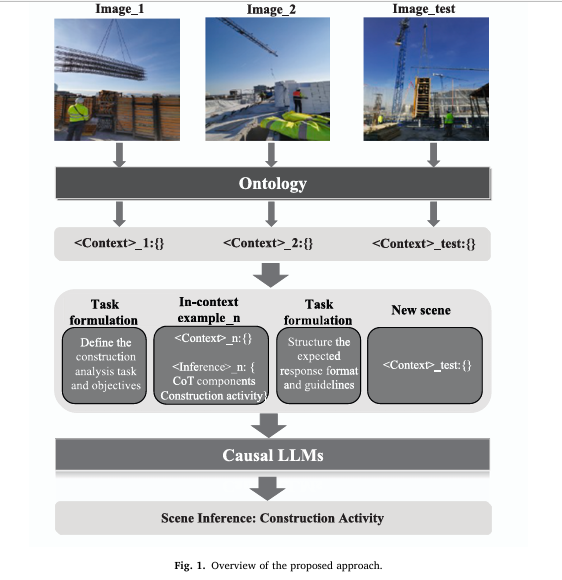
The research introduces a novel pipeline that leverages in-context learning within LLMs, guided by an ontology-driven representation of construction scenes.
Core Components of the Ontology-Based LLM Prompting System
1. Diverse Visual Information Extraction
Instead of relying solely on bounding boxes or captions, the system extracts multiple layers of visual data using advanced computer vision techniques:
| ALGORITHM | OUTPUT TYPE | ROLE IN ACTIVITY RECOGNITION |
|---|---|---|
| Object Detection | Entities (Worker_1,Excavator) | Identifies key actors and objects |
| Pose Estimation | Posture & Joint Data | Infers physical actions (e.g., lifting, drilling) |
| Attention Analysis | Gaze Direction | Reveals focus of attention (e.g., monitoring) |
| Relative Relationship Analysis | Spatial/Functional Links | Captures interactions (e.g., worker operating crane) |
| Grid-Based Spatial Indexing | NxN Position Tags | Encodes location context (N=3 used in study) |
Each entity is enriched with metadata and mapped to ontology classes, forming symbolic triples like:
(Worker_1, hasPosture, Standing)
(Worker_1, operating, Hoist_1)
(Hoist_1, lifting, Formwork_1)
(Formwork_1, locatedAt, GridCell_5)2. Ontology-Grounded Scene Representation
Using the ConSE ontology—a task-agnostic model covering low-level visuals to high-level semantics—the system converts image content into structured <Context> blocks. For example:
{
"entities": ["Worker_1", "Hoist_1", "Formwork_1"],
"attributes": {"Worker_1": "Standing", "Hoist_1": "Active"},
"relationships": [
{"subject": "Worker_1", "predicate": "operating", "object": "Hoist_1"},
{"subject": "Hoist_1", "predicate": "lifting", "object": "Formwork_1"}
],
"spatial_grid": {"Formwork_1": 5, "Worker_1": 4}
}This formalism ensures consistency, reduces ambiguity, and enables precise alignment with known activity patterns.
3. Chain-of-Thought (CoT) Prompt Engineering
A major innovation lies in integrating Chain-of-Thought reasoning into prompts. Instead of asking “What activity is shown?”, the model is guided through intermediate steps:
“Based on the presence of a worker operating a hoist that is lifting formwork near a column, and given that no pouring or cutting is occurring, the most likely activity is FormworkSetup.”
This mimics human expert reasoning and significantly improves inference accuracy.
The full prompt architecture includes:
- Task Instruction Prompt: Sets role, context, and objective
- In-Context Examples: 3 structured
<Context>→<Inference>pairs - Output Formatting Guide: Ensures consistent response structure
See Figure 1 in the paper for a complete workflow diagram.
Evaluation: Performance Metrics and Results
To test the system, researchers evaluated GPT-3.5-turbo on a dataset of 53 images representing 29 construction activity types drawn from the ConSE ontology.
