ARuleCon: How NUS Researchers Built an AI Agent That Translates Security Rules Between Any SIEM Platform — And Why This Problem Is Harder Than It Sounds
Security teams spend weeks manually rewriting intrusion detection rules when migrating between platforms like Splunk, Microsoft Sentinel, and IBM QRadar. ARuleCon uses an agentic AI pipeline with intermediate representation, retrieval-augmented generation, and Python-based consistency testing to automate this — outperforming bare LLMs by 15% on 1,492 real-world rule conversions.
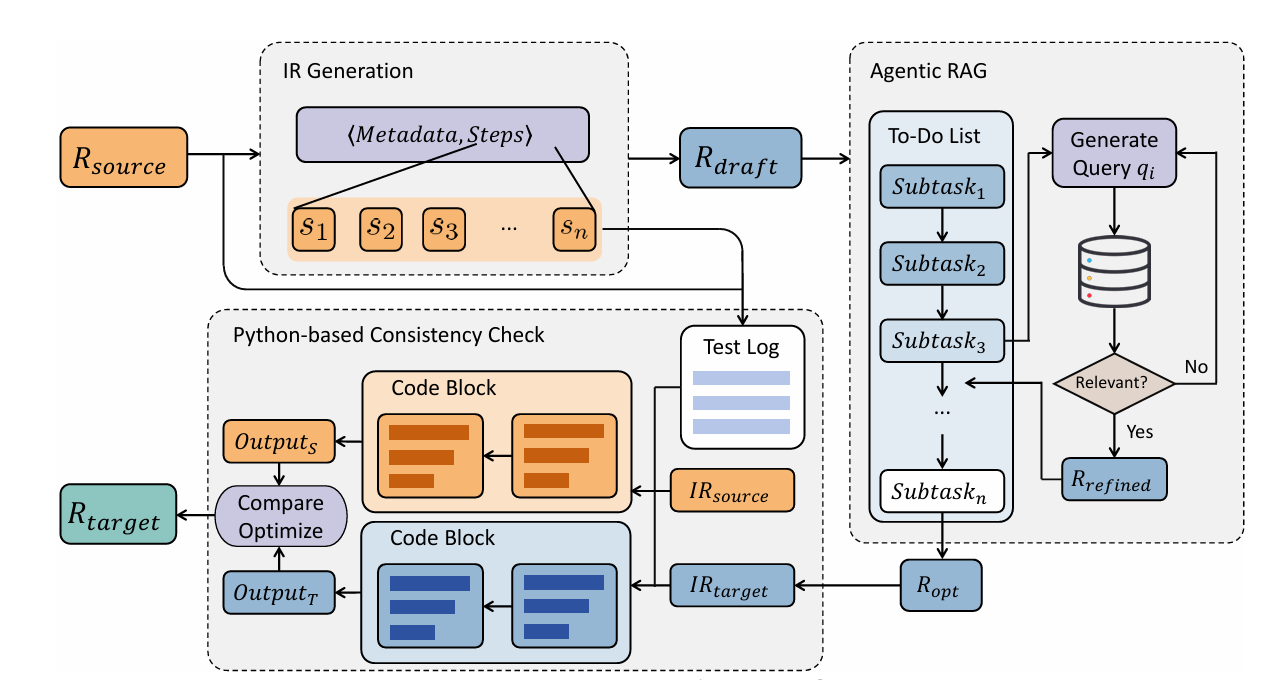
Every time a company switches SIEM platforms, merges with another organization, or needs to run two security systems in parallel, they face a hidden tax: all their carefully crafted detection rules have to be rewritten. A Splunk SPL rule that took a senior analyst two hours to get right doesn’t just run on Microsoft Sentinel or IBM QRadar. The languages aren’t compatible. The operators don’t map directly. The time window semantics are different. And getting it wrong doesn’t cause a syntax error — it causes silent security blind spots. ARuleCon, a new framework from the National University of Singapore and Fudan University, is the first serious attempt to automate this problem at scale.
Presented at WWW 2026 in Dubai, ARuleCon was evaluated on 1,492 real-world rule conversion pairs across five mainstream SIEM platforms — Splunk SPL, Microsoft Sentinel KQL, IBM QRadar AQL, Google Chronicle YARA-L, and RSA NetWitness ESA. Against bare LLM baselines using GPT-5, DeepSeek-V3, and LLaMA-3, ARuleCon consistently outperformed by around 15% on logic slot consistency and around 10% on embedding similarity and CodeBLEU. More importantly, execution success rates exceeded 90% across all target platforms — the converted rules don’t just look right, they actually run.
The framework is already being commercialized by NCS Group (Singtel Singapore’s engineering arm), and the source code is open on GitHub. The researchers’ case studies reveal something that practitioners already know intuitively but rarely quantify: the bottleneck in cross-SIEM migration is not writing the new rule from scratch — it’s understanding the source rule’s semantics well enough to know what you’re preserving, and knowing the target platform’s conventions well enough to express it correctly.
The Problem with Security Rule Migration: It’s Not Just Syntax
Most people who encounter SIEM rule migration for the first time assume it’s a straightforward translation problem — like converting between SQL dialects. It isn’t. SQL has a well-defined standard (ISO/ANSI SQL) that virtually all databases follow with minor extensions. SIEM rule languages have no such standard. Each platform was designed independently, with its own philosophical model of what a “detection” looks like.
Splunk SPL treats detection as a pipeline of transformations: filter, aggregate, threshold, in sequence, with the pipe character (|) chaining each stage. Microsoft KQL works similarly but uses different operator names (summarize instead of stats, project instead of fields) and different column naming conventions (TimeGenerated instead of _time). IBM QRadar AQL is more like traditional SQL and has a fundamental split between stateless single-event tests and stateful multi-event correlations — a distinction that doesn’t exist in Splunk or KQL and that causes conversions to silently lose temporal correlation logic.
Google Chronicle YARA-L takes a completely different approach: declarative rather than procedural, with a compact overloaded aggregate operator that simultaneously handles grouping, filtering, and thresholding in a single clause. RSA NetWitness ESA models events as streams with explicit temporal annotations. These aren’t just syntax differences — they reflect fundamentally different computational models for what “detection” means.
The paper demonstrates these problems with three concrete failure cases of naive LLM conversion. In the first, a YARA-L rule using the overloaded aggregate operator gets converted to IBM AQL by an LLM that maps it literally — producing a GROUP BY without the threshold filter, or misplacing the threshold into a WHERE clause (syntactically invalid in AQL). The 30-minute window disappears entirely. In the second, an SPL rule’s stats count by src_ip becomes a YARA-L rule that counts globally instead of per-IP — syntactically valid, semantically wrong, and completely undetectable by any text-comparison metric. In the third, Splunk’s bucket _time span=10m needs to become KQL’s bin(TimeGenerated, 10m), but the LLM doesn’t know this and leaves the time column unnamed or uses the wrong aggregation function.
| search failure
| stats dc(ip)
by user
| where count>5
| where EventID
== 4625
| summarize
dcount(ip)
by user
COUNT(*)
FROM events
WHERE action=
‘failure’
GROUP BY user
$e.name =
“LOGIN_FAIL”
match:
$e.count > 5
over 30m
SELECT * FROM
Event
.win:time(1hr)
GROUP BY ip
HAVING COUNT>5
SIEM rule conversion requires three simultaneous competencies that LLMs lack individually: (1) deep understanding of the source rule’s semantic intent, not just its syntax; (2) precise knowledge of the target vendor’s grammar and conventions, including which operators are allowed where; and (3) the ability to verify functional equivalence by actually executing both rules and comparing outputs. ARuleCon provides structured solutions to all three.
