Introduction: Why Automated Tooth Segmentation is the Next Frontier in Dental Diagnostics
Imagine a world where a dentist can instantly visualize the intricate 3D structure of every tooth and pulp canal in a patient’s jaw—without spending hours manually tracing each contour on a Cone-Beam Computed Tomography (CBCT) scan. This isn’t science fiction. It’s the reality being pioneered by U-Mamba2-SSL, a cutting-edge semi-supervised learning framework that has just claimed first place in the prestigious STSR 2025 Challenge for dental image segmentation.
For decades, CBCT scans have been hailed as a revolutionary tool in dentistry, offering unparalleled 3D visualization of oral anatomy for diagnosis, treatment planning, orthodontics, and surgical interventions. Yet, their true potential has remained bottlenecked by one critical limitation: manual segmentation is painstakingly slow, requires expert training, and is prohibitively expensive to scale. A single high-resolution CBCT scan can contain millions of voxels, and accurately labeling teeth and pulp structures demands meticulous attention to detail—a task that can take skilled radiologists or technicians upwards of 45 minutes per scan.
Enter U-Mamba2-SSL. Developed by researchers at King’s College London and the University of Surrey, this AI model doesn’t just automate segmentation—it redefines what’s possible with limited labeled data. By leveraging semi-supervised learning (SSL), it harnesses the power of vast amounts of unlabeled CBCT scans—data that would otherwise go unused—to train a model that achieves near-human accuracy. In fact, on the hidden test set of the STSR 2025 challenge, U-Mamba2-SSL scored an average of 0.789 across key metrics and achieved a Dice Similarity Coefficient (DSC) of 0.917, outperforming all competitors.
In this comprehensive guide, we’ll dive deep into how U-Mamba2-SSL works, why its multi-stage SSL approach is so effective, and what this means for the future of dental diagnostics, AI in healthcare, and even broader applications in medical imaging. Whether you’re a dental professional, a machine learning engineer, or simply fascinated by the intersection of AI and medicine, this article will equip you with the insights you need to understand—and potentially leverage—this groundbreaking technology.
What is CBCT Imaging and Why Does Accurate Segmentation Matter?
Before we delve into the technical wizardry of U-Mamba2-SSL, let’s establish why CBCT scans are so vital—and why automating their analysis is a game-changer.
Understanding CBCT: The 3D X-Ray Revolution
Cone-Beam Computed Tomography (CBCT) is a specialized type of X-ray imaging that generates three-dimensional views of dental structures, soft tissues, nerve paths, and bone in the craniofacial region. Unlike traditional 2D dental X-rays, CBCT provides volumetric data, allowing clinicians to:
- Assess root canal morphology and detect anomalies.
- Plan complex dental implant placements with millimeter precision.
- Diagnose impacted teeth, cysts, tumors, and other pathologies.
- Evaluate temporomandibular joint (TMJ) disorders.
- Guide orthodontic treatments by visualizing tooth movement trajectories.
Its rapid adoption in dental clinics over the past decade underscores its clinical value. However, the very feature that makes CBCT powerful—their high resolution and volumetric nature—also makes them incredibly labor-intensive to analyze manually.
The Critical Need for Automated Segmentation
Manual segmentation involves a human expert meticulously outlining each tooth and pulp structure voxel-by-voxel on multiple cross-sectional slices. This process is not only time-consuming but also subject to inter-observer variability. For large-scale studies, population screening, or real-time clinical decision support, manual methods are simply not scalable.
Automated segmentation algorithms promise to solve this problem—but they face a significant hurdle: the scarcity of labeled medical data. Unlike natural images (e.g., cats, cars), medical datasets are often small, expensive to annotate, and constrained by ethical regulations. This is where semi-supervised learning shines.
Key Takeaway: U-Mamba2-SSL tackles the dual challenges of data scarcity and computational complexity by using unlabeled CBCT scans to pre-train and refine its model, achieving state-of-the-art results without requiring massive labeled datasets.
