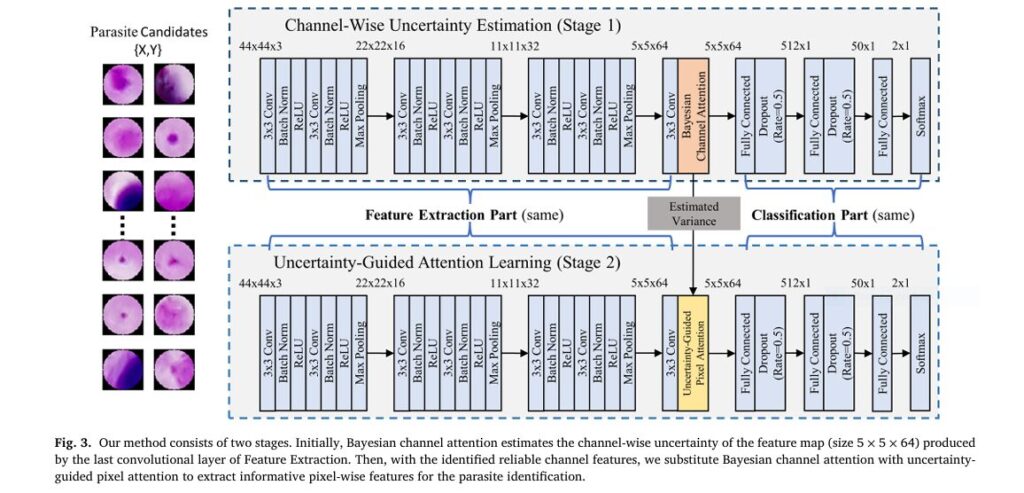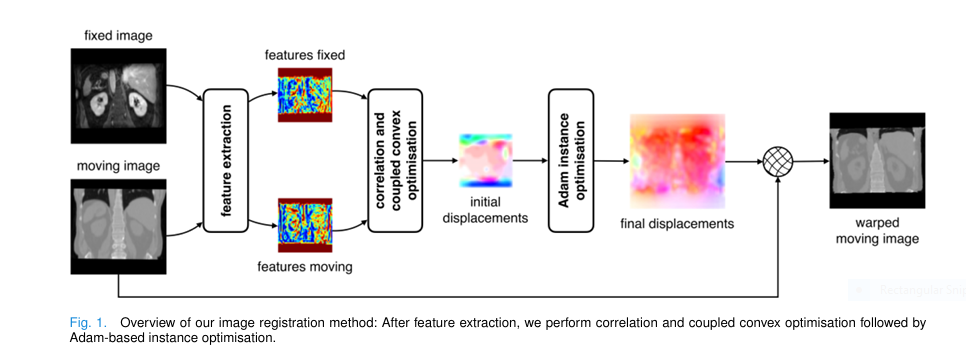
7 Revolutionary Ways ConvexAdam Beats Traditional Methods (And Why Most Fail)
Medical image registration is a cornerstone of modern diagnostics, surgical planning, and treatment monitoring. Yet, despite decades of innovation, many existing methods struggle with accuracy , speed , and versatility —especially when handling multimodal, inter-patient, or large-deformation scenarios. Enter ConvexAdam , a groundbreaking dual-optimization framework that’s redefining what’s possible in 3D medical image registration. In […]
7 Revolutionary Ways ConvexAdam Beats Traditional Methods (And Why Most Fail) Read More »