Base Experiment Configuration
| PARAMETER | SETTING |
|---|---|
| LLM Model | gpt-3.5-turbo-0613 |
| Temperature | 0.5 |
| Top_p | 0.3 |
| In-Context Examples | 3 |
| Visual Inputs | Entity + Attribute + Attention + Relationship + Spatial |
Predictions were allowed across all 41 ontology-defined activities, not just the 29 present in the dataset, to assess generalization.
Key Performance Metrics
Four evaluation metrics were used to capture different aspects of performance:
| METRIC | FORMULA | INTERPRETATION |
|---|---|---|
| Activity Accuracy | Total True Positives / Total Samples | Overall correctness of predicted activity labels |
| Activity+Elements Accuracy | Exact match of both activity and involved entities | Measures group activity recognition capability |
| Redundancy Rate | \[\frac{\text{# of ‘None’ added to GT}}{\text{Original # of GT labels}}\] | Indicates over-prediction (false positives) |
| Miss Rate | \[\frac{\text{# of ‘None’ added to prediction}}{\text{# of GT labels}}\] | Reflects under-prediction (false negatives) |
Results from the base experiment:
| METRIC | SCORE |
|---|---|
| Activity Accuracy | 73.68% |
| Activity+Elements Accuracy | 50.00% |
| Redundancy Rate | 20.78% |
| Miss Rate | 3.91% |
While not surpassing top-performing supervised models (~80%), these results demonstrate strong few-shot generalization—achieving competitive accuracy with only three in-context examples, compared to thousands of labeled images required by conventional deep learning.
Ablation Studies: What Drives Success?
To isolate the impact of each design choice, ablation studies were conducted. Here’s what they revealed:
Impact of Chain-of-Thought Reasoning
Removing CoT components caused a significant drop:
- Activity Accuracy: ↓ from 73.68% to 65.78%
- Activity+Elements Accuracy: ↓ from 50.00% to 44.73%
- Miss Rate nearly doubled
✅ Insight: CoT prompting enhances logical consistency and helps the model connect interactions to higher-level activities.
Value of Advanced Visual Features
| FEATURE REMOVED | ACTIVITY ACC DROP | ACTIVITY + ELEMENTS ACC DROP |
|---|---|---|
| Only Entities (w/ E) | –9.21% | –27.63% |
| No Spatial Info (w/o S) | –6.57% | –8.57% |
| No Attention Cues (w/o Ac) | –6.57% | –13.16% |
| No Attributes/Relations (w/o AR) | –5.26% | –18.42% |
Notably, attention cues had a dramatic effect on ProcessMonitoring recognition:
- With cues: 14.29% accuracy
- Without: 0.00% accuracy
Similarly, adding attribute and relational data boosted performance from 0% to 40.79% in some configurations.
✅ Insight: Rich contextual signals like gaze direction and functional relationships are vital for disambiguating similar-looking scenes.
Optimal Randomness and Example Count
Interestingly, introducing moderate randomness (temperature = 1.0, top_p = 0.6) improved both metrics:
- Activity Accuracy: ↑ to 77.63%
- Activity+Elements Accuracy: ↑ to 53.95%
However, high randomness degraded performance due to incoherent outputs.
Regarding in-context examples:
- 1 example: 71.05% activity accuracy
- 2 examples: 69.73%
- 3 examples: 73.68%
✅ Insight: There’s a sweet spot—too few examples limit pattern learning; too many may introduce noise or confusion.
Practical Implications for Construction Professionals
This research isn’t just theoretical—it offers tangible benefits for real-world project management.
Five Strategic Advantages of Ontology-Based LLM Prompting
- Data Efficiency
Achieves meaningful results with minimal labeled data—ideal for niche or evolving construction workflows. - Few-Shot Generalization
Adapts quickly to new project types without retraining, supporting rapid deployment across sites. - Semantic Structuring Enhances Interoperability
Ontologies enable integration with BIM, scheduling tools, and safety databases via standardized queries. - Transparent and Explainable Outputs
CoT reasoning provides natural-language explanations, building trust among engineers and site managers. - Scalable Across Tasks
Same framework can be repurposed for hazard detection, progress tracking, or compliance auditing.