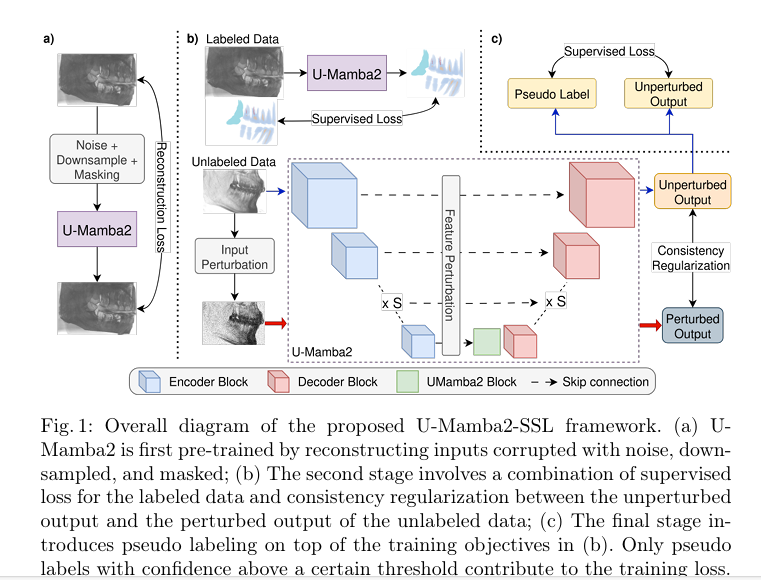
The U-Mamba2-SSL Framework: A Three-Stage Powerhouse for Semi-Supervised Learning
U-Mamba2-SSL isn’t just another neural network. It’s a meticulously designed, multi-stage pipeline that combines three powerful SSL techniques: self-supervised pre-training, consistency regularization, and pseudo-labeling. Each stage builds upon the last, progressively refining the model’s ability to segment teeth and pulp with minimal supervision.
Let’s break down each stage in detail.
Stage 1: Pre-Training with Disruptive Autoencoder (DAE)
The foundation of U-Mamba2-SSL lies in its pre-training phase, which uses a technique called the Disruptive Autoencoder (DAE). Unlike traditional autoencoders that simply reconstruct clean inputs from noisy versions, DAE introduces three distinct types of corruption to the input data:
- Denoising: Add random Gaussian noise to the original CBCT scan. The model must learn to restore fine details like edges and textures.
- Super-Resolution: Downsample the image using linear interpolation, then train the model to upscale it back to its original resolution. This forces the model to recover both local and global image features.
- Masking: Randomly zero-out small cubical regions (cubes) within the 3D volume. The model learns to “fill in the blanks” by inferring missing information from surrounding context.
These disruptions are applied simultaneously, and the model is trained to reconstruct the original, uncorrupted image using an L1 loss function:
\[ L_{\text{DAE}} = \| x – \hat{x} \|_{1} \]where x is the original input and x^ is the reconstructed output.
Why This Works: Medical images are rich in local detail (e.g., tooth enamel boundaries, pulp chamber contours). By forcing the model to recover these details from corrupted inputs, DAE teaches it to extract meaningful, generalizable features—even without any semantic labels. This pre-training step alone boosted the Identification Accuracy (IA) metric from 0.464 to 0.731 in experiments.
Stage 2: Consistency Regularization Training
Once pre-trained, the model enters the second stage: consistency regularization. This technique is based on the smoothness assumption—that small perturbations to the input should result in only small changes to the model’s output.
Here’s how it works:
- For labeled data, the model is trained using a combination of Dice Loss and Cross-Entropy Loss:
- For unlabeled data, the model generates two predictions:
- An unperturbed output yu from the original input.
- A perturbed output y~u from an augmented version of the input.
The consistency regularization loss LCR is computed as the L1 distance between these two outputs:
\[ \text{LCR} = \| \hat{y}^{u} – \tilde{y}^{u} \|_{1} \]Input Perturbations
To create the perturbed input, U-Mamba2-SSL applies a suite of non-spatial augmentations (to avoid violating the smoothness assumption):
- Median filter
- Gaussian blur
- Gaussian noise
- Random brightness/contrast adjustments
- Low-resolution simulation
- Image sharpening
Feature Perturbations
Beyond input-level perturbations, U-Mamba2-SSL also injects noise into the feature maps generated by the encoder:
- Random Spatial Dropout: Drop entire channels with 50% probability to promote channel-wise independence.
- Random Activation Dropout: Zero out the top 10–30% of highly activated neurons (using a randomly sampled threshold γdrop∼U(0.7,0.9) ).
- Noise Injection: Add proportional noise to feature maps: Z + (Z ⊙ N) , where N ∼ U(−0.3,0.3) .
