MEWS: The Segmentation Framework That Beats CLIP With Just a Few Pixel Clicks Per Class
Researchers at Aristotle University of Thessaloniki built a segmentation system that achieves 63.27% mIoU on Cityscapes — virtually matching fully supervised methods — using only sparse pixel annotations on a handful of training images. No dense masks. No text prompts. Just a few carefully chosen pixels per class.
Here’s a number that should make you pause: 63.27% mIoU on Cityscapes, achieved with just 16 annotated pixels per class across 16 training images out of the entire dataset. For comparison, CLIP-based zero-shot segmentation — which requires no annotation at all but uses massive text-image pretraining — tops out around 42% on the same benchmark. The gap between “no supervision” and “full supervision” has always been the central problem of semantic segmentation. MEWS doesn’t solve it so much as reveal that the gap was never as large as the annotation cost made it seem.
The Annotation Trap — and Why Existing Fixes Don’t Fully Work
Pixel-level image annotation is brutal. A single Cityscapes image — a complex urban street scene — takes a trained annotator roughly an hour and a half to label completely. Scale that to a dataset of thousands of images across dozens of semantic classes, factor in the inevitable inter-annotator disagreements, and you understand why the field has been searching for better options for years.
The mainstream responses to this problem fall into three broad categories, each with its own failure mode. Unsupervised segmentation methods like STEGO leverage self-supervised Vision Transformer features to discover natural clusters in the feature space without any labels. They work remarkably well on dominant visual elements but systematically fail on small, rare, or visually non-distinctive classes — exactly the classes that matter most in applications like autonomous driving (pedestrians, traffic lights, cyclists) and disaster management (fire regions, smoke plumes).
Text-prompted segmentation using CLIP and its variants addresses the “what to segment” problem elegantly — just describe the object in words. But it introduces a subtler failure mode: semantic ambiguity. Whether you type “a person walking” or “pedestrian” or “human figure” can meaningfully change the output. The model has no stable grounding in the actual pixel statistics of your target domain, which makes it brittle in any application where consistency matters. And training a CLIP-based pipeline is computationally expensive; the models are enormous.
Few-shot segmentation approaches like SegGPT require full segmentation masks for their support examples, not just sparse points — so “few-shot” still means a meaningful annotation burden. They also tend to use much larger backbone architectures (ViT-Large versus MEWS’s ViT-Base), and their retraining costs for new classes are prohibitive at scale.
MEWS threads a needle between these approaches. It builds on the Extreme Weakly Supervised (EWS) paradigm — which previously showed that a single pixel label per binary class can outperform fully unsupervised methods — and extends it to the full multiclass setting. The insight is elegant: if a pretrained Vision Transformer already knows that pixels in similar semantic regions produce similar feature vectors, then a small number of labeled pixels can anchor those clusters to specific class identities, eliminating the need for either dense annotation or ambiguous text prompts.
A DINOv3 Vision Transformer already produces semantically rich features that cluster naturally by image region type. MEWS’s job is not to teach the model to see — it already sees. The job is to give each natural feature cluster a name. A handful of labeled pixels per class is enough to do that anchoring, because each pixel maps to a patch-level feature vector that is already representative of its semantic class.
How MEWS Works: Architecture and Loss Functions
Step 1: Building Class Prototypes From Almost Nothing
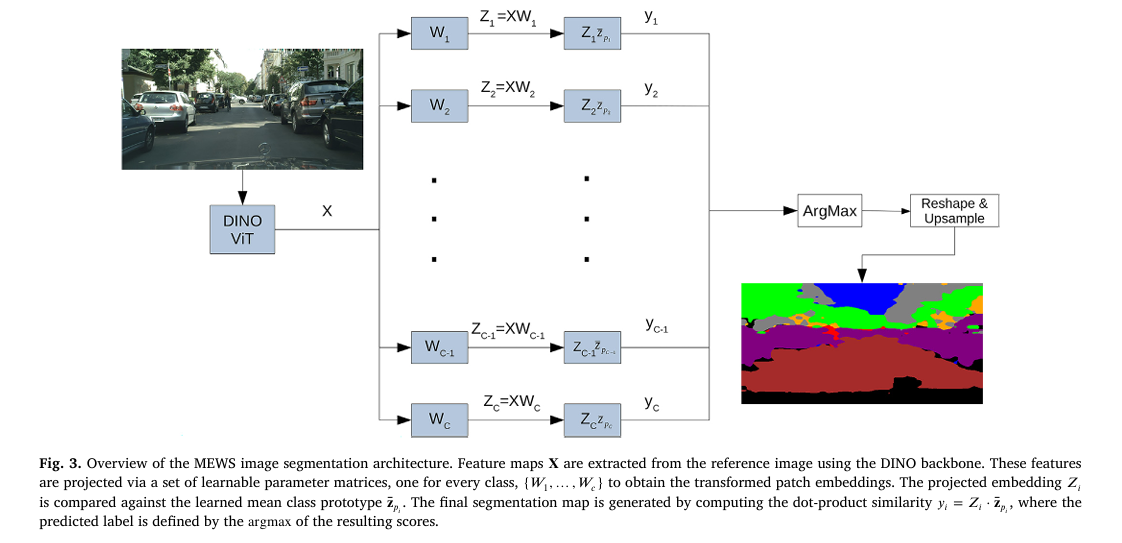
The process starts with a frozen DINOv3 ViT backbone — the latest iteration of the self-supervised DINO training framework, which learns from a massive and diverse dataset without any human labels. Given an input image, the ViT divides it into a grid of 16×16 pixel patches and produces a feature vector for each patch. For a 320×320 pixel input image, that gives you N=400 patch feature vectors, each of dimension D (768 for ViT-Base).
Now suppose you have N_c annotated pixels for each of C semantic classes. You identify which image patches correspond to those annotated pixels and extract their feature vectors. These become your class prototype vectors. For each class c, you compute a global prototype — the centroid of all annotated prototype vectors for that class. This centroid is the stable anchor that the entire training process revolves around.
Step 2: C Separate Projection Heads — One Per Class
MEWS applies C independent linear projection matrices (W_1, …, W_C), one for each semantic class, to the full image feature map. Each projection maps the D-dimensional backbone features into a lower-dimensional space optimized for discriminating that specific class. This is the key architectural departure from approaches that use a single shared projection: by giving each class its own projection, MEWS can learn class-specific feature transformations without forcing them to compete in a shared embedding space.
Given projected feature Z_c for class c and the class prototype centroid z̄_pc, classification is simple: compute the dot product similarity between each patch’s projected feature and the class prototype, then apply argmax across all C classes.