For instance, one could extend the prompt to ask:
“Based on detected entities and their interactions, list potential safety risks and cite relevant OSHA regulations.”
This flexibility makes the approach highly adaptable.
Limitations and Future Directions
Despite promising results, several challenges remain:
- Lack of Depth Perception: 2D spatial indexing struggles with depth ambiguity, especially in wide-angle shots.
- Dependency on Accurate CV Inputs: Errors in pose estimation or object detection propagate into flawed reasoning.
- Model Knowledge Gaps: Off-the-shelf LLMs may lack sufficient construction-specific expertise.
- Prompt Robustness: Poorly chosen in-context examples can mislead the model.
Future work should explore:
- Integration with vision-language models (VLMs) like BLIP-2 for end-to-end feature alignment
- Use of MPEG-7 descriptors or bounding box coordinates for richer spatial encoding
- Fine-tuning LLMs on construction-specific corpora to improve domain fluency
Conclusion: Toward Intelligent, Context-Aware Construction Sites
Ontology-based LLM prompting marks a pivotal shift in how we analyze construction imagery. By combining structured domain knowledge with generative reasoning, this method delivers a scalable, interpretable, and adaptive solution for activity recognition.
With an accuracy of 73.68% using only three in-context examples, it proves that high-performance AI doesn’t always require big data—it requires smart structuring.
As LLM context windows expand and multimodal models mature, embedding entire ontologies directly into prompts will unlock even deeper understanding, enabling real-time digital twins, automated progress validation, and proactive risk mitigation.
🔍 Want to implement this in your organization?
Explore open-source ontologies like ConSE or DiCon-SII, start curating small sets of annotated site photos, and experiment with GPT-4 or open-weight models like LLaMA via APIs.
We’d love to hear your thoughts! Have you tried using LLMs for construction analysis? Share your experiences in the comments below or download the full research paper here to dive deeper into the technical details.
Based on the research paper “Ontology-based LLM prompting with large language models for inferring construction activities from construction images,” I have written a complete Python implementation of the proposed model’s methodology.
# -*- coding: utf-8 -*-
"""
Ontology-Based Construction Activity Recognition using LLMs
This script provides a complete Python implementation of the methodology proposed
in the paper: "Ontology-based prompting with large language models for inferring
construction activities from construction images" by C. Zeng, T. Hartmann, and L. Ma.
The script simulates the end-to-end workflow described in the paper:
1. **Visual Information Extraction**: Simulates the output of various computer
vision models (e.g., object detection, pose estimation) to extract entities,
attributes, and relationships from an image.
2. **Ontology-based Scene Context Creation**: Transforms the extracted visual
information into a structured, ontology-guided text representation, as
shown in Figure 2 of the paper.
3. **Prompt Engineering**: Constructs a comprehensive prompt for a Large Language
Model (LLM) by combining:
- Task Formulation (Figure 3)
- In-Context Examples with Chain-of-Thought (CoT) reasoning
- Output Formulation (Figure 4)
- The new, unseen scene for inference.
4. **LLM Inference**: Simulates a call to a causal LLM (like GPT-3.5) to get the
inferred construction activity. The actual network call is mocked to ensure
the script runs without an API key.
5. **Output Parsing**: Displays the final inference from the model.
Note: Since the actual computer vision models, the specific ConSE ontology,
and the LLM API are external dependencies, this script uses mock data and a
simulated API call to focus on demonstrating the core logic and structure of
the proposed prompting technique.
"""
import json
class OntologyBasedActivityRecognizer:
"""
Encapsulates the entire process of inferring construction activities
from images using ontology-based prompting with an LLM.
"""
def __init__(self, llm_api_endpoint="mock_endpoint"):
"""
Initializes the recognizer.
