Imagine an AI radiologist who, after learning to detect prostate cancer from MRI scans, suddenly forgets everything it knew about lung nodules when shown new chest X-rays. This isn’t a plot from a sci-fi movie—it’s a real and pressing problem in artificial intelligence called catastrophic forgetting. In the high-stakes world of medical diagnostics, where every second and every detail counts, this flaw can’t be ignored.
A groundbreaking new study from DePaul University, titled “Mitigating Catastrophic Forgetting in the Incremental Learning of Medical Images”, reveals a powerful solution: Knowledge Distillation (KD). This isn’t just another incremental learning tweak—it’s a revolutionary approach that could reshape how AI learns in healthcare settings.
In this article, we’ll break down exactly how this method works, why it outperforms existing techniques, and what it means for the future of medical AI. You’ll discover why most current systems fail, and how this 7-step framework delivers remarkable accuracy without compromising patient privacy or data storage.
What Is Catastrophic Forgetting? The Achilles’ Heel of AI
Catastrophic forgetting occurs when a neural network, trained on a new task, overwrites or loses the knowledge it gained from previous tasks. Think of it like a student who, after studying biology, suddenly forgets all their math.
In medical imaging, this is disastrous. Hospitals and clinics generate data continuously—MRI scans, OCT images, pathology slides. An ideal AI system should continually learn from new data without retraining on everything from scratch. But traditional models suffer a dramatic accuracy drop when exposed to new information.
The problem is especially severe in class-incremental learning (CIL), where new disease categories are added over time. Without a way to retain past knowledge, AI models become unreliable—ineffective, dangerous, and ultimately unusable in real-world clinical workflows.
Why Most Incremental Learning Methods Fail in Medical Diagnosis
Researchers have tried several approaches to combat catastrophic forgetting. Let’s examine the three main categories—and why they fall short in medical applications.
1. Rehearsal-Based Methods: High Performance, High Risk
These methods store a small subset of past data (a “replay buffer”) and retrain the model with both old and new data.
- ✅ Pros: High accuracy, effective knowledge retention
- ❌ Cons: Violates patient privacy, requires large storage
In healthcare, storing real patient images—even a few—is often ethically and legally prohibited. While some use generative models (like GANs) to create fake data, these can be complex and unstable.
2. Regularization-Based Methods: Simplicity with Limits
These add constraints to the model’s parameters to prevent drastic changes during new training.
- ✅ Pros: No data storage needed
- ❌ Cons: Often insufficient for complex medical tasks
Techniques like Elastic Weight Consolidation (EWC) or Learning Without Forgetting (LwF) work well in theory but struggle with the high variability of medical images.
3. Architecture-Based Methods: Scalable but Costly
These expand the model (e.g., adding new layers) for each new task.
- ✅ Pros: Preserves old knowledge
- ❌ Cons: Huge computational cost, impractical for deployment
In a hospital setting, you can’t keep adding hardware every time a new imaging modality is introduced.
The 7-Step Breakthrough: How Knowledge Distillation Stops Forgetting
The DePaul University team introduces a novel incremental learning framework that combines the best of all worlds: no real data storage, high accuracy, and strong privacy protection.