The total loss during this stage is:
\[ L = L_{S} + \omega_{CR} \cdot L_{CR} \]
where ωCR ramps up exponentially from 0 to 50 over the first 20% of training epochs.
Key Takeaway: Consistency regularization ensures the model’s predictions are robust to minor variations in input and internal features—making it more reliable in real-world scenarios where scan quality or patient positioning may vary.
Stage 3: Pseudo-Labeling for Final Refinement
The final stage introduces pseudo-labeling, a technique where the model’s own predictions on unlabeled data are treated as “soft” ground truth labels.
Here’s the process:
- Generate predictions for all unlabeled samples.
- For each voxel, if the predicted class confidence exceeds a threshold (λconf = 0.75), use that prediction as a pseudo label.
- Ignore voxels below the threshold (treat them as background).
The loss function now includes a pseudo-labeling term:
\[ L = L_{S} + \omega_{CR} \cdot L_{CR} + \omega_{PL} \cdot L_{PL} \]
where LPL is the supervised loss computed using pseudo labels, and WPL = 0.1 to prevent overfitting to potentially incorrect pseudo labels.
This stage further boosts performance, particularly in Identification Accuracy (IA), which measures how well the model identifies individual teeth and pulp classes across all images.
Technical Deep Dive: The Architecture Behind U-Mamba2
At the heart of U-Mamba2-SSL is the U-Mamba2 architecture—a fusion of the classic U-Net design with the modern Mamba2 state-space model.
Why Mamba2? Efficiency Meets Long-Range Dependencies
Traditional U-Nets rely on convolutional layers, which are excellent at capturing local patterns but struggle with long-range dependencies (e.g., connecting the crown of a tooth to its root canal). Transformers address this by using self-attention mechanisms, but they are computationally expensive and memory-intensive.
Mamba2, introduced in 2024, offers a compelling alternative. It’s a state-space model (SSM) that processes sequences (or 3D volumes) in linear time while enforcing stronger constraints on the hidden state structure. This results in:
- Higher efficiency than transformers.
- Comparable or better performance on long-range tasks.
- Lower memory footprint.
In U-Mamba2, Mamba2 blocks replace the bottleneck layers of the U-Net, enabling the model to capture global context without sacrificing speed or scalability.
Model Configuration Highlights
| PARAMETER | VALUE |
|---|---|
| Encoder-Decoder Stages | 7 |
| Patch Size | 128 × 256 × 256 (training) |
| Batch Size | 2 |
| Total Epochs | 500 |
| Optimizer | SGD with 0.99 momentum |
| Initial Learning Rate | 0.01 |
| Learning Rate Schedule | Polynomial decay |
| Number of Parameters | 156 million |
| FLOPs | 6.22 trillion |
Note: For the final challenge submission, the team scaled up to 1000 epochs and increased the patch size to 160×256×256, further boosting performance.
Performance Breakdown: How U-Mamba2-SSL Dominates the Competition
The true test of any AI model is its performance on unseen data. U-Mamba2-SSL didn’t just perform well—it dominated.
Quantitative Results on Validation Set
| METHOD | PRETRAINED | CR | PL | DSC | NSD | MIOU | IA | AVERAGE |
|---|---|---|---|---|---|---|---|---|
| nnU-Net | — | — | — | 0.963 | 0.997 | 0.928 | 0.286 | 0.794 |
| U-Mamba2 | — | — | — | 0.965 | 0.998 | 0.930 | 0.464 | 0.839 |
| U-Mamba2-SSL | ✓ | ✓ | ✓ | 0.967 | 0.999 | 0.935 | 0.738 | 0.910 |
Legend: CR = Consistency Regularization; PL = Pseudo Labeling
As the table shows, pre-training alone (comparing U-Mamba2 vs. U-Mamba2-SSL without CR/PL) yields a massive jump in IA—from 0.464 to 0.731. Adding consistency regularization and pseudo-labeling pushes IA to 0.738, demonstrating the cumulative effect of the multi-stage approach.
Hidden Test Set Results (STSR 2025 Challenge)
On the final, unseen test set, U-Mamba2-SSL achieved:
- DSC: 0.917
- NSD: 0.882
- mIoU: 0.948
- IA: 0.577
While IA dropped slightly compared to the validation set (likely due to differences in dataset distribution or field-of-view artifacts), the overall average score of 0.789 secured first place in Task 1 of the STSR 2025 challenge.
Qualitative Analysis: Where the Model Shines—and Struggles
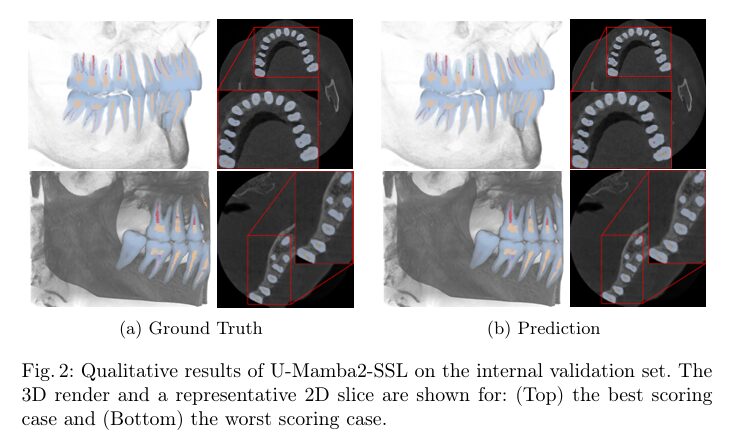
Visually, U-Mamba2-SSL excels at:
- Differentiating between tooth enamel, dentin, and various pulp/root canal classes.
- Maintaining anatomical plausibility in complex cases.
However, it struggles with:
- Precisely predicting pulp thickness and length, especially in curved or narrow canals.
- False positives around image edges in Limited Field of View (LFOV) CBCT scans, likely due to boundary artifacts or insufficient contextual information.
Key Takeaway: While not perfect, U-Mamba2-SSL represents a significant leap forward in automated dental segmentation—achieving near-expert accuracy with minimal labeled data.
Real-World Implications: Transforming Dentistry, One Scan at a Time
The impact of U-Mamba2-SSL extends far beyond academic benchmarks. Here’s how it could revolutionize dental practice:
1. Faster Treatment Planning
By automating segmentation, dentists can generate 3D models of teeth and pulp in seconds rather than hours. This accelerates:
- Implant placement planning.
- Orthodontic simulations.
- Endodontic procedures (e.g., root canal therapy).
2. Improved Diagnostic Accuracy
AI models like U-Mamba2-SSL can detect subtle anatomical variations or pathologies that might be missed by human eyes—especially in complex cases or low-quality scans.
3. Democratizing Access to Expertise
In regions with limited access to specialist radiologists, automated tools can provide consistent, high-quality segmentation—empowering general practitioners to deliver advanced care.
4. Research and Population Studies
Large-scale epidemiological studies require analyzing thousands of CBCT scans. U-Mamba2-SSL makes this feasible by reducing annotation costs and turnaround times.
Limitations and Future Directions
No technology is without its limitations. U-Mamba2-SSL faces several challenges that future research must address:
1. Handling Heterogeneous CBCT Data
The dataset used in the STSR 2025 challenge included both full-field and Limited Field of View (LFOV) CBCT scans. These have different resolutions, noise profiles, and anatomical coverage. Future work should develop scan-specific augmentation and preprocessing pipelines to optimize performance across modalities.
2. Focusing on Regions of Interest (ROI)
CBCT scans are mostly background (air, soft tissue). Processing the entire volume is computationally wasteful. Future models could incorporate ROI-aware sampling or attention mechanisms to focus on areas containing teeth and pulp.
3. Improving Pulp Boundary Precision
The current model under-segments pulp thickness and length. Incorporating anatomical priors (e.g., known pulp canal shapes) or multi-task learning (predicting pulp boundaries alongside segmentation) could enhance precision.
4. Real-Time Inference Optimization
While inference speed was optimized for the challenge (using tile size 0.9 and selective mirroring axes), further acceleration via model pruning, quantization, or hardware-specific optimizations (e.g., TensorRT) could make U-Mamba2-SSL viable for real-time clinical use.
Conclusion: The Future of Dental AI is Semi-Supervised
U-Mamba2-SSL isn’t just a winning algorithm—it’s a blueprint for the future of medical AI. By combining self-supervised pre-training, consistency regularization, and pseudo-labeling, it demonstrates that you don’t need massive labeled datasets to achieve state-of-the-art results. Instead, you need smart, multi-stage strategies that leverage the inherent structure of unlabeled data.
