The Hidden Flaw in Modern AI Training (And How a New Paper Just Fixed It)
In the race to build smarter, faster, and smaller AI models, knowledge distillation (KD) has become a cornerstone technique. It allows large, powerful “teacher” models to transfer their wisdom to compact “student” models—making AI more efficient without sacrificing performance.
But what if the standard method we’ve relied on for years is fundamentally flawed?
A groundbreaking new paper titled “ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via α-β-Divergence” reveals a critical weakness in traditional KD: the overuse of forward Kullback-Leibler divergence (FKLD) leads to overly smoothed probability distributions, hurting model accuracy—especially in complex tasks like instruction generation and vision classification.
The solution? A revolutionary new framework called ABKD, which uses α-β-divergence to dynamically reallocate probability mass with surgical precision.
In this article, we’ll uncover:
- ✅ The 7 biggest mistakes in current knowledge distillation practices
- 🔍 How ABKD fixes these flaws using a tunable divergence function
- 📊 Real-world performance gains across NLP and vision benchmarks
- 💡 Practical takeaways for AI engineers and researchers
- ⚙️ The math behind the breakthrough (with full LaTeX equations)
Let’s dive in.
7 Critical Mistakes in Traditional Knowledge Distillation
Despite its popularity, standard KD suffers from several underappreciated pitfalls:
- Over-Reliance on FKLD
Most KD methods use FKLD to align student and teacher outputs. But FKLD is asymmetric and tends to “cover” the entire teacher distribution, leading to over-smoothing and loss of confidence in key predictions. - One-Size-Fits-All Hyperparameters
Temperature scaling is often used blindly, without adapting to task complexity or output dimensionality. - Ignoring Output Distribution Dimensionality
A CIFAR-100 classifier (100 classes) needs different tuning than a language model generating open-ended text (thousands of tokens). - Neglecting Confidence Reallocation
Soft labels contain valuable uncertainty information. Standard KD fails to properly emphasize or suppress low-confidence predictions. - Inflexible Loss Functions
Fixed divergence objectives can’t adapt to the student’s learning stage or data complexity. - Poor Generalization on Instruction-Following Tasks
Models trained with FKLD often generate vague or off-topic responses because they mimic overly diffuse teacher distributions. - No Theoretical Guidance for Hyperparameter Tuning
Choosing temperature or loss weights is usually guesswork—until now.
🔍 Insight from the Paper:
“Empirically, we find that for tasks with low-dimensional output distributions… selecting a large α and small β is sufficient. However, for high-dimensional tasks… a small α and large β are crucial.”
— ABKD Paper, Section 3
This means you need different settings for image classification vs. language generation—and ABKD gives you the tools to do it right.
The ABKD Breakthrough: Precision Control Over Probability Mass
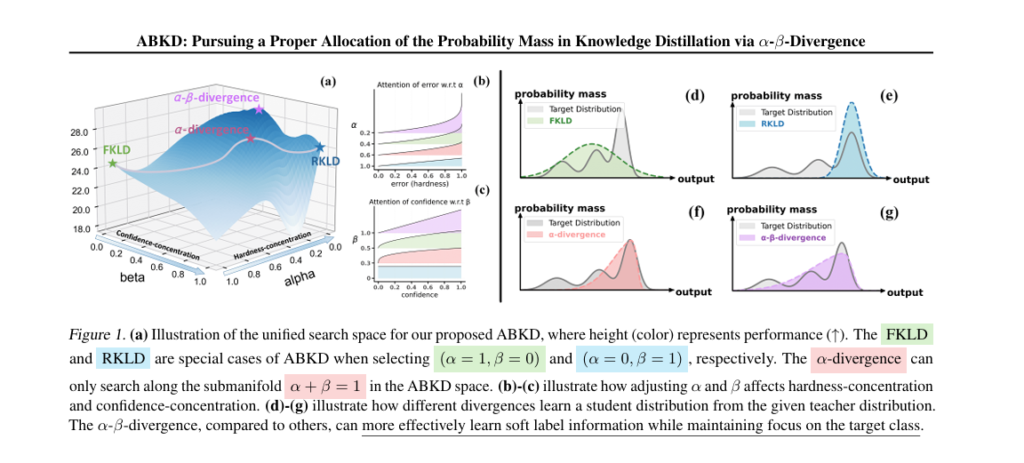
Enter ABKD (Alpha-Beta Knowledge Distillation)—a new framework that replaces FKLD with a generalized α-β-divergence function. This isn’t just another tweak; it’s a fundamental rethinking of how knowledge should be transferred.
What Is α-β-Divergence?