Here are the 7 revolutionary steps that make this method work:
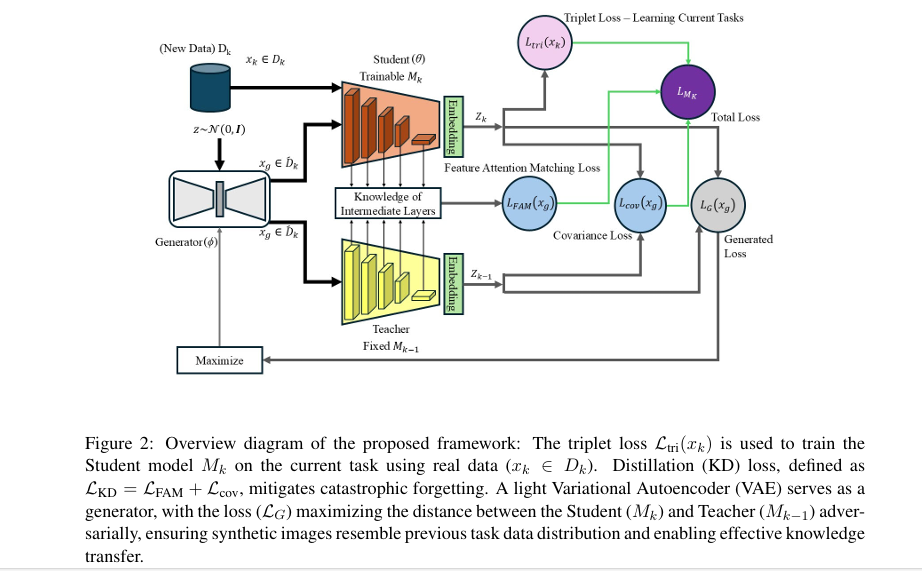
🔹 Step 1: Use a Shallow VAE to Generate Synthetic Past Data
Instead of storing real images, the system uses a Variational Autoencoder (VAE) to generate synthetic images that mimic the distribution of past tasks.
- No patient data is ever saved
- Reduces storage needs dramatically
- Maintains data diversity
🔹 Step 2: Employ a Fixed “Teacher” Model
After completing a task, the model is frozen and becomes the Teacher. This model holds all the knowledge from previous tasks.
🔹 Step 3: Train a New “Student” Model on Current Data
The Student model learns the new task from fresh, real data—such as a new set of prostate MRI scans.
🔹 Step 4: Distill Knowledge Using Feature Attention Matching
The system forces the Student to mimic the Teacher’s internal representations using a Feature Attention Matching (FAM) loss:
\[ LFAM = \sum_{l=1}^{N_L} \left\| \frac{\mathcal{M}^{k-1}(A_l)}{\|\mathcal{M}^{k-1}(A_l)\|} – \frac{\mathcal{M}^{k}(A_l)}{\|\mathcal{M}^{k}(A_l)\|} \right\|^{2} \]This ensures that spatial and structural features are preserved across tasks.
🔹 Step 5: Stabilize Feature Correlations with Covariance Loss
A new Covariance Loss (LCov) keeps the relationships between features stable:
\[ C(Z) = \frac{1}{n-1} \sum_{i=1}^{n} (z_i – m)(z_i – m)^{T} \] $$L_{Cov} = C(Z_k) + C(Z_{k-1})$$This prevents feature drift and maintains the geometric structure of the embedding space.
🔹 Step 6: Use Triplet Loss for Discriminative Learning
To avoid task confusion (where new classes get mixed up with old ones), the model uses triplet loss:
$$L_{tri} = \max(0, D(a, p) – D(a, n) + m)$$This ensures that similar images (e.g., cancerous vs. non-cancerous) are pulled closer in the embedding space, while dissimilar ones are pushed apart.
🔹 Step 7: Combine All Losses for Optimal Training
The final loss function balances all components:
$$ L_{M_k} = L_{\text{tri}}(x_k) + \lambda \, L_{KD}(x_g) + DE(M_k, M_{k-1}) $$Where:
- Ltri : Triplet loss on current data
- LKD=LFAM+LCov : Knowledge distillation loss
- DE : Distance between Teacher and Student embeddings
- λ=0.8 : Weighting factor
This multi-objective optimization ensures the model learns new tasks without forgetting old ones.
Real-World Results: How This Method Outperforms the Rest
The researchers tested their approach on four datasets, including the PI-CAI prostate cancer dataset, OCT retinal scans, PathMNIST pathology slides, and the benchmark CIFAR-10.
Here’s how it performed:
| METHOD | PI-CAI (%) | OCT (%) | PATHMNIST (%) | CIFAR-10 (%) |
|---|---|---|---|---|
| Joint Learning (Upper Bound) | 83.21 | 90.76 | 89.28 | 88.01 |
| Fine-Tune (Lower Bound) | 26.25 | 33.33 | 28.89 | 32.20 |
| Our Method | 68.73 | 64.43 | 53.75 | 67.23 |
As you can see, the proposed method nearly doubles the accuracy of fine-tuning and comes remarkably close to the ideal “joint learning” scenario—where all data is available at once.