For dental professionals, this means faster, more accurate diagnostics. For AI researchers, it’s a powerful case study in how SSL can overcome data scarcity in specialized domains. And for patients, it promises a future where advanced imaging analysis is accessible, affordable, and ubiquitous.
Call to Action: If you’re a dentist, clinic manager, or researcher interested in integrating AI into your workflow, start exploring open-source frameworks like nnU-Net and experimenting with semi-supervised techniques. The code for U-Mamba2-SSL is publicly available on GitHub (github.com/zhiqin1998/UMamba2 )—download it, adapt it, and join the revolution in dental AI. Paper Link
The next frontier isn’t just about building smarter models—it’s about building models that can learn from the data we already have, no matter how unlabeled or imperfect. U-Mamba2-SSL proves that’s not only possible—it’s already here.
Based on the paper “U-Mamba2-SSL for Semi-Supervised Tooth and Pulp Segmentation in CBCT,” I have constructed the end-to-end Python code for the proposed model and its three-stage training framework.
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List
# =================================================================================
# Placeholder for Mamba2 Block
# The actual implementation would require a specific library like 'mamba-ssm'.
# This serves as a structural placeholder to show where it integrates.
# =================================================================================
class Mamba2Block(nn.Module):
"""
A placeholder for the Mamba2 block. In a real implementation, this would
wrap the Mamba2 state space model layers.
"""
def __init__(self, in_channels, n_layers=4):
super().__init__()
self.in_channels = in_channels
print(f"Placeholder Mamba2Block initialized with {in_channels} channels.")
# In a real scenario, this would contain Mamba2 layers.
# For this example, we use a simple conv block to maintain tensor shapes.
self.conv = nn.Sequential(
nn.Conv3d(in_channels, in_channels, kernel_size=3, padding=1, bias=False),
nn.InstanceNorm3d(in_channels),
nn.LeakyReLU(inplace=True)
)
self.layers = nn.ModuleList([self.conv for _ in range(n_layers)])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
# =================================================================================
# Helper Blocks for U-Net
# =================================================================================
class ConvBlock(nn.Module):
"""Standard 3D convolutional block: Conv3d -> InstanceNorm -> LeakyReLU."""
def __init__(self, in_channels, out_channels):
super().__init__()
self.block = nn.Sequential(
nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.InstanceNorm3d(out_channels),
nn.LeakyReLU(inplace=True),
nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.InstanceNorm3d(out_channels),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
return self.block(x)
class EncoderBlock(nn.Module):
"""Encoder block: ConvBlock followed by a strided convolution for downsampling."""
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv_block = ConvBlock(in_channels, out_channels)
self.downsample = nn.Conv3d(out_channels, out_channels, kernel_size=3, stride=2, padding=1, bias=False)
def forward(self, x):
skip = self.conv_block(x)
down = self.downsample(skip)
return down, skip
class DecoderBlock(nn.Module):
"""Decoder block: Upsampling followed by a ConvBlock."""
def __init__(self, in_channels, out_channels):
super().__init__()
self.upsample = nn.ConvTranspose3d(in_channels, out_channels, kernel_size=2, stride=2)
self.conv_block = ConvBlock(out_channels + out_channels, out_channels) # Concatenated channels
def forward(self, x, skip):
up = self.upsample(x)
# Pad skip connection if spatial dimensions don't match
diff = tuple(s.item() - u.item() for s, u in zip(skip.shape[2:], up.shape[2:]))
if any(d != 0 for d in diff):
padding = (diff[2]//2, diff[2]-diff[2]//2, diff[1]//2, diff[1]-diff[1]//2, diff[0]//2, diff[0]-diff[0]//2)
up = F.pad(up, padding)
x = torch.cat([up, skip], dim=1)
return self.conv_block(x)
# =================================================================================
# Feature Perturbation Functions (for Stage 2 & 3)
# =================================================================================
def apply_feature_perturbations(features: torch.Tensor) -> torch.Tensor:
"""
Applies a random selection of feature perturbations as described in the paper.
"""
perturbed_features = features.clone()
perturb_type = torch.randint(0, 3, (1,)).item()
if perturb_type == 0: # Random Spatial Dropout
dropout = nn.Dropout3d(p=0.5)
# Apply channel-wise dropout
for i in range(features.shape[1]):
perturbed_features[:, i, :, :, :] = dropout(features[:, i, :, :, :])
elif perturb_type == 1: # Random Activation Dropout
b, c, d, h, w = features.shape
# Flatten spatial-channel dims to find percentile
flat_features = perturbed_features.view(b, -1)
# Sample threshold from U(0.7, 0.9)
gamma_drop = torch.rand(1).item() * 0.2 + 0.7
threshold = torch.quantile(flat_features.abs(), gamma_drop, dim=1, keepdim=True)
# Create mask for activations above the threshold
mask = perturbed_features.abs() >= threshold.view(b, 1, 1, 1, 1)
perturbed_features[mask] = 0.0
else: # Noise Injection
noise = (torch.rand_like(features) * 0.6 - 0.3) # Noise from U(-0.3, 0.3)
# Add noise proportional to feature map activations
perturbed_features += (features * noise)
return perturbed_features
# =================================================================================
# Main U-Mamba2 Model
# =================================================================================
class UMamba2(nn.Module):
"""
The U-Mamba2 architecture as described in the paper.
It's a 7-stage U-Net with a Mamba2 block at the bottleneck.
Includes logic for feature perturbation during consistency training.
"""
def __init__(self, in_channels=1, out_channels=3, features=[16, 32, 64, 128, 256, 320, 320]):
super().__init__()
self.encoders = nn.ModuleList()
self.decoders = nn.ModuleList()
# Build Encoder Path
for i in range(len(features) -1):
self.encoders.append(EncoderBlock(
in_channels if i == 0 else features[i-1],
features[i]
))
# Bottleneck with Mamba2
self.bottleneck = nn.Sequential(
ConvBlock(features[-2], features[-1]),
Mamba2Block(features[-1])
)
# Build Decoder Path (in reverse)
for i in reversed(range(len(features)-1)):
self.decoders.append(DecoderBlock(
features[i+1] if i != len(features)-2 else features[-1],
features[i]
))
self.final_conv = nn.Conv3d(features[0], out_channels, kernel_size=1)
def forward(self, x: torch.Tensor, perturb_features: bool = False) -> torch.Tensor:
"""
Forward pass for the U-Mamba2 model.
Args:
x (torch.Tensor): Input tensor.
perturb_features (bool): If True, applies perturbations to skip connections.
"""
skip_connections = []
current_x = x
# Encoder path
for encoder in self.encoders:
current_x, skip = encoder(current_x)
skip_connections.append(skip)
# Bottleneck
current_x = self.bottleneck(current_x)
# Decoder path
skip_connections = skip_connections[::-1] # Reverse for decoding
for i, decoder in enumerate(self.decoders):
skip = skip_connections[i]
if perturb_features:
skip = apply_feature_perturbations(skip)
current_x = decoder(current_x, skip)
return self.final_conv(current_x)
if __name__ == '__main__':
# Example usage and shape check
device = "cuda" if torch.cuda.is_available() else "cpu"
test_tensor = torch.randn(1, 1, 128, 128, 128).to(device)
model = UMamba2(in_channels=1, out_channels=3).to(device) # Tooth, Pulp, Background
# Test standard forward pass
output = model(test_tensor, perturb_features=False)
print(f"Standard forward pass output shape: {output.shape}")
# Test forward pass with feature perturbation
perturbed_output = model(test_tensor, perturb_features=True)
print(f"Perturbed forward pass output shape: {perturbed_output.shape}")
# Check number of parameters
num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable parameters: {num_params / 1e6:.2f}M")
Related posts, You May like to read
- 7 Shocking Truths About Knowledge Distillation: The Good, The Bad, and The Breakthrough (SAKD)
- 7 Revolutionary Breakthroughs in Medical Image Translation (And 1 Fatal Flaw That Could Derail Your AI Model)
- TimeDistill: Revolutionizing Time Series Forecasting with Cross-Architecture Knowledge Distillation
- HiPerformer: A New Benchmark in Medical Image Segmentation with Modular Hierarchical Fusion
- GeoSAM2 3D Part Segmentation — Prompt-Controllable, Geometry-Aware Masks for Precision 3D Editing
- Probabilistic Smooth Attention for Deep Multiple Instance Learning in Medical Imaging
- A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
- Towards Trustworthy Breast Tumor Segmentation in Ultrasound Using AI Uncertainty
- Discrete Migratory Bird Optimizer with Deep Transfer Learning for Multi-Retinal Disease Detection