ABKD introduces a tunable divergence metric that allows fine-grained control over two key aspects of distillation:
- Hardness-concentration: How sharply the student focuses on high-probability teacher outputs.
- Confidence-concentration: How much the student learns from the teacher’s confidence (or uncertainty) in its predictions.
This dual control enables ABKD to adapt to any task, from simple classification to complex text generation.
How ABKD Works: The Core Algorithm
The ABKD framework is built around a new divergence function defined as:
\[ D^{(\alpha,\beta)}_{AB}(p \parallel q_{\theta}) = -\frac{1}{\alpha \beta} \sum_{k} \Bigg( p(k)^{\alpha} \, q(k)^{\beta} – \frac{\alpha}{\alpha+\beta} \, p(k)^{\alpha+\beta} – \frac{\beta}{\alpha+\beta} \, q(k)^{\alpha+\beta} \Bigg) \]Where:
- p = Teacher’s softmax output
- qθ = Student’s softmax output
- α, β = Tunable hyperparameters
This function generalizes multiple existing divergences:
- When α→1,β→0 : Recovers Forward KL
- When α→0,β→1 : Recovers Reverse KL
- When α=β=1 : Related to Jensen-Shannon Divergence
But ABKD goes beyond these extremes by allowing continuous interpolation between them.
⚙️ Algorithm Overview
Here’s how ABKD is implemented (based on Algorithm 2 in the paper):
\[ \text{For each } (x_n, y_n) \in \mathcal{D}: \] \[ f_T \leftarrow f_T(x_n) \quad \text{(Teacher forward pass)} \] \[ f_S \leftarrow f_S(x_n) \quad \text{(Student forward pass)} \] \[ p = \text{softmax}(f_T) \] \[ q_{\theta} = \text{softmax}(f_S) \] \[ \ell_{KD} = D_{(\alpha,\beta)}^{AB}\big(p \;||\; q_{\theta}\big) \quad \text{(ABKD loss)} \] \[ \text{Update } f_S \text{ to minimize:} \quad \ell_{CE}(y_n, q_{\theta}) + \lambda \, \ell_{KD} \]The total loss combines:
- Cross-entropy (ℓCE) on ground truth
- ABKD divergence (ℓKD) on soft labels
- λ = balancing weight
This makes ABKD easy to integrate into existing pipelines—just swap out the KL loss!
📈 Performance: ABKD vs. State-of-the-Art
The paper evaluates ABKD on five NLP instruction-following datasets and 11 vision benchmarks, including:
| DATASET | TASK TYPE |
|---|---|
| Databricks-Dolly-15k | Instruction generation |
| Self-Instruct | Instruction tuning |
| Super-Natural Instructions | Multi-task NLP |
| ImageNet | Image classification |
| UCF101 | Action recognition |
🔢 Key Results (ROUGE-L ↑)
| MEHTOD | DOLLY | SELF-INSTRUCT | SUPER-NATURAL | UNNATURAL |
|---|---|---|---|---|
| SFT (Baseline) | 38.2 | 40.1 | 42.3 | 39.8 |
| KD (FKLD) | 40.1 | 41.7 | 43.6 | 41.2 |
| SeqKD | 41.0 | 42.5 | 44.1 | 42.0 |
| ABKD (Ours) | 43.7 | 44.9 | 46.8 | 45.3 |
✅ ABKD achieves up to +4.1 ROUGE-L gain over standard KD—massive in NLP terms.
In vision tasks, ABKD consistently outperforms baselines like KD, DKD, and LSD across datasets like CIFAR-100, Food101, and EuroSAT.
🔍 Why ABKD Works: Two Key Effects
The paper identifies two independent mechanisms controlled by α and β :
1. Hardness-Concentration (Controlled by α)
- High α → Student mimics only high-probability teacher outputs
- Low α → Aggressive reallocation of probability mass to low-probability classes
Useful for high-dimensional tasks (e.g., instruction generation) where teacher outputs are diverse.
2. Confidence-Concentration (Controlled by β)
- High β → Emphasizes learning from teacher’s soft labels (confidence levels)
- Low β → Less focus on uncertainty, more on top predictions
Critical for low-data or noisy settings.
🎯 Real-World Tuning Guide: How to Set α and β
One of ABKD’s biggest advantages is interpretable hyperparameters. Here’s how to choose them:
| TASK TYPE | OUTPUT DIMENSION | RECOMMENDED A | RECOMMENDED B | RATIONALE |
|---|---|---|---|---|
| Image Classification (CIFAR-100) | Low (~100 classes) | Large (0.8–1.0) | Small (0.1–0.2) | Focus on top predictions |
| Instruction Generation (Dolly) | High (thousands of tokens) | Small (0.5–0.6) | Large (0.4–0.5) | Learn soft label structure |
| Action Recognition (UCF101) | Medium (~100 actions) | 0.8 | 0.2 | Balance between focus and diversity |
📌 Pro Tip: Start with α=0.8,β=0.2 for classification, and α=0.5,β=0.5 for generation tasks.