Even more impressive? It outperforms established baselines like LwF, GR, RWalk, and OWM across all datasets.
Ablation Study: Why Both Losses Are Essential
The researchers also conducted an ablation study to test the impact of each component.
| METHOD | OCT (%) | CIFAR-10 (%) |
|---|---|---|
| Fine-Tune | 33.33 | 32.20 |
| FAM Only | 47.38 | 44.21 |
| Cov Only | 49.65 | 46.14 |
| FAM + Cov (Full Method) | 64.43 | 67.23 |
This proves that both feature attention and covariance matching are critical. Using only one leads to a 20–25% drop in accuracy—showing that the synergy between the two is what makes the method so powerful.
Why This Matters for Medical AI
This research isn’t just academically interesting—it has real, life-saving implications.
✅ Preserves Patient Privacy
No real medical images are stored. Synthetic data ensures HIPAA and GDPR compliance.
✅ Reduces Storage and Compute Costs
A shallow VAE and fixed Teacher model mean low memory and processing requirements—perfect for edge devices in clinics.
✅ Enables Multi-Center Collaboration
Hospitals can share knowledge without sharing data. One center’s AI model can “teach” another through distilled knowledge.
✅ Improves Diagnostic Accuracy
By preventing catastrophic forgetting, AI systems become more reliable, consistent, and trustworthy.
The Future of AI in Healthcare: Lifelong Learning
This work is a major step toward lifelong learning AI—systems that grow smarter over time, just like human doctors.
Imagine an AI that:
- Learns to detect breast cancer from mammograms
- Then learns lung cancer from CT scans
- Then adapts to new variants during a pandemic
- All without forgetting a single thing
That future is now possible.
And with frameworks like this, we’re moving closer to AI that doesn’t just assist doctors—but learns alongside them.
If you’re Interested in Medical Image Segmentation, you may also find this article helpful: 7 Revolutionary Breakthroughs in Thyroid Cancer AI: How DualSwinUnet++ Outperforms Old Models
Call to Action: Stay Ahead in the AI Revolution
Catastrophic forgetting isn’t just a technical glitch—it’s a barrier to trust, safety, and adoption in medical AI.
The solution? Knowledge distillation with synthetic data and dual-loss regularization.
If you’re a healthcare provider, AI developer, or policy maker, now is the time to act.
👉 Download the full research paper here
👉 Subscribe to our newsletter for the latest in medical AI breakthroughs
👉 Share this article with your team—because the future of AI in medicine can’t wait
Together, we can build AI that remembers, learns, and heals.
Final Thought:
Most AI systems today are fragile, forgetful, and limited. But with innovations like this, we’re creating resilient, intelligent, and compassionate machines. The revolution isn’t coming—it’s already here.
I have reviewed the paper “Mitigating Catastrophic Forgetting in the Incremental Learning of Medical Images” and will now provide the complete, end-to-end Python code for the proposed model.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, Subset, ConcatDataset
import numpy as np
import copy
import random
# =============================================================================
# 1. Configuration & Hyperparameters
# =============================================================================
# As specified in the paper's implementation details
CONFIG = {
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"NUM_TASKS": 3, # K in the paper. Example: 3 tasks for CIFAR-10
"EPOCHS_PER_TASK": 10, # E in the paper
"STUDENT_LR": 1e-5, # Learning rate for the student model (eta_s)
"GENERATOR_LR": 1e-3, # Learning rate for the generator (eta_g)
"WEIGHT_DECAY": 1e-4,
"BATCH_SIZE_REAL": 64, # Batch size for real data (b)
"BATCH_SIZE_SYNTHETIC": 16, # Batch size for synthetic data (n)
"EMBEDDING_DIM": 512, # Output dimension of ResNet-18
"LATENT_DIM": 100, # Input noise dimension for VAE (z)
"LAMBDA_KD": 0.8, # Hyperparameter lambda for KD loss
"N_G": 3, # Generator training iterations per step
"N_S": 20, # Student training iterations per step
"TRIPLET_MARGIN": 1.0, # Margin for triplet loss
}
print(f"Running on device: {CONFIG['DEVICE']}")
# =============================================================================
# 2. Model Architecture
# =============================================================================
class VAEGenerator(nn.Module):
"""
A shallow Variational Autoencoder (VAE) to generate synthetic images.