Args:
llm_api_endpoint (str): The endpoint for the LLM API.
Here, it's a mock endpoint.
"""
self.llm_api_endpoint = llm_api_endpoint
print("OntologyBasedActivityRecognizer initialized.")
# --- Step 1: Simulate Visual Information Extraction ---
def _simulate_visual_information_extraction(self, image_path):
"""
Simulates the output of running multiple CV algorithms on an image.
In a real-world application, this function would use models for object
detection, pose estimation, attention analysis, etc.
Args:
image_path (str): The path to the input image.
Returns:
dict: A dictionary containing the extracted visual information.
"""
print(f"\n[Step 1] Simulating visual information extraction for: {image_path}")
# Mock data based on the image path. This simulates the CV pipeline output.
if "test_image_formwork.jpg" in image_path:
# This mock data is based on Figure 7 in the paper.
return {
"entities": [
{"id": "Worker_1", "class": "Worker", "grid_location": [8]},
{"id": "Hoist_1", "class": "Hoist", "grid_location": [2]},
{"id": "FormworkRegion_1", "class": "FormworkRegion", "grid_location": [5]},
{"id": "Column_1", "class": "Column", "grid_location": [4]},
{"id": "Column_2", "class": "Column", "grid_location": [6]},
{"id": "WoodenPlateRegion_1", "class": "WoodenPlateRegion", "grid_location": [7]},
],
"attributes": [
{"entity_id": "Worker_1", "property": "hasPosture", "value": "Standing"},
],
"relationships": [
{"subject": "Worker_1", "predicate": "hasAttentionOn", "object": "Hoist_1"},
{"subject": "Hoist_1", "predicate": "isNear", "object": "FormworkRegion_1"},
{"subject": "FormworkRegion_1", "predicate": "isAttachedTo", "object": "Column_2"},
]
}
# Default mock data for any other image
return {
"entities": [
{"id": "Worker_1", "class": "Worker", "grid_location": [5, 8]},
{"id": "ReinforcementRegion_1", "class": "ReinforcementRegion", "grid_location": [1, 2, 4, 5]},
],
"attributes": [
{"entity_id": "Worker_1", "property": "hasPosture", "value": "Bending"},
],
"relationships": []
}
# --- Step 2: Create Ontology-based Scene Context ---
def _create_ontology_guided_representation(self, visual_info):
"""
Formats the extracted visual information into a structured text block
based on the ontology schema. This implements the concept from Figure 2.
Args:
visual_info (dict): The dictionary from the simulation step.
Returns:
str: A formatted string representing the scene context.
"""
print("[Step 2] Creating ontology-guided scene representation.")
context_str = "<Context>:{\n"
context_str += " Entity:{\n"
for item in visual_info["entities"]:
loc = ",".join(map(str, item['grid_location']))
context_str += f" {item['id']} a {item['class']} ({loc})\n"
context_str += " }\n"
context_str += " Attribute:{\n"
for item in visual_info["attributes"]:
context_str += f" {item['entity_id']} {item['property']} {item['value']}\n"
context_str += " }\n"
context_str += " Relationship:{\n"
for item in visual_info["relationships"]:
context_str += f" {item['subject']} {item['predicate']} {item['object']}\n"
context_str += " }\n"
context_str += "}"
return context_str
# --- Step 3: Prompt Engineering ---
def _get_task_formulation_prompt(self):
"""
Returns the task formulation prompt as described in Figure 3.
This sets the role, context, and task for the LLM.
"""
return """Your role is that of a construction engineering professional, and I'm proposing a collaborative effort in understanding of how visual data in a specific context leads to inferences.
To start, I'll provide you with images for in-context learning. I'll address your limitations associated with processing image inputs by presenting examples based on the ontology-based knowledge graphs. The graph has two parts:
The <Context>: This section includes basic visual facts. Each image is divided into a 3x3 grid, and numerical annotations indicate the spatial location of each entity, whether fully or partially occupied, within the image.