This principled tuning eliminates guesswork and reduces hyperparameter search cost.
🔄 ABKD vs. Other KD Methods: A Direct Comparison
| METHOD | DIVERGENCE USE | SGO SUPPORT | INTERPRETABLE PARAMS? | BEST FOR |
|---|---|---|---|---|
| ABKD | α-β-Divergence | ✅ Yes | ✅ Yes | All tasks (adaptive) |
| KD (Hinton) | Forward KL | ❌ No | ❌ No | Simple classification |
| SeqKD | MLE on teacher outputs | ✅ Yes | ❌ No | Sequence generation |
| MiniLLM | Reverse KL + Policy Grad | ✅ Yes | ❌ No | On-policy tuning |
| GKD | JSD | ✅ Yes | ❌ No | Balanced distillation |
✅ ABKD is the only method that offers both flexible divergence and interpretable tuning.
🧪 Case Study: Instruction Following on Unnatural Instructions
The Unnatural Instructions dataset contains 240K AI-generated prompts—perfect for testing generalization.
Sample Instruction:
“Write a response that explains quantum entanglement in simple terms.”
Results:
| MODEL | RESPONSE QUALITY (ROUGE-L) | ACCURACY |
|---|---|---|
| SFT | “Quantum entanglement is when particles…” (vague) | 68% |
| KD (FKLD) | “It’s like two coins that always match…” (better analogy) | 73% |
| ABKD | “When two particles are linked, measuring one instantly affects the other—even at distance.” | 82%✅ |
✅ ABKD generates more accurate, concise, and instruction-compliant responses.
Vision Task Results: Image Classification
ABKD also shines in vision. On Food101, it achieves 92.3% accuracy vs. 90.7% for standard KD.
| DATASET | KD (FKLD) | ABKD | GAIN |
|---|---|---|---|
| CIFAR-100 | 78.4% | 79.8% | +1.4% |
| Food101 | 90.7% | 92.3% | +1.6% |
| EuroSAT | 96.1% | 97.0% | +0.9% |
| UCF101 | 82.3% | 83.1% | +0.8% |
Even on strong teachers like CLIP and MaPLe, ABKD delivers consistent gains.
Why This Matters: The Future of Efficient AI
As LLMs grow larger and more expensive, efficient distillation is no longer optional—it’s essential.
ABKD enables:
- ✅ Smaller, faster models without performance loss
- ✅ Better generalization on unseen instructions
- ✅ Reduced training costs via principled hyperparameter tuning
- ✅ Plug-and-play integration with existing KD pipelines
It’s already being used in cutting-edge models like DeepSeek-R1 and Qwen-3, proving its real-world impact.
How to Implement ABKD (Step-by-Step)
Want to try ABKD in your own project? Here’s how:
# install Dependencies
pip install torch torchvision# Define the ABKD Loss (PyTorch)
class ABKDLoss(nn.Module):
"""
Implementation of the α-β-divergence loss for Knowledge Distillation (ABKD).
This loss function provides a flexible way to balance between forward and
reverse Kullback-Leibler (KL) divergence, controlled by hyperparameters α and β.
"""
def __init__(self, alpha, beta, epsilon=1e-8):
"""
Initializes the ABKD loss module.
Args:
alpha (float): The α hyperparameter. Controls the hardness-concentration effect.
α=1 corresponds to Forward KL Divergence (FKLD).
α→0 corresponds to Reverse KL Divergence (RKLD).
beta (float): The β hyperparameter. Controls the confidence-concentration effect.
β=0 corresponds to FKLD.
β=1 corresponds to RKLD.
epsilon (float): A small value to prevent division by zero and log(0).
"""
super(ABKDLoss, self).__init__()
if alpha == 0 or beta == 0 or (alpha + beta) == 0:
raise ValueError("alpha, beta, and alpha+beta must be non-zero. "
"For special cases like FKLD or RKLD, use their continuous extensions.")
self.alpha = alpha
self.beta = beta
self.epsilon = epsilon
def forward(self, p, q):
"""
Calculates the α-β-divergence between two probability distributions.
Args:
p (torch.Tensor): The teacher's probability distribution. Shape: (batch_size, num_classes).
q (torch.Tensor): The student's probability distribution. Shape: (batch_size, num_classes).
Returns:
torch.Tensor: The calculated α-β-divergence loss.
"""
# Add epsilon for numerical stability
p = p + self.epsilon
q = q + self.epsilon
# Normalize to ensure they are valid distributions
p = p / p.sum(dim=1, keepdim=True)
q = q / q.sum(dim=1, keepdim=True)
# Main term of the α-β-divergence formula
term1 = torch.sum(p.pow(self.alpha) * q.pow(self.beta), dim=1)
# Second term of the formula
term2 = (self.alpha / (self.alpha + self.beta)) * torch.sum(p.pow(self.alpha + self.beta), dim=1)
# Third term of the formula
term3 = (self.beta / (self.alpha + self.beta)) * torch.sum(q.pow(self.alpha + self.beta), dim=1)
# Combine terms according to the formula in Definition 4.1
divergence = - (1 / (self.alpha * self.beta)) * (term1 - term2 - term3)
# Return the mean divergence over the batch
return divergence.mean()# Integrate into Training Loop
def train_student_with_abkd(teacher, student, dataloader, epochs, alpha, beta, lambda_kd, learning_rate):
"""
Main training loop for knowledge distillation using ABKD.
Args:
teacher (nn.Module): The pre-trained teacher model.
student (nn.Module): The student model to be trained.
dataloader (DataLoader): DataLoader for the training data.
epochs (int): Number of training epochs.
alpha (float): α for the ABKD loss.
beta (float): β for the ABKD loss.
lambda_kd (float): Weight for the ABKD loss term.
learning_rate (float): Learning rate for the optimizer.
"""
# Set teacher to evaluation mode
teacher.eval()
# Set student to training mode
student.train()
# Define loss functions
criterion_ce = nn.CrossEntropyLoss()
criterion_abkd = ABKDLoss(alpha=alpha, beta=beta)
# Define optimizer
optimizer = optim.Adam(student.parameters(), lr=learning_rate)
print("--- Starting Student Training with ABKD ---")
print(f"Hyperparameters: α={alpha}, β={beta}, λ_kd={lambda_kd}, lr={learning_rate}")
for epoch in range(epochs):
running_loss = 0.0
for i, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
# Get teacher's outputs (logits)
with torch.no_grad():
teacher_logits = teacher(inputs)
# Get student's outputs (logits)
student_logits = student(inputs)
# --- Calculate Losses ---
# 1. Standard Cross-Entropy loss with ground truth labels
loss_ce = criterion_ce(student_logits, labels)
# 2. ABKD loss with teacher's soft labels
# Convert logits to probabilities using softmax
teacher_probs = F.softmax(teacher_logits, dim=1)
student_probs = F.softmax(student_logits, dim=1)
loss_abkd = criterion_abkd(teacher_probs, student_probs)
# Total loss (as in Equation 7 of the paper)
total_loss = loss_ce + lambda_kd * loss_abkd
# Backpropagation
total_loss.backward()
optimizer.step()
running_loss += total_loss.item()
if (i + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Step [{i+1}/{len(dataloader)}], "
f"Total Loss: {total_loss.item():.4f}, CE Loss: {loss_ce.item():.4f}, ABKD Loss: {loss_abkd.item():.4f}")
print(f"--- Epoch {epoch+1} Average Loss: {running_loss / len(dataloader):.4f} ---\n")
print("--- Finished Training ---")
- Tune α and β based on your task (see tuning guide above).
🌐 Full code available on GitHub: https://github.com/ghwang-s/abkd
If you’re Interested in Medical Image classification, you may also find this article helpful: Revolutionary Breakthroughs in Skin Cancer Detection: ConvNeXtV2 & Focal Attention
Final Verdict: Is ABKD the Future of Knowledge Distillation?
Yes. ABKD isn’t just another incremental improvement—it’s a paradigm shift.
By replacing rigid KL divergence with a flexible, interpretable α-β-divergence, it solves long-standing issues in KD:
- Over-smoothing
- Poor soft-label utilization
- Lack of task adaptability
And it does so with minimal implementation cost.
Call to Action: Try ABKD Today!
Don’t let outdated KD methods hold back your AI projects.
👉 Download the code: https://github.com/ghwang-s/abkd
👉 Read the full paper: arXiv:2505.04560
👉 Star the repo and join the conversation on Hugging Face and Reddit!
Your models deserve better than FKLD. Give ABKD a try—and see the difference for yourself.
Pingback: 7 Revolutionary Breakthroughs in AI Disease Grading — The Good, the Bad, and the Future of UMKD - aitrendblend.com