The Intermediate Representation: A Vendor-Neutral Semantic Language
The first innovation in ARuleCon is a formal Intermediate Representation (IR) — a structured, vendor-agnostic language that captures what a detection rule does without specifying how any particular SIEM expresses it. The design of this IR is where most of the domain knowledge lives.
Formally, an IR is a pair (M, S) where M is a set of metadata fields (rule_name, description, data_source, event_type) and S is an ordered list of semantic steps. Each step is a triplet:
The KEYWORD vocabulary is a predefined set of 15 vendor-agnostic functional abstractions: FILTER, EXTRACT, AGGREGATE, OUTPUT, TRANSFORM, RENAME, LOOKUP, BUCKET, JOIN, FILL, APPEND, SORT, DEDUP, APPLY, DEBUG. These map many-to-many with actual SIEM operators — a single KEYWORD can correspond to one or more concrete operators across platforms, and a single vendor operator may decompose into multiple keywords.
The key insight is that this decomposition exposes hidden structure. When the YARA-L aggregate operator — which silently handles grouping, filtering, and thresholding simultaneously — is parsed into IR, it becomes three explicit steps: a FILTER step, a grouping step, and a BUCKET/threshold step. Each step carries its full parameter set, so nothing is lost. This explicit representation makes it impossible for a downstream LLM to generate a translation that “forgets” the grouping, because the grouping is now a first-class step in the pipeline.
The IR is generated by an LLM acting as a knowledge-grounded interpreter, supplied with vendor-specific tutorials distilled from official documentation. This isn’t just free-form parsing — the model is told exactly how each platform expresses filtering, aggregation, and temporal windows, so it can correctly identify and decompose vendor-specific constructs.
Agentic RAG: Consulting the Documentation Like a Human Analyst Would
Once the IR exists, ARuleCon generates a draft target rule using a vendor-aware chain-of-thought prompt. The draft is structurally correct in broad strokes but typically contains errors in operator-level specifics: wrong aggregation function names, missing required clauses, incorrect field names for the target platform.
The second stage is an Agentic RAG reflection loop that fixes these issues by dynamically querying official vendor documentation. This is fundamentally different from standard RAG, which retrieves documents once and appends them to the prompt. Agentic RAG is iterative: the system generates a to-do list of specific optimization subtasks (operator replacement, parameter adjustment, syntax correction), and for each subtask, it iteratively generates queries, retrieves documentation evidence, evaluates whether the evidence is sufficient, and either accepts it or refines the query and tries again.
The paper’s DNS tunneling example illustrates this beautifully. When converting a Splunk SPL rule that uses bucket _time span=10m and dc(sld) to KQL, the agent first identifies “KQL time-window aggregation” and “KQL distinct count” as subtasks. The retrieval surfaces the official summarize operator documentation, which shows that bucket _time span=30m becomes bin(TimeGenerated, 30m) and dc() becomes dcount(). The agent applies these corrections and propagates the updated rule to the next subtask — all without any human intervention.
The design prevents context overflow by running each subtask in isolation. This is an important practical constraint: SIEM documentation is dense and lengthy, and dumping all of it into a single prompt context would push out the rule being converted or cause attention to scatter. By isolating subtasks, each retrieval operates on a focused context and produces precise, actionable corrections.
“This mimics how a human analyst consults manuals — continuously reformulating searches until the right tutorial or operator explanation is found.” — Xu, Wang, Guo et al. · ARuleCon · WWW ’26, Dubai
Python-Based Consistency Check: Does It Actually Do the Same Thing?
The third and most distinctive component of ARuleCon is a behavioral equivalence test that actually runs both the source and target rules and compares their outputs. This is the component that catches the subtle semantic drift that text-similarity metrics miss entirely.
The process converts both the source IR and the target rule’s derived IR into executable Python functions — one function per step — and then runs them sequentially on synthetic log data. The logs are generated to include both benign events and attack-pattern events that should trigger the detection rule. By comparing the final outputs (which IPs/users/events are flagged), the system can detect whether the converted rule is equivalent.
The paper’s concrete example makes this vivid. The SPL rule correctly groups failures by src_ip and returns [‘1.2.3.4’] for a test log where one IP has many failures. The naively converted YARA-L rule returns [‘ALL’] because it counts all failures globally without grouping. The mismatch is flagged, and the system generates a correction that adds the missing by src_ip grouping — transforming the broken version into the faithful conversion.
df = pd.DataFrame(logs)
d = df[df[“action”]
== “failure”]
grp = d.groupby(“src_ip”)
.size()
return grp[grp > 5].index
→ Output: [‘1.2.3.4’] ✓
df = pd.DataFrame(logs)
d = df[df[“action”]
== “failure”]
# BUG: global count, no grouping
return [“ALL”] if
len(d) > 5 else []
→ Output: [‘ALL’] ✗ MISMATCH
Evaluation Results: +15% Over Baseline LLMs Across All Metrics
The evaluation covers 1,492 conversion pairs across all 20 source-target direction combinations for 5 SIEM platforms. ARuleCon was tested with three state-of-the-art LLMs as backbone — GPT-5, DeepSeek-V3 (671B), and LLaMA-3 (405B) — and compared against the same models used without ARuleCon’s components.
| Conversion Direction | CodeBLEU AC | CodeBLEU BL | Embed Sim AC | Embed Sim BL | Logic Slot AC | Logic Slot BL |
|---|---|---|---|---|---|---|
| Splunk → Microsoft Sentinel | 63.7 | 58.9 | 69.3 | 63.8 | 73.2 | 67.6 |
| Splunk → Google Chronicle | 63.1 | 58.0 | 83.6 | 77.9 | 68.0 | 62.6 |
| IBM QRadar → Google Chronicle | 69.1 | 63.6 | 82.4 | 76.8 | 56.9 | 51.8 |
| Google Chronicle → RSA NetWitness | 65.1 | 59.9 | 89.6 | 84.3 | 75.2 | 69.8 |
| RSA NetWitness → IBM QRadar | 71.5 | 66.0 | 59.9 | 54.7 | 81.1 | 75.8 |
| RSA NetWitness → Google Chronicle | 67.2 | 61.7 | 64.1 | 59.0 | 78.9 | 73.4 |
Table 1: Selected GPT-5 results (AC = ARuleCon, BL = Baseline). Full results cover all 20 direction × 3 model combinations. ARuleCon consistently outperforms baseline by +5% to +15% depending on conversion direction and metric.
On average across all models: GPT-5 sees +9.1% CodeBLEU, +10.3% embedding similarity, +11.6% logic slot consistency; DeepSeek-V3 gains +8.4%, +11.1%, +13.0%; LLaMA-3 gains +9.7%, +10.8%, +12.1%. The improvements are consistent across models, confirming that ARuleCon’s gains come from its structural design rather than any one LLM’s capabilities.
IBM QRadar conversions show the largest consistency challenges — the stateless/stateful split in QRadar’s architecture creates conversion failures that aren’t easily fixed by documentation retrieval alone, because the target platform simply doesn’t have an equivalent construct. IBM AQL→Splunk Logic Slot scores are notably lower (52.2% ARuleCon vs 47.1% baseline) compared to RSA→IBM (81.1% vs 75.8%), suggesting that query-to-stream conversion is harder than stream-to-query.
Execution success rates across all target platforms with ARuleCon are consistently above 90%, reaching 100% for Google Chronicle and conversions targeting Splunk from most sources. The baseline models are notably worse on execution validity — the paper notes their performance was so poor that reporting it would be misleading.
Removing IR hurts logical consistency most (operators like aggregate and tstats are harder to decompose without structured steps). Removing Agentic RAG hurts embedding similarity most (vendor-specific operators need documentation support). Removing the Python consistency check hurts logic slot alignment most (execution validation catches missing GROUP BY and misplaced thresholds that text comparison misses). Each component contributes uniquely — the combination is necessary for best performance.