The <Inference>: This part encapsulates the results inferred by combining the visual facts with underlying heuristics.
All elements in the input are represented as triples and have explicit semantic meaning. To fully understand the input, your task is to carefully analyze each triple by considering both the given ontology and your expertise in construction. Your primary goal is to learn the implicit heuristics connecting the <Context> and the <Inference>. This will require you to utilize the provided examples, the ontology, and your domain-specific knowledge."""
def _get_output_formulation_prompt(self):
"""
Returns the output formulation prompt as described in Figure 4.
This guides the LLM on how to structure its response.
"""
return """I believe you have already grasped the implicit heuristics. Now you should apply your learnt heuristics to generate the <Inference>, as per formatted in the examples, based on the new test <Context> I shall provide later. Here are some guidelines to follow when generating your answer:
1. When generating the activity type for an <Activity>, it's crucial to specifically map your understanding to the terms within the brackets that I will provide later.
Activity:[ConcretePouring, FormworkSetUp, ReinforcementAssembly, SoilExcavation, ProcessMonitoring, ...]
2. When selecting participants for an activity, it's essential to ensure that each activity includes, at the very least, either a worker or a heavy machine.
3. When the given context involves concurrent activities, you are encouraged to include multiple activities in your response.
4. Please refrain from making excessive assumptions about the situation. Instead, strive to provide reasonable inferences based on the context provided. If certain entities are not actively participating in any activities, please avoid suggesting activities for them."""
def _get_in_context_examples(self):
"""
Provides a list of structured in-context examples for few-shot learning.
Each example includes the context, the Chain-of-Thought (CoT) components,
and the final high-level semantic inference.
"""
return [
{
"context": """<Context>:{
Entity:{
Worker_1 a Worker (5,8)
Worker_2 a Worker (8)
ReinforcementRegion_1 a ReinforcementRegion (1,2,4,5)
SteelRod_1 a SteelRod (9)
}
Attribute:{
Worker_1 hasPosture Standing
Worker_2 hasPosture Bending
Worker_1 hasBodyPart Worker_Hand_1
}
Relationship:{
Worker_1 hasAttentionOn ReinforcementRegion_1
Worker_2 isConnectedTo SteelRod_1
Worker_Hand_1 isConnectedTo ReinforcementRegion_1
}
}""",
"inference": """<Inference>:{
the CoT components:{
WorkerBasicInteraction:{
Worker_1 installing ReinforcementRegion_1
Worker_2 assisting Worker_1
}
}
high-level semantics:{
Activity:{
Activity_1:{
Activity type:{
ReinforcementAssembly
}
Activity elements:{
Worker_1, Worker_2, ReinforcementRegion_1, SteelRod_1
}
}
}
}
}"""
},
# Add a second example for better learning
{
"context": """<Context>:{
Entity:{
Excavator_1 a Excavator (4,5,7,8)
Worker_1 a Worker (6)
SoilTrenchRegion_1 a SoilTrenchRegion (7,8)
SoilGroundRegion_1 a SoilGroundRegion (1,2,3)
}
Attribute:{
Excavator_1 hasPart Excavator_Bucket_1
}
Relationship:{
Worker_1 hasAttentionOn Excavator_1
Excavator_Bucket_1 isIn SoilTrenchRegion_1
}
}""",
"inference": """<Inference>:{
the CoT components:{
MachineryInteraction:{
Excavator_1 excavating SoilTrenchRegion_1
}
WorkerBasicInteraction:{
Worker_1 monitoring Excavator_1
}
}
high-level semantics:{
Activity:{
Activity_1:{
Activity type:{
SoilExcavation
}
Activity elements:{
Excavator_1, SoilTrenchRegion_1
}
},
Activity_2:{
Activity type:{
ProcessMonitoring
}
Activity elements:{
Worker_1, Excavator_1
}
}
}
}
}"""
}
]
def construct_full_prompt(self, new_scene_context):
"""
Assembles the complete prompt to be sent to the LLM.
Args:
new_scene_context (str): The ontology-guided representation of the new image.