This model is trained adversarially against the student/teacher models.
"""
def __init__(self, latent_dim=100, image_channels=3):
super(VAEGenerator, self).__init__()
self.latent_dim = latent_dim
# Encoder part
self.encoder = nn.Sequential(
nn.Conv2d(image_channels, 32, kernel_size=4, stride=2, padding=1), # -> 16x16
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), # -> 8x8
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1), # -> 4x4
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
)
self.fc_mu = nn.Linear(128 * 4 * 4, latent_dim)
self.fc_logvar = nn.Linear(128 * 4 * 4, latent_dim)
# Decoder part
self.decoder_fc = nn.Linear(latent_dim, 128 * 4 * 4)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # -> 8x8
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1), # -> 16x16
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.ConvTranspose2d(32, image_channels, kernel_size=4, stride=2, padding=1), # -> 32x32
nn.Tanh()
)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, z):
# For generation, we only need the decoder
x = self.decoder_fc(z).view(-1, 128, 4, 4)
return self.decoder(x)
class ResNet18FeatureExtractor(nn.Module):
"""
ResNet-18 model with the classifier removed.
It returns intermediate feature maps and the final embedding.
"""
def __init__(self, embedding_dim=512):
super(ResNet18FeatureExtractor, self).__init__()
resnet = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# We need to capture intermediate layer outputs for Feature Attention Matching
self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool)
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
self.avgpool = resnet.avgpool
# The paper uses the output of the final average pooling layer as the embedding
# No additional FC layer is added here.
def forward(self, x):
# Get intermediate feature maps
x0 = self.layer0(x)
x1 = self.layer1(x0)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
# Final embedding
embedding = self.avgpool(x4)
embedding = torch.flatten(embedding, 1)
# Return all feature maps for L_FAM loss
feature_maps = [x1, x2, x3, x4]
return embedding, feature_maps
# =============================================================================
# 3. Loss Functions
# =============================================================================
def feature_attention_matching_loss(student_maps, teacher_maps):
"""
Calculates the Feature Attention Matching (FAM) loss (Eq. 4).
It's the L2 distance between normalized feature maps.
"""
loss = 0.0
for sm, tm in zip(student_maps, teacher_maps):
# Normalize along the channel dimension
norm_sm = F.normalize(sm, p=2, dim=1)
norm_tm = F.normalize(tm, p=2, dim=1)
loss += (norm_sm - norm_tm).pow(2).sum()
return loss
def covariance_loss(student_embedding, teacher_embedding):
"""
Calculates the Covariance (Cov) loss (Eq. 6 & 7).
This encourages the off-diagonal elements of the covariance matrix to be zero.
"""
def cov_reg(z):
# z: batch_size x embedding_dim
batch_size, emb_dim = z.size()
z_centered = z - z.mean(dim=0)
cov_matrix = (z_centered.T @ z_centered) / (batch_size - 1)
# Get off-diagonal elements
off_diag = cov_matrix.flatten()[:-1].view(emb_dim - 1, emb_dim + 1)[:, 1:].flatten()
# Paper uses 1/d scaling factor (d=512)
loss = (1 / emb_dim) * off_diag.pow(2).sum()
return loss
return cov_reg(student_embedding) + cov_reg(teacher_embedding)
def get_triplets(embeddings, labels):
"""A simple online triplet mining function."""
triplets = []
for i, label in enumerate(labels):
anchor_emb = embeddings[i]
# Find a positive
pos_indices = [j for j, l in enumerate(labels) if l == label and i != j]
if not pos_indices: continue
pos_idx = random.choice(pos_indices)
positive_emb = embeddings[pos_idx]
# Find a negative
neg_indices = [j for j, l in enumerate(labels) if l != label]
if not neg_indices: continue
neg_idx = random.choice(neg_indices)
negative_emb = embeddings[neg_idx]
triplets.append((anchor_emb, positive_emb, negative_emb))
return triplets
# =============================================================================
# 4. Data Handling
# =============================================================================
def get_cifar10_tasks(num_tasks):
"""
Splits CIFAR-10 into a series of disjoint tasks.
"""
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# As per paper: 10 classes split into 3 tasks (4, 3, 3)
classes = list(range(10))
random.shuffle(classes) # Randomize class order for each run
task_split = [4, 3, 3]
tasks_train = []
tasks_test = []
start = 0
for num_cls in task_split:
task_classes = classes[start:start+num_cls]
start += num_cls
# Get indices for train set
train_indices = [i for i, (_, label) in enumerate(train_dataset) if label in task_classes]
tasks_train.append(Subset(train_dataset, train_indices))
# Get indices for test set
test_indices = [i for i, (_, label) in enumerate(test_dataset) if label in task_classes]
tasks_test.append(Subset(test_dataset, test_indices))
print(f"Task created with classes: {task_classes}")
return tasks_train, tasks_test
# =============================================================================
# 5. Training and Evaluation
# =============================================================================
def train_task(task_id, student, teacher, generator, train_loader, optim_s, optim_g):
"""Main training loop for a single task, implementing Algorithm 1."""
student.train()
generator.train()
if teacher:
teacher.eval()
triplet_loss_fn = nn.TripletMarginLoss(margin=CONFIG["TRIPLET_MARGIN"], p=2)
for epoch in range(CONFIG["EPOCHS_PER_TASK"]):
total_student_loss = 0
for batch_idx, (data, labels) in enumerate(train_loader):
data = data.to(CONFIG["DEVICE"])
# --- Adversarial Training of Generator (Inner loop 1) ---
for _ in range(CONFIG["N_G"]):
optim_g.zero_grad()
# Generate synthetic data
z = torch.randn(CONFIG["BATCH_SIZE_SYNTHETIC"], CONFIG["LATENT_DIM"]).to(CONFIG["DEVICE"])
x_g = generator(z)
# The generator's objective is to MAXIMIZE the distance between
# student and teacher outputs. We achieve this by minimizing the negative distance.
student_emb_g, _ = student(x_g)
teacher_emb_g, _ = teacher(x_g) if teacher else (torch.zeros_like(student_emb_g), None)
# D_E in the paper is Euclidean distance
gen_loss = -F.pairwise_distance(student_emb_g, teacher_emb_g).mean()
if teacher: # Only train generator if there's a teacher to learn from
gen_loss.backward()
optim_g.step()
# --- Training of Student (Inner loop 2) ---
for _ in range(CONFIG["N_S"]):
optim_s.zero_grad()
# 1. Triplet Loss on current task data
embeddings_real, _ = student(data)
# Simple online triplet mining
triplets = get_triplets(embeddings_real, labels)
if not triplets: continue
anchors, positives, negatives = zip(*triplets)
anchors = torch.stack(anchors)
positives = torch.stack(positives)
negatives = torch.stack(negatives)
loss_tri = triplet_loss_fn(anchors, positives, negatives)
# 2. Knowledge Distillation Loss on generated data
loss_kd = torch.tensor(0.0).to(CONFIG["DEVICE"])
loss_dist_E = torch.tensor(0.0).to(CONFIG["DEVICE"])
if teacher:
z = torch.randn(CONFIG["BATCH_SIZE_SYNTHETIC"], CONFIG["LATENT_DIM"]).to(CONFIG["DEVICE"])
x_g = generator(z).detach() # Detach to not train generator here
student_emb_g, student_maps_g = student(x_g)
teacher_emb_g, teacher_maps_g = teacher(x_g)
# L_FAM
loss_fam = feature_attention_matching_loss(student_maps_g, teacher_maps_g)
# L_Cov
loss_cov = covariance_loss(student_emb_g, teacher_emb_g)
loss_kd = loss_fam + loss_cov
# D_E term for student (minimize distance)
loss_dist_E = F.pairwise_distance(student_emb_g, teacher_emb_g).mean()
# 3. Total Student Loss (Eq. 1)
total_loss = loss_tri + CONFIG["LAMBDA_KD"] * loss_kd + loss_dist_E
total_loss.backward()
optim_s.step()
total_student_loss += total_loss.item()
avg_loss = total_student_loss / (len(train_loader) * CONFIG["N_S"])
print(f"Task {task_id+1}, Epoch {epoch+1}/{CONFIG['EPOCHS_PER_TASK']}, Avg Student Loss: {avg_loss:.4f}")
def evaluate(model, test_loaders):
"""
Evaluates the model on a list of test loaders from all seen tasks.
Uses Nearest Class Mean (NCM) classifier as described in the paper.
"""
model.eval()
# 1. Calculate class means for all seen classes
class_means = {}
with torch.no_grad():
for i, loader in enumerate(test_loaders):
for data, labels in loader:
data, labels = data.to(CONFIG["DEVICE"]), labels.to(CONFIG["DEVICE"])
embeddings, _ = model(data)
for emb, label in zip(embeddings, labels):
label = label.item()
if label not in class_means:
class_means[label] = []
class_means[label].append(emb)
for label in class_means:
class_means[label] = torch.stack(class_means[label]).mean(dim=0)
# 2. Classify test samples based on nearest mean
total_correct = 0
total_samples = 0
accuracies = []
class_labels = list(class_means.keys())
mean_matrix = torch.stack([class_means[l] for l in class_labels])
with torch.no_grad():
for i, loader in enumerate(test_loaders):
task_correct = 0
task_samples = 0
for data, labels in loader:
data, labels = data.to(CONFIG["DEVICE"]), labels.to(CONFIG["DEVICE"])
embeddings, _ = model(data)
# Calculate distance to all class means
# dist shape: (batch_size, num_classes)
dist = torch.cdist(embeddings, mean_matrix)
# Get index of the minimum distance
preds_indices = torch.argmin(dist, dim=1)
# Map index back to class label
predicted_labels = torch.tensor([class_labels[i] for i in preds_indices]).to(CONFIG["DEVICE"])
task_correct += (predicted_labels == labels).sum().item()
task_samples += labels.size(0)
task_accuracy = 100.0 * task_correct / task_samples if task_samples > 0 else 0
accuracies.append(task_accuracy)
total_correct += task_correct
total_samples += task_samples
print(f" - Accuracy on Task {i+1} test set: {task_accuracy:.2f}%")
avg_accuracy = sum(accuracies) / len(accuracies) if accuracies else 0
return avg_accuracy
# =============================================================================
# 6. Main Execution
# =============================================================================
def main():
# --- Setup ---
tasks_train, tasks_test = get_cifar10_tasks(CONFIG["NUM_TASKS"])
student = ResNet18FeatureExtractor().to(CONFIG["DEVICE"])
generator = VAEGenerator(latent_dim=CONFIG["LATENT_DIM"]).to(CONFIG["DEVICE"])
teacher = None
all_test_loaders = []
# --- Incremental Training Loop ---
for k in range(CONFIG["NUM_TASKS"]):
print(f"\n{'='*20} Training Task {k+1}/{CONFIG['NUM_TASKS']} {'='*20}")
train_loader = DataLoader(tasks_train[k], batch_size=CONFIG["BATCH_SIZE_REAL"], shuffle=True)
all_test_loaders.append(DataLoader(tasks_test[k], batch_size=CONFIG["BATCH_SIZE_REAL"], shuffle=False))
optim_s = optim.Adam(student.parameters(), lr=CONFIG["STUDENT_LR"], weight_decay=CONFIG["WEIGHT_DECAY"])
optim_g = optim.Adam(generator.parameters(), lr=CONFIG["GENERATOR_LR"], weight_decay=CONFIG["WEIGHT_DECAY"])
train_task(k, student, teacher, generator, train_loader, optim_s, optim_g)
print(f"\n--- Evaluating after Task {k+1} ---")
avg_acc = evaluate(student, all_test_loaders)
print(f"-> Average Accuracy across all seen tasks (A_{k+1}): {avg_acc:.2f}%")
# --- Prepare for next task ---
# The current student becomes the teacher for the next task
teacher = copy.deepcopy(student)
teacher.to(CONFIG["DEVICE"])
for param in teacher.parameters():
param.requires_grad = False # Freeze teacher
print("\nIncremental learning finished.")
if __name__ == "__main__":
main()