Complete Python Implementation
The following is a full, runnable end-to-end implementation of ARuleCon’s core components: IR generation and representation, draft rule synthesis, Agentic RAG simulation, and the Python-based consistency checker. The implementation is designed to be readable and extensible — real deployment would substitute live LLM API calls and an actual vector database for documentation retrieval.
# ─────────────────────────────────────────────────────────────────────────────
# ARuleCon: Agentic Security Rule Conversion
# Xu, Wang, Guo, Yu, Han, Lim, Dong, Zhang
# NUS & Fudan University · arXiv:2604.06762v1 · WWW '26 Dubai
# Complete end-to-end implementation
# Requirements: openai, pandas, numpy, json, re, dataclasses
# GitHub: https://github.com/LLM4SOC-Topic/ARuleCon
# ─────────────────────────────────────────────────────────────────────────────
import json
import re
import copy
import textwrap
from typing import List, Dict, Optional, Tuple, Any
from dataclasses import dataclass, field
import pandas as pd
import numpy as np
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 1 · Core Data Structures
# ═══════════════════════════════════════════════════════════════════════════
# The 15 vendor-agnostic KEYWORD abstractions (Section 3.1 of paper)
VALID_KEYWORDS = {
"FILTER", "EXTRACT", "AGGREGATE", "OUTPUT", "TRANSFORM",
"RENAME", "LOOKUP", "BUCKET", "JOIN", "FILL",
"APPEND", "SORT", "DEDUP", "APPLY", "DEBUG"
}
# Supported SIEM platforms
SIEM_PLATFORMS = ["splunk_spl", "microsoft_kql", "ibm_aql", "google_yara_l", "rsa_esa"]
@dataclass
class IRStep:
"""
One atomic step in the Intermediate Representation.
Eq. from paper: s_i = ⟨KEYWORD, PARAM, DESCRIPTION⟩
KEYWORD: vendor-agnostic functional abstraction
PARAM: full parameter payload preserving all source semantics
DESC: natural language explanation for LLM reasoning
"""
keyword: str
param: str
description: str
def validate(self) -> bool:
return self.keyword.upper() in VALID_KEYWORDS
def to_dict(self) -> Dict:
return {"keyword": self.keyword, "param": self.param, "description": self.description}
@dataclass
class IntermediateRepresentation:
"""
Vendor-agnostic IR schema: IR = ⟨M, S⟩
M = metadata {rule_name, description, data_source, event_type}
S = ordered list of IRStep objects
"""
rule_name: str
description: str
data_source: str
event_type: str
steps: List[IRStep] = field(default_factory=list)
def to_dict(self) -> Dict:
return {
"metadata": {
"rule_name": self.rule_name,
"description": self.description,
"data_source": self.data_source,
"event_type": self.event_type,
},
"steps": [s.to_dict() for s in self.steps]
}
def to_json(self) -> str:
return json.dumps(self.to_dict(), indent=2)
@classmethod
def from_dict(cls, d: Dict) -> 'IntermediateRepresentation':
meta = d.get("metadata", {})
steps = [IRStep(**s) for s in d.get("steps", [])]
return cls(
rule_name=meta.get("rule_name", ""),
description=meta.get("description", ""),
data_source=meta.get("data_source", ""),
event_type=meta.get("event_type", ""),
steps=steps
)
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 2 · LLM Interface (stub — replace with real API)
# ═══════════════════════════════════════════════════════════════════════════
class LLMClient:
"""
LLM interface stub. Replace with real OpenAI / DeepSeek / LLaMA calls.
In production:
from openai import OpenAI
client = OpenAI(api_key="...")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0.3, top_p=0.9, max_tokens=1024
)
return response.choices[0].message.content
Paper uses temperature=0.3, top_p=0.9, max_tokens=1024 for all models.
"""
def __init__(self, model: str = "gpt-5"):
self.model = model
def complete(self, prompt: str, system: str = "") -> str:
"""Call LLM and return text response."""
# STUB: in production, call real API
print(f" [LLM {self.model}] Processing {len(prompt)} chars...")
return "[LLM response would appear here in production]"
def complete_json(self, prompt: str, system: str = "") -> Dict:
"""Call LLM and parse JSON response."""
raw = self.complete(prompt, system)
# Strip markdown code fences if present
raw = re.sub(r'```(?:json)?\s*|\s*```', '', raw).strip()
try:
return json.loads(raw)
except json.JSONDecodeError:
return {}
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 3 · IR Generation: Source Rule → Vendor-Agnostic IR
# ═══════════════════════════════════════════════════════════════════════════
# Vendor documentation summaries (distilled tutorials for IR parsing)
VENDOR_TUTORIALS = {
"splunk_spl": """
Splunk SPL uses pipe (|) chaining. Key operators:
- search/where: filtering (FILTER keyword)
- stats count/dc/avg by field: aggregation (AGGREGATE keyword)
- bucket _time span=Xm: time windowing (BUCKET keyword)
- lookup: enrichment (LOOKUP keyword)
- eval: field computation (TRANSFORM keyword)
- fields/table: output selection (OUTPUT keyword)
- rename: field renaming (RENAME keyword)
- sort: sorting (SORT keyword)
- dedup: deduplication (DEDUP keyword)
Subsearch: [ search ... ] embeds a query as a filter.
""",
"microsoft_kql": """
KQL uses pipe chaining. Key operators:
- where: filtering (FILTER keyword)
- summarize f() by col, bin(TimeGenerated, Xm): aggregation+window (AGGREGATE+BUCKET)
- project: field selection (OUTPUT keyword)
- extend: new fields (TRANSFORM keyword)
- join: joining tables (JOIN keyword)
- sort by: sorting (SORT keyword)
- distinct: deduplication (DEDUP keyword)
Time column: TimeGenerated. Distinct count: dcount().
""",
"ibm_aql": """
IBM AQL is SQL-like. Key clauses:
- WHERE: filtering (FILTER keyword)
- GROUP BY + HAVING COUNT(*) > N: aggregation+threshold (AGGREGATE keyword)
- SELECT columns: output (OUTPUT keyword)
- .win:time(Xs): time window via EPL-style stream (BUCKET keyword)
- LEFT JOIN: joining (JOIN keyword)
IMPORTANT: QRadar separates stateless (single-event) and stateful (multi-event) tests.
Stateful correlations use .win:time() or WITHIN intervals.
""",
"google_yara_l": """
YARA-L 2.0 is declarative. Key sections:
- rule NAME { meta: events: match: condition: outcome: }
- events: $var.field = "value": per-event filtering (FILTER keyword)
- match: $var1.key = $var2.key over Xm: multi-event correlation (JOIN+BUCKET)
- condition: count($var) by $var.field >= N: threshold (AGGREGATE keyword)
- outcome: result fields (OUTPUT keyword)
The aggregate operator is OVERLOADED — it handles grouping, filtering, AND thresholding.
Always decompose aggregate into separate FILTER + BUCKET + AGGREGATE IR steps.
""",
"rsa_esa": """
RSA ESA uses CEP (Complex Event Processing) with EPL.
- SELECT fields FROM Event: field selection (OUTPUT keyword)
- WHERE condition: filtering (FILTER keyword)
- .win:time(Xmin): sliding time window (BUCKET keyword)
- GROUP BY field HAVING COUNT(*) > N: aggregation+threshold (AGGREGATE keyword)
- @RSAAlert: alert annotation triggers on rule match
""",
}
class IRGenerator:
"""
Parses a source SIEM rule into vendor-agnostic Intermediate Representation.
The LLM acts as a knowledge-grounded interpreter: it is supplied with
vendor-specific tutorials so it can correctly identify and decompose
vendor-specific constructs into generic IR steps.
"""
def __init__(self, llm: LLMClient):
self.llm = llm
def _build_ir_prompt(self, source_rule: str, source_platform: str) -> str:
"""Construct the IR extraction prompt with vendor tutorial context."""
tutorial = VENDOR_TUTORIALS.get(source_platform, "")
return f"""You are a security analyst specializing in SIEM rule analysis.
## Platform: {source_platform.upper()}
## Platform Tutorial:
{tutorial}
## Valid IR Keywords:
{', '.join(sorted(VALID_KEYWORDS))}
## Task:
Parse the following SIEM rule into a vendor-agnostic Intermediate Representation (IR).
The IR must:
1. Capture ALL semantic details (thresholds, time windows, grouping keys, field names)
2. Decompose overloaded operators into multiple explicit steps
3. Use only the valid IR keywords listed above
4. Preserve EVERY parameter from the source rule
## Source Rule:
```
{source_rule}
```
## Output format (JSON):
{{
"metadata": {{
"rule_name": "descriptive name",
"description": "what this rule detects",
"data_source": "log source type",
"event_type": "event category"
}},
"steps": [
{{"keyword": "FILTER", "param": "field = value", "description": "Filter to X events"}},
{{"keyword": "AGGREGATE", "param": "count() > 5 by src_ip", "description": "Count failures per IP"}},
...
]
}}
Output ONLY the JSON object, no explanation."""
def generate(self, source_rule: str, source_platform: str) -> IntermediateRepresentation:
"""Parse source rule into IR."""
prompt = self._build_ir_prompt(source_rule, source_platform)
ir_dict = self.llm.complete_json(prompt)
if not ir_dict:
# Return a minimal IR on parse failure
return IntermediateRepresentation(
rule_name="parse_error", description="IR generation failed",
data_source="unknown", event_type="unknown"
)
ir = IntermediateRepresentation.from_dict(ir_dict)
# Validate all keywords
ir.steps = [s for s in ir.steps if s.validate()]
return ir
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 4 · Draft Rule Generation
# ═══════════════════════════════════════════════════════════════════════════
class DraftGenerator:
"""
Generates an initial target rule draft from the IR using vendor-aware CoT prompting.
The draft preserves IR semantics and is structurally correct, but may contain
operator-level errors that Agentic RAG will fix in the next stage.
Prompt structure matches Table 6 in the paper.
"""
# Vendor-specific few-shot examples
FEW_SHOT_EXAMPLES = {
"splunk_spl": "index=auth action=failure | stats count by src_ip | where count > 5",
"microsoft_kql":"SecurityEvent | where ActionType == \"failure\" | summarize count() by src_ip | where count_ > 5",
"ibm_aql": "SELECT src_ip, COUNT(*) FROM events WHERE action='failure' GROUP BY src_ip HAVING COUNT(*) > 5",
"google_yara_l":"rule brute_force { events: $e.action = \"failure\" condition: count($e) by $e.src_ip >= 5 }",
"rsa_esa": "@RSAAlert SELECT src_ip FROM Event.win:time(30 min) WHERE action='failure' GROUP BY src_ip HAVING COUNT(*) > 5",
}
def __init__(self, llm: LLMClient):
self.llm = llm
def _build_draft_prompt(self, ir: IntermediateRepresentation, target_platform: str) -> str:
"""Vendor-aware CoT prompt matching paper's Table 6."""
example = self.FEW_SHOT_EXAMPLES.get(target_platform, "")
ir_json = ir.to_json()
return f"""You are a security analyst specializing in writing and optimizing {target_platform} rules for threat detection.
## Task:
Convert the following Intermediate Representation (IR) into a syntactically valid {target_platform} rule.
## Input IR:
{ir_json}
## Reasoning Steps (Chain-of-Thought):
1. Identify relevant event sources from metadata.data_source
2. Map IR keywords to equivalent operators in {target_platform}
3. Apply parameters (param) precisely WITHOUT loss — preserve all thresholds, time windows, and grouping keys
4. Verify temporal windows, aggregations, and thresholds are correctly expressed
5. Construct a rule that is both syntactically correct and semantically faithful
6. Validate against vendor grammar before final output
## Platform Tutorial:
{VENDOR_TUTORIALS.get(target_platform, '')}
## Example {target_platform} rule for reference:
{example}
## Output:
A single {target_platform} detection rule (wrapped in ```rule...``` code block).
Do NOT omit any parameters from the IR."""
def generate(self, ir: IntermediateRepresentation, target_platform: str) -> str:
"""Generate target rule draft from IR."""
prompt = self._build_draft_prompt(ir, target_platform)
raw = self.llm.complete(prompt)
# Extract code block content if present
match = re.search(r'```(?:\w+)?\s*(.*?)\s*```', raw, re.DOTALL)
if match:
return match.group(1).strip()
return raw.strip()
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 5 · Agentic RAG Reflection
# ═══════════════════════════════════════════════════════════════════════════
class VendorDocumentationDB:
"""
Simulates the vendor documentation corpus D_V.
In production: Chroma vector store with text-embedding-ada-002 embeddings
of official vendor documentation, hierarchically chunked by section.
Top-5 most relevant passages retrieved per query.
"""
DOCS = {
"microsoft_kql": {
"time_window": "KQL time binning: use bin(TimeGenerated, Xm) inside summarize. Example: summarize count() by bin(TimeGenerated, 10m). The time column is always TimeGenerated, NOT _time.",
"distinct_count": "KQL distinct count: use dcount(field). Example: summarize dcount(src_ip). NOT dc() or COUNT(DISTINCT).",
"aggregation": "KQL aggregation: use summarize func() by field1, field2. Post-aggregation filter: | where count_ > N.",
"field_selection": "KQL field selection: use project field1, field2. Equivalent to SPL fields/table.",
"list_values": "KQL collect values: use make_set(field). Equivalent to SPL values().",
},
"splunk_spl": {
"time_window": "SPL time windowing: use | bucket _time span=Xm before | stats. Example: | bucket _time span=10m | stats count by src_ip, _time.",
"aggregation": "SPL aggregation: | stats count(field) by group_key. Then filter: | where count > N.",
"distinct_count": "SPL distinct count: dc(field) in stats. Example: | stats dc(src_ip) by user.",
"subsearch": "SPL subsearch: [ search ... | fields key_field ] used as a filter in parent search.",
},
"ibm_aql": {
"time_window": "AQL time window: table_name.win:time(X seconds). Example: events.win:time(1800) for 30 minutes.",
"aggregation": "AQL threshold: HAVING COUNT(*) > N (NOT WHERE COUNT > N - WHERE is pre-aggregation only).",
"stateful": "AQL stateful: use .std:groupwin() for grouped time windows. Multi-event rules require EPL patterns.",
},
"google_yara_l": {
"aggregate": "YARA-L aggregate is OVERLOADED. Decompose into: events: (filtering) + match: (grouping + window) + condition: count() by field >= N.",
"multi_event": "YARA-L multi-event: declare both $e1 and $e2 in events:, then correlate in match: $e1.src.ip = $e2.src.ip over Xm.",
"outcome": "YARA-L outcome: list fields to include in alert. Example: outcome: $e.src.ip, $e.target.user.",
},
"rsa_esa": {
"time_window": "RSA ESA time: .win:time(X min) appended to FROM clause. Example: FROM Event.win:time(30 min).",
"alert": "RSA ESA alert: prefix rule with @RSAAlert annotation. Required for all detection rules.",
}
}
def retrieve(self, query: str, platform: str, top_k: int = 3) -> List[str]:
"""
Retrieve top-k relevant documentation passages.
In production: cosine similarity search in Chroma using text-embedding-ada-002.
"""
platform_docs = self.DOCS.get(platform, {})
if not platform_docs: return []
# Simple keyword matching (production uses dense vector retrieval)
query_lower = query.lower()
scored = []
for key, doc in platform_docs.items():
score = sum(1 for word in query_lower.split() if word in doc.lower())
scored.append((score, doc))
scored.sort(key=lambda x: x[0], reverse=True)
return [doc for _, doc in scored[:top_k] if _ > 0]
@dataclass
class RAGSubtask:
"""One subtask in the to-do list T = ⟨t_1, ..., t_m⟩"""
goal: str # optimization goal description
category: str # e.g., "operator_replacement", "syntax_correction"
class AgenticRAGReflector:
"""
Implements the Agentic RAG reflection loop (Section 3.2.2).
For each subtask t_i in T:
1. Generate query q_i for vendor documentation D_V
2. Retrieve evidence E_i
3. Judge: sufficient? → apply / reject and refine
4. Apply update: R_draft^(i) = Apply(R_draft^(i-1), E*)
Max N=3 retrieval iterations per subtask (from paper's Appendix C.1)
"""
MAX_RETRIEVAL_ITERS = 3
def __init__(self, llm: LLMClient, doc_db: VendorDocumentationDB):
self.llm = llm
self.doc_db = doc_db
def gen_todo_list(self, draft_rule: str, ir: IntermediateRepresentation, target: str) -> List[RAGSubtask]:
"""
Generate an ordered list of optimization subtasks from the draft rule.
T = GenTodo(R_draft, IR)
"""
prompt = f"""Analyze this {target} draft rule against the IR and list specific issues to fix.
## IR (source logic):
{ir.to_json()}
## Draft rule:
{draft_rule}
## Output: JSON list of subtasks, each with "goal" and "category"
Categories: operator_replacement | syntax_correction | field_remap | threshold_fix | temporal_fix | schema_alignment
Example: [{{"goal": "Replace dc() with dcount()", "category": "operator_replacement"}}]"""
result = self.llm.complete_json(prompt)
if isinstance(result, list):
return [RAGSubtask(**t) for t in result if "goal" in t]
return []
def _retrieve_with_retry(self, subtask: RAGSubtask, draft: str,
ir: IntermediateRepresentation, target: str) -> List[str]:
"""
Iterative retrieval loop for one subtask.
Refines query until evidence is judged sufficient (accept) or max iters reached.
"""
query = subtask.goal
for j in range(self.MAX_RETRIEVAL_ITERS):
evidence = self.doc_db.retrieve(query, target)
if evidence:
# Judge sufficiency: does evidence address the goal?
judge_prompt = f"""Does this documentation evidence sufficiently address the goal: "{subtask.goal}"?
Evidence:
{chr(10).join(evidence)}
Answer: "accept" if yes, "reject: [refined query]" if no."""
judgment = self.llm.complete(judge_prompt).strip().lower()
if judgment.startswith("accept"):
return evidence
# Refine query and try again
if "reject:" in judgment:
query = judgment.split("reject:", 1)[1].strip()
return evidence # Return best evidence after max iters
def reflect(self, draft_rule: str, ir: IntermediateRepresentation, target: str) -> str:
"""
Full Agentic RAG reflection loop.
Returns refined rule R_opt after all subtasks are processed.
"""
# Step 1: Generate to-do list
todo_list = self.gen_todo_list(draft_rule, ir, target)
if not todo_list:
print(" [RAG] No subtasks identified, draft appears clean.")
return draft_rule
print(f" [RAG] {len(todo_list)} subtasks: {[t.goal for t in todo_list]}")
current_rule = draft_rule
# Step 2: Execute each subtask in isolated context
for i, subtask in enumerate(todo_list):
print(f" [RAG] Subtask {i+1}/{len(todo_list)}: {subtask.goal}")
# Retrieve vendor documentation evidence
evidence = self._retrieve_with_retry(subtask, current_rule, ir, target)
if not evidence:
print(f" [RAG] No evidence found for subtask {i+1}, skipping.")
continue
# Apply correction guided by evidence
apply_prompt = f"""You are fixing a {target} SIEM rule.
## Subtask: {subtask.goal}
## Category: {subtask.category}
## Vendor Documentation Evidence:
{chr(10).join(f"- {e}" for e in evidence)}
## Current rule:
{current_rule}
## Original IR (reference for intended semantics):
{ir.to_json()}
Apply ONLY the fix for this specific subtask. Output the corrected rule in a code block."""
raw = self.llm.complete(apply_prompt)
match = re.search(r'```(?:\w+)?\s*(.*?)\s*```', raw, re.DOTALL)
if match:
current_rule = match.group(1).strip()
return current_rule
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 6 · Python-Based Consistency Check (Algorithm 1)
# ═══════════════════════════════════════════════════════════════════════════
class TestLogGenerator:
"""
Generates synthetic log data L = L_normal ∪ L_attack
based on the IR semantics of the source rule.
"""
def generate(self, ir: IntermediateRepresentation, n_normal: int = 50, n_attack: int = 30) -> List[Dict]:
"""
Generate realistic test logs based on IR step parameters.
Attack logs are designed to trigger the detection rule.
Normal logs are benign and should not trigger it.
"""
logs = []
# Extract key parameters from IR steps
filter_field, filter_value = "action", "failure"
group_key = "src_ip"
threshold = 5
attack_ip = "192.168.1.100"
for step in ir.steps:
param_lower = step.param.lower()
if step.keyword == "FILTER" and "=" in step.param:
parts = step.param.split("=", 1)
if len(parts) == 2:
filter_field = parts[0].strip().split(".")[-1]
filter_value = parts[1].strip().strip('"\'')
elif step.keyword == "AGGREGATE" and "by" in param_lower:
m = re.search(r'by\s+(\S+)', param_lower)
if m:
group_key = m.group(1).strip()
m2 = re.search(r'>\s*(\d+)', step.param)
if m2:
threshold = int(m2.group(1))
# Generate attack logs (triggering IP exceeds threshold)
for i in range(threshold + 3):
logs.append({
filter_field: filter_value,
group_key: attack_ip,
"timestamp": f"2024-01-01T10:{i:02d}:00Z",
"user": "admin",
"status": "401"
})
# Add some failures from a benign IP (below threshold)
for i in range(max(1, threshold - 2)):
logs.append({
filter_field: filter_value,
group_key: "10.0.0.50",
"timestamp": f"2024-01-01T10:{i+30:02d}:00Z",
"user": "bob",
"status": "401"
})
# Normal events (no failures)
for i in range(n_normal):
logs.append({
filter_field: "success",
group_key: f"192.168.1.{i % 200 + 1}",
"timestamp": f"2024-01-01T11:{i % 60:02d}:00Z",
"user": f"user{i}",
"status": "200"
})
return logs
class PythonIRExecutor:
"""
Converts IR steps into Python code blocks and executes them sequentially.
This implements the compositional pipeline f_1 ∘ f_2 ∘ ... ∘ f_n applied to L.
Each step produces output that becomes input for the next step.
"""
# Python code templates for each IR keyword
CODE_TEMPLATES = {
"FILTER": """
# FILTER: {param}
def step_filter(data, **kw):
import pandas as pd
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
parts = '{param}'.replace('"', '').replace("'", '').split('=', 1)
if len(parts) == 2:
col = parts[0].strip().split('.')[-1]
val = parts[1].strip()
if col in df.columns:
df = df[df[col].astype(str) == val]
return df
""",
"AGGREGATE": """
# AGGREGATE: {param}
def step_aggregate(data, **kw):
import pandas as pd, re
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
param = '{param}'
by_match = re.search(r'by\s+(\S+)', param)
thresh_match = re.search(r'>\s*(\d+)', param)
threshold = int(thresh_match.group(1)) if thresh_match else 0
if by_match:
group_col = by_match.group(1).strip()
if group_col in df.columns:
counts = df.groupby(group_col).size().reset_index(name='__count')
result = counts[counts['__count'] > threshold][group_col].tolist()
return result
return []
""",
"BUCKET": """
# BUCKET (time window): {param}
def step_bucket(data, **kw):
import pandas as pd, re
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
m = re.search(r'(\d+)\s*m', '{param}')
window_min = int(m.group(1)) if m else 30
if 'timestamp' in df.columns:
df['timestamp'] = pd.to_datetime(df['timestamp'], errors='coerce')
df = df.dropna(subset=['timestamp'])
df['time_bucket'] = df['timestamp'].dt.floor(f'{window_min}min')
return df
""",
"OUTPUT": """
# OUTPUT: {param}
def step_output(data, **kw):
import pandas as pd
if isinstance(data, pd.DataFrame):
fields = [f.strip() for f in '{param}'.split(',')]
fields = [f for f in fields if f in data.columns]
return data[fields].to_dict('records') if fields else data.to_dict('records')
return data
""",
"TRANSFORM": """
# TRANSFORM: {param}
def step_transform(data, **kw):
import pandas as pd
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
# Passthrough for now — param: {param}
return df
""",
"LOOKUP": """
# LOOKUP: {param}
def step_lookup(data, **kw):
# Enrich with external lookup (simulated passthrough) — param: {param}
return data
""",
"SORT": """
# SORT: {param}
def step_sort(data, **kw):
import pandas as pd
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
col = '{param}'.split()[-1] if '{param}' else None
if col and col in df.columns:
df = df.sort_values(col)
return df
""",
"DEDUP": """
# DEDUP: {param}
def step_dedup(data, **kw):
import pandas as pd
df = pd.DataFrame(data) if not isinstance(data, pd.DataFrame) else data
cols = [c.strip() for c in '{param}'.split(',') if c.strip() in df.columns]
if cols:
df = df.drop_duplicates(subset=cols)
return df
""",
}
DEFAULT_TEMPLATE = """
# {keyword}: {param}
def step_{keyword_lower}(data, **kw):
return data # passthrough for unimplemented keyword
"""
def generate_python_for_step(self, step: IRStep, llm: Optional[LLMClient] = None) -> str:
"""Generate Python function for one IR step."""
template = self.CODE_TEMPLATES.get(
step.keyword.upper(),
self.DEFAULT_TEMPLATE
)
return template.format(
param=step.param.replace("'", "\\'"),
keyword=step.keyword.upper(),
keyword_lower=step.keyword.lower()
)
def execute_ir(self, ir: IntermediateRepresentation, logs: List[Dict]) -> Any:
"""
Execute IR as a sequential Python pipeline over test logs.
Each step's output becomes the next step's input.
Returns final detection output.
"""
data = logs
for i, step in enumerate(ir.steps):
code = self.generate_python_for_step(step)
try:
local_ns = {}
exec(code, local_ns)
func_name = [k for k in local_ns if k.startswith("step_")][0]
data = local_ns[func_name](data)
except Exception as e:
print(f" [Executor] Step {i} ({step.keyword}) error: {e}")
return data
class ConsistencyChecker:
"""
Python-based consistency check implementing Algorithm 1.
Verifies semantic equivalence between source and target rules
by running both over synthetic test logs and comparing outputs.
If mismatch Δ = O_S △ O_T detected:
- Analyze discrepancy type (missing GROUP BY, wrong threshold, etc.)
- Generate optimization suggestions for R_T
- Up to K=5 fix attempts
"""
MAX_FIX_ATTEMPTS = 5
def __init__(self, llm: LLMClient, ir_generator: IRGenerator):
self.llm = llm
self.ir_gen = ir_generator
self.executor = PythonIRExecutor()
self.log_gen = TestLogGenerator()
def normalize_output(self, output: Any) -> set:
"""Normalize pipeline outputs for comparison."""
if isinstance(output, list):
if all(isinstance(x, dict) for x in output):
return frozenset(frozenset(d.items()) for d in output)
return frozenset(str(x) for x in output)
elif hasattr(output, 'to_dict'): # DataFrame
rows = output.to_dict('records')
return frozenset(frozenset(d.items()) for d in rows)
return frozenset([str(output)])
def compute_similarity(self, o_source: Any, o_target: Any) -> float:
"""Compute Jaccard similarity between source and target outputs."""
s = self.normalize_output(o_source)
t = self.normalize_output(o_target)
if not s and not t: return 1.0
if not s or not t: return 0.0
intersection = len(s & t)
union = len(s | t)
return intersection / union if union > 0 else 0.0
def analyze_mismatch(self, o_source: Any, o_target: Any,
ir_source: IntermediateRepresentation,
target_rule: str) -> str:
"""Generate optimization suggestions for detected semantic mismatch."""
prompt = f"""Analyze the semantic mismatch between source and target rule outputs.
## Source IR logic:
{ir_source.to_json()}
## Source rule output (CORRECT):
{repr(o_source)}
## Target rule output (INCORRECT):
{repr(o_target)}
## Target rule (needs fixing):
{target_rule}
Identify the root cause of the mismatch (e.g., missing GROUP BY, wrong threshold placement,
omitted time window, incorrect field name). Suggest a specific fix."""
return self.llm.complete(prompt)
def check_and_fix(self,
source_ir: IntermediateRepresentation,
target_rule: str,
target_platform: str) -> Tuple[str, float, str]:
"""
Full consistency check + iterative repair loop.
Algorithm 1:
1. Generate test logs L from IR_S
2. Derive target IR: IR_T = DeriveIR(Rule_T)
3. Execute IR_S and IR_T over L → O_S, O_T
4. Compare: diffs = O_S △ O_T
5. If diffs: suggest → optimize R_T → repeat up to K times
Returns:
(final_rule, semantic_score, status_message)
"""
# Step 1: Generate test logs
logs = self.log_gen.generate(source_ir)
print(f" [PyCheck] Generated {len(logs)} test log entries")
# Step 2: Execute source IR pipeline
o_source = self.executor.execute_ir(source_ir, logs)
current_rule = target_rule
best_score = 0.0
best_rule = target_rule
for attempt in range(self.MAX_FIX_ATTEMPTS):
# Step 3: Derive target IR and execute
target_ir = self.ir_gen.generate(current_rule, target_platform)
o_target = self.executor.execute_ir(target_ir, logs)
# Step 4: Compare outputs
score = self.compute_similarity(o_source, o_target)
print(f" [PyCheck] Attempt {attempt+1}: semantic similarity = {score:.3f}")
if score > best_score:
best_score = score
best_rule = current_rule
if score >= 0.95: # sufficient equivalence
print(f" [PyCheck] Equivalence achieved (score={score:.3f})")
return best_rule, best_score, "PASS"
# Step 5: Analyze mismatch and generate fix
suggestions = self.analyze_mismatch(o_source, o_target, source_ir, current_rule)
print(f" [PyCheck] Mismatch detected. Applying fix: {suggestions[:80]}...")
# Apply fix
fix_prompt = f"""Fix this {target_platform} rule based on the suggestions.
## Rule to fix:
{current_rule}
## Optimization suggestions:
{suggestions}
Output the corrected rule only (in a code block)."""
raw = self.llm.complete(fix_prompt)
match = re.search(r'```(?:\w+)?\s*(.*?)\s*```', raw, re.DOTALL)
if match:
current_rule = match.group(1).strip()
msg = "PARTIAL" if best_score > 0.5 else "FAIL"
return best_rule, best_score, msg
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 7 · Full ARuleCon Pipeline
# ═══════════════════════════════════════════════════════════════════════════
class ARuleCon:
"""
Full agentic SIEM rule conversion pipeline.
Stages:
1. IR Generation: parse source rule into vendor-agnostic IR
2. Draft Generation: LLM generates target rule from IR
3. Agentic RAG Reflection: iterative documentation-guided refinement
4. Python Consistency Check: behavioral equivalence verification + repair
Paper results: +15% over baseline LLMs on 1,492 conversion pairs
"""
def __init__(self, llm: LLMClient):
doc_db = VendorDocumentationDB()
self.ir_gen = IRGenerator(llm)
self.draft_gen = DraftGenerator(llm)
self.rag = AgenticRAGReflector(llm, doc_db)
self.py_check = ConsistencyChecker(llm, self.ir_gen)
def convert(self,
source_rule: str,
source_platform: str,
target_platform: str,
verbose: bool = True) -> Dict:
"""
Convert a SIEM rule from source_platform to target_platform.
Args:
source_rule: the original SIEM rule text
source_platform: one of SIEM_PLATFORMS
target_platform: one of SIEM_PLATFORMS
verbose: print progress information
Returns:
dict with keys: ir, draft, refined, final, semantic_score, status
"""
if source_platform not in SIEM_PLATFORMS:
raise ValueError(f"Unknown source platform: {source_platform}")
if target_platform not in SIEM_PLATFORMS:
raise ValueError(f"Unknown target platform: {target_platform}")
results = {}
# ── Stage 1: IR Generation ────────────────────────────────────────────
if verbose: print(f"\n[Stage 1] Generating IR from {source_platform} rule...")
ir = self.ir_gen.generate(source_rule, source_platform)
results["ir"] = ir
if verbose:
print(f" IR: {len(ir.steps)} steps extracted")
for i, s in enumerate(ir.steps):
print(f" [{i+1}] {s.keyword}: {s.param[:60]}...")
# ── Stage 2: Draft Generation ─────────────────────────────────────────
if verbose: print(f"\n[Stage 2] Generating {target_platform} draft rule...")
draft = self.draft_gen.generate(ir, target_platform)
results["draft"] = draft
if verbose: print(f" Draft ({len(draft)} chars): {draft[:80]}...")
# ── Stage 3: Agentic RAG Reflection ──────────────────────────────────
if verbose: print(f"\n[Stage 3] Running Agentic RAG reflection...")
refined = self.rag.reflect(draft, ir, target_platform)
results["refined"] = refined
if verbose: print(f" Refined rule: {refined[:80]}...")
# ── Stage 4: Python Consistency Check ────────────────────────────────
if verbose: print(f"\n[Stage 4] Running Python-based consistency check...")
final, score, status = self.py_check.check_and_fix(ir, refined, target_platform)
results["final"] = final
results["semantic_score"] = score
results["status"] = status
if verbose:
print(f"\n{'='*60}")
print(f"CONVERSION COMPLETE: {source_platform} → {target_platform}")
print(f" Semantic score: {score:.3f}")
print(f" Status: {status}")
print(f" Final rule preview: {final[:120]}...")
print(f"{'='*60}")
return results
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 8 · Batch Evaluation + Metrics
# ═══════════════════════════════════════════════════════════════════════════
class RuleEvaluator:
"""
Computes the three evaluation metrics from the paper:
1. CodeBLEU: structural/lexical alignment (requires Python-equivalent translation)
2. Embedding Similarity: semantic similarity via cosine distance
3. Logic Slot Consistency: preservation of predicates, windows, thresholds
"""
def logic_slot_consistency(self, source_ir: IntermediateRepresentation,
target_ir: IntermediateRepresentation) -> float:
"""
Compute Logic Slot Consistency score.
Extracts semantic slots (predicates, thresholds, windows, groupings)
from both IRs and computes token-overlap Jaccard similarity.
"""
def extract_slots(ir: IntermediateRepresentation) -> set:
slots = set()
for step in ir.steps:
# Normalize and tokenize param values
tokens = re.findall(r'\b[\w.]+\b', step.param.lower())
for tok in tokens:
slots.add(f"{step.keyword.upper()}:{tok}")
# Extract numeric thresholds
nums = re.findall(r'\d+', step.param)
for n in nums:
slots.add(f"THRESH:{n}")
return slots
source_slots = extract_slots(source_ir)
target_slots = extract_slots(target_ir)
if not source_slots or not target_slots:
return 0.0
intersection = source_slots & target_slots
union = source_slots | target_slots
return len(intersection) / len(union)
def embedding_similarity(self, source_text: str, target_text: str) -> float:
"""
Compute cosine similarity between rule texts.
In production: use text-embedding-ada-002 dense vectors.
Here: simple token overlap as proxy.
"""
s_tokens = set(re.findall(r'\b\w+\b', source_text.lower()))
t_tokens = set(re.findall(r'\b\w+\b', target_text.lower()))
if not s_tokens or not t_tokens: return 0.0
intersection = s_tokens & t_tokens
return len(intersection) / max(len(s_tokens), len(t_tokens))
def evaluate_batch(self,
source_rules: List[str],
converted_rules: List[str],
source_irs: List[IntermediateRepresentation],
target_irs: List[IntermediateRepresentation]) -> Dict:
"""Compute aggregate evaluation metrics over a batch of conversions."""
emb_scores, slot_scores = [], []
for src, tgt, sir, tir in zip(source_rules, converted_rules, source_irs, target_irs):
emb_scores.append(self.embedding_similarity(src, tgt))
slot_scores.append(self.logic_slot_consistency(sir, tir))
return {
"embedding_similarity": np.mean(emb_scores) * 100,
"logic_slot_consistency": np.mean(slot_scores) * 100,
"n_samples": len(source_rules),
}
# ═══════════════════════════════════════════════════════════════════════════
# SECTION 9 · Main Entry Point
# ═══════════════════════════════════════════════════════════════════════════
def demo_motivating_examples():
"""
Demonstrate the three motivating failure cases from the paper (Section 2.2).
Shows what ARuleCon fixes vs. naive LLM translation.
"""
print("=" * 70)
print("ARuleCon: Motivating Failure Case Demonstrations")
print("=" * 70)
# Case 1: YARA-L overloaded aggregate → IBM AQL
print("\n[Case 1] YARA-L aggregate operator (overloaded) → IBM QRadar AQL")
yara_rule = """
events:
filter: event.type = "login_failure"
aggregate: count() > 5 by src_ip within 30m
"""
naive_aql = """
SELECT src_ip, COUNT(*)
FROM events
WHERE event_type = 'login_failure' AND COUNT(*) > 5
GROUP BY src_ip, log_source_time
"""
correct_aql = """
SELECT src_ip
FROM events.win:time(30 min)
WHERE event_type = 'login_failure'
GROUP BY src_ip
HAVING COUNT(*) > 5
"""
print(f" Source YARA-L:\n{yara_rule.strip()}")
print(f" Naive LLM (WRONG): COUNT(*) > 5 in WHERE clause (syntactically invalid AQL)")
print(f" ARuleCon (CORRECT): {correct_aql.strip()}")
print(f" IR decomposition would produce:")
ir_yara = IntermediateRepresentation(
rule_name="brute_force_login", description="Detect IPs with > 5 login failures in 30m",
data_source="auth_logs", event_type="login_event",
steps=[
IRStep("FILTER", 'event.type = "login_failure"', "Filter to login failure events"),
IRStep("BUCKET", "within 30m", "30-minute sliding time window"),
IRStep("AGGREGATE", "count() > 5 by src_ip", "Count failures per src_ip, threshold 5"),
IRStep("OUTPUT", "src_ip", "Return suspicious source IPs")
]
)
for s in ir_yara.steps:
print(f" {s.keyword}: {s.param}")
# Case 2: SPL src_ip grouping missing in YARA-L translation
print("\n[Case 2] SPL grouping semantics → YARA-L (silent error)")
spl_rule = "index=auth action=failure | stats count by src_ip | where count > 5"
wrong_yara = """events:\n filter: action = "failure"\n aggregate: count() > 5"""
right_yara = """events:\n filter: action = "failure"\n aggregate: count() > 5 by src_ip"""
print(f" Source SPL: {spl_rule}")
print(f" Wrong YARA-L: counts globally → ['ALL'] when any IP fails 5+ times")
print(f" Correct YARA-L: counts per src_ip → ['1.2.3.4'] for attacker IP only")
print(f" Python check: source outputs ['1.2.3.4'], wrong target outputs ['ALL'] → MISMATCH detected")
# Case 3: Temporal window conversion SPL→KQL
print("\n[Case 3] Temporal window and distinct-count operator mapping SPL → KQL")
spl_dns = "index=dns | eval tld=... | bucket _time span=10m | stats dc(sld) as sld_cnt by host, _time | where sld_cnt >= 3"
kql_dns = "DnsEvents | extend SLD=... | summarize sld_cnt=dcount(SLD) by Computer, bin(TimeGenerated, 10m) | where sld_cnt >= 3"
print(f" SPL: bucket _time span=10m + dc(sld)")
print(f" KQL: bin(TimeGenerated, 10m) + dcount(SLD) — RAG retrieval maps both correctly")
print(f" Key: Agentic RAG queries 'KQL time-window aggregation' and 'KQL distinct count'")
print(f" then retrieves official docs showing: dc()→dcount(), _time→TimeGenerated")
def main():
"""
End-to-end ARuleCon demonstration.
In production: replace LLMClient stub with real OpenAI/DeepSeek/LLaMA calls.
Temperature=0.3, top_p=0.9, max_tokens=1024 (paper settings).
"""
print("=" * 70)
print("ARuleCon: Agentic Security Rule Conversion")
print("Xu, Wang, Guo et al. · NUS & Fudan University · arXiv:2604.06762v1")
print("WWW '26, Dubai, UAE · GitHub: github.com/LLM4SOC-Topic/ARuleCon")
print("=" * 70)
# Show motivating examples
demo_motivating_examples()
# Run full pipeline demo
print("\n" + "=" * 70)
print("Full ARuleCon Pipeline Demo: SPL → KQL")
print("=" * 70)
llm = LLMClient(model="gpt-5")
arulecon = ARuleCon(llm)
source_spl = """
index=auth sourcetype=auth_logs action=failure
| bucket _time span=10m
| stats count as fail_cnt, dc(src_ip) as unique_ips by user, _time
| where fail_cnt >= 10 AND unique_ips >= 3
| table user, fail_cnt, unique_ips, _time
"""
print(f"\nSource SPL rule:\n{source_spl.strip()}")
print(f"\nConverting SPL → KQL via ARuleCon...")
results = arulecon.convert(
source_rule=source_spl,
source_platform="splunk_spl",
target_platform="microsoft_kql",
verbose=True
)
# Show IR decomposition
print("\n[IR Decomposition Detail]")
ir = results["ir"]
print(f" Metadata: {ir.rule_name} — {ir.description}")
print(f" Data source: {ir.data_source} | Event type: {ir.event_type}")
for i, step in enumerate(ir.steps):
print(f" Step {i+1}: [{step.keyword}] {step.param}")
# Test the Python executor independently
print("\n[Python Executor Demo] Running IR pipeline on synthetic logs...")
executor = PythonIRExecutor()
log_gen = TestLogGenerator()
logs = log_gen.generate(ir, n_normal=30, n_attack=20)
print(f" Generated {len(logs)} log entries")
for step in ir.steps[:2]:
code = executor.generate_python_for_step(step)
print(f" Step [{step.keyword}] Python code snippet:\n{textwrap.indent(code.strip()[:100], ' ')}...")
output = executor.execute_ir(ir, logs)
print(f" Pipeline output: {repr(output)[:80]}...")
print("\n" + "=" * 70)
print("ARuleCon architecture demonstration complete.")
print("Replace LLMClient stub with real API calls for production use.")
print("=" * 70)
if __name__ == '__main__':
main()
What the Efficiency Numbers Tell Us
ARuleCon is slower and more expensive than raw LLM translation, and the paper is transparent about this. With GPT-5, a single rule conversion consumes around 20,000 prompt tokens and 3,000 output tokens, taking about 142 seconds and costing roughly $0.046. The baseline takes 2,100 tokens, 12 seconds, and $0.008.
That’s 10× the cost and computation. Whether that tradeoff is worth it depends entirely on what you’re converting. For a routine migration of 1,000 rules, the total cost would be around $46 with ARuleCon versus $8 with naive LLM translation. The 15% improvement in logic slot consistency translates to roughly 150 fewer rules with incorrect temporal semantics, missing groupings, or wrong threshold placements — each of which represents a real blind spot in production security monitoring that could go undetected for months.
The paper makes this tradeoff explicit: a 15% accuracy gain justifies an additional 100 seconds of computation for a high-stakes security task where misconfigured rules create silent detection failures. In practice, rule conversion happens infrequently (during migrations and major platform upgrades) and the cost of a missed detection vastly outweighs the cost of a few extra API tokens.
ARuleCon is not trying to compete with raw LLM translation on speed or cost. It’s trying to produce correct results in a domain where correctness is critical and errors are silent. The agentic pipeline costs 10× more per rule but prevents the kind of semantic drift that turns a working Splunk detection into a broken KQL rule that appears valid, never throws an error, and never fires on the attacks it was supposed to catch.
Limitations and What’s Next
The IBM QRadar results highlight a fundamental challenge that no amount of prompting or documentation retrieval can fully solve: when the target platform simply lacks a construct that the source requires, conversion accuracy must suffer. QRadar’s strict stateless/stateful dichotomy has no equivalent in Splunk or KQL, and rules that rely on multi-event temporal correlation across dozens of events need to be partially rewritten rather than converted — a task that requires architectural knowledge beyond what current agentic workflows can reliably provide.
The paper also notes that nested Splunk subsearches pose consistent challenges. Converting a subsearch-based rule to Chronicle YARA-L requires explicitly decomposing the nesting into sequential IR steps and then reconstructing it as YARA-L’s explicit event variable correlation system. ARuleCon handles this better than naive LLMs (the case study in the appendix shows a faithful Chronicle conversion of a nested SPL rule), but the process is more fragile than straightforward pipeline conversions.
Future directions the paper explicitly mentions: building a larger corpus of paired source-target rules for fine-tuning (currently the 1,492 pairs used for evaluation come from official repositories, and many direction combinations have limited ground-truth data), and extending the Agentic RAG to handle multi-hop documentation retrieval for complex operators that require understanding several interconnected concepts simultaneously.
The broader implication of ARuleCon’s case studies with Singtel Singapore is significant: real-world SOC professionals spend substantial time not on writing new rules but on maintaining existing ones across platforms. ARuleCon’s framework — distill the logic, consult the docs, verify behaviorally — is the right mental model for that task, whether it’s performed by an AI agent or a human analyst. The fact that it can now be automated without expert intervention represents genuine time savings in security operations workflows.
Access the Paper and Code
ARuleCon is published at WWW ’26. The source code is open on GitHub and the framework is being commercialized by NCS Group (Singtel Singapore). Supported by the Singapore Ministry of Education and the NUS-NCS Joint Laboratory for Cyber Security.
Xu, M., Wang, H., Guo, Y., Yu, Z., Han, W., Lim, H. W., Dong, J. S., & Zhang, J. (2026). ARuleCon: Agentic Security Rule Conversion. In Proceedings of the ACM Web Conference 2026 (WWW ’26). ACM. https://doi.org/10.1145/3774904.3792458
This article is an independent editorial analysis of peer-reviewed research. The Python implementation is an educational re-implementation based on the paper’s method descriptions and does not represent the authors’ official code. Always refer to the original publication and GitHub repository for authoritative details and official implementations. Code is provided for educational and research purposes.
Explore More on AI Trend Blend
If this article caught your attention, here is more of what we cover — from edge AI and model compression to image restoration, knowledge distillation, and hardware-efficient deep learning.