INPUT IMAGE (320×320 px)
│
┌──────▼──────────────────────────────────────────┐
│ FROZEN DINOv3 ViT-Base Backbone │
│ → N=400 patches × D=768 features │
│ → Feature map X ∈ ℝ^(N×D) │
│ → L2-normalize each row vector │
└──────┬──────────────────────────────────────────┘
│ X (normalized)
┌────┴────────────────────────┐
│ CLASS PROTOTYPE EXTRACTION │
│ For each class c: │
│ • Find annotated patches │
│ • Project: Z_pc = X_pc·Wc │
│ • Compute centroid z̄_pc │
└────┬────────────────────────┘
│
┌──────▼─────────────────────────────────────────────────────┐
│ C PARALLEL PROJECTION HEADS (learnable W_1 … W_C) │
│ │
│ X·W_1 → Z_1 ∈ ℝ^(N×D') y_i1 = z_i1ᵀ·z̄_p1 │
│ X·W_2 → Z_2 ∈ ℝ^(N×D') y_i2 = z_i2ᵀ·z̄_p2 │
│ ... │
│ X·W_C → Z_C ∈ ℝ^(N×D') y_iC = z_iCᵀ·z̄_pC │
│ │
│ ĉ_i = argmax[y_i1, …, y_iC] (per-patch label) │
└──────┬─────────────────────────────────────────────────────┘
│
┌──────▼───────────────────────────────────┐
│ RESHAPE + UPSAMPLE │
│ N patch labels → H×W segmentation map │
└──────────────────────────────────────────┘
TRAINING LOSSES (on W_1 … W_C only — backbone stays frozen):
L_total = L_corr + L_proto + L_triplet
Step 3: Three Complementary Loss Functions That Do the Heavy Lifting
The projection matrices are learned through a combination of three losses that each address a different aspect of the segmentation challenge. None of them require dense ground truth masks — just the sparse pixel prototypes established at initialization.
Correlation Contrastive Loss (L_corr) is the unsupervised foundation, inherited and extended from STEGO. It encourages the projected feature space to preserve the self-similarity structure of the original DINOv3 features: patches that were similar in the backbone space should remain similar after projection. The key innovation is a patch-specific dynamic threshold β_i that determines whether two patches are genuinely similar or merely weakly correlated. This threshold is computed automatically by fitting a two-component Gaussian Mixture Model (GMM) to the self-similarity distribution of each patch — no manual tuning required. Only patch pairs with similarity exceeding their patch-specific threshold contribute to the loss, preventing the model from aligning genuinely unrelated image regions.
Prototype Alignment Loss (L_proto) is the supervised anchor — and the ablation studies reveal it to be the single most important component. It ensures that the similarity relationships between patch features and the annotated class prototypes in the raw backbone space are faithfully preserved after projection. In practical terms: if a patch looked like a “sky” region before projection (it was similar to the sky prototype vectors), it should still look like a “sky” region after projection. This loss acts as a semantic bridge, grounding the self-supervised DINOv3 features to the specific class names provided by the sparse annotations. Removing it causes mIoU to plummet from 63.27% to 54.78% — an 8.5 point collapse that makes clear it’s doing the essential work of semantic alignment.
Prototype Triplet Loss (L_triplet) adds an explicit inter-class separation force. Standard triplet losses use individual sample anchors, but MEWS uses the class centroid z̄_pc as the anchor — a more stable choice that prevents correlated classes (say, “road” and “sidewalk”) from merging in the projected feature space. The loss employs hard-in-batch mining: for each class, it identifies the prototype that is furthest from its class centroid (the “hard positive”) and the nearest mean prototype from a different class (the “hard negative”), then pushes them apart by a margin m.
One important nuance: the triplet loss is essentially inert in extremely sparse supervision regimes (1–2 annotated images). When the prototype pool is tiny, the “hard positive” is trivially close to its centroid anchor, the margin is not violated, and the loss outputs zero. This is not a bug — it’s an honest reflection of the geometry. With more annotated images (8+), the triplet loss finds meaningful hard positives and contributes a consistent +1.66% mIoU gain on top of the already-strong prototype alignment loss.
Results: The Numbers That Matter
Cityscapes Performance
The headline result is MEWS BEST achieving 63.27% mIoU — within 0.19% of the fully supervised STEGO upper bound (63.46%), while using only 256 total annotated pixels (16 pixels per class across 16 images, in a dataset of 2,975 training images). Even the modest MEWS 4Px8I configuration — just 4 annotated pixels per class in 8 images — reaches 61.19%, outperforming the unsupervised STEGO baseline by a remarkable 7 points and ExCEL (the strongest CLIP-based competitor) by over 19 points.
| Method | Mean mIoU | Flat | Construct. | Human | Vehicle | Notes |
|---|---|---|---|---|---|---|
| STEGO Supervised | 63.46 | 88.95 | 75.25 | 50.72 | 71.34 | Full annotation upper bound |
| STEGO Unsupervised | 54.18 | 79.68 | 68.77 | 8.88 | 62.07 | No labels |
| CLIP-ES | 40.14 | 22.10 | 54.12 | 8.01 | 27.47 | Text prompts only |
| ExCEL | 41.90 | 80.07 | 47.80 | 11.34 | 46.87 | CLIP + patch-text alignment |
| DINO+Prototypes (4Px8I) | 57.55 | 84.81 | 70.42 | 17.70 | 60.78 | Same pixels, no projection |
| MEWS (4Px8I) | 61.19 | 88.37 | 73.04 | 32.25 | 65.92 | 32 total pixels! |
| MEWS (BEST) | 63.27 | 89.05 | 74.69 | 40.07 | 66.22 | −0.19% vs fully supervised |
The “Human” class result deserves special attention. It’s the hardest class in urban scene segmentation — pedestrians are small, often occluded, visually variable, and present at widely different scales. Unsupervised STEGO manages just 8.88%. CLIP-based methods hover around 8–11%. MEWS at 4Px8I achieves 32.25%, and MEWS BEST reaches 40.07%. The sparse pixel annotations are providing semantic grounding that text prompts and self-supervised clustering simply cannot replicate.
Sardinia Wildfire Dataset — Where It Gets Real
The Cityscapes results are impressive in a benchmark sense, but the Sardinia Wildfire dataset is where MEWS makes its strongest practical argument. This Natural Disaster Management dataset contains 668 aerial images with four classes: Background, Burnt, Smoke, and Fire. Smoke and Fire are particularly challenging — they’re sparse, irregularly shaped, spectrally unusual, and exactly the classes that matter most for rapid disaster assessment.
| Method | Mean | Background | Burnt | Smoke | Fire |
|---|---|---|---|---|---|
| STEGO Supervised | 57.05 | 95.46 | 35.10 | 55.96 | 41.68 |
| STEGO Unsupervised | 15.32 | 40.11 | 4.15 | 17.06 | 0.08 |
| 1-Shot SegGPT | 39.50 | 94.23 | 26.92 | 8.75 | 28.11 |
| 2-Shot SegGPT | 40.03 | 94.47 | 26.08 | 3.61 | 35.95 |
| DINO+Prototypes (4Px8I) | 29.44 | 72.88 | 17.20 | 18.22 | 9.45 |
| MEWS (4Px8I) | 44.95 | 87.28 | 19.76 | 40.02 | 32.75 |
| MEWS (4Px12I) | 46.58 | 89.02 | 24.23 | 42.16 | 30.92 |
MEWS outperforms SegGPT — a one-shot method trained on full segmentation masks — by over 6 mIoU points. For Smoke specifically, MEWS achieves 40.02% versus SegGPT’s 8.75%. That’s not a small improvement — it’s a qualitatively different capability. SegGPT, for all its sophistication, has effectively zero Smoke detection ability on this dataset. MEWS, with 4 pixel clicks per class in 8 images, correctly identifies smoke regions over 40% of the time.
“MEWS shows remarkable efficiency on the highly challenging and sparse disaster classes of Smoke and Fire, registering IoU scores that are more than double those of DINO+Prototypes and significantly higher than other few-shot and unsupervised baselines.” — Apostolidis, Mygdalis, Tzimas & Pitas, Neurocomputing 2026
The Ablation: What Actually Drives Performance
Three findings from the ablation study are worth internalizing because they have practical implications for anyone deploying a MEWS-style system.
First, annotated images matter far more than annotated pixels per image. Going from 4 images to 8 images produces a substantial mIoU jump; going from 4 pixels to 16 pixels per image produces diminishing returns. The practical implication is clear: if you have an annotation budget of N total pixels, spread them across as many images as possible rather than annotating more pixels per image. For MEWS, the sweet spot appears to be around 8 annotated images — performance typically plateaus after that, regardless of how many more images you add.
Second, the prototype alignment loss is non-negotiable. Removing it causes an 8.5% mIoU collapse. It’s the mechanism that transforms DINOv3’s generic visual features into class-specific representations. Without it, the correlation contrastive loss still produces good feature clusters, but they don’t correspond to the target semantic classes — they just correspond to whatever visual patterns DINO found naturally dominant.
Third, the triplet loss is a bonus, not a foundation. Adding it gains +1.66% at the top end, but it contributes nothing (and occasionally hurts slightly) in extremely sparse annotation regimes. If you’re working with fewer than 4 annotated images, you can safely omit it. If you have 8+ images, include it — the hard-mining provides meaningful class boundary enforcement once the prototype pool is large enough to find genuinely difficult positive examples.
Complete MEWS Implementation (PyTorch)
The implementation covers all components from the paper in 10 sections: configuration, DINOv3 backbone wrapper, GMM dynamic threshold computation, class prototype generation, MEWS projection architecture, Correlation Contrastive Loss, Prototype Alignment Loss, Prototype Triplet Loss with hard-in-batch mining, complete MEWS model combining all components, and a full training loop with a smoke test on synthetic data.
# ==============================================================================
# MEWS: Multiclass Extreme Weak Supervision for Semantic Image Segmentation
# Paper: Neurocomputing 680 (2026) 133290
# Authors: A. Apostolidis, V. Mygdalis, M. Tzimas, I. Pitas
# Affiliation: Aristotle University of Thessaloniki, Greece
# ==============================================================================
# Sections:
# 1. Imports & Configuration
# 2. DINOv3 Backbone Wrapper (frozen feature extractor)
# 3. GMM Dynamic Threshold Computation (offline, per-patch)
# 4. Class Prototype Generator (from sparse pixel annotations)
# 5. MEWS Projection Architecture (C independent heads)
# 6. Correlation Contrastive Loss L_corr (Eq. 3)
# 7. Prototype Alignment Loss L_proto (Eq. 4)
# 8. Prototype Triplet Loss L_triplet with hard mining (Eq. 5)
# 9. Full MEWS Model combining all components
# 10. Training Loop & Smoke Test
# ==============================================================================
from __future__ import annotations
import math, warnings
from typing import Dict, List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
import numpy as np
warnings.filterwarnings("ignore")
# ─── SECTION 1: Configuration ─────────────────────────────────────────────────
class MEWSConfig:
"""
MEWS hyperparameters from the paper.
Defaults match the Cityscapes configuration using DINOv3 ViT-Base.
"""
# Image settings
image_size: int = 320 # Input resolution (320×320)
patch_size: int = 16 # DINOv3 patch size (16×16 pixels)
# Backbone
backbone_dim: int = 768 # ViT-Base hidden dimension
proj_dim: int = 70 # D' projected dimension per class head
# Segmentation
num_classes: int = 8 # Cityscapes: 8 superclasses + void
# Annotation settings
n_pixels_per_class: int = 4 # N_c: annotated pixels per class
n_annotated_images: int = 8 # Number of images with annotations
# Loss hyperparameters
corr_clamp: float = -0.25 # r: minimum clamp for cosine sim (Eq. 3)
triplet_margin: float = 0.25 # m: triplet loss margin (best per Table 5)
# GMM initialization (from EWS paper experiments)
gmm_init_low: float = 0.04 # Low-similarity GMM centroid init
gmm_init_high: float = 0.30 # High-similarity GMM centroid init
gmm_n_iter: int = 50 # EM iterations for GMM fitting
# Training
lr: float = 1e-4
batch_size: int = 24
def __init__(self, **kwargs):
for k, v in kwargs.items(): setattr(self, k, v)
@property
def n_patches(self) -> int:
"""Total number of image patches: (image_size // patch_size)^2"""
s = self.image_size // self.patch_size
return s * s
# ─── SECTION 2: DINOv3 Backbone Wrapper ───────────────────────────────────────
class DINOv3Backbone(nn.Module):
"""
Frozen DINOv3 ViT-Base backbone for dense patch feature extraction.
In production, replace the __init__ body with:
self.model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
The model stays completely frozen during MEWS training — only the
C projection head weight matrices W_1 ... W_C are optimized.
Key properties of DINOv3 features (cited in the paper):
- Semantically rich patch features that generalize across domains
- Consistent region features: patches in the same semantic region
produce similar feature vectors even across images
- Captures scene layout naturally via self-supervised training
"""
def __init__(self, cfg: MEWSConfig, use_pretrained: bool = False):
super().__init__()
self.cfg = cfg
if use_pretrained:
# Production: load actual DINOv3 / DINOv2 weights
# self.model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
# Freeze all backbone parameters
# for p in self.model.parameters(): p.requires_grad_(False)
pass
else:
# Smoke-test stub: mimics backbone output shape
self.stub = nn.Sequential(
nn.Linear(cfg.patch_size * cfg.patch_size * 3, cfg.backbone_dim),
nn.LayerNorm(cfg.backbone_dim),
nn.GELU(),
nn.Linear(cfg.backbone_dim, cfg.backbone_dim),
)
for p in self.stub.parameters():
p.requires_grad_(False) # Frozen in both cases
self.use_pretrained = use_pretrained
def forward(self, images: Tensor) -> Tensor:
"""
images: (B, 3, H, W) — batch of RGB images
Returns: X (B, N, D) — patch feature maps (L2-normalized)
where N = (H//patch_size)*(W//patch_size), D = backbone_dim
"""
B, C_img, H, W = images.shape
p = self.cfg.patch_size
if self.use_pretrained:
# Real DINOv3/v2 call:
# features = self.model.forward_features(images)['x_norm_patchtokens']
# return F.normalize(features, dim=-1)
pass
# Stub: patchify and run through linear layers
N_h, N_w = H // p, W // p
# Unfold: (B, C, H, W) → (B, N, p*p*C)
x = images.unfold(2, p, p).unfold(3, p, p) # (B,C,Nh,Nw,p,p)
x = x.contiguous().view(B, C_img, N_h * N_w, p * p)
x = x.permute(0, 2, 1, 3).reshape(B, N_h * N_w, C_img * p * p)
x = self.stub(x.float()) # (B, N, D)
return F.normalize(x, dim=-1) # L2-normalize rows
# ─── SECTION 3: GMM Dynamic Threshold Computation ─────────────────────────────
def compute_gmm_thresholds(
X: Tensor, # (N, D) L2-normalized feature map
init_low: float = 0.04,
init_high: float = 0.30,
n_iter: int = 50,
eps: float = 1e-6,
) -> Tensor:
"""
Compute per-patch GMM thresholds β_i for the Correlation Contrastive Loss.
(Section 3.3 — dynamic computation of L_corr hyperparameters)
For each patch i, we fit a 2-component 1D Gaussian Mixture Model (GMM)
to the distribution of cosine similarities [C_XX]_{i,:} between patch i
and all other patches. The threshold β_i is the mean of the two GMM
centroids — one representing high-similarity (same-region) pairs and
one representing low-similarity (cross-region) pairs.
This eliminates the need for manual threshold tuning and adapts
automatically to each image's specific feature statistics.
Args:
X: (N, D) L2-normalized feature map for a single image
init_low: Initial centroid for the low-similarity component
init_high: Initial centroid for the high-similarity component
n_iter: Number of EM iterations
eps: Numerical stability epsilon
Returns:
beta: (N,) per-patch similarity thresholds
"""
N, D = X.shape
# Compute full NxN cosine similarity matrix
C_XX = X @ X.T # (N, N), values in [-1, 1]
# For each patch, fit GMM to its similarity distribution with all other patches
betas = torch.zeros(N, device=X.device)
for i in range(N):
sim_i = C_XX[i].detach().cpu().numpy() # (N,) similarities
mu1, mu2 = float(init_low), float(init_high)
sigma1 = sigma2 = 0.1
pi1 = pi2 = 0.5
for _ in range(n_iter):
# E-step: compute responsibilities
g1 = pi1 * np.exp(-0.5 * ((sim_i - mu1) / (sigma1 + eps))**2) / (sigma1 + eps)
g2 = pi2 * np.exp(-0.5 * ((sim_i - mu2) / (sigma2 + eps))**2) / (sigma2 + eps)
denom = g1 + g2 + eps
r1, r2 = g1 / denom, g2 / denom # Responsibilities
# M-step: update parameters
n1, n2 = r1.sum() + eps, r2.sum() + eps
mu1 = (r1 * sim_i).sum() / n1
mu2 = (r2 * sim_i).sum() / n2
sigma1 = np.sqrt((r1 * (sim_i - mu1)**2).sum() / n1 + eps)
sigma2 = np.sqrt((r2 * (sim_i - mu2)**2).sum() / n2 + eps)
pi1, pi2 = n1 / (2 * N), n2 / (2 * N)
# Threshold is the mean of the two cluster centroids
betas[i] = (mu1 + mu2) / 2
return betas
def compute_proto_threshold(
Z_pc: Tensor, # (N_c, D') projected prototypes for class c
z_bar_pc: Tensor, # (D',) mean class prototype
eps: float = 1e-6,
) -> Tensor:
"""
Compute class-specific threshold β_{p_c} for L_proto.
(Section 3.3 — dynamic computation of L_proto hyperparameters)
β_{p_c} = average of the minimum similarity values within the
high-similarity cluster of all annotated patches in class c.
This provides a conservative lower bound for reliable prototype
similarities, preventing the model from aligning uncertain regions.
"""
# Cosine similarities between each prototype and class centroid
sims = F.normalize(Z_pc, dim=-1) @ F.normalize(z_bar_pc, dim=0) # (N_c,)
# Threshold = mean of minimum similarities (conservative lower bound)
min_sim = sims.min()
mean_sim = sims.mean()
return (min_sim + mean_sim) / 2
# ─── SECTION 4: Class Prototype Generator ─────────────────────────────────────
class ClassPrototypeGenerator(nn.Module):
"""
Generates class prototype feature vectors from sparse pixel annotations.
(Section 3.1 — Multiple class prototype vector generation)
For each annotated pixel (y, x) for class c, identifies the corresponding
ViT image patch, extracts its feature vector, and computes a class centroid.
In real deployments, annotation_coords come from manual user clicks in a
lightweight UI — the paper shows that 4 clicks per class in 8 images is
sufficient for near-supervised performance on Cityscapes.
"""
def __init__(self, cfg: MEWSConfig):
super().__init__()
self.cfg = cfg
def forward(
self,
X: Tensor, # (N, D) L2-normalized feature map for one image
annotation_coords: List[List[Tuple[int,int]]], # Per-class list of (row,col) pixel coords
W: int, # Feature map width in patches
) -> Tuple[Dict[int, Tensor], Dict[int, Tensor]]:
"""
Returns:
prototypes: dict[class_id → (N_c, D) raw prototype feature vectors]
centroids: dict[class_id → (D,) mean prototype vector (z̄_pc)]
"""
prototypes, centroids = {}, {}
p = self.cfg.patch_size
for c, coords in enumerate(annotation_coords):
proto_vecs = []
for (row_px, col_px) in coords:
# Map pixel coordinate to patch index
patch_row = row_px // p
patch_col = col_px // p
patch_idx = patch_row * W + patch_col
patch_idx = min(patch_idx, X.shape[0] - 1)
proto_vecs.append(X[patch_idx])
if proto_vecs:
P = torch.stack(proto_vecs) # (N_c, D)
prototypes[c] = P
centroids[c] = P.mean(dim=0) # (D,) — z̄_pc
return prototypes, centroids
# ─── SECTION 5: MEWS Projection Architecture ──────────────────────────────────
class MEWSProjectionHeads(nn.Module):
"""
C independent linear projection heads — one per semantic class.
(Section 3.2 — MEWS image segmentation architecture)
Each head W_c ∈ ℝ^(D×D') projects the shared ViT features into a
class-specific embedding space. This allows each class to learn its
own optimal feature transformation without competing with other classes
in a shared projection space — critical for distinguishing visually
correlated classes like 'road' vs 'sidewalk'.
Classification: ĉ_i = argmax_c [ z_ic · z̄_pc ] for all patches i
"""
def __init__(self, cfg: MEWSConfig):
super().__init__()
self.cfg = cfg
self.C = cfg.num_classes
# C separate projection matrices (each D × D')
# Stored as a ModuleList so they're all trainable
self.heads = nn.ModuleList([
nn.Linear(cfg.backbone_dim, cfg.proj_dim, bias=False)
for _ in range(cfg.num_classes)
])
def project_all(self, X: Tensor) -> List[Tensor]:
"""
Project feature map through all C heads.
X: (B, N, D) or (N, D) feature map
Returns: list of C tensors, each (B, N, D') or (N, D')
"""
return [head(X) for head in self.heads]
def segment(
self,
X: Tensor, # (N, D) feature map (single image)
centroids: Dict[int, Tensor], # class_id → (D',) projected centroid
) -> Tuple[Tensor, Tensor]:
"""
Perform segmentation by argmax over per-class similarity scores.
Returns:
scores: (N, C) similarity scores per patch per class
labels: (N,) predicted class label per patch
"""
N = X.shape[0]
scores = torch.full((N, self.C), -float('inf'), device=X.device)
for c, head in enumerate(self.heads):
Z_c = head(X) # (N, D')
Z_c_norm = F.normalize(Z_c, dim=-1)
if c in centroids:
z_bar = F.normalize(centroids[c], dim=0) # (D',)
scores[:, c] = Z_c_norm @ z_bar # (N,) dot-product similarity
labels = scores.argmax(dim=-1) # (N,)
return scores, labels
# ─── SECTION 6: Correlation Contrastive Loss ──────────────────────────────────
class CorrelationContrastiveLoss(nn.Module):
"""
L_corr: Encourages projected features to preserve ViT self-similarity.
(Section 3.3, Eq. 3)
For each class c, the projected feature map Z_c must maintain the
same pairwise cosine similarity structure as the original backbone
features X. Concretely:
- Pairs with C_XX[i,j] > β_i (above threshold): Z_c should also
show high similarity → the loss rewards aligned similarities
- Pairs with C_XX[i,j] ≤ β_i (below threshold): ignored
The per-patch GMM threshold β_i dynamically separates genuinely
similar pairs from weakly correlated ones, removing the need for
manual hyperparameter tuning across different image distributions.
This is the unsupervised backbone of MEWS, extending STEGO's
contrastive objective to the multiclass setting.
"""
def __init__(self, cfg: MEWSConfig):
super().__init__()
self.cfg = cfg
self.r = cfg.corr_clamp # −0.25: min clamp for Z_c similarity
def forward(
self,
X: Tensor, # (N, D) L2-normalized backbone features
Z_list: List[Tensor], # List of C (N, D') projected feature maps
betas: Tensor, # (N,) per-patch thresholds from GMM
class_weights: Optional[Tensor] = None, # (C,) a_c weights, default 1
) -> Tensor:
N = X.shape[0]
if class_weights is None:
class_weights = torch.ones(len(Z_list), device=X.device)
# Compute backbone self-similarity matrix C_XX
C_XX = X @ X.T # (N, N)
# β_i threshold matrix: broadcast (N,) → (N, N) for masking
beta_mat = betas.unsqueeze(1).expand(N, N) # (N, N)
total_loss = torch.tensor(0.0, device=X.device)
for c, Z_c in enumerate(Z_list):
# Compute projected feature self-similarity C_{ZcZc}
Z_c_norm = F.normalize(Z_c, dim=-1)
C_ZZ = Z_c_norm @ Z_c_norm.T # (N, N)
C_ZZ_clamped = torch.clamp(C_ZZ, min=self.r) # Clamp at r=−0.25
# Loss: reward projected similarity where backbone similarity is high
# Mask: only contribute when C_XX[i,j] > β_i
mask = (C_XX - beta_mat) # (N, N): positive where above threshold
loss_c = -1 / (N * N) * (mask * C_ZZ_clamped).sum()
total_loss = total_loss + class_weights[c] * loss_c
return total_loss
# ─── SECTION 7: Prototype Alignment Loss ──────────────────────────────────────
class PrototypeAlignmentLoss(nn.Module):
"""
L_proto: Aligns projected patch features with annotated class prototypes.
(Section 3.3, Eq. 4)
This is the supervised bridge between DINOv3's self-supervised features
and the target semantic classes. It ensures that:
1. Patches that were similar to class c prototypes in the raw backbone
space remain similar to class c prototypes after projection (s_ic)
2. The alignment is soft-thresholded by β_{p_c}: only confidently
prototype-similar patches contribute to the loss gradient
Ablation: removing L_proto causes mIoU to drop from 63.27% → 54.78%,
confirming it is the single most critical MEWS component. Without it,
clusters form but don't map to the target semantic classes.
"""
def __init__(self, cfg: MEWSConfig):
super().__init__()
self.cfg = cfg
def forward(
self,
X: Tensor, # (N, D) backbone features
Z_list: List[Tensor], # C list of (N, D') projected features
X_prototypes: Dict[int, Tensor], # class_id → (N_c, D) raw prototypes
Z_centroids: Dict[int, Tensor], # class_id → (D',) projected centroids
beta_proto: Dict[int, Tensor], # class_id → scalar threshold β_{p_c}
class_weights: Optional[Tensor] = None,
) -> Tensor:
N = X.shape[0]
if class_weights is None:
class_weights = torch.ones(len(Z_list), device=X.device)
total_loss = torch.tensor(0.0, device=X.device)
for c, Z_c in enumerate(Z_list):
if c not in X_prototypes:
continue
# s_ic: average cosine similarity between patch i and all raw class c prototypes
X_pc = X_prototypes[c] # (N_c, D) raw prototype vectors
X_pc_norm = F.normalize(X_pc, dim=-1) # (N_c, D)
X_norm = F.normalize(X, dim=-1) # (N, D)
# s_ic = mean similarity of patch i to all N_c raw prototypes of class c
s_ic = (X_norm @ X_pc_norm.T).mean(dim=-1) # (N,)
# y_ic: similarity between projected patch i and projected class c centroid
Z_c_norm = F.normalize(Z_c, dim=-1) # (N, D')
z_bar_c = F.normalize(Z_centroids[c], dim=0) # (D',)
y_ic = Z_c_norm @ z_bar_c # (N,) projected similarity
y_ic_clamped = torch.clamp(y_ic, min=0) # max(y_ic, 0)
# β_{p_c}: class-specific threshold (computed from GMM on prototype sims)
beta_c = beta_proto.get(c, torch.tensor(0.1, device=X.device))
# Loss: penalize misalignment between s_ic and y_ic (above threshold)
loss_c = -1 / N * ((s_ic - beta_c) * y_ic_clamped).sum()
total_loss = total_loss + class_weights[c] * loss_c
return total_loss
# ─── SECTION 8: Prototype Triplet Loss ────────────────────────────────────────
class PrototypeTripletLoss(nn.Module):
"""
L_triplet: Enforces intra-class compactness and inter-class separation.
(Section 3.3, Eq. 5)
Unlike standard triplet losses that use individual sample anchors,
MEWS uses the class centroid z̄_pc as the stable anchor. This prevents
correlated classes (e.g., 'road' and 'sidewalk', 'sky' and 'construction')
from merging in the projected feature space.
Hard-in-batch mining strategy:
- Hard positive (z_{p_ic}): the prototype of class c FURTHEST from z̄_pc
- Hard negative (z̄_{p_l}): the mean prototype of class l ≠ c CLOSEST to z̄_pc
The loss pushes the hard positive toward its centroid while pushing the
centroid away from the hard negative class centroid.
Critical limitation: with very few prototypes (1–2 annotated images),
the hard positive is trivially close to its anchor, the margin is never
violated, and the loss outputs zero (inactive). Effective only when
N_c × num_annotated_images ≥ ~32 total prototypes.
"""
def __init__(self, cfg: MEWSConfig):
super().__init__()
self.cfg = cfg
self.m = cfg.triplet_margin # Default m=0.25 (best per Table 5)
def forward(
self,
Z_pc_dict: Dict[int, Tensor], # class_id → (N_c, D') projected prototypes
Z_centroids: Dict[int, Tensor], # class_id → (D',) projected centroids
class_weights: Optional[Tensor] = None,
) -> Tensor:
classes = list(Z_centroids.keys())
C = len(classes)
if C < 2:
return torch.tensor(0.0) # Need at least 2 classes for triplet
if class_weights is None:
class_weights = {c: 1.0 for c in classes}
# Stack centroids for all classes: (C, D')
device = list(Z_centroids.values())[0].device
centroid_stack = torch.stack([Z_centroids[c] for c in classes]) # (C, D')
total_loss = torch.tensor(0.0, device=device)
for idx_c, c in enumerate(classes):
if c not in Z_pc_dict:
continue
Z_pc = Z_pc_dict[c] # (N_c, D') projected prototypes
z_bar_c = Z_centroids[c] # (D',) anchor: class c centroid
# ── Hard Positive Mining ──────────────────────────────────────────────
# Find the prototype in class c FURTHEST from its centroid (Eq. 5)
dists_pos = torch.norm(Z_pc - z_bar_c.unsqueeze(0), dim=-1) # (N_c,)
hard_pos_dist = dists_pos.max() # d(z̄_pc, z_{p_ic}) — hardest
# ── Hard Negative Mining ──────────────────────────────────────────────
# Find the mean prototype from a DIFFERENT class CLOSEST to z̄_pc
other_centroids = torch.stack([
centroid_stack[j] for j, cl in enumerate(classes) if cl != c
]) # (C-1, D')
dists_neg = torch.norm(other_centroids - z_bar_c.unsqueeze(0), dim=-1) # (C-1,)
hard_neg_dist = dists_neg.min() # d(z̄_pc, z̄_{p_l}) — closest negative
# ── Triplet Loss ──────────────────────────────────────────────────────
# max{d_pos - d_neg + m, 0}
loss_c = torch.clamp(hard_pos_dist - hard_neg_dist + self.m, min=0)
total_loss = total_loss + class_weights.get(c, 1.0) * loss_c
return total_loss
# ─── SECTION 9: Full MEWS Model ───────────────────────────────────────────────
class MEWS(nn.Module):
"""
MEWS: Multiclass Extreme Weak Supervision for Semantic Image Segmentation.
(Neurocomputing 680, 2026)
Full pipeline:
1. Frozen DINOv3 backbone → L2-normalized patch features X
2. GMM threshold computation (offline, per image)
3. Sparse pixel annotation → class prototypes & centroids
4. C projection heads W_1 ... W_C (the ONLY trainable parameters)
5. Three complementary losses (L_corr + L_proto + L_triplet)
6. Inference: argmax over per-class similarity scores
Parameter count scales linearly with C:
Each head adds D × D' params. For ViT-Base + D'=70:
1 class = 768 × 70 ≈ 54K params
8 classes ≈ 430K params (comparable to a standard segmentation head)
"""
def __init__(self, cfg: Optional[MEWSConfig] = None, use_pretrained: bool = False):
super().__init__()
cfg = cfg or MEWSConfig()
self.cfg = cfg
# Components
self.backbone = DINOv3Backbone(cfg, use_pretrained=use_pretrained)
self.proto_gen = ClassPrototypeGenerator(cfg)
self.proj_heads = MEWSProjectionHeads(cfg)
# Loss functions
self.loss_corr = CorrelationContrastiveLoss(cfg)
self.loss_proto = PrototypeAlignmentLoss(cfg)
self.loss_triplet = PrototypeTripletLoss(cfg)
# Cached prototypes and thresholds (updated from annotated images)
self.register_buffer('_prototype_ready', torch.tensor(False))
self._centroids: Optional[Dict[int, Tensor]] = None
def extract_features(self, images: Tensor) -> Tensor:
"""Extract L2-normalized patch features. (B, N, D)"""
with torch.no_grad():
return self.backbone(images)
def build_prototypes(
self,
images: Tensor, # (B, 3, H, W)
annotations: List[List[List[Tuple[int,int]]]], # [batch][class][pixel coords]
) -> Tuple[Dict[int, Tensor], Dict[int, Tensor], Dict[int, Tensor]]:
"""
Build class prototypes from annotated images.
Aggregates across multiple annotated images to form a single prototype
set that covers the full annotation budget.
Returns:
all_prototypes: class_id → (total_N_c, D) raw prototypes
all_centroids_X: class_id → (D,) mean raw prototype (from backbone)
beta_proto: class_id → scalar threshold β_{p_c}
"""
W = self.cfg.image_size // self.cfg.patch_size
all_prototypes: Dict[int, List[Tensor]] = {}
all_centroids_X: Dict[int, Tensor] = {}
beta_proto: Dict[int, Tensor] = {}
with torch.no_grad():
X_all = self.extract_features(images) # (B, N, D)
for b in range(images.shape[0]):
X_b = X_all[b] # (N, D)
protos_b, _ = self.proto_gen(X_b, annotations[b], W)
for c, P in protos_b.items():
if c not in all_prototypes:
all_prototypes[c] = []
all_prototypes[c].append(P)
# Aggregate: stack all prototypes across images per class
for c, proto_list in all_prototypes.items():
P_agg = torch.cat(proto_list, dim=0) # (total_N_c, D)
all_prototypes[c] = P_agg
all_centroids_X[c] = P_agg.mean(dim=0) # (D,)
return all_prototypes, all_centroids_X, beta_proto
def forward(
self,
images: Tensor, # (B, 3, H, W) training batch
X_proto_dict: Dict[int, Tensor], # class_id → (N_c, D) raw prototypes
X_centroid_dict: Dict[int, Tensor],# class_id → (D,) raw centroids
) -> Dict[str, Tensor]:
"""
Forward pass for a training batch.
Computes all three losses and returns them together with the total.
For inference, use predict() instead.
"""
B = images.shape[0]
W = self.cfg.image_size // self.cfg.patch_size
# 1. Extract backbone features (frozen)
with torch.no_grad():
X_all = self.extract_features(images) # (B, N, D)
# Accumulate losses across batch
total_l_corr = torch.tensor(0.0, device=images.device)
total_l_proto = torch.tensor(0.0, device=images.device)
total_l_triplet = torch.tensor(0.0, device=images.device)
for b in range(B):
X_b = X_all[b] # (N, D)
# 2. Project through all C heads
Z_list = self.proj_heads.project_all(X_b) # list of C (N, D')
# 3. Project prototypes through respective heads
Z_pc_dict: Dict[int, Tensor] = {}
Z_centroid_dict: Dict[int, Tensor] = {}
beta_proto: Dict[int, Tensor] = {}
for c in range(self.cfg.num_classes):
if c not in X_proto_dict:
continue
head = self.proj_heads.heads[c]
Z_pc = head(X_proto_dict[c]) # (N_c, D')
Z_pc_dict[c] = Z_pc
Z_centroid_dict[c] = Z_pc.mean(dim=0) # (D',) projected centroid
# Compute β_{p_c} from projected prototypes
beta_proto[c] = compute_proto_threshold(Z_pc, Z_centroid_dict[c])
# 4. Compute GMM thresholds for this image (offline, from backbone features)
betas = compute_gmm_thresholds(
X_b.detach(), self.cfg.gmm_init_low, self.cfg.gmm_init_high, self.cfg.gmm_n_iter
)
# 5. Compute three losses
l_corr = self.loss_corr(X_b, Z_list, betas)
l_proto = self.loss_proto(X_b, Z_list, X_proto_dict, Z_centroid_dict, beta_proto)
l_triplet = self.loss_triplet(Z_pc_dict, Z_centroid_dict)
total_l_corr = total_l_corr + l_corr
total_l_proto = total_l_proto + l_proto
total_l_triplet = total_l_triplet + l_triplet
# Average over batch
l_corr_mean = total_l_corr / B
l_proto_mean = total_l_proto / B
l_triplet_mean = total_l_triplet / B
l_total = l_corr_mean + l_proto_mean + l_triplet_mean
return {
'loss': l_total,
'l_corr': l_corr_mean,
'l_proto': l_proto_mean,
'l_triplet': l_triplet_mean,
}
@torch.no_grad()
def predict(
self,
image: Tensor, # (3, H, W) single image
centroids: Dict[int, Tensor], # class_id → (D',) projected centroid
) -> Tensor:
"""
Inference: produce a dense segmentation map for a single image.
Returns: seg_map (H, W) integer class labels
"""
H, W_img = image.shape[1], image.shape[2]
N_h = H // self.cfg.patch_size
N_w = W_img // self.cfg.patch_size
X = self.extract_features(image.unsqueeze(0))[0] # (N, D)
_, patch_labels = self.proj_heads.segment(X, centroids) # (N,)
# Reshape patch labels to spatial grid and upsample to full resolution
patch_map = patch_labels.view(N_h, N_w).float() # (N_h, N_w)
seg_map = F.interpolate(
patch_map.unsqueeze(0).unsqueeze(0),
size=(H, W_img), mode='nearest'
).squeeze().long() # (H, W)
return seg_map
# ─── SECTION 10: Training Loop & Smoke Test ───────────────────────────────────
def generate_synthetic_dataset(
n_images: int = 24,
n_annot: int = 8,
image_size: int = 320,
n_classes: int = 8,
n_pixels_per_class: int = 4,
device: torch.device = torch.device('cpu'),
) -> Tuple[Tensor, List[List[List[Tuple[int,int]]]], List[List[List[Tuple[int,int]]]]]:
"""
Generate synthetic RGB images with random pixel annotations.
Replace with real Cityscapes/Wildfire DataLoader for production use.
Returns:
images: (n_images, 3, H, W) float32 images in [0,1]
train_annot: annotations for the n_annot training images
test_images: remaining images for segmentation evaluation
"""
images = torch.rand(n_images, 3, image_size, image_size, device=device)
# Generate random pixel coordinates per class per image
def _random_coords():
coords = []
for c in range(n_classes):
class_coords = [
(torch.randint(16, image_size - 16, (1,)).item(),
torch.randint(16, image_size - 16, (1,)).item())
for _ in range(n_pixels_per_class)
]
coords.append(class_coords)
return coords
train_annot = [_random_coords() for _ in range(n_annot)]
eval_annot = [_random_coords() for _ in range(n_images - n_annot)]
return images, train_annot, eval_annot
def run_mews_training(device_str: str = 'cpu', n_steps: int = 5):
"""
MEWS training loop demonstration.
For production training on Cityscapes or Wildfire datasets:
1. Load DINOv3 backbone: torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
2. Use DataLoader with batch_size=24, Adam lr=1e-4
3. Select n_annot=8 images from training set, get manual pixel clicks per class
4. Run 100–200 epochs; performance plateaus around 8 annotated images
"""
device = torch.device(device_str)
# Config: tiny for smoke test
cfg = MEWSConfig(
image_size=64,
patch_size=16,
backbone_dim=128,
proj_dim=32,
num_classes=4,
n_pixels_per_class=4,
n_annotated_images=4,
gmm_n_iter=5, # Fewer iterations for speed in smoke test
)
model = MEWS(cfg, use_pretrained=False).to(device)
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"\nMEWS trainable parameters: {total_params:,} (projection heads only)")
print(f"Frozen backbone params: {sum(p.numel() for p in model.backbone.parameters()):,}")
# Generate synthetic dataset
n_img = cfg.n_annotated_images + 4
all_images, train_annot, _ = generate_synthetic_dataset(
n_images=n_img, n_annot=cfg.n_annotated_images,
image_size=cfg.image_size, n_classes=cfg.num_classes,
n_pixels_per_class=cfg.n_pixels_per_class, device=device,
)
annot_images = all_images[:cfg.n_annotated_images]
train_images = all_images[cfg.n_annotated_images:]
# Build class prototypes from annotated images (done ONCE before training)
print("\nBuilding class prototypes from annotated images...")
X_proto_dict, X_centroid_dict, _ = model.build_prototypes(annot_images, train_annot)
print(f" Prototypes built for {len(X_proto_dict)} classes")
for c, P in X_proto_dict.items():
print(f" Class {c}: {P.shape[0]} prototype vectors (dim={P.shape[1]})")
# Optimizer: only projection heads are trained
optimizer = torch.optim.Adam(model.proj_heads.parameters(), lr=cfg.lr)
model.train()
print(f"\nTraining for {n_steps} steps (batch=all train images)...")
for step in range(n_steps):
optimizer.zero_grad()
out = model(train_images, X_proto_dict, X_centroid_dict)
loss = out['loss']
loss.backward()
torch.nn.utils.clip_grad_norm_(model.proj_heads.parameters(), 5.0)
optimizer.step()
print(
f" Step {step+1}/{n_steps} | total={loss.item():.4f} | "
f"corr={out['l_corr'].item():.4f} | "
f"proto={out['l_proto'].item():.4f} | "
f"triplet={out['l_triplet'].item():.4f}"
)
# Inference demo
print("\nRunning inference on a test image...")
model.eval()
# Build projected centroids for inference
projected_centroids: Dict[int, Tensor] = {}
with torch.no_grad():
for c, proto in X_proto_dict.items():
Z_pc = model.proj_heads.heads[c](proto)
projected_centroids[c] = Z_pc.mean(dim=0)
test_img = all_images[-1] # (3, H, W)
seg_map = model.predict(test_img, projected_centroids) # (H, W)
print(f" Input image: {tuple(test_img.shape)}")
print(f" Segmentation map: {tuple(seg_map.shape)}")
unique_labels = seg_map.unique().tolist()
print(f" Unique predicted classes: {unique_labels}")
return model
if __name__ == '__main__':
print("=" * 60)
print(" MEWS — Full Architecture Smoke Test")
print("=" * 60)
torch.manual_seed(42)
np.random.seed(42)
# ── 1. Test individual loss functions ────────────────────────────────────
print("\n[1/4] Testing CorrelationContrastiveLoss...")
cfg_test = MEWSConfig(backbone_dim=64, proj_dim=32, num_classes=3,
image_size=64, patch_size=16, gmm_n_iter=3)
X_test = F.normalize(torch.randn(16, 64), dim=-1)
betas_test = torch.ones(16) * 0.1
Z_test = [F.normalize(torch.randn(16, 32), dim=-1) for _ in range(3)]
l_corr_fn = CorrelationContrastiveLoss(cfg_test)
l_corr_val = l_corr_fn(X_test, Z_test, betas_test)
print(f" L_corr = {l_corr_val.item():.4f}")
print("\n[2/4] Testing PrototypeTripletLoss...")
Z_pc_d = {0: torch.randn(8, 32), 1: torch.randn(8, 32), 2: torch.randn(8, 32)}
Z_cent_d = {c: v.mean(dim=0) for c, v in Z_pc_d.items()}
l_tri_fn = PrototypeTripletLoss(cfg_test)
l_tri_val = l_tri_fn(Z_pc_d, Z_cent_d)
print(f" L_triplet = {l_tri_val.item():.4f}")
print("\n[3/4] Testing ClassPrototypeGenerator...")
proto_gen = ClassPrototypeGenerator(cfg_test)
X_dummy = F.normalize(torch.randn(16, 64), dim=-1) # 4×4 patches
annots = [[(10, 10), (20, 20)], [(30, 10), (40, 20)], [(10, 40), (20, 50)]]
protos, cents = proto_gen(X_dummy, annots, W=4)
print(f" Generated prototypes for {len(protos)} classes")
print("\n[4/4] Full training loop...")
trained_model = run_mews_training(device_str='cpu', n_steps=5)
print("\n" + "=" * 60)
print("✓ All checks passed. MEWS is ready for real training.")
print("=" * 60)
print("""
Production checklist:
1. Install DINOv3/v2:
import torch
model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
2. Download Cityscapes:
Home
3. Download Sardinia Wildfire (BLAZE 2):
Will be published as part of BLAZE 2 multiclass segmentation dataset
4. Annotation strategy (from paper):
- Select 8 images randomly from training set
- For each image, click 4 pixels per semantic class
- Prefer central region pixels (avoids boundary ambiguity)
- Apply minimum filter of 16px to ensure spatial separation
5. Training configuration:
- Batch size: 24 (larger is better per ablation)
- Optimizer: Adam, lr=1e-4
- Triplet margin: m=0.25 (fast convergence) or m=0.75 (stability)
- ONLY train projection heads W_1 ... W_C (backbone stays frozen)
- Validation plateau typically reached at ~8 annotated images
""")
Read the Full Paper
The complete study — including per-class IoU breakdowns, full ablation tables for every loss component and annotation configuration, GMM threshold analysis, backbone comparison, and Sardinia Wildfire dataset description — is published in Neurocomputing.
Apostolidis, A., Mygdalis, V., Tzimas, M., & Pitas, I. (2026). MEWS: Semantic image segmentation with multiclass extreme weak supervision. Neurocomputing, 680, 133290. https://doi.org/10.1016/j.neucom.2026.133290
This article is an independent editorial analysis of peer-reviewed research. The PyTorch implementation is an educational adaptation of the published methodology. For the exact experimental configurations (DINOv3 backbone weights, Cityscapes preprocessing, GMM initialization values), refer to the original paper. This work was supported by the European Commission under HORIZON EUROPE grant 101093003 (TEMA).