FedDRLPD: Teaching AI to Defend Itself Against Poisoning Attacks Through Deep Reinforcement Learning
A novel defense framework that integrates Deep Q-Network algorithms with Mahalanobis distance-based maliciousness evaluation to dynamically select benign users, achieving up to 9% accuracy improvement over state-of-the-art approaches in non-IID federated learning environments.
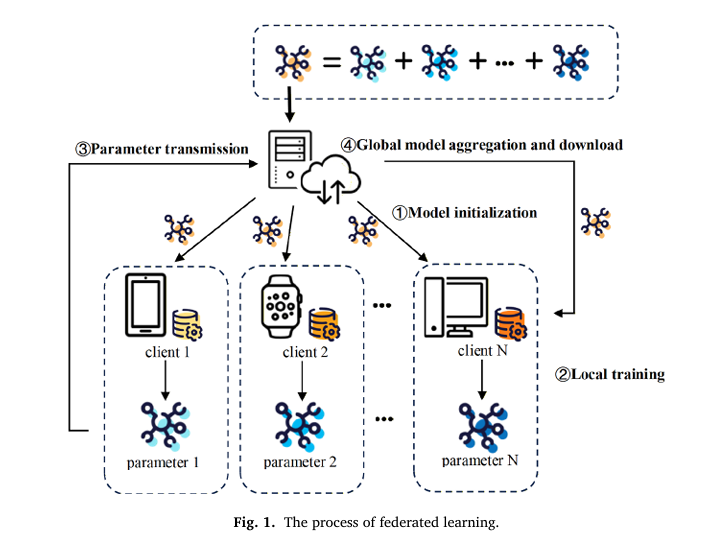
Federated learning promised a revolution in privacy-preserving machine learning by keeping data on local devices. Yet this very architecture created a fatal vulnerability: malicious participants can poison the global model by submitting manipulated updates, and the central server—blind to local data—cannot distinguish legitimate contributions from toxic ones. Existing defenses rely on static thresholds or gradient similarity metrics that collapse under data heterogeneity, misclassifying benign users as attackers and crippling model convergence.
Researchers from Kunming University of Science and Technology and University of Electronic Science and Technology of China have proposed a paradigm shift in how we defend federated learning systems. Their framework, FedDRLPD (Federated Deep Reinforcement Learning Poisoning Defense), treats malicious user detection not as a static classification problem but as a sequential decision-making process that must adapt to evolving adversarial strategies. By integrating Deep Q-Network (DQN) algorithms with a sophisticated Mahalanobis distance-based maliciousness evaluation mechanism, the system learns to dynamically exclude attackers while maintaining robust performance even in highly heterogeneous data environments.
What distinguishes this work is its explicit handling of the adaptability and variability of adversarial behaviors. Unlike existing approaches that apply fixed detection rules, FedDRLPD’s DQN agent continuously refines its user selection policy through environmental feedback, achieving up to 9% accuracy improvement over state-of-the-art methods while maintaining high performance under non-IID conditions. The framework demonstrates that architectural innovation—specifically, the marriage of deep reinforcement learning with statistical anomaly detection—can overcome fundamental limitations of both robust aggregation and reputation-based defenses.
The Poisoning Paradox: Why Privacy Enables Attacks
Federated learning’s core innovation—keeping raw data on local devices while exchanging only model parameters—simultaneously enables privacy preservation and creates an attack surface. In this architecture, the central server aggregates updates from distributed clients without visibility into their training data or local model training processes. This opacity, while protecting user privacy, prevents the server from verifying the legitimacy of submitted updates.
Poisoning attacks exploit this trust model. Malicious clients, controlling their own data and local training, can manipulate model updates through multiple vectors: flipping data labels to corrupt learned representations, injecting additive noise to distort parameter updates, or embedding backdoor triggers that activate only on specific inputs. The attacker’s goal is to degrade global model accuracy, hinder convergence, or implant hidden behaviors that activate under specific conditions.
Existing defense strategies fall into three categories, each with critical limitations:
Robust aggregation-based approaches (Krum, Bulyan, Trimmed Mean) leverage statistical or geometric properties to identify trustworthy updates without assuming specific adversarial behaviors. However, these methods experience significant performance degradation under non-IID data distributions, where benign updates naturally exhibit high variance.
Reputation-based approaches assign contribution weights based on historical behavior, but cannot guarantee complete elimination of malicious influence. A client with fluctuating behavior may maintain sufficient reputation to periodically poison the model.
Similarity-based methods identify outliers using cosine similarity between gradients, but face a critical flaw: under significant data heterogeneity, benign users produce updates that deviate substantially from the majority. Static similarity thresholds inevitably misclassify legitimate participants as malicious, degrading model performance through false positives.
FedDRLPD addresses the fundamental limitation of static defenses by introducing adaptive decision-making. The DQN agent learns to distinguish benign heterogeneity from malicious manipulation through continuous interaction, enabling dynamic policy updates that maintain defense robustness even as adversarial strategies evolve.
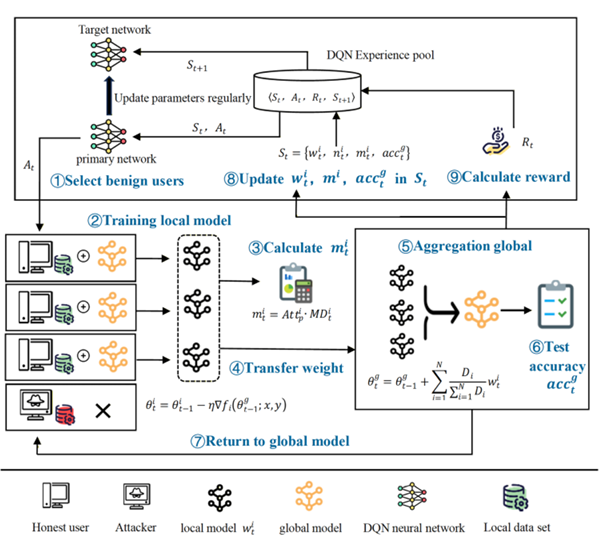
The practical manifestation of this insight is a closed-loop system where a DQN agent perceives global training states—including model performance, user behaviors, and maliciousness indicators—and adaptively determines optimal client participation strategies. This transforms defense from a passive filtering mechanism into an active learning process that improves with experience.
The DQN Architecture: Learning Whom to Trust
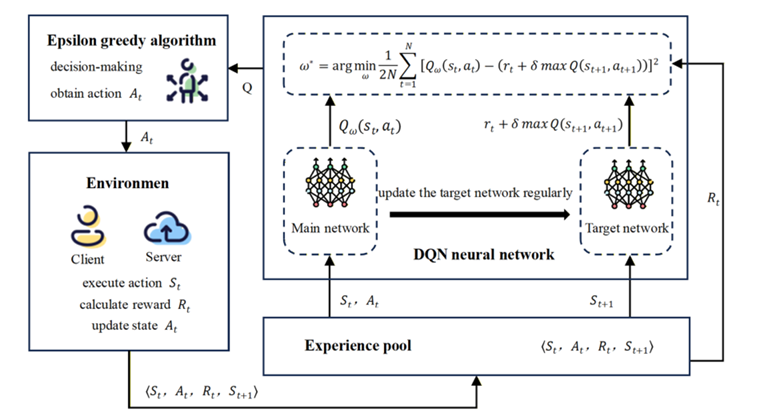
The high-level defense strategy is bootstrapped by framing client selection as a Markov Decision Process (MDP), where the agent must learn optimal actions through trial and error. Unlike conventional DQN applications that select single actions, FedDRLPD adapts the epsilon-greedy strategy to select multiple users per round: the agent inputs states of all users to the main network, obtains Q-values for each potential selection, and chooses the top-P actions representing the most trustworthy participants.
The state representation is carefully engineered to capture the multi-dimensional nature of trustworthiness in federated learning:
Local model weights (\(w_t^i\)): Captured via PCA dimensionality reduction to avoid the curse of dimensionality, these represent each user’s current model update and indirectly reflect their data distribution.
Sample counts (\(n_t^i\)): The number of training samples per user serves as a crucial indicator for distinguishing benign heterogeneity from malicious behavior. Users with small datasets may naturally produce biased updates, while users with large datasets exhibiting extreme deviations are more likely malicious.
Malicious scores (\(m_t^i\)): A time-dependent cumulative metric that captures temporal attack dynamics. Even if an attacker behaves normally in a single round, continuous abnormal updates cause this score to increase, leaving a long-term trace that enables the DQN to recognize persistent threats.
Global accuracy (\(acc_t^g\)): The current performance of the global model provides immediate feedback on the quality of recent aggregation decisions.
“Unlike existing defenses, FedDRLPD leverages the decision-making capability of Deep Q-Network algorithm to dynamically exclude malicious users based on observed user behaviors and system status, thereby improving resilience against poisoning attacks.” — Xu et al., Knowledge-Based Systems 2026
The action space consists of selecting P users from N total participants for each training round. The reward function is meticulously designed to balance multiple objectives:
Where \(U(\cdot)\) measures the local model’s positive contribution based on parameter divergence and accuracy improvement, \(M(\cdot)\) penalizes malicious behavior, and \(\alpha, \beta, \lambda\) are weighting coefficients (set to 0.2, 0.5, and 0.3 respectively) that emphasize timely responsiveness and positive reinforcement. The utility function explicitly rewards accuracy improvements while penalizing excessive deviation from the global model, enabling the agent to handle both non-IID data and poisoning scenarios.
Mahalanobis Distance: Accounting for Data Distribution
While the DQN provides the learning framework, the maliciousness evaluation mechanism provides the critical signal for distinguishing attackers from benign users. The key innovation is using Mahalanobis distance rather than Euclidean distance to measure deviation, thereby accounting for the underlying data distribution rather than just point-to-point distance.
The distinction is crucial: Euclidean distance may misidentify point B as an outlier due to its larger distance from C, while failing to distinguish equidistant points A and B. Mahalanobis distance correctly flags A as an outlier because it accounts for the covariance structure of the data—point B aligns with the distribution’s principal axes despite its distance, while A deviates perpendicularly from the expected pattern.
The Mahalanobis distance is computed as:
Where \(\mu\) is the mean vector of all users’ local model weights and \(Cov\) is the covariance matrix. This formulation remains invariant to scale and rotation, keeping the distance measure stable even as client weights deviate from the global mean under non-IID conditions.
However, Mahalanobis distance alone cannot distinguish occasional poor performance from systematic attacks. To address this, FedDRLPD introduces an attacker probability coefficient that tracks historical malicious behavior:
Where \(P_j(u_i)\) indicates whether user \(i\) was judged as a potential attacker at round \(j\). This cumulative metric transforms instant judgments into frequency-based historical assessments. For benign clients with occasional deviations, \(Att_p^i\) remains close to 1. For malicious clients showing persistently high Mahalanobis distances, the coefficient grows and exponentially amplifies their maliciousness score \(m_t^i = Att_p^i \cdot MD_t^i\).
The combination of Mahalanobis distance and attacker probability creates a temporally-aware anomaly detector that distinguishes transient non-IID effects from persistent adversarial behavior. This enables the DQN to maintain low false positive rates even when benign users exhibit significant model deviations.
Closed-Loop Defense: How Perception Shapes Action
The two components—DQN-based user selection and Mahalanobis-based maliciousness evaluation—form a synergistic closed-loop system. Forward communication flows from the DQN’s user selection decisions to the federated training process. The feedback loop consists of execution outcomes: global model accuracy improvements and computed malicious scores inform the DQN’s state updates and reward calculations.
This coupling creates virtuous cycles. As the DQN learns to select more trustworthy users, the global model receives higher-quality updates, improving accuracy and providing stronger positive rewards that reinforce good selection policies. Simultaneously, more reliable aggregation produces cleaner covariance estimates for Mahalanobis distance calculations, improving malicious user detection precision.
The co-evolution is implemented through experience replay: interaction tuples \(\langle S_t, A_t, R_t, S_{t+1} \rangle\) are stored in a replay buffer, and the DQN updates its policy by sampling from this buffer. The target network is synchronized with the main network at regular intervals to stabilize learning, following standard DQN practice.
The practical efficiency is notable. Unlike reputation-based methods that require extensive historical records, FedDRLPD begins learning immediately and adapts to new attack patterns through environmental interaction. The Mahalanobis distance computation adds minimal overhead compared to gradient similarity calculations, while the DQN’s inference cost is amortized across training rounds.
Experimental Validation: Resilience Across Attack Scenarios
The primary evaluation covers three poisoning attack types—label flipping, additive noise, and backdoor attacks—across three datasets: CIFAR-10, CIFAR-100, and Fashion-MNIST. Each scenario tests different adversarial capabilities: label flipping corrupts training data semantics, additive noise distorts parameter magnitudes, and backdoor attacks implant hidden triggers.
Performance Under Variable Attack Rates
FedDRLPD maintains remarkable stability even as the proportion of malicious users increases. At 30% attack rates, the system achieves 77.24% accuracy on CIFAR-10 under label flipping, 74.18% under additive noise, and 75.15% under backdoor attacks. On Fashion-MNIST, accuracy remains above 84% across all attack types, with minimal degradation compared to attack-free scenarios.
The most challenging dataset, CIFAR-100, shows the framework’s robustness in complex classification tasks. Even with 30% malicious participants, FedDRLPD achieves 53.18% accuracy under label flipping and 47.41% under additive noise—substantially outperforming baseline approaches that often collapse below 40% under such conditions.
Comparison with State-of-the-Art
Compared to the strongest baseline (Abbas et al.’s robust privacy-preserving approach), FedDRLPD demonstrates consistent improvements:
| Attack Type | Dataset | FedDRLPD (%) | Abbas et al. (%) | Gain (%) |
|---|---|---|---|---|
| Label Flipping | CIFAR-10 | 75.93 | 67.04 | +8.89 |
| CIFAR-100 | 53.72 | 46.40 | +7.32 | |
| Fashion-MNIST | 90.53 | 91.27 | -0.74 | |
| Backdoor Attack | CIFAR-10 | 75.88 | 66.96 | +8.92 |
| CIFAR-100 | 49.71 | 42.64 | +7.07 | |
| Fashion-MNIST | 86.27 | 85.07 | +1.20 | |
| Additive Attack | CIFAR-10 | 74.14 | 66.55 | +7.59 |
| CIFAR-100 | 47.47 | 40.76 | +6.71 | |
| Fashion-MNIST | 90.92 | 86.58 | +4.34 |
Table 1: Final accuracy comparison between FedDRLPD and the strongest baseline (Abbas et al.) across three datasets and attack types. FedDRLPD achieves substantial gains on complex datasets (CIFAR-10/100) with only minor trade-offs on simpler tasks.
Detection Accuracy: True and False Positive Rates
Beyond model accuracy, FedDRLPD demonstrates superior malicious user identification capability. The True Positive Rate (TPR)—correctly identifying malicious users—reaches 97.1% on CIFAR-10, 94.4% on CIFAR-100, and 98.8% on Fashion-MNIST. More critically, the False Positive Rate (FPR)—incorrectly flagging benign users as malicious—is suppressed to approximately 3%, compared to 4.7% for the baseline method.
This low FPR is crucial for federated learning practicality: high false positive rates exclude legitimate participants, reducing the diversity of training data and potentially biasing the global model. By maintaining FPR below 3.1% across all datasets, FedDRLPD preserves the collaborative benefits of federated learning while filtering toxic contributions.
Ablation Studies: Isolating Component Contributions
Systematic ablations quantify the contribution of each architectural decision. Replacing Mahalanobis distance with Euclidean distance (DQN with ED) causes significant performance degradation, particularly at 30% attack rates where accuracy drops and convergence becomes unstable. This confirms that accounting for data distribution structure is essential for non-IID robustness.
Removing the DQN module entirely and using random user selection results in severe performance collapse, demonstrating that adaptive learning is necessary for effective defense. The hierarchical combination of DQN-based selection with Mahalanobis-based evaluation achieves the highest accuracy and most stable convergence across all attack types.
Ablating the attacker probability coefficient—using only instantaneous Mahalanobis distance without historical accumulation—reduces detection accuracy for sophisticated attackers who alternate between benign and malicious behavior. The cumulative metric is essential for catching “stealth” adversaries who attempt to evade detection by occasionally submitting legitimate updates.
Comparative Advantages: Why FedDRLPD Differs from Prior Art
FedDRLPD represents a distinct evolution from existing defense paradigms:
vs. Robust Aggregation: Methods like Krum and Bulyan rely on geometric properties that assume specific attack models and fail under non-IID conditions. FedDRLPD’s learning-based approach adapts to data heterogeneity by learning what “normal” deviation looks like for each user, rather than applying universal thresholds.
vs. Reputation-Based Defenses: While reputation mechanisms track historical behavior, they typically use fixed update rules that cannot adapt to evolving attack patterns. FedDRLPD’s DQN continuously refines its selection policy through environmental feedback, enabling response to novel adversarial strategies.
vs. Similarity-Based Methods: Cosine similarity approaches struggle with the fundamental ambiguity of non-IID data—benign users naturally produce divergent updates. FedDRLPD resolves this ambiguity through temporal integration (the attacker probability coefficient) and distributional awareness (Mahalanobis distance).
vs. Static DRL Applications: Prior work applying DRL to federated learning focused on resource allocation and communication efficiency rather than security. FedDRLPD is among the first to apply deep reinforcement learning specifically to poisoning defense, demonstrating that the sequential decision-making framework naturally matches the temporal structure of attack-defense interactions.
Implications and Future Directions
FedDRLPD’s architectural principles suggest broader implications for secure distributed learning:
Adaptive Security: The framework demonstrates that defense mechanisms must be as dynamic as the attacks they oppose. Static thresholds and fixed similarity metrics are inherently limited against adversaries who can optimize their strategies to evade detection. Learning-based approaches that adapt through interaction provide more robust long-term security.
Heterogeneity as Feature, Not Bug: Rather than treating non-IID data as a nuisance to be eliminated, FedDRLPD leverages the structure of heterogeneous updates to improve detection. The Mahalanobis distance explicitly models the covariance of benign updates, using heterogeneity patterns to better identify true outliers.
Minimal Overhead: The defense adds minimal computational cost—PCA dimensionality reduction is applied once per round, Mahalanobis distance computation is \(O(d^2)\) for model dimension \(d\), and DQN inference is amortized across users. This efficiency makes the approach practical for real-world deployment.
Several directions for future work emerge:
- Server-Side Attacks: Extending the framework to address attacks targeting the aggregation process itself, not just client updates.
- Privacy Integration: Combining FedDRLPD with homomorphic encryption or secure multi-party computation to protect the defense mechanism itself from inference attacks.
- Multi-Task Generalization: Enabling the DQN to transfer learned defense policies across different federated learning tasks without retraining.
- Theoretical Guarantees: Formal analysis of convergence properties and bounds on attack success probability under the FedDRLPD defense.
What This Work Actually Means
The central achievement of FedDRLPD is not merely an incremental improvement in detection accuracy, but a conceptual reorientation of how we defend federated learning systems. By recognizing that malicious user detection is fundamentally a sequential decision problem under uncertainty, the framework applies deep reinforcement learning to adaptively optimize defense strategies.
The Mahalanobis distance-based maliciousness evaluation demonstrates that statistical sophistication matters: simple distance metrics fail under non-IID conditions because they ignore data distribution structure. By incorporating covariance information and temporal accumulation, the system achieves low false positive rates even when benign users exhibit substantial model deviation.
The multi-metric reward function shows that defense objectives must be carefully balanced. Maximizing accuracy alone might lead to excessive conservatism (excluding too many users), while minimizing malicious influence alone might sacrifice model performance. The weighted combination of historical rewards, utility contributions, and maliciousness penalties guides the DQN toward optimal trade-offs.
Perhaps most significantly, the experimental validation demonstrates that architectural innovation can overcome fundamental limitations of existing approaches. The 9% accuracy improvement on CIFAR-10 and 7% improvement on CIFAR-100 represent not just better numbers, but proof that adaptive learning can succeed where static methods fail.
For practitioners, FedDRLPD provides a deployable framework for securing federated learning systems against poisoning attacks. The DQN-based selector integrates naturally with existing aggregation protocols, while the Mahalanobis distance computation requires only standard linear algebra operations. The low false positive rate ensures that legitimate participants are not unnecessarily excluded, preserving the collaborative benefits that motivate federated learning in the first place.
As federated learning expands into critical domains—healthcare, finance, autonomous systems—the need for robust defenses becomes paramount. FedDRLPD suggests that the solution lies not in more complex cryptography or heavier computation, but in smarter algorithms that learn to distinguish friend from foe through continuous interaction. In the arms race between attacks and defenses, adaptability is the ultimate weapon.
The poison, it turns out, can be filtered—but only by a defense that learns as fast as the attack evolves.
Conceptual Framework Implementation (Python)
The implementation below illustrates the core mechanisms of FedDRLPD: the DQN-based user selection, Mahalanobis distance calculation with attacker probability tracking, and the closed-loop defense system. This educational code demonstrates the key architectural concepts described in the paper.
# ─────────────────────────────────────────────────────────────────────────────
# FedDRLPD: Deep Reinforcement Learning-Based Defense Against Poisoning Attacks
# Xu, Feng, Liu et al. · Knowledge-Based Systems 2026
# Conceptual implementation of DQN selection and Mahalanobis evaluation
# ─────────────────────────────────────────────────────────────────────────────
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import List, Tuple, Dict, Optional
from dataclasses import dataclass
from collections import deque
from sklearn.decomposition import PCA
# ─── Section 1: Maliciousness Evaluation with Mahalanobis Distance ───────────
class MaliciousnessEvaluator:
"""
Computes comprehensive malicious scores using Mahalanobis distance
and attacker probability coefficients. Handles non-IID data through
distributional awareness rather than simple distance thresholds.
"""
def __init__(self, n_users: int, pca_components: int = 50):
self.n_users = n_users
self.pca = PCA(n_components=pca_components)
self.attack_history = np.zeros(n_users) # Track P_j(u_i)
self.current_round = 0
def compute_mahalanobis_distance(self,
weights: np.ndarray) -> np.ndarray:
"""
Compute MD_t^i for all users.
Args:
weights: Array of shape (n_users, n_features) containing
local model weight updates
Returns:
md_scores: Array of shape (n_users,) with Mahalanobis distances
"""
# Apply PCA to reduce dimensionality and avoid curse of dimensionality
w_reduced = self.pca.fit_transform(weights)
# Compute mean and covariance
mu = np.mean(w_reduced, axis=0)
cov = np.cov(w_reduced, rowvar=False)
# Add small regularization to ensure invertibility
cov += np.eye(cov.shape[0]) * 1e-6
cov_inv = np.linalg.inv(cov)
# Compute Mahalanobis distance for each user
md_scores = np.zeros(self.n_users)
for i in range(self.n_users):
diff = w_reduced[i] - mu
md_scores[i] = np.sqrt(diff.T @ cov_inv @ diff)
return md_scores
def update_attack_history(self,
selected_users: List[int],
all_users: List[int]) -> None:
"""
Update P_j(u_i) tracking which users were flagged as potential attackers.
In practice, this would use the DQN's selection decisions. Here we
simulate based on whether users were excluded from selection.
"""
for user_id in all_users:
if user_id not in selected_users:
self.attack_history[user_id] += 1
self.current_round += 1
def compute_attacker_probability(self) -> np.ndarray:
"""
Compute Att_p^i = 1 + (1/t) * sum(P_j(u_i))
Returns:
att_prob: Array of attacker probability coefficients
"""
if self.current_round == 0:
return np.ones(self.n_users)
att_prob = 1 + (self.attack_history / self.current_round)
return att_prob
def compute_malicious_scores(self,
weights: np.ndarray) -> np.ndarray:
"""
Compute comprehensive malicious scores m_t^i = Att_p^i * MD_t^i
Args:
weights: Local model weight updates
Returns:
scores: Final maliciousness scores for all users
"""
md_scores = self.compute_mahalanobis_distance(weights)
att_prob = self.compute_attacker_probability()
scores = att_prob * md_scores
return scores
# ─── Section 2: DQN Architecture for User Selection ──────────────────────────
class DQNNetwork(nn.Module):
"""
Deep Q-Network for federated learning client selection.
Estimates Q-values for selecting each user given current state.
"""
def __init__(self, state_dim: int, n_users: int, hidden_dim: int = 256):
super(DQNNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, n_users) # Q-value per user
def forward(self, state: torch.Tensor) -> torch.Tensor:
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
q_values = self.fc3(x)
return q_values
class ExperienceReplayBuffer:
">Store and sample experience tuples (S_t, A_t, R_t, S_{t+1})"""
def __init__(self, capacity: int = 10000):
self.buffer = deque(maxlen=capacity)
def push(self,
state: np.ndarray,
action: List[int],
reward: float,
next_state: np.ndarray) -> None:
"""Store transition in buffer"""
self.buffer.append((state, action, reward, next_state))
def sample(self, batch_size: int) -> Tuple:
"""Sample random batch for training"""
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
batch = [self.buffer[i] for i in indices]
return zip(*batch)
def __len__(self) -> int:
return len(self.buffer)
class DQNAgent:
"""
DQN agent for adaptive client selection in federated learning.
Implements epsilon-greedy policy with top-P user selection.
"""
def __init__(self,
n_users: int,
state_dim: int,
selection_ratio: float = 0.3,
gamma: float = 0.99,
epsilon: float = 1.0,
epsilon_min: float = 0.01,
epsilon_decay: float = 0.995,
lr: float = 1e-4):
self.n_users = n_users
self.state_dim = state_dim
self.P = int(n_users * selection_ratio) # Number of users to select
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_decay
# Q-networks
self.policy_net = DQNNetwork(state_dim, n_users)
self.target_net = DQNNetwork(state_dim, n_users)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=lr)
self.replay_buffer = ExperienceReplayBuffer()
def select_action(self, state: np.ndarray) -> List[int]:
"""
Select P users using epsilon-greedy policy.
Args:
state: Current state vector (weights, sample_counts,
malicious_scores, accuracy)
Returns:
selected_users: List of user indices to participate in aggregation
"""
if np.random.random() < self.epsilon:
# Exploration: random selection
selected = np.random.choice(self.n_users, self.P, replace=False)
return selected.tolist()
# Exploitation: select top-P by Q-value
with torch.no_grad():
state_tensor = torch.FloatTensor(state).unsqueeze(0)
q_values = self.policy_net(state_tensor).squeeze()
# Select top P users with highest Q-values
_, top_indices = torch.topk(q_values, self.P)
return top_indices.tolist()
def compute_reward(self,
prev_accuracy: float,
current_accuracy: float,
malicious_scores: np.ndarray,
weights: np.ndarray,
global_weights: np.ndarray,
alpha: float = 0.2,
beta: float = 0.5,
lam: float = 0.3) -> float:
"""
Compute multi-metric reward function.
r_t = alpha * r_{t-1} + beta * U(w_t^i, w_t^g, acc_t^g) - lambda * M(m_t^i)
"""
# Utility function based on accuracy improvement and weight divergence
if current_accuracy > prev_accuracy:
# Reward accuracy improvement
acc_component = current_accuracy
# Penalize large deviations from global model
divergence = np.mean(np.abs(weights - global_weights) / (np.abs(global_weights) + 1e-8))
utility = np.exp(-divergence) + acc_component
else:
# Accuracy decreased - penalize
divergence = np.mean(np.abs(weights - global_weights) / (np.abs(global_weights) + 1e-8))
utility = -np.exp(-divergence)
# Maliciousness penalty
mal_penalty = 1 - np.exp(-np.mean(malicious_scores))
# Combine components (simplified - would include historical reward in full implementation)
reward = beta * utility - lam * mal_penalty
return reward
def update(self, batch_size: int = 32) -> Optional[float]:
"""
Update policy network using experience replay.
"""
if len(self.replay_buffer) < batch_size:
return None
# Sample batch
states, actions, rewards, next_states = self.replay_buffer.sample(batch_size)
# Convert to tensors
states = torch.FloatTensor(np.array(states))
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(np.array(next_states))
# Compute current Q-values
current_q = self.policy_net(states)
# Compute target Q-values using target network
with torch.no_grad():
next_q = self.target_net(next_states)
max_next_q = next_q.max(dim=1)[0]
target_q = rewards + self.gamma * max_next_q
# Compute loss (simplified - full implementation would index by action)
loss = F.mse_loss(current_q.mean(dim=1), target_q)
# Optimize
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Decay epsilon
self.epsilon = max(self.epsilon_min, self.epsilon * self.epsilon_decay)
return loss.item()
def update_target_network(self) -> None:
">Synchronize target network with policy network"""
self.target_net.load_state_dict(self.policy_net.state_dict())
# ─── Section 3: FedDRLPD Integration ─────────────────────────────────────────
class FedDRLPD:
"""
Complete FedDRLPD defense system integrating DQN-based user selection
with Mahalanobis distance-based maliciousness evaluation.
"""
def __init__(self,
n_users: int = 100,
n_malicious: int = 20,
state_dim: int = 200,
target_update_freq: int = 10):
self.n_users = n_users
self.n_malicious = n_malicious
self.target_update_freq = target_update_freq
self.current_round = 0
# Initialize components
self.dqn_agent = DQNAgent(n_users=n_users, state_dim=state_dim)
self.maliciousness_eval = MaliciousnessEvaluator(n_users=n_users)
# State tracking
self.prev_accuracy = 0.0
self.global_weights = None
def construct_state(self,
local_weights: np.ndarray,
sample_counts: np.ndarray,
malicious_scores: np.ndarray,
global_accuracy: float) -> np.ndarray:
"""
Construct state vector S_t = {w_t^i, n_t^i, m_t^i, acc_t^g}
Returns concatenated state vector for DQN input.
"""
# Flatten and concatenate all state components
# In practice, PCA is applied to weights first
state = np.concatenate([
local_weights.flatten(),
sample_counts,
malicious_scores,
[global_accuracy]
])
return state
def defense_round(self,
local_weights: np.ndarray,
sample_counts: np.ndarray,
global_accuracy: float) -> List[int]:
"""
Execute one round of FedDRLPD defense.
Args:
local_weights: Array of shape (n_users, n_features) with model updates
sample_counts: Array of shape (n_users,) with sample counts per user
global_accuracy: Current global model accuracy
Returns:
selected_users: Indices of users selected for aggregation
"""
self.current_round += 1
# Step 1: Compute malicious scores using Mahalanobis distance
malicious_scores = self.maliciousness_eval.compute_malicious_scores(local_weights)
# Step 2: Construct state for DQN
state = self.construct_state(local_weights, sample_counts,
malicious_scores, global_accuracy)
# Step 3: DQN selects users
selected_users = self.dqn_agent.select_action(state)
# Step 4: Update attack history based on selection
all_users = list(range(self.n_users))
self.maliciousness_eval.update_attack_history(selected_users, all_users)
# Step 5: Compute reward and store experience
if self.global_weights is not None:
reward = self.dqn_agent.compute_reward(
self.prev_accuracy,
global_accuracy,
malicious_scores[selected_users],
local_weights[selected_users],
self.global_weights
)
# Construct next state (simplified - would use actual next state)
next_state = state
self.dqn_agent.replay_buffer.push(state, selected_users, reward, next_state)
# Step 6: Update DQN
loss = self.dqn_agent.update()
# Step 7: Update target network periodically
if self.current_round % self.target_update_freq == 0:
self.dqn_agent.update_target_network()
# Update tracking variables
self.prev_accuracy = global_accuracy
self.global_weights = np.mean(local_weights[selected_users], axis=0)
return selected_users
def evaluate_defense(self,
true_malicious: List[int],
selected_users: List[int]) -> Dict[str, float]:
"""
Evaluate defense performance using TPR and FPR.
"""
selected_set = set(selected_users)
malicious_set = set(true_malicious)
benign_set = set(range(self.n_users)) - malicious_set
# True Positives: malicious users correctly excluded
excluded = set(range(self.n_users)) - selected_set
tp = len(excluded & malicious_set)
# False Positives: benign users incorrectly excluded
fp = len(excluded & benign_set)
# Calculate rates
tpr = tp / len(malicious_set) if malicious_set else 0.0
fpr = fp / len(benign_set) if benign_set else 0.0
return {"TPR": tpr, "FPR": fpr}
# ─── Section 4: Demonstration ────────────────────────────────────────────────
if __name__ == "__main__":
"""
Demonstration of FedDRLPD defense framework.
Shows initialization, defense rounds, and evaluation.
"""
print("=" * 70)
print("FedDRLPD: Deep Reinforcement Learning Poisoning Defense")
print("Knowledge-Based Systems 2026 - Xu, Feng, Liu et al.")
print("=" * 70)
# Configuration
N_USERS = 100
N_MALICIOUS = 20
N_ROUNDS = 50
# Initialize defense system
print("\n[1] Initializing FedDRLPD defense system...")
defense = FedDRLPD(n_users=N_USERS, n_malicious=N_MALICIOUS)
# Simulate malicious users
malicious_users = list(range(N_MALICIOUS)) # First 20 users are malicious
print(f" Configured with {N_USERS} total users, {N_MALICIOUS} malicious")
# Simulate federated learning rounds
print("\n[2] Running defense simulation...")
for round_idx in range(N_ROUNDS):
# Generate synthetic local weights (normally distributed)
local_weights = np.random.randn(N_USERS, 100)
# Make malicious weights more divergent
for m_id in malicious_users:
local_weights[m_id] += np.random.randn(100) * 3.0 # Larger variance
sample_counts = np.random.randint(200, 800, size=N_USERS)
global_acc = 0.5 + (round_idx / N_ROUNDS) * 0.3 # Improving accuracy
# Execute defense round
selected = defense.defense_round(local_weights, sample_counts, global_acc)
if round_idx % 10 == 0:
metrics = defense.evaluate_defense(malicious_users, selected)
print(f" Round {round_idx}: Selected {len(selected)} users, "
f"TPR={metrics['TPR']:.3f}, FPR={metrics['FPR']:.3f}")
# Final evaluation
print("\n[3] Final Defense Metrics:")
final_metrics = defense.evaluate_defense(malicious_users, selected)
print(f" True Positive Rate: {final_metrics['TPR']:.3f}")
print(f" False Positive Rate: {final_metrics['FPR']:.3f}")
print("\n[4] FedDRLPD Architecture Summary:")
print(" High-Level Defense (DQN Agent):")
print(" - Model: Deep Q-Network with experience replay")
print(" - Action: Select P trustworthy users per round")
print(" - State: {w_t^i, n_t^i, m_t^i, acc_t^g}")
print(" - Reward: Multi-metric (accuracy, divergence, maliciousness)")
print(" Low-Level Evaluation (Mahalanobis):")
print(" - Distance: MD_t^i = sqrt((w-μ)^T Cov^{-1} (w-μ))")
print(" - Temporal: Att_p^i = 1 + (1/t) * sum(P_j(u_i))")
print(" - Score: m_t^i = Att_p^i * MD_t^i")
print(" Integration: Closed-loop co-evolution via experience replay")
print("\n" + "=" * 70)
print("FedDRLPD enables adaptive defense against poisoning attacks")
print("through deep reinforcement learning and distributional anomaly detection.")
print("=" * 70)
Access the Paper and Resources
The full FedDRLPD framework details and experimental protocols are available in Knowledge-Based Systems 2026. Implementation resources and extended evaluations will be made available by the authors.
Xu, N., Feng, Y., Liu, N., Liu, M., Li, Y., & Fu, X. (2026). FedDRLPD: Deep reinforcement Learning-Based defense mechanism against poisoning attacks in federated learning. Knowledge-Based Systems, 339, 115558. https://doi.org/10.1016/j.knosys.2026.115558
This article is an independent editorial analysis of peer-reviewed research published in Knowledge-Based Systems. The views and commentary expressed here reflect the editorial perspective of this site and do not represent the views of the original authors or their institutions. Code implementations are provided for educational purposes to illustrate the technical concepts described in the paper. Always refer to the original publication for authoritative details and official implementations.
Explore More on AI Security Research
If this analysis sparked your interest, here is more of what we cover across the site — from foundational tutorials to the latest research breakthroughs in secure machine learning, adversarial robustness, and trustworthy AI.