Returns:
str: The complete, formatted prompt.
"""
print("[Step 3] Constructing the full LLM prompt.")
prompt = self._get_task_formulation_prompt()
prompt += "\n\n--- EXAMPLES ---\n"
for example in self._get_in_context_examples():
prompt += f"\n{example['context']}\n"
prompt += f"{example['inference']}\n"
prompt += "---\n"
prompt += "\n--- NEW SCENE TO ANALYZE ---\n"
prompt += self._get_output_formulation_prompt()
prompt += f"\n\n{new_scene_context}\n"
prompt += "<Inference>:" # This prompts the model to generate the inference part.
return prompt
# --- Step 4: Simulate LLM Inference ---
def _simulate_llm_inference(self, prompt):
"""
Simulates making an API call to a large language model.
In a real application, this would use a library like 'requests' or 'openai'.
Args:
prompt (str): The fully constructed prompt.
Returns:
str: The simulated text response from the LLM.
"""
print("[Step 4] Simulating LLM API call...")
# This is a mock response tailored to the "test_image_formwork.jpg" input.
# It mirrors the inference shown in Figure 7 of the paper.
if "FormworkRegion_1" in prompt and "Hoist_1" in prompt:
# A realistic, structured response from the LLM
mock_response = """{
"the CoT components":{
"WorkerBasicInteraction":{
"Worker_1 monitoring Hoist_1"
},
"MachineryInteraction":{
"Hoist_1 lifting FormworkRegion_1"
}
},
"high-level semantics":{
"Activity":{
"Activity_1":{
"Activity type":{
"FormworkSetUp"
},
"Activity elements":{
"Worker_1", "Hoist_1", "FormworkRegion_1"
}
}
}
}
}"""
return mock_response
return "{\n \"error\": \"Could not determine activity based on context.\" \n}"
# --- Example of a REAL API call (e.g., with OpenAI) ---
#
# import openai
# openai.api_key = "YOUR_API_KEY"
#
# try:
# response = openai.Completion.create(
# engine="text-davinci-003", # Or a different model
# prompt=prompt,
# max_tokens=500,
# temperature=0.5, # As used in the paper
# top_p=0.3 # As used in the paper
# )
# return response.choices[0].text.strip()
# except Exception as e:
# return f"An API error occurred: {e}"
def run_inference_on_image(self, image_path):
"""
Executes the full pipeline for a single image.
Args:
image_path (str): The path to the image to analyze.
"""
# Step 1
visual_info = self._simulate_visual_information_extraction(image_path)
# Step 2
scene_context = self._create_ontology_guided_representation(visual_info)
# Step 3
full_prompt = self.construct_full_prompt(scene_context)
print("\n" + "="*50)
print(" FINAL PROMPT SENT TO LLM (Excerpt)")
print("="*50)
print(full_prompt[-1000:]) # Print the tail of the prompt for brevity
print("="*50 + "\n")
# Step 4
llm_response_str = self._simulate_llm_inference(full_prompt)
# Step 5 - Parse and display the result
print("[Step 5] Parsing and displaying the final inference.")
print("-" * 50)
print(" LLM INFERENCE RESULT")
print("-" * 50)
try:
# Try to pretty-print if it's JSON
parsed_response = json.loads(llm_response_str.replace("'", '"')) # Basic cleanup
print(json.dumps(parsed_response, indent=4))
except json.JSONDecodeError:
# Otherwise, print as raw text
print(llm_response_str)
print("-" * 50)
if __name__ == '__main__':
# Initialize the recognizer model
recognizer = OntologyBasedActivityRecognizer()
# Define a mock image file path to be analyzed.
# The simulation is keyed to this specific filename.
test_image_file = "mock_data/images/test_image_formwork.jpg"
# Run the full inference pipeline
recognizer.run_inference_on_image(test_image_file)
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- DeepSPV: Revolutionizing 3D Spleen Volume Estimation from 2D Ultrasound with AI
- ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection